Understanding Censorship in Large Language Models: From Mechanisms to Governance
Pith reviewed 2026-07-01 06:59 UTC · model grok-4.3
The pith
LLM censorship operates through data curation, alignment, policies and regulation, shifting focus from whether to moderate to how to do so accountably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
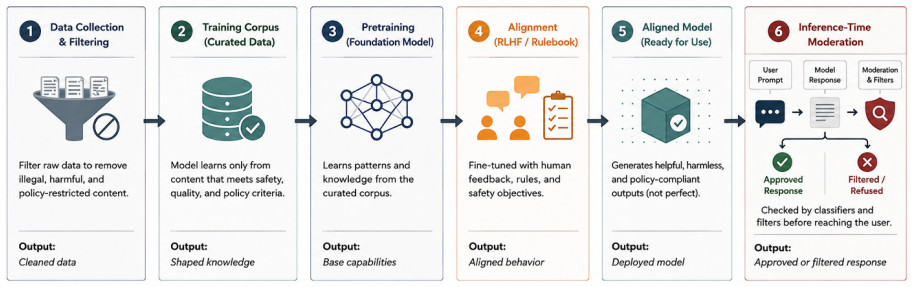
LLM censorship emerges as a sociotechnical phenomenon that extends beyond explicit refusals to include omissions, selective emphasis, framing effects, and geographically variable content controls shaped by training-data curation, alignment procedures, provider policies, inference-time moderation, and jurisdictional regulation; the analysis identifies the tension between safety and openness, the difficulty of measuring soft censorship, geopolitical divergence of regimes, and the requirement for transparent, contestable, and independently auditable governance mechanisms.
What carries the argument
Layered censorship mechanisms across the LLM lifecycle, including training-data curation, alignment, provider policies, inference-time moderation and jurisdictional regulation, that produce both hard refusals and softer effects like framing and omissions.
If this is right
- Geopolitical divergence will produce different content availability and framing depending on the jurisdiction governing each model.
- New auditing methods will be required to detect and quantify soft censorship beyond simple refusal rates.
- Governance must prioritize contestable and independently auditable mechanisms to limit opaque control over information access.
- Mitigation strategies must address the full lifecycle rather than isolated stages such as inference-time filters alone.
Where Pith is reading between the lines
- If governance remains provider-controlled, users may migrate toward decentralized or open models to regain access to contested topics.
- Pluralistic moderation could require standardized public benchmarks for measuring framing effects across providers.
- The same mechanisms that enable safety filtering also create opportunities for targeted narrative shaping by state or corporate actors.
Load-bearing premise
The selected empirical studies, provider case studies, regulatory developments, auditing methods, and mitigation strategies provide a sufficiently representative and unbiased picture of censorship mechanisms across the model lifecycle and different jurisdictions.
What would settle it
A systematic cross-jurisdictional audit of identical prompts on multiple LLMs that finds no measurable differences in omissions, framing, or selective responses traceable to provider policies, alignment choices, or regulatory environments.
Figures

read the original abstract
Large language models (LLMs) increasingly mediate access to information, yet their responses are shaped by training-data curation, alignment procedures, provider policies, inference-time moderation, and jurisdictional regulation. This paper examines LLM censorship as a sociotechnical phenomenon that extends beyond explicit refusals to include omissions, selective emphasis, framing effects, and geographically variable content controls. We synthesize recent empirical studies, provider case studies, regulatory developments, auditing methods, and mitigation strategies to clarify how censorship-like behavior emerges across the model lifecycle. The analysis highlights the tension between safety and openness, the difficulty of measuring soft censorship, the geopolitical divergence of moderation regimes, and the need for transparent, contestable, and independently auditable governance mechanisms. We argue that the central challenge is not whether LLMs should moderate content, but how moderation can be made proportionate, accountable, pluralistic, and resistant to opaque epistemic control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript synthesizes empirical studies, provider case studies, regulatory developments, auditing methods, and mitigation strategies to analyze LLM censorship as a sociotechnical phenomenon spanning training-data curation, alignment, inference-time moderation, and jurisdictional regulation. It examines tensions between safety and openness, challenges in measuring soft censorship and framing effects, geopolitical divergences in moderation regimes, and concludes that the central governance challenge is rendering moderation proportionate, accountable, pluralistic, and resistant to opaque epistemic control.
Significance. If the underlying synthesis is representative, the paper supplies a structured normative framing that could usefully orient technical auditing research and policy discussions on AI content governance, moving beyond binary safety-versus-openness debates toward concrete criteria for contestability and independent auditability.
major comments (1)
- [Abstract] Abstract: The description of the synthesis provides no detail on study selection criteria, search strategy, inclusion/exclusion rules, or reconciliation of conflicting findings. This omission is load-bearing for any literature-review claim, as it prevents evaluation of selection bias or completeness.
