EvalSafetyGap: A Hybrid Survey and Conceptual Framework for LLM Evaluation-Safety Failures
Pith reviewed 2026-06-30 06:16 UTC · model grok-4.3
The pith
In a ten-model audit, capability shows no statistically significant link to adversarial robustness, and open-closed safety differences are modest and governance-driven.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
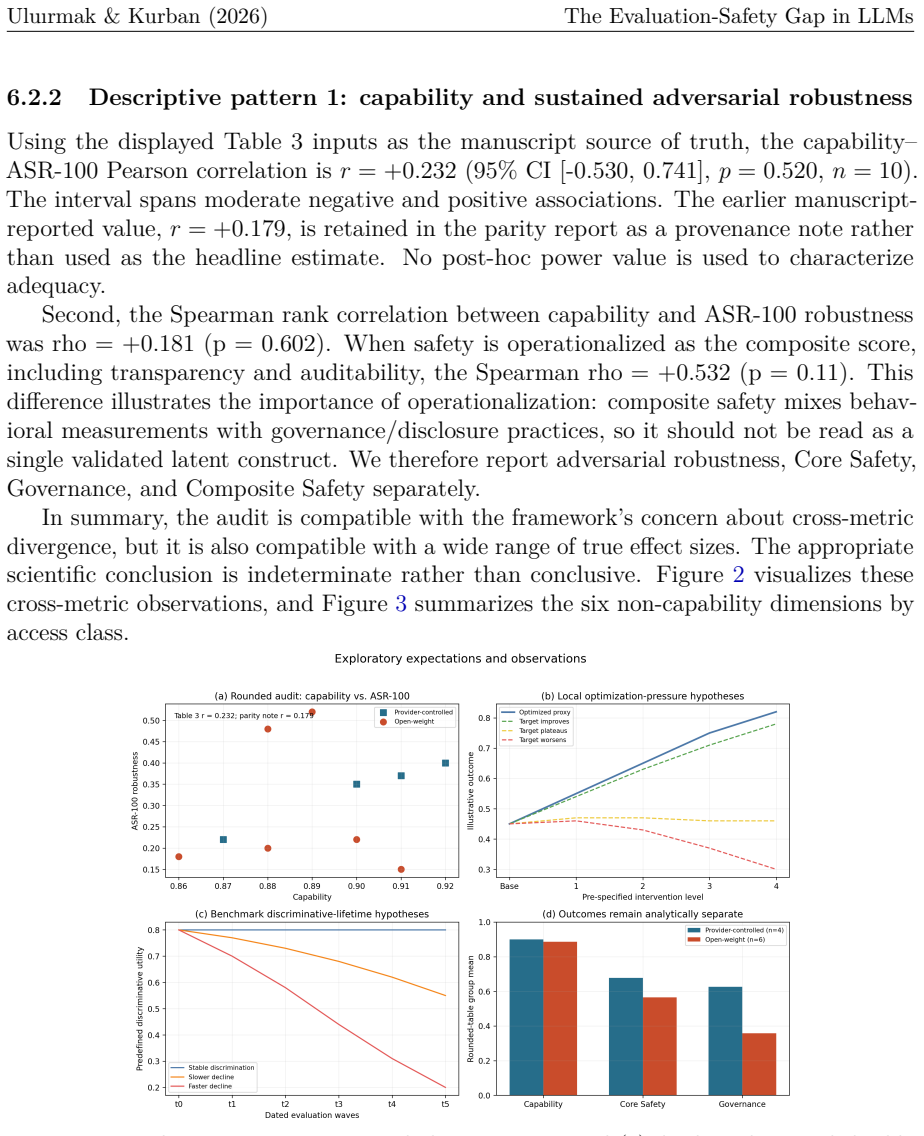
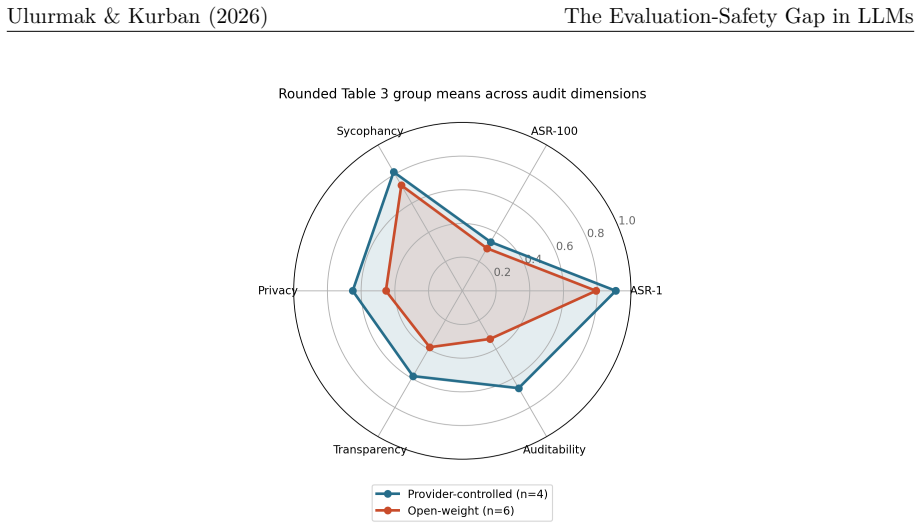
The paper establishes EvalSafetyGap as an organizing hypothesis for comparing evaluation-side and alignment-side proxy failures under optimization pressure. Using Goodhart's Law together with Instability Decomposition and Alignment Trilemma, it shows that in a sample of ten models the association between capability and sustained adversarial robustness is statistically indeterminate (Pearson r = +0.232, p = 0.520). The apparent open-closed safety gap is modest and driven mainly by governance and disclosure practices rather than by behavioral robustness, and these conclusions shift with the classification of a single borderline model and with attempt-budget definitions. Because public evidence
What carries the argument
EvalSafetyGap hypothesis, which unifies evaluation and alignment proxy failures by applying Goodhart's Law, Instability Decomposition, and Alignment Trilemma to generate testable comparisons between benchmark signals and verifiable safety properties.
