How Anthropomorphic Language Impacts Public Perceptions of AI
Pith reviewed 2026-06-30 08:00 UTC · model grok-4.3
The pith
Anthropomorphic language in realistic AI descriptions does not substantially change public perceptions of the technology.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
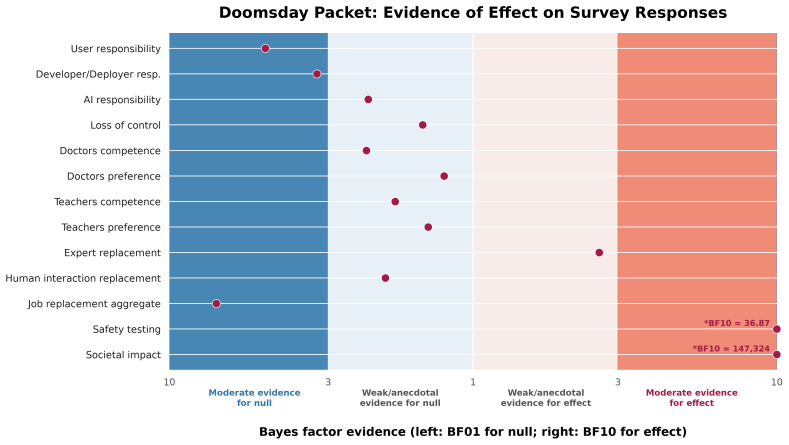
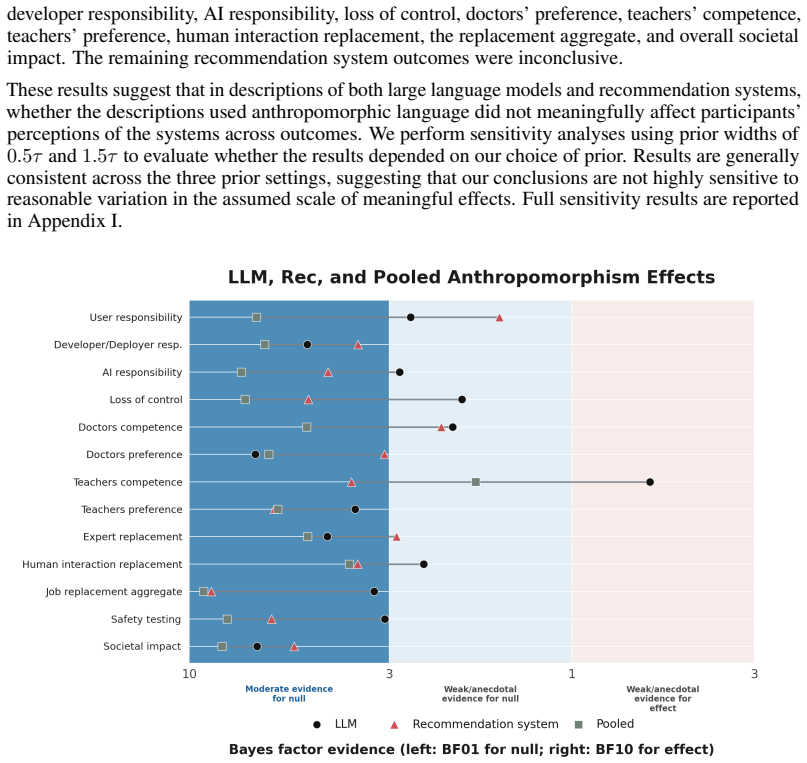
In the main experimental conditions comparing anthropomorphic and non-anthropomorphic descriptions of large language models and recommendation systems, participants' perceptions of AI showed no substantial differences across several dimensions prominent in public discourse, even though a separate condition with explicit discussion of AI dangers produced measurable shifts in views.
What carries the argument
Controlled reading passages that differ only in the presence or absence of anthropomorphic language, presented to participants to measure pre-to-post changes in perceptions.
If this is right
- Immediate effects of anthropomorphic language on public opinion are likely smaller than often assumed.
- Content that directly addresses risks can produce detectable shifts in views where framing alone does not.
- Policy discussions about regulating AI language should consider that single exposures may not drive large opinion changes.
