Clearer Sight, Fewer Lies: Oriented Pickup Preference Optimization for Multimodal Hallucination Mitigation
Pith reviewed 2026-06-30 06:11 UTC · model grok-4.3
The pith
Oriented Pickup Preference Optimization aligns multimodal model responses to stronger visual evidence to reduce hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
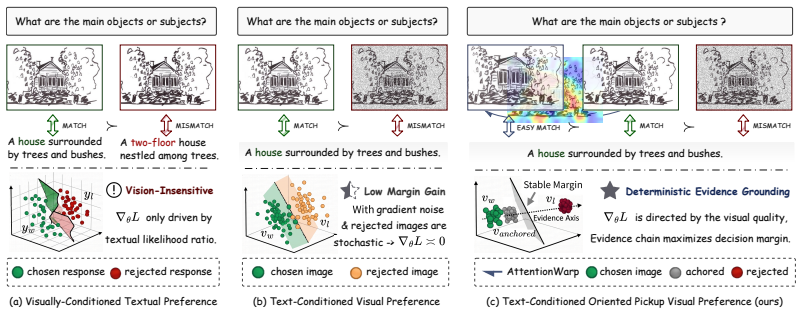
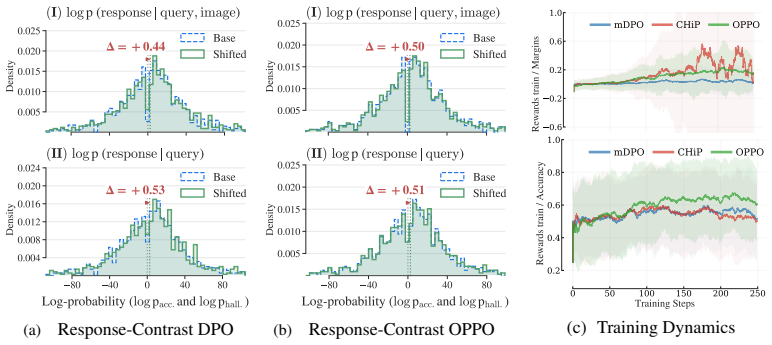
When query-relevant visual evidence is strengthened using the model's own attention, generation accuracy increases, indicating that hallucinations stem partly from insufficient trust in attended evidence. OPPO learns preferences over evidence strength by contrasting the same faithful response under stronger and weaker evidence views, inducing a positive lower bound on local visual sensitivity through ordered evidence margins.
What carries the argument
Oriented Pickup Preference Optimization (OPPO), an evidence-aware alignment objective that contrasts faithful responses under varying strengths of visual evidence anchored by the model's attention.
Load-bearing premise
The empirical observation that strengthening query-relevant visual evidence via the model's own attention improves accuracy generalizes to the proposed ordered preference objective and induces the claimed positive lower bound on local visual sensitivity.
What would settle it
An experiment showing that models trained with OPPO do not exhibit higher accuracy when visual evidence is strengthened via attention, or that the lower bound on visual sensitivity is not positive.
Figures






read the original abstract
Multimodal Large Language Models (MLLMs) are prone to hallucination as their generation preferences are insufficiently calibrated to visual evidence, causing them to fall back on linguistic priors, rather than faithful grounding. In this work, we start from an empirical observation: when query-relevant visual evidence is explicitly strengthened using the model's own attention, generation becomes more accurate, suggesting that many failures do not arise solely from missing perception, but from an insufficient tendency to trust the evidence the model has already attended to. Motivated by this finding, we propose Oriented Pickup Preference Optimization (\texttt{OPPO}), an evidence-aware alignment objective that learns preferences over the strength of visual evidence, rather than only response quality. Concretely, \texttt{OPPO} contrasts the same faithful response under stronger, anchored, weaker-evidence views, turning naive visual preference into ordered visual-evidence alignment. We further combine this objective with fine-grained span-level and token-level regularization to stabilize the training. Besides, we provide a theoretical analysis showing that ordered evidence margins induce a positive lower bound on local visual sensitivity. Extensive evaluations across hallucination and general-purpose benchmarks demonstrate that \texttt{OPPO} consistently outperforms baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MLLMs hallucinate due to insufficient calibration of generation preferences to visual evidence rather than missing perception. It proposes Oriented Pickup Preference Optimization (OPPO), an evidence-aware alignment method that learns ordered preferences over visual evidence strength by contrasting the same faithful response under stronger/anchored/weaker evidence views derived from the model's own attention. The method adds span-level and token-level regularization, includes a theoretical analysis asserting that ordered evidence margins induce a positive lower bound on local visual sensitivity, and reports consistent outperformance over baselines on hallucination and general-purpose benchmarks.