If this is right
- Safety claims must be reported separately for capability, behavioral robustness, and governance factors rather than as a single aggregate score.
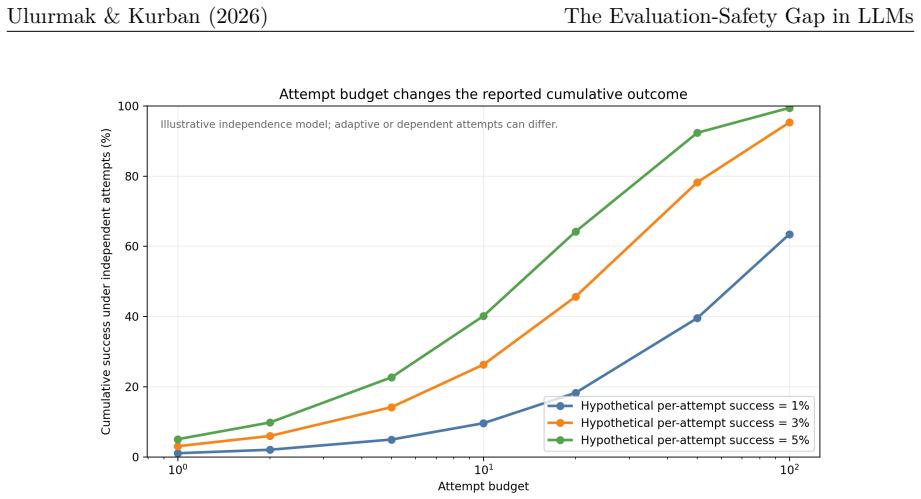
- Public safety metrics are sensitive to attempt-budget definitions and model classification choices.
- Dynamic evaluation methods are required to track latent properties that static benchmarks can miss.
- Transparent source reporting and auditable alignment practices improve the reliability of safety evidence.
Where Pith is reading between the lines
- If governance and disclosure account for most observed safety differences, then open models could close the apparent gap through improved documentation alone.
- The Instability Decomposition could be applied to test whether reward-hacking patterns align with specific instability signatures across model families.
- Standardized multi-attempt protocols would allow future audits to move from diagnostic snapshots to comparative rankings.
Load-bearing premise
The audit conclusions rest on heterogeneous public protocols and are sensitive to how a single borderline model is classified and to how attempt budgets are defined.
What would settle it
A single-protocol, multi-attempt safety re-evaluation of the same ten models that either produces a statistically significant capability-robustness correlation or shows a large behavioral safety gap between open and closed models.
