Consistency as Inductive Bias: Learning Cross-View Invariance for Robust Multimodal Reasoning
Pith reviewed 2026-06-30 06:08 UTC · model grok-4.3
The pith
ConsistRoll injects cross-view consistency into RLVR by jointly rewarding only correct and consistent completions from original and transformed views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cross-view consistency is a missing inductive bias in multimodal large language models: semantically invariant views of the same instance should produce the same answer. ConsistRoll enforces the bias by placing original and transformed views in the same GRPO generation group and assigning a joint reward only when paired completions are both correct and consistent, thereby turning consistency into an online credit-assignment signal without extra overhead or annotations. The method introduces a cross-view correction term absent from standard data augmentation, penalizing view dependence and alleviating advantage collapse.
What carries the argument
ConsistRoll joint-reward assignment inside shared GRPO generation groups for original and semantically invariant transformed views.
If this is right
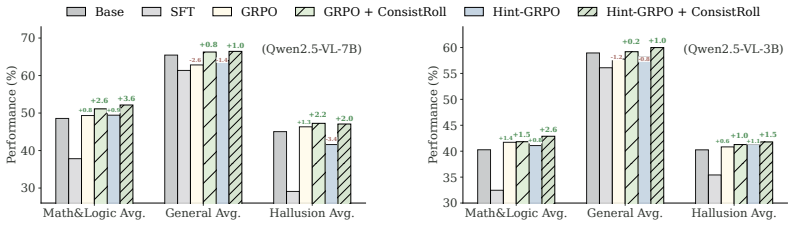
- Robust performance gains appear across math, general-purpose, and hallucination domains in multimodal reasoning.
- A cross-view correction term is added to the advantage that penalizes dependence on any single view.
- Advantage collapse is alleviated during training.
- No additional generation overhead or human annotations are required.
Where Pith is reading between the lines
- The same grouping-and-joint-reward pattern could be applied to other consistency requirements such as temporal or textual invariance.
- The approach may reduce sensitivity to real-world image variations that were not explicitly augmented during training.
- Combining ConsistRoll with other inductive biases could further stabilize long-horizon multimodal reasoning.
Load-bearing premise
That assigning a joint reward only when both original and transformed completions are correct and consistent will reliably enforce cross-view invariance without creating new failure modes.
What would settle it
A direct measurement showing that ConsistRoll-trained models exhibit no higher rate of agreement on held-out transformed views than standard RLVR models trained with independent rewards.
Figures



read the original abstract
Inductive biases steer learning toward generalizable solutions by encoding task structure. In this work, we identify a crucial missing bias in MLLMs: cross-view consistency, \textit{i.e.}, semantically invariant views of the same instance should lead to the same answer. Standard reinforcement learning with verifiable rewards (RLVR) objectives do not impose this constraint, but instead assign pointwise rewards to each visual input. Even with data augmentation (DA), transformed views are typically rewarded independently, providing little signal once within-view rewards saturate. We propose \textbf{ConsistRoll}, a simple but effective method that injects cross-view consistency into RLVR training by reusing the group-sampling mechanism of GRPO. Specifically, ConsistRoll places original and semantically invariant transformed views in the same generation group, and assigns a joint reward only when paired completions are both correct and consistent. In this way, ConsistRoll turns consistency into an online credit-assignment signal, \textbf{without extra generation overhead and annotations}. Theoretically, we show that cross-view consistency is a valid inductive bias, and ConsistRoll introduces a cross-view correction term absent from DA, penalizing view dependence and alleviating advantage collapse. Comprehensive benchmarks across math, general-purpose, hallucination domains confirm that ConsistRoll achieves robust improvements in multimodal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that cross-view consistency is a missing inductive bias in MLLMs under RLVR, and proposes ConsistRoll to enforce it by placing original and semantically invariant transformed views in the same GRPO group and assigning a joint (non-zero) reward only when both completions are correct and consistent. This is said to convert consistency into an online credit-assignment signal without extra generation or annotation cost, to introduce a cross-view correction term absent from standard data augmentation, to alleviate advantage collapse, and to yield robust empirical gains on math, general-purpose, and hallucination benchmarks.
Significance. If the empirical gains are reproducible and the theoretical correction term is correctly derived, the work would supply a lightweight way to inject an invariance bias into existing group-based RLVR pipelines for vision-language models, potentially improving robustness without changing sampling budgets or requiring new labels.
major comments (2)
- [Abstract] Abstract (method description): the joint-reward rule (non-zero advantage only when both views are correct *and* consistent) necessarily lowers the positive-reward rate relative to independent per-view rewards, since P(both correct) < P(at least one correct) under independent sampling noise. No quantification of the resulting reward density, no derivation of how the GRPO advantage estimator behaves under this stricter condition, and no ablation comparing joint vs. independent rewards are supplied, which directly bears on the central claim that the method “turns consistency into an online credit-assignment signal” without introducing new failure modes.