Significance. If the claimed theoretical lower bound and the generalization from the empirical attention-strengthening observation to the ordered preference objective hold with reproducible gains, the work would offer a targeted alignment approach for visual grounding in MLLMs that could improve reliability without requiring new perception modules.
minor comments (2)
- The abstract asserts a theoretical analysis and positive lower bound without visible equations or proof sketch; the full manuscript should include the derivation in a dedicated section with explicit assumptions.
- Experimental details such as exact benchmark splits, number of runs, error bars, and ablation isolating the ordered-evidence component versus standard DPO are needed to support the 'consistently outperforms' claim.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript, which accurately captures the motivation, the OPPO objective, the regularization terms, the theoretical claim on evidence margins, and the empirical results. We appreciate the recognition that, if the lower bound and the attention-to-preference generalization hold with reproducible gains, the approach could provide a targeted alignment method for visual grounding without new perception modules. No specific major comments were provided in the report.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The provided abstract and description contain no visible equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims (OPPO objective, ordered evidence alignment, or theoretical bound on visual sensitivity) to their own inputs by construction. The empirical motivation is stated as an observation, the method is defined directly from it, and the theoretical analysis is asserted as an independent result without reduction to prior fitted values or author-overlapping uniqueness theorems. This matches the default expectation of a non-circular paper; the reader's score of 3.0 is consistent with absence of detectable circular steps at the abstract level.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[6]
Can multimodal large language models truly perform multimodal in-context learning? In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6000–6010
Shuo Chen, Zhen Han, Bailan He, Jianzhe Liu, Mark Buckley, Yao Qin, Philip Torr, V olker Tresp, and Jindong Gu. Can multimodal large language models truly perform multimodal in-context learning? In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6000–6010. IEEE, 2025
2025
-
[7]
Halc: Object hallucination reduction via adaptive focal-contrast decoding
Zhaorun Chen, Zhuokai Zhao, Hongyin Luo, Huaxiu Yao, Bo Li, and Jiawei Zhou. Halc: Object hallucination reduction via adaptive focal-contrast decoding. InForty-first International Conference on Machine Learning, 2024
2024
-
[8]
Yeongjae Cho, Keonwoo Kim, Taebaek Hwang, and Sungzoon Cho. Do you keep an eye on what i ask? mitigating multimodal hallucination via attention-guided ensemble decoding.arXiv preprint arXiv:2505.17529, 2025
-
[9]
Dola: Decoding by contrasting layers improves factuality in large language models
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R Glass, and Pengcheng He. Dola: Decoding by contrasting layers improves factuality in large language models. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[10]
Constructive Distortion: Improving MLLMs with Attention-Guided Image Warping
Dwip Dalal, Gautam Vashishtha, Utkarsh Mishra, Jeonghwan Kim, Madhav Kanda, Hyeonjeong Ha, Svetlana Lazebnik, Heng Ji, and Unnat Jain. Constructive distortion: Improving mllms with attention- guided image warping.arXiv preprint arXiv:2510.09741, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
On the limitations of multimodal vaes.arXiv preprint arXiv:2110.04121, 2021
Imant Daunhawer, Thomas M Sutter, Kieran Chin-Cheong, Emanuele Palumbo, and Julia E V ogt. On the limitations of multimodal vaes.arXiv preprint arXiv:2110.04121, 2021
-
[12]
