Using AI Agents to Automate Black-Box Audits of Personalization Algorithms at Scale
Pith reviewed 2026-07-01 02:18 UTC · model grok-4.3
The pith
Generative AI agents with fixed personas enable black-box counterfactual audits of how platforms personalize content by perturbing user attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
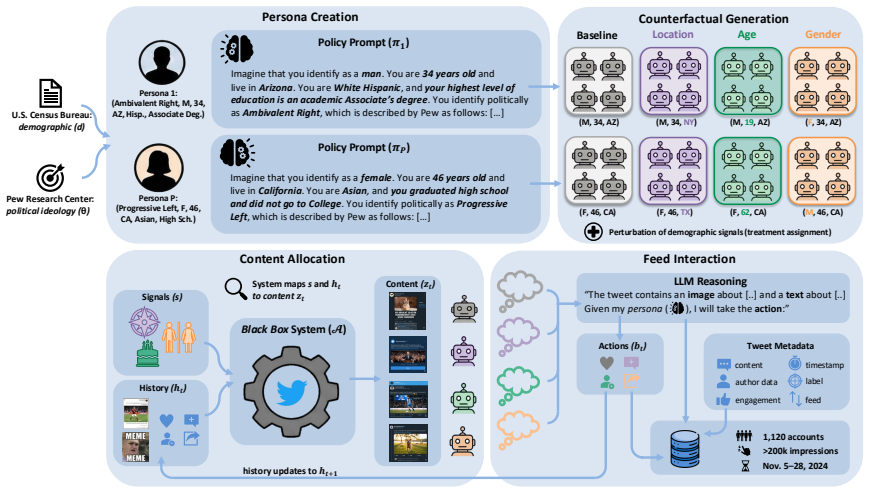
We introduce a framework for black-box audits of personalization algorithms using generative AI agents as behavioral engines for synthetic accounts. Each agent is instantiated with a fixed persona, grounded in demographic and political survey data, and interacts with a platform's content by reasoning about it and choosing actions. Because behavior is fixed within each persona while platform-visible signals such as age, gender, or location can be experimentally perturbed, our design enables counterfactual auditing of how platforms respond to user attributes. As a case study, we deploy 1,120 agents on X shortly after the 2024 U.S. election, spanning 14 personas and three counterfactual conditi
What carries the argument
Generative AI agents instantiated with fixed personas grounded in survey data, used as behavioral engines that keep interaction behavior constant while allowing experimental perturbation of platform-visible attributes.
If this is right
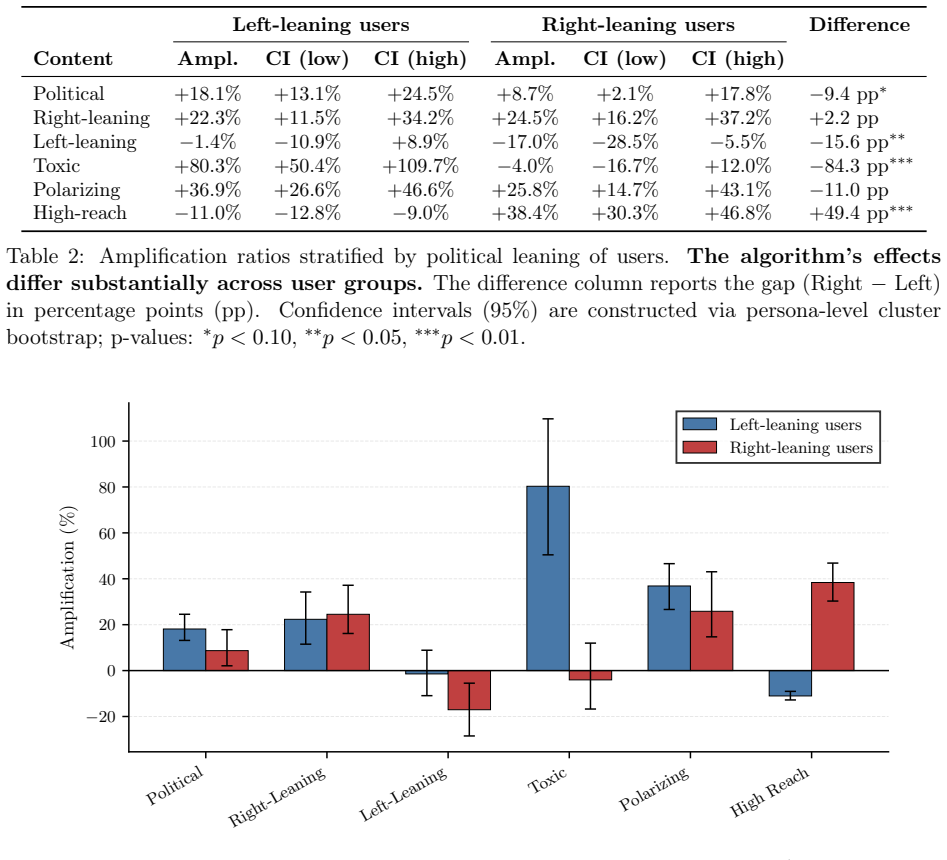
- X's algorithmic feed amplifies toxic, polarizing, political, and right-leaning content more than its chronological feed.