Simulated Author's Rebuttal
We thank the referee for this constructive observation on the abstract. We agree that greater transparency regarding the synthesis approach is warranted and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The description of the synthesis provides no detail on study selection criteria, search strategy, inclusion/exclusion rules, or reconciliation of conflicting findings. This omission is load-bearing for any literature-review claim, as it prevents evaluation of selection bias or completeness.
Authors: We agree that the abstract does not provide these methodological details. The manuscript offers a narrative synthesis of selected empirical studies, case analyses, regulatory documents, and auditing literature rather than a systematic review following formal protocols such as PRISMA. To address the concern, we will revise the abstract to state explicitly that the synthesis draws on prominent recent sources identified through targeted searches and domain expertise. We will also add a short 'Scope and Approach' subsection early in the introduction that outlines the rationale for source selection, the handling of conflicting findings, and the primarily conceptual rather than exhaustive nature of the review. These changes will be incorporated in the revised manuscript. revision: yes
Circularity Check
No significant circularity in literature synthesis
full rationale
This paper is a review article that synthesizes external empirical studies, case studies, regulatory developments, auditing methods, and mitigation strategies without presenting new mathematical derivations, equations, fitted parameters, or formal proofs. Its central normative claim about governance priorities is framed as emerging from the cited literature rather than reducing to any self-defined quantities or self-citation chains within the paper. No load-bearing step equates a prediction or result to its own inputs by construction, satisfying the criteria for a self-contained synthesis with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Holistic evaluation of language models.Transactions on Machine Learning Research, 2023
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models.Transactions on Machine Learning Research, 2023
2023
-
[3]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pages 610–623. ACM, 2021
2021
-
[4]
Algorithmic content moderation: Technical and political challenges in the automation of platform governance.Big Data & Society, 7(1):2053951719897945, 2020
Robert Gorwa, Reuben Binns, and Christian Katzenbach. Algorithmic content moderation: Technical and political challenges in the automation of platform governance.Big Data & Society, 7(1):2053951719897945, 2020
2020
-
[5]
Taxonomy of risks posed by language models
Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, Courtney Biles, Sasha Brown, Zac Kenton, Will Hawkins, Tom Stepleton, Abeba Birhane, Lisa Anne Hendricks, Laura Rimell, William Isaac, Julia Haas, Sean Legassick, Geoffrey Irving, and Iason Gabriel. Taxonomy...
2022
-
[6]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
2022
-
[7]
What large language models do not talk about: An empirical study of moderation and censorship practices
Sander Noels, Guillaume Bied, Maarten Buyl, Alexander Rogiers, Yousra Fettach, Jefrey Lijffijt, and Tijl De Bie. What large language models do not talk about: An empirical study of moderation and censorship practices. In Machine Learning and Knowledge Discovery in Databases. Research Track, volume 16013 ofLecture Notes in Computer Science, pages 265–281. ...
2026
-
[8]
An analysis of chinese censorship bias in LLMs
Mohamed Ahmed, Jeffrey Knockel, and Rachel Greenstadt. An analysis of chinese censorship bias in LLMs. Proceedings on Privacy Enhancing Technologies, 2025(4):112–129, 2025
2025
-
[9]
Documenting large webtext corpora: A case study on the colossal clean crawled corpus
Jesse Dodge, Maarten Sap, Ana Marasovi´c, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. Documenting large webtext corpora: A case study on the colossal clean crawled corpus. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 1286–1305. Association for Computational Lingu...