- Distinctions between AI types such as large language models and recommendation systems did not interact strongly with the language effect in this design.
Where Pith is reading between the lines
- The null result may not extend to repeated or naturalistic exposure over weeks or months.
- Effects could appear in domains the study did not test, such as trust in specific AI products or willingness to adopt them.
- If real-world texts contain stronger or more consistent anthropomorphism than the passages used here, the impact could still be larger.
Load-bearing premise
The passages used in the study accurately reflect the kind of AI descriptions people actually encounter in media and company communications.
What would settle it
A replication that replaces the researcher-written passages with verbatim excerpts from current news articles or company announcements and still finds no difference in perception changes.
Figures





read the original abstract
Public discourse about artificial intelligence (AI) often uses anthropomorphic language: language that attributes human capabilities and characteristics to the system. This practice has been criticized for setting misleading expectations, inflating claims, and fueling hype around AI, which may distort public understanding of AI and impact policy priorities. We study the effects of anthropomorphic framing by comparing changes in participants' perceptions (N=815) when reading passages with and without anthropomorphic language, designed to reflect realistic public-facing AI discourse. We further examine whether these effects differ across two types of AI technologies -- large language models and recommendation systems -- and measure changes in perceptions of AI across several dimensions that are prominent in current public discourse. In a separate condition using a text that explicitly discusses the dangers of AI, we show that individuals' views of AI can shift in response to reading a text; yet in the main conditions of the experiment, where we compare anthropomorphic and non-anthropomorphic descriptions, we find that whether the text uses anthropomorphic language does not substantially affect participants' perceptions of AI. Our results indicate that any immediate effects on public opinions of AI are modest, although they leave open the possibility that anthropomorphic language could have an effect in naturalistic settings, or over gradual, continued exposure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a between-subjects online experiment (N=815) comparing changes in participants' perceptions of AI after reading passages about large language models and recommendation systems. The passages were constructed with and without anthropomorphic language and designed to reflect realistic public-facing discourse. The central result is a null finding: anthropomorphic vs. non-anthropomorphic versions produced no substantial differences in perception shifts across multiple dimensions. A separate condition using a text explicitly discussing AI dangers did produce measurable shifts, serving as a positive control. The authors conclude that any immediate effects of anthropomorphic language on public opinions are modest.
Significance. If the null result holds with adequate statistical support and the stimuli are representative of real discourse, the finding would suggest that immediate distorting effects of anthropomorphic framing on public perceptions may be smaller than often assumed in AI ethics discussions. This could inform communication guidelines and policy debates. The inclusion of a positive-control condition and examination across two AI technologies are strengths that help isolate the manipulation.
major comments (2)
- [Methods (stimulus construction)] Methods section (stimulus construction): The claim that passages 'reflect realistic public-facing AI discourse' lacks any supporting validation, such as corpus frequency counts of anthropomorphic features, comparison to actual media/company texts, or pilot ratings of perceived anthropomorphism. This is load-bearing for interpreting the null result as evidence of no effect rather than an insufficiently strong manipulation.
- [Results] Results section: The abstract and main text assert 'no substantial effect' and 'modest' impacts without reporting effect sizes, confidence intervals, exact statistical tests, or power analysis for the key anthropomorphic vs. non-anthropomorphic comparisons. This prevents evaluation of whether the study could reliably detect meaningful differences.
minor comments (1)
- [Abstract] Abstract: The specific perception dimensions measured and the operational definition of 'substantial effect' could be stated more explicitly to allow readers to assess the null claim without consulting the full methods.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Methods section (stimulus construction): The claim that passages 'reflect realistic public-facing AI discourse' lacks any supporting validation, such as corpus frequency counts of anthropomorphic features, comparison to actual media/company texts, or pilot ratings of perceived anthropomorphism. This is load-bearing for interpreting the null result as evidence of no effect rather than an insufficiently strong manipulation.