Jacob Eisenstein, Chirag Nagpal, Alekh Agarwal, Ahmad Beirami, Alex D’Amour, DJ Dvijotham, Adam Fisch, Katherine Heller, Stephen Pfohl, Deepak Ramachandran, et al. Helping or herding? reward model ensembles mitigate but do not eliminate reward hacking.arXiv preprint arXiv:2312.09244, 2023
-
[13]
Chip: Cross-modal hierarchical direct preference optimization for multimodal llms
Jinlan Fu, Hao Fei, Xiaoyu Shen, Bryan Hooi, Xipeng Qiu, See-Kiong Ng, et al. Chip: Cross-modal hierarchical direct preference optimization for multimodal llms. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[14]
Ocrbench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning, 2024
Ling Fu, Biao Yang, Zhebin Kuang, Jiajun Song, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, Mingxin Huang, Zhang Li, Guozhi Tang, Bin Shan, Chunhui Lin, Qi Liu, Binghong Wu, Hao Feng, Hao Liu, Can Huang, Jingqun Tang, Wei Chen, Lianwen Jin, Yuliang Liu, and Xiang Bai. Ocrbench v2: An improved benchmark for evaluating large multimodal models on vis...
2024
-
[15]
Mitigating hallucination in multi- modal large language model via hallucination-targeted direct preference optimization
Yuhan Fu, Ruobing Xie, Xingwu Sun, Zhanhui Kang, and Xirong Li. Mitigating hallucination in multi- modal large language model via hallucination-targeted direct preference optimization. InFindings of the Association for Computational Linguistics: ACL 2025, pages 16563–16577, 2025. 10
2025
-
[16]
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pag...
2024
-
[17]
Detecting and preventing hallucinations in large vision language models
Anisha Gunjal, Jihan Yin, and Erhan Bas. Detecting and preventing hallucinations in large vision language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18135–18143, 2024
2024
-
[18]
Junlin Han, Shengbang Tong, David Fan, Yufan Ren, Koustuv Sinha, Philip Torr, and Filippos Kokkinos. Learning to see before seeing: Demystifying llm visual priors from language pre-training.arXiv preprint arXiv:2509.26625, 2025
-
[19]
Self-contradiction as self-improvement: Mitigating the generation-understanding gap in mllms.arXiv e-prints, pages arXiv–2507, 2025
Yujin Han, Hao Chen, Andi Han, Zhiheng Wang, Xinyu Lin, Yingya Zhang, Shiwei Zhang, and Difan Zou. Self-contradiction as self-improvement: Mitigating the generation-understanding gap in mllms.arXiv e-prints, pages arXiv–2507, 2025
2025
-
[20]
Seeing is believing? mitigating ocr hallucinations in multimodal large language models
Zhentao He, Can Zhang, Ziheng Wu, Zhenghao Chen, Yufei Zhan, Yifan Li, Zhao Zhang, Xian Wang, and Minghui Qiu. Seeing is believing? mitigating ocr hallucinations in multimodal large language models. NeurIPS, 2025
2025
-
[21]
Mmboundary: Advancing mllm knowledge boundary awareness through reasoning step confidence calibration
Zhitao He, Sandeep Polisetty, Zhiyuan Fan, Yuchen Huang, Shujin Wu, and Yi R Fung. Mmboundary: Advancing mllm knowledge boundary awareness through reasoning step confidence calibration. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16427–16444, 2025
2025
-
[22]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[23]
mplug-docowl2: High-resolution compressing for ocr-free multi-page document understanding
Anwen Hu, Haiyang Xu, Liang Zhang, Jiabo Ye, Ming Yan, Ji Zhang, Qin Jin, Fei Huang, and Jingren Zhou. mplug-docowl2: High-resolution compressing for ocr-free multi-page document understanding. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5817–5834, 2025
2025
-
[24]
Bliva: A simple multimodal llm for better handling of text-rich visual questions
Wenbo Hu, Yifan Xu, Yi Li, Weiyue Li, Zeyuan Chen, and Zhuowen Tu. Bliva: A simple multimodal llm for better handling of text-rich visual questions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 2256–2264, 2024
2024
-
[25]
Visual instruction tuning towards general-purpose multimodal large language model: A survey
Jiaxing Huang, Jingyi Zhang, Kai Jiang, Han Qiu, Xiaoqin Zhang, Ling Shao, Shijian Lu, and Dacheng Tao. Visual instruction tuning towards general-purpose multimodal large language model: A survey. International Journal of Computer Vision, 133(11):8151–8189, 2025