- [Abstract] Abstract (theoretical claim): the statement that ConsistRoll “introduces a cross-view correction term absent from DA, penalizing view dependence and alleviating advantage collapse” is presented without any equation, proof sketch, or explicit comparison to the standard GRPO advantage estimator, preventing verification that the claimed term is non-reducible to quantities already present in data-augmented RLVR.
minor comments (1)
- [Abstract] The abstract supplies no dataset names, model sizes, or numerical results, which makes the empirical claim difficult to assess from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract's method description and theoretical claims. We address each point below, noting revisions to improve verifiability while defending the core contributions based on the full manuscript analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract (method description): the joint-reward rule (non-zero advantage only when both views are correct *and* consistent) necessarily lowers the positive-reward rate relative to independent per-view rewards, since P(both correct) < P(at least one correct) under independent sampling noise. No quantification of the resulting reward density, no derivation of how the GRPO advantage estimator behaves under this stricter condition, and no ablation comparing joint vs. independent rewards are supplied, which directly bears on the central claim that the method “turns consistency into an online credit-assignment signal” without introducing new failure modes.
Authors: We agree the abstract omits explicit quantification of reward density and a derivation of the GRPO advantage estimator under the joint-reward condition. The full manuscript contains an ablation (Section 4.3) comparing joint versus independent rewards, demonstrating that the stricter joint condition improves robustness by filtering inconsistent signals rather than introducing failure modes. We will revise the abstract to include a brief note on reward density and add a short derivation of the advantage estimator behavior to the methods section for completeness. revision: yes
-
Referee: [Abstract] Abstract (theoretical claim): the statement that ConsistRoll “introduces a cross-view correction term absent from DA, penalizing view dependence and alleviating advantage collapse” is presented without any equation, proof sketch, or explicit comparison to the standard GRPO advantage estimator, preventing verification that the claimed term is non-reducible to quantities already present in data-augmented RLVR.
Authors: The full manuscript derives the cross-view correction term in Section 3.2 with an explicit comparison showing it is non-reducible to standard data-augmented GRPO quantities. We acknowledge the abstract presents the claim without the supporting equation or sketch. We will revise the abstract to reference the correction term more precisely and ensure the main text includes a concise proof sketch for easier verification. revision: yes
Circularity Check
No circularity: method reuses existing GRPO mechanism without reducing claims to self-defined inputs
full rationale
The abstract and provided text describe ConsistRoll as placing original/transformed views in the same GRPO group and applying a joint reward only on paired correct+consistent completions. This is presented as an inductive bias injection into standard RLVR, with a claimed theoretical correction term. No equations, fitted parameters, or self-citations are shown that make any prediction equivalent to the input by construction. The derivation chain relies on the external GRPO framework and does not reduce the consistency signal or advantage alleviation to a tautology or renamed fit. This is the common case of an independent methodological contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-view consistency (semantically invariant views should produce the same answer) is a valid inductive bias for multimodal reasoning.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M. Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021. 3, 17
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Xu, and Liang Lin
Jiaqi Chen, Jianheng Tang, Jinghui Qin, Xiaodan Liang, Lingbo Liu, Eric P. Xu, and Liang Lin. GeoQA: A geometric question answering benchmark towards multimodal numerical reasoning. InFindings of the Association for Computational Linguistics (ACL-IJCNLP), pages 513–523, 2021. 10, 16
2021
-
[4]
Group equivariant convolutional networks
Taco Cohen and Max Welling. Group equivariant convolutional networks. InInternational conference on machine learning, pages 2990–2999. PMLR, 2016. 3, 17
2016
-
[5]
Cubuk, Barret Zoph, Dandelion Mané, Vijay Vasudevan, and Quoc V
Ekin D. Cubuk, Barret Zoph, Dandelion Mané, Vijay Vasudevan, and Quoc V . Le. AutoAugment: Learning augmentation strategies from data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 113–123, 2019. 3, 17
2019
-
[6]
Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V
Ekin D. Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V . Le. RandAugment: Practical automated data augmentation with a reduced search space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 702–703, 2020. 3, 17
2020
-
[7]
CHiP: Cross-modal hierarchical direct preference optimization for multimodal LLMs
Jinlan Fu, Shenzhen Huangfu, Hao Fei, Xiaoyu Shen, Bryan Hooi, Xipeng Qiu, and See-Kiong Ng. CHiP: Cross-modal hierarchical direct preference optimization for multimodal LLMs. InInternational Conference on Learning Representations, 2025. 3, 17
2025
-
[8]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020. 17
2020
-
[9]
HallusionBench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. HallusionBench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision an...