- The size of this amplification varies sharply according to the ideology of the persona.
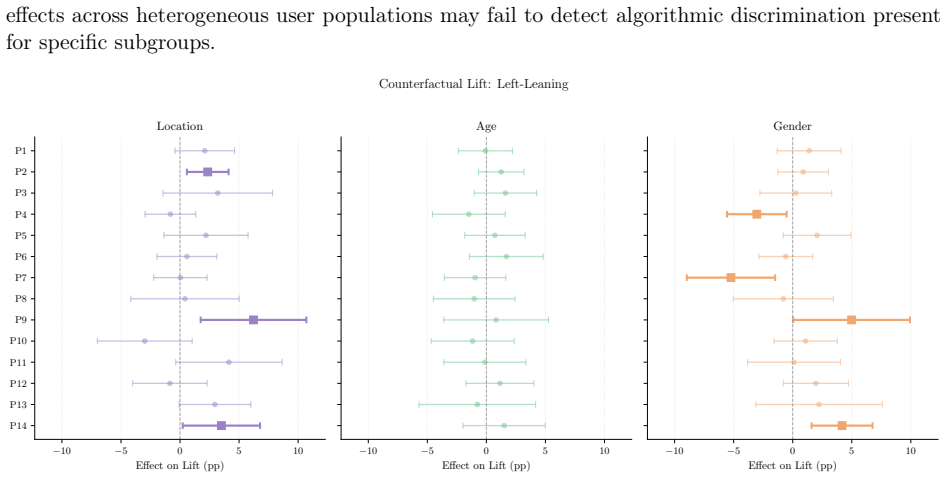
- Changing demographic signals alters the content delivered, but the direction and magnitude of the change depends on the specific persona.
- When results are pooled across personas, demographic effects appear largely null even though subgroup effects are heterogeneous.
Where Pith is reading between the lines
- The same agent design could be used to audit personalization on other platforms where black-box access is the only option.
- Extending agent interaction histories over weeks or months would test whether the framework still supports causal claims once behavioral trajectories diverge.
- If the agents' exposure patterns can be validated against real-user data, independent researchers could run large-scale audits without recruiting human participants.
Load-bearing premise
The generative AI agents produce behavior realistic and stable enough that changes in their visible attributes produce content patterns that reflect genuine platform personalization responses.
What would settle it
A side-by-side test in which real users with matching personas and the same attribute perturbations receive substantially different content distributions than the AI agents on the same platform.