2025
-
[26]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1– 55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1– 55, 2025
2025
-
[27]
Mingxin Huang, Yongxin Shi, Dezhi Peng, Songxuan Lai, Zecheng Xie, and Lianwen Jin. Ocr-reasoning benchmark: Unveiling the true capabilities of mllms in complex text-rich image reasoning.arXiv preprint arXiv:2505.17163, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13418–13427, 2024
2024
-
[29]
Zhiwei Jin, Xiaohui Song, Nan Wang, Yafei Liu, Chao Li, Xin Li, Ruichen Wang, Zhihao Li, Qi Qi, Long Cheng, et al. Andesvl technical report: An efficient mobile-side multimodal large language model.arXiv preprint arXiv:2510.11496, 2025
-
[30]
Visual Funnel: Resolving Contextual Blindness in Multimodal Large Language Models
Woojun Jung, Jaehoon Go, Mingyu Jeon, Sunjae Yoon, and Junyeong Kim. Visual funnel: Resolving contextual blindness in multimodal large language models.arXiv preprint arXiv:2512.10362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Exposing and mitigating spurious correlations for cross-modal retrieval
Jae Myung Kim, A Koepke, Cordelia Schmid, and Zeynep Akata. Exposing and mitigating spurious correlations for cross-modal retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2585–2595, 2023. 11
2023
-
[32]
Vru-accident: A vision-language benchmark for video question answering and dense captioning for accident scene understanding
Younggun Kim, Ahmed S Abdelrahman, and Mohamed Abdel-Aty. Vru-accident: A vision-language benchmark for video question answering and dense captioning for accident scene understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 761–771, 2025
2025
-
[33]
Rlaif vs
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, et al. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback. InForty-first International Conference on Machine Learning, 2024
2024
-
[34]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. arXiv preprint arXiv:2311.16922, 2023
-
[35]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872– 13882, 2024
2024
-
[36]
Mitigating object hallucinations in mllms via multi-frequency perturbations
Shuo Li, Jiajun Sun, Guodong Zheng, Xiaoran Fan, Yujiong Shen, Yi Lu, Zhiheng Xi, Yuming Yang, Wenming Tan, Tao Ji, et al. Mitigating object hallucinations in mllms via multi-frequency perturbations. arXiv preprint arXiv: 2503.14895, 2025
-
[37]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[38]
Monkey: Image resolution and text label are important things for large multi-modal models
Zhang Li, Biao Yang, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu, and Xiang Bai. Monkey: Image resolution and text label are important things for large multi-modal models. InCVPR, pages 26763–26773, 2024
2024
-
[39]
P 2-dpo: Grounding hallucination in perceptual processing via calibration direct preference optimization
Zhihao Li, Haozhang Yuan, CL Philip Chen, Tong Zhang, et al. P 2-dpo: Grounding hallucination in perceptual processing via calibration direct preference optimization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[40]
Doclayllm: An efficient multi-modal extension of large language models for text-rich document understanding
Wenhui Liao, Jiapeng Wang, Hongliang Li, Chengyu Wang, Jun Huang, and Lianwen Jin. Doclayllm: An efficient multi-modal extension of large language models for text-rich document understanding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4038–4049, 2025
2025
-
[41]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
2024
-
[42]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2024
2024
-
[43]
Wenqi Liu, Xuemeng Song, Jiaxi Li, Yinwei Wei, Na Zheng, Jianhua Yin, and Liqiang Nie. Mitigating hallucination through theory-consistent symmetric multimodal preference optimization.arXiv preprint arXiv:2506.11712, 2025
-
[44]
Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233. Springer, 2024
2024
-
[45]