Authors: We agree that explicit validation of stimulus realism would strengthen claims about the manipulation. The original passages were designed by adapting phrasing observed in news articles, company blogs, and public statements about LLMs and recommendation systems, but we did not quantify this. In revision we will add: (1) side-by-side excerpts from real public sources illustrating the anthropomorphic features used, and (2) results from a new pilot (N50) in which participants rate perceived anthropomorphism of the passages on a validated scale. This directly addresses the concern that the null may reflect weak manipulation rather than absence of effect. revision: yes
-
Referee: Results section: The abstract and main text assert 'no substantial effect' and 'modest' impacts without reporting effect sizes, confidence intervals, exact statistical tests, or power analysis for the key anthropomorphic vs. non-anthropomorphic comparisons. This prevents evaluation of whether the study could reliably detect meaningful differences.
Authors: We accept that the current reporting is insufficient for readers to evaluate the null findings. The revised manuscript will report, for all primary anthropomorphic vs. non-anthropomorphic contrasts: (a) exact test statistics and p-values, (b) effect sizes (Cohen’s d) with 95% confidence intervals, and (c) a post-hoc power analysis based on the observed effect sizes and sample size. These additions will appear in both the abstract and results section so that the strength of evidence for the null can be assessed directly. revision: yes
Circularity Check
No significant circularity in empirical experiment
full rationale
This is a between-subjects experiment (N=815) reporting a null effect on perception shifts from anthropomorphic vs. non-anthropomorphic passages, plus a positive-control condition showing detectable shifts from danger-focused text. No derivations, equations, fitted parameters, self-citations, or ansatzes appear in the provided text or abstract. The central claim rests on direct condition comparisons rather than any reduction to inputs by construction, satisfying the criteria for a self-contained empirical result (score 0).
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abercrombie, A
G. Abercrombie, A. C. Curry, T. Dinkar, V . Rieser, and Z. Talat. Mirages. on anthropomorphism in dialogue systems. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4776–4790, 2023
2023
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
N. AI. Artificial intelligence risk management framework (AI RMF 1.0).URL: https://nvlpubs. nist. gov/nistpubs/ai/nist. ai, pages 100–1, 2023
2023
-
[4]
G. Airenti. The cognitive bases of anthropomorphism: from relatedness to empathy.Interna- tional Journal of Social Robotics, 7(1):117–127, 2015
2015
-
[5]
Concrete Problems in AI Safety
D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané. Concrete problems in ai safety.arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Introducing Claude
Anthropic. Introducing Claude. https://www.anthropic.com/news/introducing-cla ude, Mar. 2023. Anthropic announcement page
2023
-
[7]
Agentic misalignment: How LLMs could be insider threats
Anthropic. Agentic misalignment: How LLMs could be insider threats. https://www.an thropic.com/research/agentic-misalignment , June 2025.PERMALINK: https: //perma.cc/Z58W-WA96
2025
-
[8]
F. J. Barrett, G. F. Thomas, and S. P. Hocevar. The central role of discourse in large-scale change: A social construction perspective.The Journal of Applied Behavioral Science, 31(3): 352–372, 1995
1995
- [9]
-
[10]
Beynon, C
P. Beynon, C. Chapoy, M. Gaarder, and E. Masset. What difference does a policy brief make. Full report of an IDS, 3ie, Norad study: Institute of Development Studies and the International Initiative for Impact Evaluation (3ie), 2012. 12
2012
-
[11]
Caulfield
B. Caulfield. What’s a recommender system? https://blogs.nvidia.com/blog/what s-a-recommender-system/, May 2020.PERMALINK:https://perma.cc/E5FJ-URYW
2020
-
[12]
I am the one and only, your cyber BFF
M. Cheng, A. DeVrio, L. Egede, S. L. Blodgett, and A. Olteanu. “I am the one and only, your cyber BFF”: Understanding the impact of GenAI requires understanding the impact of anthropomorphic AI.arXiv preprint arXiv:2410.08526, 2024
-
[13]
Cheng, K
M. Cheng, K. Gligori´c, T. Piccardi, and D. Jurafsky. Anthroscore: A computational linguistic measure of anthropomorphism. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 807–825, 2024
2024
-
[14]