Figures
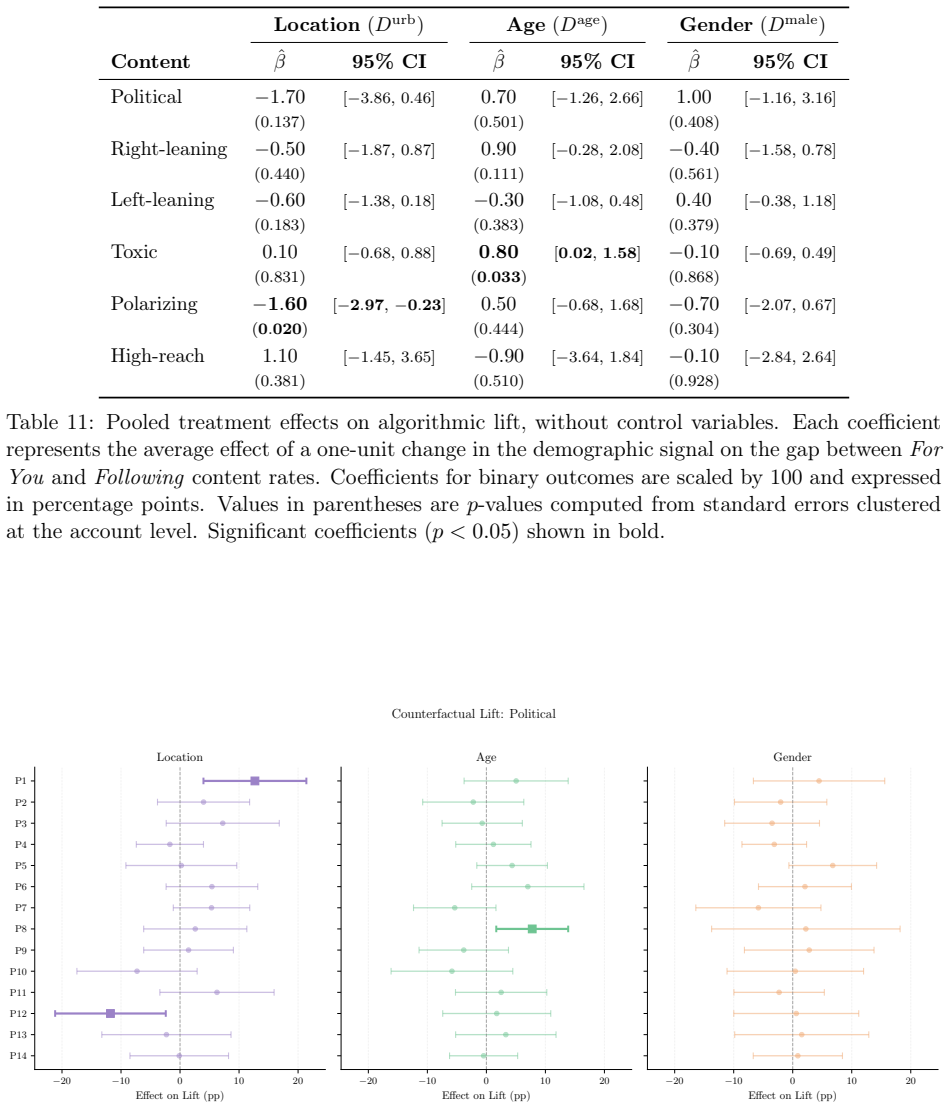
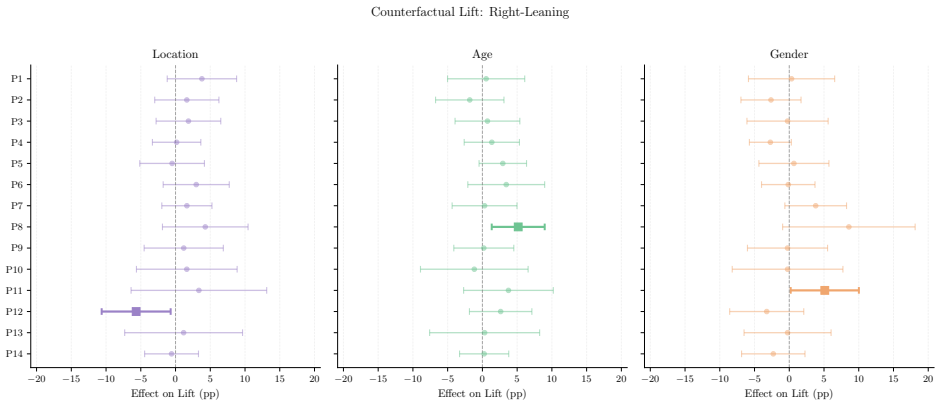
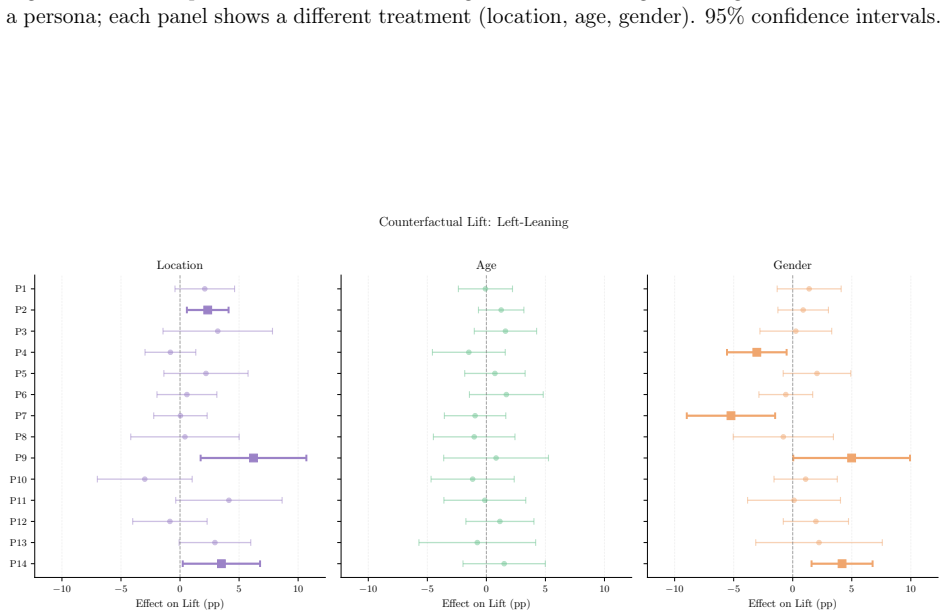
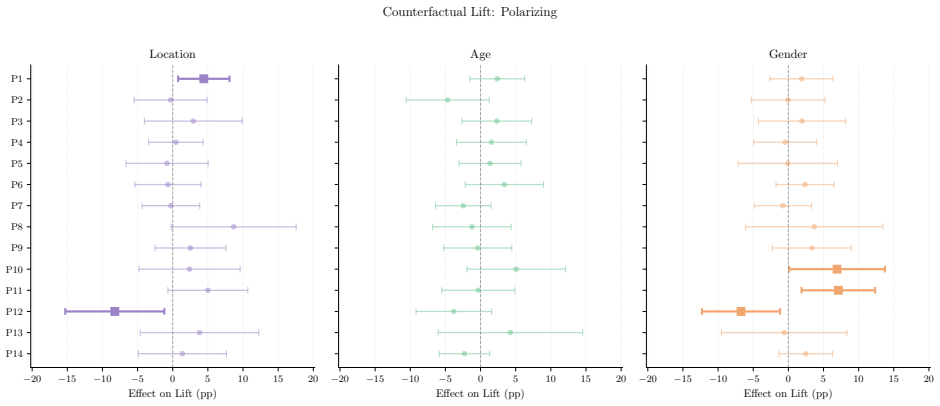
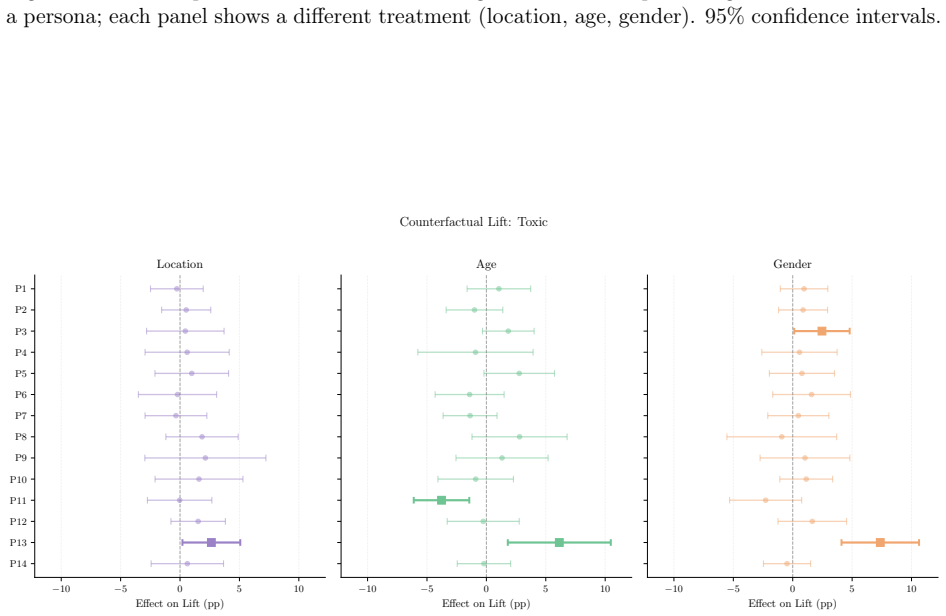
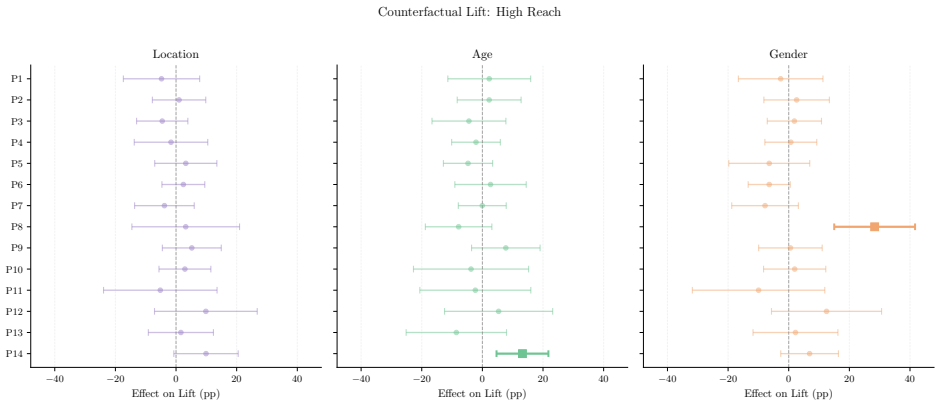
read the original abstract
Personalization algorithms determine what content users encounter on online platforms. Auditing these systems is difficult because independent auditors have only black-box access to the algorithms, while personalization depends on users' attributes, behavior, and evolving interaction histories. Existing auditing methods face a tradeoff: studies with real users capture realistic behavior but are costly and hard to control, whereas sock-puppet audits scale more easily but often rely on scripted behavior that limits realism. Beyond this, both approaches struggle to decouple user attributes from user behavior, limiting our ability to causally understand personalization. To address this gap, we introduce a framework for black-box audits of personalization algorithms using generative AI agents as behavioral engines for synthetic accounts. Each agent is instantiated with a fixed persona, grounded in demographic and political survey data, and interacts with a platform's content by reasoning about it and choosing actions. Because behavior is fixed within each persona while platform-visible signals such as age, gender, or location can be experimentally perturbed, our design enables counterfactual auditing of how platforms respond to user attributes. As a case study, we deploy 1,120 agents on X shortly after the 2024 U.S. election, spanning 14 personas and three counterfactual conditions, collecting over 200,000 content exposures. We find that X's algorithmic feed amplifies toxic, polarizing, political, and right-leaning content relative to the chronological feed, with amplification