2024
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 3, 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Augmix: A simple data processing method to improve robustness and uncertainty
Dan Hendrycks, Norman Mu, Ekin Dogus Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshmi- narayanan. Augmix: A simple data processing method to improve robustness and uncertainty. In International Conference on Learning Representations, 2020. 3, 17
2020
-
[12]
The origins and prevalence of texture bias in convolutional neural networks.Advances in neural information processing systems, 33:19000–19015,
Katherine Hermann, Ting Chen, and Simon Kornblith. The origins and prevalence of texture bias in convolutional neural networks.Advances in neural information processing systems, 33:19000–19015,
-
[13]
Boosting mllm reasoning with text-debiased hint-grpo
Qihan Huang, Weilong Dai, Jinlong Liu, Wanggui He, Hao Jiang, Mingli Song, Jingyuan Chen, Chang Yao, and Jie Song. Boosting mllm reasoning with text-debiased hint-grpo. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4848–4857, 2025. 6, 7, 16, 18
2025
-
[14]
Spotlight on token perception for multimodal reinforcement learning
Siyuan Huang, Xiaoye Qu, Yafu Li, Yun Luo, Zefeng He, Daizong Liu, and Yu Cheng. Spotlight on token perception for multimodal reinforcement learning. InInternational Conference on Learning Representations, 2026. 2
2026
-
[15]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Yao Hu, and Shaohui Lin. Vision-R1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025. 2, 3, 17, 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019. 16
2019
-
[17]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team. Kimi k1.5: Scaling reinforcement learning with LLMs.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Generalization and network design strategies
Yann LeCun. Generalization and network design strategies. In R. Pfeifer, Z. Schreter, F. Fogelman-Soulié, and L. Steels, editors,Connectionism in Perspective. Elsevier, 1989. 2, 3, 17
1989
-
[19]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models.arXiv preprint arXiv:2305.10355, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Zhiqi Li, Guo Chen, Shilong Liu, Shihao Wang, Vibashan VS, Yishen Ji, Shiyi Lan, Hao Zhang, Yilin Zhao, Subhashree Radhakrishnan, et al. Eagle 2: Building post-training data strategies from scratch for frontier vision-language models.arXiv preprint arXiv:2501.14818, 2025. 2
-
[22]
Xiangyan Liu, Jinjie Ni, Zijian Wu, Chao Du, Longxu Dou, Haonan Wang, Tianyu Pang, and Michael Qizhe Shieh. Noisyrollout: Reinforcing visual reasoning with data augmentation.arXiv preprint arXiv:2504.13055, 2025. 2, 3, 18
-
[23]
Mmbench: Is your multi-modal model an all-around player? In European Conference on Computer Vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In European Conference on Computer Vision, pages 216–233. Springer, 2025. 16
2025
-
[24]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-RFT: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025. 1, 2, 3, 17, 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023. 16
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, Ping Luo, Yu Qiao, Qiaosheng Zhang, and Wenqi Shao. Mm- eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning.arXiv preprint arXiv:2503.07365, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Virtual adversarial training: A regularization method for supervised and semi-supervised learning
Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, and Shin Ishii. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. volume 41, pages 1979–1993, 2018. 3, 17
1979
-
[29]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022. 3, 17
2022
-
[30]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, 2023. 17
2023
-
[31]
Hashimoto, and Percy Liang
Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural net- works for group shifts: On the importance of regularization for worst-case generalization. InInternational Conference on Learning Representations (ICLR), 2020. 17
2020
-
[32]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. InarXiv preprint arXiv:1707.06347, 2017. 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 1, 3, 4, 6, 7, 8, 9, 16, 17, 18
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. VLM-R1: A stable and generalizable R1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025. 2, 3, 17, 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Aligning large multimodal models with factually augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang- Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, and Trevor Darrell. Aligning large multimodal models with factually augmented RLHF. InFindings of the Association for Computational Linguistics: ACL, 2024. 3, 17 12
2024
-
[36]
arXiv preprint arXiv:2503.20752 (2025)
Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Minglan Lin, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Reason-RFT: Reinforcement fine-tuning for visual reasoning.arXiv preprint arXiv:2503.20752,
-
[37]
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017. 3, 17
2017
-
[38]
Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen
Fei Wang, Wenxuan Zhou, James Y . Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen. mDPO: Conditional preference optimization for multimodal large language models. InProceedings of the Conference on Empirical Methods in Natural Language Processing, 2024. 3, 17
2024
-
[39]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, and Jitao Sang. AMBER: An LLM-free multi-dimensional benchmark for MLLMs hallucination evaluation.arXiv preprint arXiv:2311.07397, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Perception-aware policy optimization for multimodal reasoning
Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, and Heng Ji. Perception-aware policy optimization for multimodal reasoning. InInternational Conference on Learning Representations, 2026. 2
2026
-
[41]
General E(2)-equivariant steerable CNNs
Maurice Weiler and Gabriele Cesa. General E(2)-equivariant steerable CNNs. InAdvances in Neural Information Processing Systems (NeurIPS), volume 32, 2019. 3, 17
2019
-
[42]
Tong Xiao, Xin Xu, Zhenya Huang, Hongyu Gao, Quan Liu, Qi Liu, and Enhong Chen. Perception-R1: Advancing multimodal reasoning capabilities of MLLMs via visual perception reward.arXiv preprint arXiv:2506.07218, 2025. 3, 17, 18
-
[43]
Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V . Le. Unsupervised data augmenta- tion for consistency training. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6256–6268, 2020. 3, 17
2020
-
[44]
V-DPO: Mitigating hallucination in large vision language models via vision-guided direct preference optimization
Yuxi Xie, Guanzhen Li, Xiao Xu, and Min-Yen Kan. V-DPO: Mitigating hallucination in large vision language models via vision-guided direct preference optimization. InFindings of the Association for Computational Linguistics: EMNLP, 2024. 3, 17
2024
-
[45]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098, 2025. 7, 16
2087
-
[46]
Huanjin Yao, Qixiang Yin, Jingyi Zhang, Min Yang, Yibo Wang, Wenhao Wu, Fei Su, Li Shen, Minghui Qiu, Dacheng Tao, and Jiaxing Huang. R1-ShareVL: Incentivizing reasoning capability of multimodal large language models via share-GRPO.arXiv preprint arXiv:2505.16673, 2025. 2, 3, 17, 18
-
[47]
A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024. 1
2024
-
[48]
RLHF-V: Towards trustworthy MLLMs via behavior alignment from fine-grained correctional human feedback
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, and Tat-Seng Chua. RLHF-V: Towards trustworthy MLLMs via behavior alignment from fine-grained correctional human feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 3, 17
2024
-
[49]
Deep sets.Advances in neural information processing systems, 30, 2017
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexander J Smola. Deep sets.Advances in neural information processing systems, 30, 2017. 2, 3, 17
2017
-
[50]
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-VL: Learning to reason with multimodal large language models via step-wise group relative policy optimization.arXiv preprint arXiv:2503.12937, 2025. 2, 3, 17, 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Lmms-eval: Reality check on the evaluation of large multimodal models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 881–916, 2025. 7, 16
2025
-
[52]
Xingjian Zhang, Siwei Wen, Wenjun Wu, and Lei Huang. Edge-grpo: Entropy-driven grpo with guided error correction for advantage diversity.arXiv preprint arXiv:2507.21848, 2025. 2
-
[53]
Kening Zheng, Junkai Chen, Yibo Yan, Xin Zou, and Xuming Hu. Reefknot: A comprehensive benchmark for relation hallucination evaluation, analysis and mitigation in multimodal large language models.arXiv preprint arXiv:2408.09429, 2024. 17 13
-
[54]
Mitigating modality prior- induced hallucinations in multimodal large language models via deciphering attention causality
Guanyu Zhou, Yibo Yan, Xin Zou, Kun Wang, Aiwei Liu, and Xuming Hu. Mitigating modality prior- induced hallucinations in multimodal large language models via deciphering attention causality. In International Conference on Learning Representations, volume 2025, pages 54415–54439, 2025. 17
2025
-
[55]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019. 3, 17
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[56]
Learning disentangled representations for generalized multi-view clustering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
Xin Zou, Ruimeng Liu, Chang Tang, Zhenglai Li, Xinwang Liu, Kunlun He, and Wanqing Li. Learning disentangled representations for generalized multi-view clustering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026. 17
2026
-
[57]
Dpnet: Dynamic poly-attention network for trustworthy multi-modal classification
Xin Zou, Chang Tang, Xiao Zheng, Zhenglai Li, Xiao He, Shan An, and Xinwang Liu. Dpnet: Dynamic poly-attention network for trustworthy multi-modal classification. InProceedings of the 31st ACM international conference on multimedia, pages 3550–3559, 2023. 17
2023
-
[58]
Xin Zou, Yizhou Wang, Yibo Yan, Sirui Huang, Kening Zheng, Junkai Chen, Chang Tang, and Xuming Hu. Look twice before you answer: Memory-space visual retracing for hallucination mitigation in multimodal large language models.arXiv preprint arXiv:2410.03577, 2024. 17 14 Contents of Technical Appendices A Detailed Experiment Settings 16 A.1 Training Setup . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.