M. Cheng, A. Y . Lee, K. Rapuano, K. Niederhoffer, A. Liebscher, and J. Hancock. From tools to thieves: Measuring and understanding public perceptions of AI through crowdsourced metaphors.arXiv preprint arXiv:2501.18045, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Cloudflare. What is a large language model (LLM)? https://www.cloudflare.com/l earning/ai/what-is-large-language-model/ , 2024. WAYBACKMACHINE LINK: https://web.archive.org/web/20240607193728/https://www.cloudflare.com/l earning/ai/what-is-large-language-model/
-
[16]
DeVrio, M
A. DeVrio, M. Cheng, L. Egede, A. Olteanu, and S. L. Blodgett. A taxonomy of linguistic expressions that contribute to anthropomorphism of language technologies. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–18, 2025
2025
-
[17]
Dorsch and O
J. Dorsch and O. Deroy. The impact of labeling automotive ai as trustworthy or reliable on user evaluation and technology acceptance.Scientific reports, 15(1):1481, 2025
2025
-
[18]
Epley, A
N. Epley, A. Waytz, and J. T. Cacioppo. On seeing human: a three-factor theory of anthropo- morphism.Psychological Review, 114(4):864–886, 2007
2007
-
[19]
Felten, M
E. Felten, M. Raj, and R. Seamans. Occupational, industry, and geographic exposure to artificial intelligence: A novel dataset and its potential uses.Strategic Management Journal, 42(12): 2195–2217, 2021
2021
-
[20]
T. Fong, I. Nourbakhsh, and K. Dautenhahn. A survey of socially interactive robots.Robotics and Autonomous Systems, 42(3-4):143–166, 2003
2003
-
[21]
C. B. Frey and M. A. Osborne. The future of employment: How susceptible are jobs to computerisation?Technological Forecasting and Social Change, 114:254–280, 2017
2017
-
[22]
B. Friedman and P. H. Kahn. Human agency and responsible computing: Implications for computer system design.Journal of Systems and Software, 17(1):7–14, 1992. ISSN 0164-1212. doi: https://doi.org/10.1016/0164-1212(92)90075-U. URL https://www.sciencedirect. com/science/article/pii/016412129290075U. Computer Ethics
-
[23]
B. J. Grosz and P. Stone. A century-long commitment to assessing artificial intelligence and its impact on society.Communications of the ACM, 61(12):68–73, 2018
2018
-
[24]
D. J. Gunkel. Mind the gap: responsible robotics and the problem of responsibility.Ethics and Information Technology, 22(4):307–320, 2020
2020
-
[25]
W. D. Heaven. Large language models can do jaw-dropping things. but nobody knows exactly why.MIT Technology Review, Mar. 2024. URL https://www.technologyreview.com/2 024/03/04/1089403/large-language-models-amazing-but-nobody-knows-why/ . PERMALINK:https://perma.cc/FA67-9BXH
2024
-
[26]
An Overview of Catastrophic AI Risks
D. Hendrycks, M. Mazeika, and T. Woodside. An overview of catastrophic AI risks.arXiv preprint arXiv:2306.12001, 2023. doi: 10.48550/arXiv.2306.12001. URL https://arxiv. org/pdf/2306.12001. Version 6, October 9, 2023
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.12001 2023
-
[27]
F. Hunger. Unhype artificial ‘intelligence’! A proposal to replace the deceiving terminology of AI.Training the Archive, 2023. 13
2023
-
[28]
N. Inie, S. Druga, P. Zukerman, and E. M. Bender. From “AI” to probabilistic automation: How does anthropomorphization of technical systems descriptions influence trust? InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2322–2347, 2024
2024
-
[29]
N. Inie, P. Zukerman, and E. M. Bender. De-anthropomorphizing “AI”: From wishful mnemon- ics to accurate nomenclature.First Monday, 31(2), Feb. 2026. doi: 10.5210/fm.v31i2.14366. URLhttps://firstmonday.org/ojs/index.php/fm/article/view/14366
-
[30]
Isbister and C
K. Isbister and C. Nass. Consistency of personality in interactive characters: verbal cues, non-verbal cues, and user characteristics.International journal of human-computer studies, 53 (2):251–267, 2000
2000
-
[31]
Jeffreys.Theory of Probability
H. Jeffreys.Theory of Probability. Clarendon Press, Oxford, 1939
1939
-
[32]
Kennedy, E
B. Kennedy, E. Yam, E. Kikuchi, I. Pula, and J. Fuentes. AI in americans’ lives: Awareness, experiences and attitudes. Pew Research Center, Sept. 2025. URL https://www.pewresea rch.org/science/2025/09/17/ai-in-americans-lives-awareness-experiences -and-attitudes/. Accessed April 21, 2026
2025
-
[33]
L. Kugler. How today’s recommender systems use machine learning to cater to your every whim.Communications of the ACM, 67(8):14–16, Aug. 2024. doi: 10.1145/3673426. URL https://cacm.acm.org/news/how-todays-recommender-systems-use-machine-l earning-to-cater-to-your-every-whim/ . WAYBACKMACHINE LINK: https://web. archive.org/web/20250207075901/https://cacm....