2021
-
[10]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
2021
-
[11]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Deep Ganguli, Tom Henighan, Nicholas Joseph, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Open problems and fundamental limitations of reinforcement learning from human feedback.Transactions on Machine Learning Research, 2023
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. Open problems and fundamental limitations of reinforcement learning from human feedback.Transactions on Machine Learning Research, 2023
2023
-
[13]
Characterizing the implementation of censorship policies in chinese LLM services
Anna Ablove, Shreyas Chandrashekaran, Xiao Qiang, and Roya Ensafi. Characterizing the implementation of censorship policies in chinese LLM services. InProceedings of the Network and Distributed System Security Symposium, 2026
2026
-
[14]
Westwood, Justin Grimmer, and Andrew B
Sean J. Westwood, Justin Grimmer, and Andrew B. Hall. Measuring perceived slant in large language models through user evaluations. Technical report, Hoover Institution and Stanford University, May 2025
2025
-
[15]
V oelkel, Shane Muldowney, Johannes C
Hui Bai, Jan G. V oelkel, Shane Muldowney, Johannes C. Eichstaedt, and Robb Willer. LLM-generated messages can persuade humans on policy issues.Nature Communications, 16:6037, 2025
2025
- [16]
-
[17]
Language (technology) is power: A critical survey of Bias in NLP
Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach. Language (technology) is power: A critical survey of Bias in NLP. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5454–5476. Association for Computational Linguistics, 2020
2020
-
[18]
Foundations of cyber resilience: The confluence of game, control, and learning theories
Quanyan Zhu. Foundations of cyber resilience: The confluence of game, control, and learning theories. In Igor Linkov and Alexander Kott, editors,Cyber Resilience: Applied Perspectives, Risk, Systems and Decisions, pages 27–58. Springer Cham, 2025
2025
-
[19]
A game-theoretic approach to design secure and resilient distributed support vector machines.IEEE Transactions on Neural Networks and Learning Systems, 29(11):5512–5527, 2018
Rui Zhang and Quanyan Zhu. A game-theoretic approach to design secure and resilient distributed support vector machines.IEEE Transactions on Neural Networks and Learning Systems, 29(11):5512–5527, 2018
2018
-
[20]
Translation: Measures for the management of generative artificial intelligence services (draft for comment) – april 2023
Seaton Huang, Helen Toner, Zac Haluza, Rogier Creemers, and Graham Webster. Translation: Measures for the management of generative artificial intelligence services (draft for comment) – april 2023. DigiChina, Stanford University, 2023
2023
-
[21]
Inside-out: Hidden factual knowledge in LLMs
Zorik Gekhman, Eyal Ben David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart. Inside-out: Hidden factual knowledge in LLMs. InProceedings of the Second Conference on Language Modeling, 2025
2025
-
[22]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Nicholas Schiefer, Thomas I. Liao, Nicholas Joseph, Nova DasSarma, Tom Henighan, Andy Jones, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369. Association for Computational Linguistics, 2020
2020
-
[24]
Meta’s ai rules have let bots hold ‘sensual’ chats with kids, offer false medical info
Jeff Horwitz. Meta’s ai rules have let bots hold ‘sensual’ chats with kids, offer false medical info. Reuters Investigates, August 2025
2025
-
[25]
Lama Ahmad, Sandhini Agarwal, Michael Lampe, and Pamela Mishkin. Openai’s approach to external red teaming for AI models and systems.arXiv preprint arXiv:2503.16431, 2025
-
[26]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models.arXiv preprint arXiv:2202.03286, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Novel universal bypass for all major LLMs
Conor McCauley, Kenneth Yeung, Jason Martin, and Kasimir Schulz. Novel universal bypass for all major LLMs. HiddenLayer Research Blog, April 2025
2025
-
[28]
Jailbroken: How Does LLM Safety Training Fail?
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail?arXiv preprint arXiv:2307.02483, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Political censorship in large language models originating from china.PNAS Nexus, 5(2):pgag013, 2026
Jennifer Pan and Xu Xu. Political censorship in large language models originating from china.PNAS Nexus, 5(2):pgag013, 2026. 18
2026
-
[31]
Regulation (EU) 2022/2065 on a single market for digital services and amending directive 2000/31/EC (digital services act)
European Parliament and Council of the European Union. Regulation (EU) 2022/2065 on a single market for digital services and amending directive 2000/31/EC (digital services act). https://eur-lex.europa.eu/eli/ reg/2022/2065/oj, 2022
2022
-
[32]
Online safety act 2023
UK Parliament. Online safety act 2023. https://www.legislation.gov.uk/ukpga/2023/50/contents, 2023
2023
-
[33]
Artificial intelligence risk management framework (AI RMF 1.0)
National Institute of Standards and Technology. Artificial intelligence risk management framework (AI RMF 1.0). Technical Report NIST AI 100-1, National Institute of Standards and Technology, 2023
2023
-
[34]
A pro-innovation approach to AI regulation