Ocrbench: on the hidden mystery of ocr in large multimodal models
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences, 67(12), December 2024
2024
-
[46]
OCRBench: On the Hidden Mystery of OCR in Large Multimodal Models
Yuliang Liu, Zhang Li, Hongliang Li, Wenwen Yu, Mingxin Huang, Dezhi Peng, Mingyu Liu, Mingrui Chen, Chunyuan Li, Lianwen Jin, et al. On the hidden mystery of ocr in large multimodal models.arXiv preprint arXiv:2305.07895, 2(5):6, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Zhining Liu, Ziyi Chen, Hui Liu, Chen Luo, Xianfeng Tang, Suhang Wang, Joy Zeng, Zhenwei Dai, Zhan Shi, Tianxin Wei, Benoit Dumoulin, and Hanghang Tong. Seeing but not believing: Probing the disconnect between visual attention and answer correctness in vlms.arXiv preprint arXiv:2510.17771, 2025
-
[48]
Principal components analysis (pca).Computers & Geosciences, 19(3):303–342, 1993
Andrzej Ma ´ckiewicz and Waldemar Ratajczak. Principal components analysis (pca).Computers & Geosciences, 19(3):303–342, 1993. 12
1993
-
[49]
Inform: Mitigating reward hacking in rlhf via information-theoretic reward modeling.Advances in Neural Information Processing Systems, 37:134387–134429, 2024
Yuchun Miao, Sen Zhang, Liang Ding, Rong Bao, Lefei Zhang, and Dacheng Tao. Inform: Mitigating reward hacking in rlhf via information-theoretic reward modeling.Advances in Neural Information Processing Systems, 37:134387–134429, 2024
2024
-
[50]
Dexter Neo and Tsuhan Chen. V ord: Visual ordinal calibration for mitigating object hallucinations in large vision-language models.arXiv preprint arXiv:2412.15739, 2024
-
[51]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[52]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[53]
Object hallucination in image captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045, 2018
2018
-
[54]
Pritam Sarkar, Sayna Ebrahimi, Ali Etemad, Ahmad Beirami, Sercan Ö Arık, and Tomas Pfister. Mitigating object hallucination in mllms via data-augmented phrase-level alignment.arXiv preprint arXiv:2405.18654, 2024
-
[55]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[56]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Dong Shu, Haiyan Zhao, Jingyu Hu, Weiru Liu, Ali Payani, Lu Cheng, and Mengnan Du. Large vision- language model alignment and misalignment: A survey through the lens of explainability.arXiv preprint arXiv:2501.01346, 2025
-
[58]
When semantics mislead vision: Mitigating large multimodal models hallucinations in scene text spotting and understanding.NeurIPS, 2025
Yan Shu, Hangui Lin, Yexin Liu, Yan Zhang, Gangyan Zeng, Yan Li, Yu Zhou, Ser-Nam Lim, Harry Yang, and Nicu Sebe. When semantics mislead vision: Mitigating large multimodal models hallucinations in scene text spotting and understanding.NeurIPS, 2025
2025
-
[59]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InCVPR, pages 8317–8326, 2019
2019
-
[60]
Aligning Large Multimodal Models with Factually Augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang- Yan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually augmented rlhf.arXiv preprint arXiv:2309.14525, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Aligning large multimodal models with factually augmented rlhf
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually augmented rlhf. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13088–13110, 2024
2024
-
[62]
Textsquare: Scaling up text-centric visual instruction tuning.arXiv preprint arXiv:2404.12803, 2024
Jingqun Tang, Chunhui Lin, Zhen Zhao, Shu Wei, Binghong Wu, Qi Liu, Yangfan He, Kuan Lu, Hao Feng, Yang Li, et al. Textsquare: Scaling up text-centric visual instruction tuning.arXiv preprint arXiv:2404.12803, 2024
-
[63]
Revisiting mllm based image quality assessment: Errors and remedy
Zhenchen Tang, Songlin Yang, Bo Peng, Zichuan Wang, and Jing Dong. Revisiting mllm based image quality assessment: Errors and remedy. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 9475–9483, 2026
2026
-