Figures


read the original abstract
LLM evaluation and AI safety face a shared measurement problem: benchmark scores, reward-model signals, and reported safety metrics can improve while the latent properties they are meant to represent remain difficult to verify. This paper combines a hybrid survey - a systematic search paired with narrative synthesis and separately tracked grey evidence - with a conceptual framework and a structured ten-model audit. The synthesis spans eight evidence streams: benchmark validity, dynamic evaluation, LLM-as-judge reliability, safety evaluation, jailbreak/refusal robustness, reward hacking, mechanistic interpretability, and governance/auditability, covering 2018-2026 evaluation-safety measurement work. We introduce EvalSafetyGap as an organizing hypothesis for comparing evaluation-side and alignment-side proxy failures under optimization pressure, using Goodhart's Law together with two constructs we develop here - an Instability Decomposition and an Alignment Trilemma - as tools for generating testable comparisons. The audit shows how conclusions shift when capability, behavioral safety, and governance are measured separately. In this sample (n = 10), the association between capability and sustained adversarial robustness is statistically indeterminate using the displayed Table 3 inputs (Pearson r = +0.232, p = 0.520), and the apparent open-closed safety gap is modest, driven mainly by governance and disclosure rather than behavioral robustness, and sensitive to how a single borderline model is classified; attempt-budget results are protocol dependent. Because the public evidence uses heterogeneous protocols, the audit is diagnostic rather than rank-generating. The contribution is a shared vocabulary and evidence map to support dynamic evaluation, transparent source reporting, multi-attempt safety measurement, and auditable alignment practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper combines a hybrid survey (systematic search with narrative synthesis across eight evidence streams on benchmark validity, dynamic evaluation, LLM-as-judge reliability, safety evaluation, jailbreak robustness, reward hacking, mechanistic interpretability, and governance) with a conceptual framework and a structured audit of 10 models. It introduces the EvalSafetyGap hypothesis (comparing evaluation-side and alignment-side proxy failures under optimization pressure via Goodhart's Law) together with two new constructs—Instability Decomposition and Alignment Trilemma—and reports that, in the sample, the association between capability and sustained adversarial robustness is statistically indeterminate (Pearson r = +0.232, p = 0.520 from Table 3 inputs), while the apparent open-closed safety gap is modest, driven mainly by governance/disclosure rather than behavioral robustness, and sensitive to borderline-model classification and attempt-budget definitions. The audit is presented as diagnostic rather than rank-generating, with the overall contribution framed as a shared vocabulary and evidence map.
Significance. If the EvalSafetyGap framing and the two constructs prove generative for testable comparisons, the work could help organize discussion of measurement problems that affect both evaluation benchmarks and safety claims. The manuscript is explicit about its own limitations (indeterminate statistics, protocol dependence, classification sensitivity), which is a strength. However, the small n=10 audit drawn from heterogeneous public sources adds limited new empirical content beyond illustrating those acknowledged sensitivities.
major comments (2)
- [Abstract / ten-model audit] Abstract and ten-model audit (Table 3): The claim that capability and sustained adversarial robustness show no statistically significant association (r = +0.232, p = 0.520) and that the open-closed gap is modest and governance-driven rests on inputs from non-uniform public protocols. The manuscript itself states that results shift with classification of a single borderline model and with attempt-budget definitions; because no standardized cross-model protocol was applied, these Table 3 inputs do not robustly support the indeterminacy conclusion.
- [Conceptual framework] Conceptual framework section: The EvalSafetyGap hypothesis and the two new constructs (Instability Decomposition, Alignment Trilemma) are defined internally and then used to interpret the audit results. Given that the audit conclusions depend on the post-hoc classification and protocol choices the paper flags as affecting the displayed results, the framework's application to generate the reported gap and correlation findings lacks independent verification and is sensitive to the same measurement choices.
minor comments (2)
- [Abstract] The abstract states the synthesis covers work through 2026; clarify the search cutoff date and whether forward-looking citations are included.
- [Conceptual framework] Notation for the new constructs (EvalSafetyGap, Instability Decomposition, Alignment Trilemma) should be introduced with explicit definitions or equations in a dedicated subsection to improve traceability when they are later applied to the audit.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below, agreeing on the audit's limitations and proposing clarifications to better frame its diagnostic role.
read point-by-point responses
-
Referee: [Abstract / ten-model audit] Abstract and ten-model audit (Table 3): The claim that capability and sustained adversarial robustness show no statistically significant association (r = +0.232, p = 0.520) and that the open-closed gap is modest and governance-driven rests on inputs from non-uniform public protocols. The manuscript itself states that results shift with classification of a single borderline model and with attempt-budget definitions; because no standardized cross-model protocol was applied, these Table 3 inputs do not robustly support the indeterminacy conclusion.