varying sharply by user ideology. Counterfactual analyses show that demographic signals affect content delivery in persona-dependent ways: pooled effects are largely null, while subgroup-level effects vary in direction and magnitude. Our work establishes GenAI-based agents as a new tool for algorithmic auditing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for black-box audits of personalization algorithms using generative AI agents as behavioral engines for synthetic accounts. Each agent has a fixed persona grounded in demographic and political survey data; platform-visible attributes (age, gender, location) can be perturbed while behavior remains fixed within the persona. This enables counterfactual auditing. As a case study, 1,120 agents spanning 14 personas and three conditions were deployed on X after the 2024 U.S. election, yielding over 200,000 content exposures. Key findings: X's algorithmic feed amplifies toxic, polarizing, political, and right-leaning content relative to chronological; amplification varies by user ideology; demographic signals affect delivery in persona-dependent ways (pooled effects largely null, subgroup effects vary).
Significance. If the agents produce stable, realistic, persona-grounded behavior that is separable from perturbed attributes, the framework offers a scalable alternative to real-user and sock-puppet audits, enabling causal claims about how platforms respond to user attributes. The case-study scale (1,120 agents, 200k+ exposures) and explicit counterfactual design are strengths; reproducible code or parameter-free elements are not claimed.
major comments (2)
- [Abstract (agent design and counterfactual conditions)] Abstract (agent design and counterfactual conditions): The central claim that the design 'enables counterfactual auditing of how platforms respond to user attributes' rests on the unvalidated assumption that 'behavior is fixed within each persona' while attributes are perturbed. No evidence is supplied that (a) generated actions match real-user distributions for the same persona or (b) attribute perturbations do not induce unintended shifts inside the LLM reasoning process. This is load-bearing for attributing exposure differences to platform response rather than model artifacts.
- [Case study results (amplification and counterfactual analyses)] Case study results (amplification and counterfactual analyses): The reported amplification effects (toxic/polarizing/right-leaning content) and the subgroup-level demographic findings (pooled null but varying by persona) are presented without reference to statistical controls, error analysis, or robustness checks on how content exposure is measured and attributed. These details are required to support the causal interpretation and are absent from the methods description.
minor comments (1)
- [Abstract] The abstract states 'collecting over 200,000 content exposures' but does not define the exact unit of exposure or how chronological vs. algorithmic feeds are distinguished in the data pipeline.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major comment below and outline the revisions we will make to improve the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: The central claim that the design 'enables counterfactual auditing of how platforms respond to user attributes' rests on the unvalidated assumption that 'behavior is fixed within each persona' while attributes are perturbed. No evidence is supplied that (a) generated actions match real-user distributions for the same persona or (b) attribute perturbations do not induce unintended shifts inside the LLM reasoning process. This is load-bearing for attributing exposure differences to platform response rather than model artifacts.