[64]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Describe anything model for visual question answering on text-rich images
Yen-Linh Vu, Dinh-Thang Duong, Truong-Binh Duong, Anh-Khoi Nguyen, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Jianhua Xing, Xingjian Li, Tianyang Wang, Ulas Bagci, et al. Describe anything model for visual question answering on text-rich images. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7484–7494, 2025
2025
-
[66]
mdpo: Conditional preference optimization for multimodal large language models
Fei Wang, Wenxuan Zhou, James Y Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen. mdpo: Conditional preference optimization for multimodal large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8078–8088, 2024. 13
2024
-
[67]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Ming Yan, Ji Zhang, and Jitao Sang. An llm-free multi-dimensional benchmark for mllms hallucination evaluation.arXiv preprint arXiv:2311.07397, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Biemann. Mitigating hallucinations in large vision- language models with instruction contrastive decoding.arXiv preprint arXiv:2403.18715, 2024
-
[70]
Detecting and mitigating hallucination in large vision language models via fine-grained ai feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Fangxun Shu, Hao Jiang, and Linchao Zhu. Detecting and mitigating hallucination in large vision language models via fine-grained ai feedback. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25543–25551, 2025
2025
-
[71]
V-dpo: Mitigating hallucination in large vision language models via vision-guided direct preference optimization
Yuxi Xie, Guanzhen Li, Xiao Xu, and Min-Yen Kan. V-dpo: Mitigating hallucination in large vision language models via vision-guided direct preference optimization. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 13258–13273, 2024
2024
-
[72]
Yun Xing, Yiheng Li, Ivan Laptev, and Shijian Lu. Mitigating object hallucination via concentric causal attention.arXiv preprint arXiv:2410.15926, 2024
-
[73]
Mitigating hallucinations in multi-modal large language models via image token attention-guided decoding
Xinhao Xu, Hui Chen, Mengyao Lyu, Sicheng Zhao, Yizhe Xiong, Zijia Lin, Jungong Han, and Guiguang Ding. Mitigating hallucinations in multi-modal large language models via image token attention-guided decoding. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Techno...
2025
-
[74]
Mitigating hallucinations in large vision-language models via dpo: On-policy data hold the key
Zhihe Yang, Xufang Luo, Dongqi Han, Yunjian Xu, and Dongsheng Li. Mitigating hallucinations in large vision-language models via dpo: On-policy data hold the key. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10610–10620, 2025
2025
-
[75]
mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Haowei Liu, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration.arXiv preprint arXiv:2311.04257, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
A Survey on Multimodal Large Language Models
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.arXiv preprint arXiv:2306.13549, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[77]
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13807–13816, 2024
2024
-
[78]
Tianyu Yu, Haoye Zhang, Yuan Yao, Yunkai Dang, Da Chen, Xiaoman Lu, Ganqu Cui, Taiwen He, Zhiyuan Liu, Tat-Seng Chua, et al. Rlaif-v: Aligning mllms through open-source ai feedback for super gpt-4v trustworthiness.arXiv preprint arXiv:2405.17220, 2024
-
[79]
Token-level direct preference optimization
Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, and Jun Wang. Token-level direct preference optimization. InProceedings of the 41st International Conference on Machine Learning, pages 58348–58365, 2024
2024
-
[80]
Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, and Filip Ilievski. Mllms know where to look: Training-free perception of small visual details with multimodal llms.arXiv preprint arXiv:2502.17422, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.