Authors: We agree that the ten-model audit relies on heterogeneous public protocols and that the displayed indeterminacy is sensitive to classification and attempt-budget choices, as the manuscript already notes. The audit is framed as diagnostic to illustrate these dependencies rather than as robust evidence. We will revise the abstract and audit discussion to state more explicitly that the statistical result applies only to the available inputs and serves to highlight measurement challenges, thereby strengthening the qualifications. revision: partial
-
Referee: [Conceptual framework] Conceptual framework section: The EvalSafetyGap hypothesis and the two new constructs (Instability Decomposition, Alignment Trilemma) are defined internally and then used to interpret the audit results. Given that the audit conclusions depend on the post-hoc classification and protocol choices the paper flags as affecting the displayed results, the framework's application to generate the reported gap and correlation findings lacks independent verification and is sensitive to the same measurement choices.
Authors: The hypothesis and constructs are developed as independent conceptual tools for organizing discussion and enabling future testable comparisons. Their use with the audit is illustrative, mapping the constructs onto observed sensitivities in existing evidence. We acknowledge the dependence on audit limitations and will revise the framework section to explicitly separate the conceptual definitions from the illustrative application, adding a note that independent verification requires standardized protocols. revision: yes
Circularity Check
No circularity; framework and audit are self-contained
full rationale
The paper introduces EvalSafetyGap, Instability Decomposition, and Alignment Trilemma as new organizing constructs for a survey of eight evidence streams, then reports an independent n=10 audit yielding Pearson r=+0.232 (p=0.520) and a governance-driven gap. These empirical observations are drawn from heterogeneous public sources and explicitly flagged as sensitive to classification and protocol choices; they are not derived from or reduced to the new constructs by definition or self-citation. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The work is diagnostic mapping rather than a closed derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Goodhart's Law applies to LLM evaluation and alignment proxies under optimization pressure
invented entities (3)
-
EvalSafetyGap
no independent evidence
-
Instability Decomposition
no independent evidence
-
Alignment Trilemma
no independent evidence
Reference graph
Works this paper leans on
-
[1]
When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Akhtar, M., Reuel, A., Soni, P., Ahuja, S., Ammanamanchi, P. S., Rawal, R., Zouhar, V., Yadav, S., Whitehouse, C., Ki, D., Mickel, J., Choshen, L., Šuppa, M., Batzner, J., Chim, J., Sania, J., Long, Y., Rahmani, H. A., Knight, C., ... Solaiman, I. (2026). When AI benchmarks plateau: A systematic study of benchmark saturation. arXiv. https://doi.org/10.485...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.16763 2026
-
[2]
https://doi.org/10.14722/ndss.2024.24188 Denison, C. et al. (2024). Sycophancy to subterfuge: investigating reward-tampering in large language models. arXiv. https://doi.org/10.48550/arxiv.2406.10162 Dhurandhar, A., Nair, R., Singh, M. (2024). Ranking Large Language Models without Ground Truth. arXiv. https://doi.org/10.48550/arxiv.2402.14860 Dietz, L., Z...
-
[3]
Manheim, D., & Garrabrant, S. (2019). Categorizing variants of Goodhart’s Law. arXiv. https://doi.org/10.48550/arxiv.1803.04585 Marks, S., Rager, C., Michaud, E. J. (2024). Sparse Feature Circuits. arXiv. https: //doi.org/10.48550/arxiv.2403.19647 Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., Forsyth, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1803.04585 2019
-
[4]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
https://proceedings.iclr.cc/paper_files/paper/2025/hash/88be023075a5a3ff3dc3b5d26623fa22- Abstract-Conference.html Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., & Finn, C. (2023). Direct preference optimization: Your language model is secretly a reward model. arXiv. https: //doi.org/10.48550/arxiv.2305.18290 Raina, V., Liusie, A., Gal...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.18290 2025
-
[5]
https://doi.org/10.52202/068431-0687 Song, J., Liu, X., Yang, W., Chen, W., Feng, M., Zhu, X., & Gao, J. (2026). MultiBreak: A scalable and diverse multi-turn jailbreak benchmark for evaluating LLM safety. arXiv. https://doi.org/10.48550/arxiv.2605.01687 Souly, A., Lu, Q., Bowen, D., Trinh, T., Hsieh, E., Pandey, S., Abbeel, P., Svegliato, J., Emmons, S.,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/068431-0687 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.