Authors: We agree that direct empirical validation against real-user behavior distributions would strengthen the counterfactual interpretation. The manuscript grounds personas in publicly available survey data (e.g., Pew Research Center political and demographic surveys) and constrains behavior via structured prompts that separate persona reasoning from profile attributes. However, we did not include quantitative comparisons to real-user action distributions, as such data are not publicly available for the specific personas. We will revise the manuscript by adding a dedicated 'Limitations and Validation Considerations' subsection in the Methods that explicitly discusses the grounding approach, the prompt structure used to fix behavior, potential LLM artifacts from attribute perturbations, and the full prompt templates in the appendix. This will allow readers to evaluate the fixed-behavior assumption directly. revision: partial
-
Referee: The reported amplification effects (toxic/polarizing/right-leaning content) and the subgroup-level demographic findings (pooled null but varying by persona) are presented without reference to statistical controls, error analysis, or robustness checks on how content exposure is measured and attributed. These details are required to support the causal interpretation and are absent from the methods description.
Authors: We accept this criticism. While the internal analysis included regression models with temporal and agent-level controls, standard error estimation, and some sensitivity checks, these were not fully documented in the submitted Methods section. In the revision we will expand the 'Analysis and Measurement' subsection to specify: the content classifiers and their validation metrics; the exact regression specifications used for amplification and counterfactual effects (including controls); reporting of confidence intervals and error analysis; and robustness checks such as alternative exposure attribution windows and alternative classifiers. These additions will be included in the main text and supplementary materials. revision: yes
Circularity Check
No circularity: empirical case study with no derivation chain or self-referential reductions.
full rationale
The paper introduces an empirical auditing framework using GenAI agents, deploys 1,120 agents on X, and reports observational findings on content exposure. No equations, first-principles derivations, or predictions are claimed; results are data-driven from the described experiment. The persona-grounding assumption is an unvalidated modeling choice but does not reduce any result to its inputs by construction. No self-citation load-bearing steps or fitted-input-as-prediction patterns appear. The work is self-contained as an empirical demonstration against external benchmarks (real platform interactions).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generative AI agents instantiated with survey-grounded personas produce stable, realistic behavior that can be decoupled from platform-visible attributes.
invented entities (1)
-
Generative AI agents as behavioral engines
no independent evidence
Reference graph
Works this paper leans on
-
[1]
G. Aher, R. I. Arriaga, and A. T. Kalai. Using large language models to simulate multiple humans and replicate human subject studies. InProceedings of Machine Learning Research, volume 202, 2023
2023
-
[2]
J. R. Anthis, R. Liu, S. M. Richardson, A. C. Kozlowski, B. Koch, E. Brynjolfsson, J. Evans, and M. S. Bernstein. Position: Llm social simulations are a promising research method. In Proceedings of Machine Learning Research, volume 267, 2025
2025
-
[3]
L. P. Argyle, E. C. Busby, N. Fulda, J. R. Gubler, C. Rytting, and D. Wingate. Out of one, many: Using language models to simulate human samples.Political Analysis, 31, 2023. ISSN 14764989. doi: 10.1017/pan.2023.2
-
[4]
C. A. Bail, L. P. Argyle, T. W. Brown, J. P. Bumpus, H. Chen, M. F. Hunzaker, J. Lee, M. Mann, F. Merhout, and A. Volfovsky. Exposure to opposing views on social media can increase political polarization.Proceedings of the National Academy of Sciences, 115(37):9216– 9221, 2018
2018
-
[5]
Bakshy, S
E. Bakshy, S. Messing, and L. A. Adamic. Exposure to ideologically diverse news and opinion on facebook.Science, 348(6239):1130–1132, 2015
2015
-
[6]
J. Bandy. Problematic machine behavior: A systematic literature review of algorithm audits. Proceedings of the acm on human-computer interaction, 5(CSCW1):1–34, 2021
2021
-
[7]
Bandy and N
J. Bandy and N. Diakopoulos. Curating quality? how twitter’s timeline algorithm treats different types of news.Social Media and Society, 7, 2021. ISSN 20563051. doi: 10.1177/ 20563051211041648
2021
-
[8]
N. Bartley, A. Abeliuk, E. Ferrara, and K. Lerman. Auditing algorithmic bias on twitter. In ACM International Conference Proceeding Series, 2021. doi: 10.1145/3447535.3462491
-
[9]
N. Bartley, K. Burghardt, and K. Lerman. Auditing exposure bias on social media for a healthier online discourse. InWorkshop Proceedings of the 18th International AAAI Confer- ence on Web and Social Media (ICWSM Workshops), 2024. doi: 10.36190/2024.12. URL 20 https://workshop-proceedings.icwsm.org/abstract.php?id=2024_12. CySoc 2024: 5th International Wor...