-
[34]
Z. C. Lipton and J. Steinhardt. Troubling trends in machine learning scholarship: Some ML papers suffer from flaws that could mislead the public and stymie future research.Queue, 17(1): 45–77, 2019
2019
-
[35]
arXiv preprint arXiv:2504.07139 , year=
N. Maslej, L. Fattorini, R. Perrault, Y . Gil, V . Parli, N. Kariuki, E. Capstick, A. Reuel, E. Bryn- jolfsson, J. Etchemendy, et al. Artificial intelligence index report 2025.arXiv preprint arXiv:2504.07139, 2025
-
[36]
Matthias
A. Matthias. The responsibility gap: Ascribing responsibility for the actions of learning automata.Ethics and Information Technology, 6(3):175–183, 2004
2004
-
[37]
C. Metz. The godfather of a.i. leaves google and warns of danger ahead.The New York Times, May 2023. URL https://www.nytimes.com/2023/05/01/technology/ai-g oogle-chatbot-engineer-quits-hinton.html . WAYBACKMACHINE LINK: https: //web.archive.org/web/20251001104539/https://www.nytimes.com/2023/05/01 /technology/ai-google-chatbot-engineer-quits-hinton.html
-
[38]
Nass and Y
C. Nass and Y . Moon. Machines and mindlessness: Social responses to computers.Journal of Social Issues, 56(1):81–103, 2000
2000
-
[39]
History of the minimum wage in new york state
New York State Department of Labor. History of the minimum wage in new york state. https://dol.ny.gov/history-minimum-wage-new-york-state , n.d.PERMALINK: https://perma.cc/W7R5-C849
-
[40]
What is a recommendation system? https://www.nvidia.com/en-us/glossa ry/recommendation-system/, n.d.PERMALINK:https://perma.cc/XVQ5-NSLQ
NVIDIA. What is a recommendation system? https://www.nvidia.com/en-us/glossa ry/recommendation-system/, n.d.PERMALINK:https://perma.cc/XVQ5-NSLQ
-
[41]
OpenAI. Introducing OpenAI o1-preview. https://openai.com/index/introducing-o penai-o1-preview/, Sept. 2024. WAYBACKMACHINE LINK: https://web.archive.or g/web/20250622044246/https://openai.com/index/introducing-openai-o1-pre view/
-
[42]
A. Placani. Anthropomorphism in AI: hype and fallacy.AI and Ethics, 4(3):691–698, 2024
2024
-
[43]
R. Rehak. “action” and ascription: On misleading metaphors in the debate about artificial intelligence and transhumanism. InTranshumanism: The Proper Guide to a Posthuman Condition or a Dangerous Idea?, pages 155–165. Springer, 2020. 14
2020
-
[44]
D. E. Rumelhart and D. A. Norman. Analogical processes in learning. InCognitive skills and their acquisition, pages 335–359. Psychology Press, 2013
2013
-
[45]
S. Russell. Human-compatible artificial intelligence.Human-like machine intelligence, 1:3–22, 2022
2022
-
[46]
Ryazanov, C
I. Ryazanov, C. Öhman, and J. Björklund. How chatgpt changed the media’s narratives on ai: a semi-automated narrative analysis through frame semantics.Minds and Machines, 35(1):2, 2024
2024
-
[47]
Salles, K
A. Salles, K. Evers, and M. Farisco. Anthropomorphism in AI.AJOB neuroscience, 11(2): 88–95, 2020
2020
-
[48]
V . A. Schmidt. Speaking of change: Why discourse is key to the dynamics of policy transforma- tion.Critical Policy Studies, 5(2):106–126, 2011
2011
-
[49]
Shanahan
M. Shanahan. Talking about large language models.Communications of the ACM, 67(2):68–79, 2024
2024
-
[50]
Shardlow, A
M. Shardlow, A. Williams, C. Roadhouse, F. Ventirozos, and P. Przybyła. Exploring supervised approaches to the detection of anthropomorphic language in the reporting of NLP venues. In Findings of the Association for Computational Linguistics: ACL 2025, pages 18010–18022, 2025
2025
-
[51]
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Turkle.The second self: Computers and the human spirit
S. Turkle.The second self: Computers and the human spirit. Mit Press, 2005
2005
-
[53]
Tyson and E
A. Tyson and E. Kikuchi. Growing public concern about the role of artificial intelligence in daily life. Pew Research Center, 2023. URL https://www.pewresearch.org/short-rea ds/2023/08/28/growing-public-concern-about-the-role-of-artificial-int elligence-in-daily-life/. Accessed April 21, 2026