UK Department for Science, Innovation and Technology. A pro-innovation approach to AI regulation. https://www.gov.uk/government/publications/ai-regulation-a-pro-innovation-approach/ white-paper, 2023. Command Paper 815
2023
-
[35]
Executive order 14110: Safe, secure, and trustworthy development and use of artificial intelligence
Executive Office of the President of the United States. Executive order 14110: Safe, secure, and trustworthy development and use of artificial intelligence. https://www.govinfo.gov/app/details/DCPD-202300949, October 2023
2023
-
[36]
Executive order on safe, secure, and trustworthy artificial intelligence
National Institute of Standards and Technology. Executive order on safe, secure, and trustworthy artificial intelligence. https://www.nist.gov/artificial-intelligence/ executive-order-safe-secure-and-trustworthy-artificial-intelligence , 2025. Notes rescission of Executive Order 14110 on January 20, 2025
2025
-
[37]
47 U.S.C
United States Code. 47 U.S.C. § 230: Protection for private blocking and screening of offensive material. https://www.law.cornell.edu/uscode/text/47/230, 1996. Accessed June 16, 2026
1996
-
[38]
Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (artificial intelligence act)
European Parliament and Council of the European Union. Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (artificial intelligence act). https://eur-lex.europa.eu/eli/reg/2024/ 1689/oj/eng, 2024
2024
-
[39]
Provisions on the administration of deep synthesis internet information services
Cyberspace Administration of China. Provisions on the administration of deep synthesis internet information services. http://www.cac.gov.cn/2022-12/11/c_1672221949354811.htm, 2022. Issued November 25, 2022; effective January 10, 2023
2022
-
[40]
White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes
Inioluwa Deborah Raji, Andrew Smart, Rebecca N. White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes. Closing the ai accountability gap: Defining an end-to-end framework for internal algorithmic auditing. InProceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pages 33–44, 2020
2020
-
[41]
Co-auditing: A method for measuring, evaluating, and improving ai systems.Proceedings of the ACM on Human-Computer Interaction, 6(CSCW2):1–35, 2022
Michael Madaio, Luke Stark, Jennifer Wortman Vaughan, and Hanna Wallach. Co-auditing: A method for measuring, evaluating, and improving ai systems.Proceedings of the ACM on Human-Computer Interaction, 6(CSCW2):1–35, 2022
2022
-
[42]
arXiv preprint arXiv:2508.09224 , year=
Yuan Yuan, Tina Sriskandarajah, Anna-Luisa Brakman, Alec Helyar, Alex Beutel, Andrea Vallone, and Saachi Jain. From hard refusals to safe-completions: Toward output-centric safety training.arXiv preprint arXiv:2508.09224, 2025
-
[43]
The state and fate of linguistic diversity and inclusion in the NLP world
Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. The state and fate of linguistic diversity and inclusion in the NLP world. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6282–6293. Association for Computational Linguistics, 2020
2020
-
[44]
Game theory for cyber deception: A tutorial
Quanyan Zhu. Game theory for cyber deception: A tutorial. InProceedings of the 2019 Symposium and Bootcamp on the Science of Security, pages 8:1–8:3, 2019
2019
-
[45]
A game-theoretic taxonomy and survey of defensive deception for cybersecurity and privacy.ACM Computing Surveys, 52(4):82:1–82:28, 2019
Jeffrey Pawlick, Edward Colbert, and Quanyan Zhu. A game-theoretic taxonomy and survey of defensive deception for cybersecurity and privacy.ACM Computing Surveys, 52(4):82:1–82:28, 2019
2019
-
[46]
Yunfei Ge and Quanyan Zhu. The game-theoretic symbiosis of trust and AI in networked systems.arXiv preprint arXiv:2411.12859, 2024
-
[47]
Model cards for model reporting
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. InProceedings of the Conference on Fairness, Accountability, and Transparency, pages 220–229. ACM, 2019
2019
-
[48]
Claude’s constitution
Anthropic. Claude’s constitution. https://www.anthropic.com/constitution, 2026. Accessed June 8, 2026
2026
-
[49]
Quanyan Zhu. The doctrine of cyber effect: An ethics framework for defensive cyber deception.arXiv preprint arXiv:2302.13362, 2023
-
[50]
Algorithmic gatekeepers: The human rights impacts of LLM content moderation
European Center for Not-for-Profit Law. Algorithmic gatekeepers: The human rights impacts of LLM content moderation. Technical report, European Center for Not-for-Profit Law, 2025. 19
2025
-
[51]
A Roadmap to Pluralistic Alignment
Taylor Sorensen, Jared Moore, Jillian Fisher, Mitchell Gordon, Niloofar Mireshghallah, Christopher Michael Rytting, Andre Ye, Liwei Jiang, Ximing Lu, Nouha Dziri, Tim Althoff, and Yejin Choi. A roadmap to pluralistic alignment.arXiv preprint arXiv:2402.05070, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Quanyan Zhu. Game theory meets LLM and agentic AI: Reimagining cybersecurity for the age of intelligent threats.arXiv preprint arXiv:2507.10621, 2025
-
[53]
Ya-Ting Yang and Quanyan Zhu. Internet of agentic AI: Incentive-compatible distributed teaming and workflow. arXiv preprint arXiv:2602.03145, 2026
-
[54]
Ya-Ting Yang and Quanyan Zhu. PACT: A contract-theoretic framework for pricing agentic AI services powered by large language models.arXiv preprint arXiv:2505.21286, 2025
-
[55]
Quanyan Zhu. Insurance of agentic AI.arXiv preprint arXiv:2606.05449, 2026. 20
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.