-
[10]
Baumann, P
J. Baumann, P. Röttger, A. Urman, A. Wendsjö, F. M. P. del Arco, J. B. Gruber, and D. Hovy. Large language model hacking: Quantifying the hidden risks of using llms for text annotation,
- [11]
-
[12]
Benjamini and Y
Y. Benjamini and Y. Hochberg. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological), 57(1):289–300, 1995
1995
-
[13]
Bisbee, J
J. Bisbee, J. D. Clinton, C. Dorff, B. Kenkel, and J. M. Larson. Synthetic replacements for human survey data? the perils of large language models.Political Analysis, 32(4):401–416, 2024
2024
-
[14]
Boeker and A
M. Boeker and A. Urman. An empirical investigation of personalization factors on tiktok. In Proceedings of the ACM web conference 2022, pages 2298–2309, 2022
2022
-
[15]
Bouchaud, D
P. Bouchaud, D. Chavalarias, and M. Panahi. Crowdsourced audit of twitter’s recommender systems.Scientific Reports, 13(1):16815, 2023
2023
-
[16]
W. J. Brady, K. McLoughlin, T. N. Doan, and M. J. Crockett. How social learning amplifies moral outrage expression in online social networks.Science Advances, 7(33):eabe5641, 2021
2021
-
[17]
Brand, A
J. Brand, A. Israeli, and D. Ngwe. Using gpt for market research. InProceedings of the 25th ACM Conference on Economics and Computation, EC ’24, page 613, New York, NY, USA,
-
[18]
Association for Computing Machinery. ISBN 9798400707049. doi: 10.1145/3670865. 3673479. URLhttps://doi.org/10.1145/3670865.3673479
-
[19]
Casper, C
S. Casper, C. Ezell, C. Siegmann, N. Kolt, T. L. Curtis, B. Bucknall, A. Haupt, K. Wei, J. Scheurer, M. Hobbhahn, et al. Black-box access is insufficient for rigorous ai audits. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2254–2272, 2024
2024
-
[20]
S. H. Cen and R. Alur. From transparency to accountability and back: A discussion of access and evidence in ai auditing. InProceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization, pages 1–14, 2024
2024
- [21]
-
[22]
Chang, A
S. Chang, A. Chaszczewicz, E. Wang, M. Josifovska, E. Pierson, and J. Leskovec. Llms generate structurally realistic social networks but overestimate political homophily. InProceedings of the International AAAI Conference on Web and Social Media, volume 19, pages 341–371, 2025
2025
-
[23]
A. Y. Chen, B. Nyhan, J. Reifler, R. E. Robertson, and C. Wilson. Subscriptions and external linkshelpdriveresentfuluserstoalternativeandextremistyoutubechannels.Science Advances, 9(35):eadd8080, 2023
2023
-
[24]
W. Chen, D. Pacheco, K.-C. Yang, and F. Menczer. Neutral bots probe political bias on social media.Nature communications, 12(1):5580, 2021
2021
-
[25]
Davidson, D
T. Davidson, D. Warmsley, M. Macy, and I. Weber. Automated hate speech detection and the problem of offensive language. InProceedings of the international AAAI conference on web and social media, volume 11, pages 512–515, 2017. 21
2017
-
[26]
Elkin-Koren
N. Elkin-Koren. Let the crawlers crawl: On virtual gatekeepers and the right to exclude indexing.University of Dayton Law Review, 26(2):3, 2001
2001
-
[27]
Ferraro, A
A. Ferraro, A. Galli, V. La Gatta, M. Postiglione, G. M. Orlando, D. Russo, G. Riccio, A. Ro- mano, and V. Moscato. Agent-based modelling meets generative ai in social network simula- tions. InInternational conference on advances in social networks analysis and mining, pages 155–170. Springer, 2024
2024
-
[28]
A. Filippas, J. J. Horton, and B. S. Manning. Large language models as simulated economic agents: What can we learn from homo silicus? InProceedings of the 25th ACM Conference on Economics and Computation, EC ’24, page 614–615, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 9798400707049. doi: 10.1145/3670865.3673513. URLhttps: //doi.o...