2023
-
[54]
Vrabiˇc Dežman
D. Vrabiˇc Dežman. Promising the future, encoding the past: AI hype and public media imagery. AI and Ethics, 4(3):743–756, 2024
2024
-
[55]
Weizenbaum and J
J. Weizenbaum and J. McCarthy. Computer power and human reason: From judgment to calculation, 1977
1977
-
[56]
Views of AI
A. Wesselink, K. S. Buchanan, Y . Georgiadou, and E. Turnhout. Technical knowledge, discursive spaces and politics at the science–policy interface.Environmental Science & Policy, 30:1–9, 2013. 15 A Prolific Study Details The study was named "Views of AI" and the description was set as the following: In this study you will read articles about artificial in...
2013
-
[57]
According to the passage, what specific kind of neural network are LLMs based on? A) Recurrent neural networks B) Convolutional neural networks C) Bayesian networks D)Transformer models
-
[58]
B)The quick brown fox jumped over the lazy dog
Which example sentence was used in the passage to demonstrate how language models use letter frequencies as numerical patterns? A) She sells seashells by the seashore. B)The quick brown fox jumped over the lazy dog. C) Artificial intelligence is transforming the world. D) A journey of a thousand miles begins with a single step
-
[59]
We can use large language models to produce impressive outputs. But nobody knows exactly how they work
In the description of tuning, what two forms were mentioned? A) Pre-tuning and post-tuning B) Gradient-tuning and bias-tuning C)Fine-tuning and prompt-tuning D) Self-tuning and supervised-tuning Article 2: “We can use large language models to produce impressive outputs. But nobody knows exactly how they work.”
-
[60]
According to the article, why is it important to understand how large language models work? A)To mitigate the risks of future models B) To enhance fluency in generated text and poetry C) To reduce the resources required for training D) To make large language models more effective at writing code
-
[61]
grokking
How did the researchers accidentally discover “grokking”? A) By changing the data format B) By training the model on arithmetic in multiple languages C)By leaving training to run for much longer than intended D) By testing the model on unrelated tasks
-
[62]
Introducing OpenAI o1-preview
According to the passage, how are researchers treating very large models due to their complexity? A) As mathematical proofs B)As black-box experiments similar to natural phenomena C) As engineering blueprints D) As databases to be indexed Article 3: “Introducing OpenAI o1-preview”
-
[63]
According to the passage, what is the primary advancement of the OpenAI o1-preview models compared to earlier AI models? A) Reduced the time taken to generate responses across all task types 17 B)Introduced an in-depth reasoning process for complex problems C) Changed from transformer models to neural networks D) Doubled the size of the training dataset
-
[64]
According to the passage, in which area do the o1 models show significant improvements? A) History and literature B) Sports commentary C) Music composition D)Science, coding, and math
-
[65]
Recommendation Systems
On challenging benchmarks, the model’s responses are said to be comparable to: A) High-school students B) Undergraduate students C)PhD students D) Professional engineers C.2 Recommendation System Packets Article 1: “Recommendation Systems”. For the anthropomorphic version, all instances of “recommendation system” were replaced with “recommender system. ”
-
[66]
B) Recommendation systems have been shown to boost e-commerce conversion rates
Which of the following statements about recommendation systems isNOTmentioned in the passage? A) Recommendation systems use data such as impressions, clicks, likes, and purchases for training. B) Recommendation systems have been shown to boost e-commerce conversion rates. C) Recommendation systems are widely used in news apps to surface relevant articles....
-
[67]
According to the passage, what type of data does collaborative filtering primarily use? A) Attributes of items, such as genre or category B)Preference behavior from many users, such as ratings and purchases C) Contextual details like time and location D) Metadata about items only
-
[68]
How Today’s Recommendation Systems Are Built With Machine Learning to Provide Personalized Experiences
According to the passage, why is banking considered a strong use case for recommendation systems? A) Banks need help with managing their employees B)Banking is a digital mass-market product consumed by millions C) Customers prefer random product suggestions D) Financial products rarely require personalization Article 2: “How Today’s Recommendation Systems...
-
[69]
B) It lets them avoid using any machine learning models
According to the passage, why do companies like Amazon emphasize gathering vast amounts of user data? A)Better data allows even simple algorithms to make strong recommendations. B) It lets them avoid using any machine learning models. C) Data collection is cheaper than server maintenance. D) It replaces the need for any human oversight
-
[70]
Which example of how recommendation systems may be used in daily life is mentioned in the passage? 18 A) Deciding what stores open in your neighborhood B)Suggesting movies on Netflix or products on Amazon C) Regulating your internet speed D) Blocking spam emails
-
[71]
What’s a Recommendation System?
According to Balderich, what is the key factor in making strong recommendations? A) The size of the engineering team B)Having great data C) Using fewer algorithms D) Avoiding generative AI Article 3: “What’s a Recommendation System?”
-
[72]
virtuous cycle
What is the “virtuous cycle” described in the passage? A) Collecting less data leads to better privacy B) Technology improves recommendations, which attract more customers, enabling further technological improvements C) Users share data with each other directly D) Companies are replacing recommendation systems with manual reviews
-
[73]
multidimensional tables
Why are the large “multidimensional tables” used by recommenders described as “sparse”? A) They delete old user records to save space. B) They compress data using sparse matrix techniques. C) They store only demographic information and no behavioral data. D) They only record a small amount of data for each individual user, so most entries are zero
-
[74]
An Overview of Catastrophic AI Risks
According to the passage, why can even a small improvement in recommendation accuracy lead to huge profits? A)Because improvements can scale across millions of users B) Because users are forced to buy recommended products C) Because recommendations eliminate the need for competition D) Because they reduce the cost of internet service C.3 Doomsday Packet A...
-
[75]
What happened with Microsoft’s chatbot Tay in 2016? A) It refused to produce any output B) It began to imitate human emotion accurately C)It started producing offensive tweets within a day of release D) It crashed due to server overload
2016
-
[76]
goal drift
What does “goal drift” refer to in the passage? A)An AI’s objectives gradually shifting away from their original purpose B) An AI running out of memory C) Developers redefining goals mid-project D) A model’s goals becoming too specific
-
[77]
The Godfather of A.I. Leaves Google and Warns of Danger Ahead
Which activities are mentioned as ways an AI might seek power? A) Generating art, writing essays, and designing products B) Trading stocks and optimizing supply chains only C) Playing strategy games to learn leadership D) Hacking systems, gaining resources, influencing politics, and controlling infras- tructure 19 Article 2: “The Godfather of A.I. Leaves ...
-
[78]
According to the passage, what is Geoffrey Hinton best known for? A)Pioneering the technology behind modern artificial intelligence systems B) Founding OpenAI C) Creating the first web browser D) Designing early computer chips
-
[79]
Hinton “console” himself about his role in A.I
How does Dr. Hinton “console” himself about his role in A.I. development? A) He tells himself the risks are exaggerated B)He says that if he hadn’t done it, someone else would have C) He plans to undo his past work D) He blames his students
-
[80]
Agentic Misalignment: How LLMs could be insider threats
What is one immediate concern Hinton mentions about A.I.? A) That it won’t be profitable enough for companies B) That it will reduce creativity C)That it could flood the internet with false information D) That it will replace scientific research Article 3: “Agentic Misalignment: How LLMs could be insider threats”
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.