-
[29]
C. Gao, X. Lan, Z. Lu, J. Mao, J. Piao, H. Wang, D. Jin, and Y. Li. S3: Social-network simu- lation system with large language model-empowered agents.arXiv preprint arXiv:2307.14984, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Y. Gao, D. Lee, G. Burtch, and S. Fazelpour. Take caution in using llms as human surrogates. Proceedings of the National Academy of Sciences, 122(24):e2501660122, 2025
2025
-
[31]
S. Gerhart. Do web search engines suppress controversy?First Monday, 2004
2004
-
[32]
Gillum, A
J. Gillum, A. Corse, and A. Tong. X algorithm feeds users political content— whether they want it or not, 2024. URLhttps://www.wsj.com/politics/elections/ x-twitter-political-content-election-2024-28f2dadd. Accessed: 2026-02-07
2024
-
[33]
González-Bailón, D
S. González-Bailón, D. Lazer, P. Barberá, M. Zhang, H. Allcott, T. Brown, A. Crespo-Tenorio, D. Freelon, M. Gentzkow, A. M. Guess, et al. Asymmetric ideological segregation in exposure to political news on facebook.Science, 381(6656):392–398, 2023
2023
-
[34]
A. M. Guess, N. Malhotra, J. Pan, P. Barberá, H. Allcott, T. Brown, A. Crespo-Tenorio, D. Dimmery, D. Freelon, M. Gentzkow, et al. How do social media feed algorithms affect attitudes and behavior in an election campaign?Science, 381(6656):398–404, 2023
2023
- [35]
-
[36]
Hanu and Unitary team
L. Hanu and Unitary team. Detoxify. Github. https://github.com/unitaryai/detoxify, 2020
2020
-
[37]
M. Haroon, M. Wojcieszak, A. Chhabra, X. Liu, P. Mohapatra, and Z. Shafiq. Auditing youtube’s recommendation system for ideologically congenial, extreme, and problematic recom- mendations.Proceedings of the National Academy of Sciences of the United States of America, 120, 2023. ISSN 10916490. doi: 10.1073/pnas.2213020120
-
[38]
Heseltine and B
M. Heseltine and B. Clemm von Hohenberg. Large language models as a substitute for human experts in annotating political text.Research & Politics, 11(1):20531680241236239, 2024
2024
-
[39]
Hewitt, A
L. Hewitt, A. Ashokkumar, I. Ghezae, and R. Willer. Predicting results of social science experiments using large language models.Preprint, 2024
2024
-
[40]
Huszár, S
F. Huszár, S. I. Ktena, C. O’Brien, L. Belli, A. Schlaikjer, and M. Hardt. Algorithmic amplifica- tion of politics on twitter.Proceedings of the national academy of sciences, 119(1):e2025334119, 2022. 22
2022
-
[41]
B. Imana, A. Korolova, and J. Heidemann. Having your privacy cake and eating it too: Platform-supported auditing of social media algorithms for public interest.Proceedings of the ACM on Human-Computer Interaction, 7, 2023. ISSN 25730142. doi: 10.1145/3579610
-
[42]
L. D. Introna and H. Nissenbaum. Shaping the web: Why the politics of search engines matters. The information society, 16(3):169–185, 2000
2000
-
[43]
C. Kang. Openai’s sam altman urges a.i. regulation in senate hearing.The New York Times, May 2023. URLhttps://www.nytimes.com/2023/05/16/technology/ openai-altman-artificial-intelligence-regulation.html
2023
-
[44]
Y. Leng. Can llms mimic human-like mental accounting and behavioral biases? InProceedings of the 25th ACM Conference on Economics and Computation, EC ’24, page 581, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 9798400707049. doi: 10.1145/ 3670865.3673632. URLhttps://doi.org/10.1145/3670865.3673632
-
[45]
Y. Leng and T. Nguyen.Latent Neural Coupling of Risk and Time Preferences in LLMs Mirrors Human Biases, page 542. Association for Computing Machinery, New York, NY, USA, 2025. ISBN 9798400719431. URLhttps://doi.org/10.1145/3736252.3742588
-
[46]
A. Li, H. Chen, H. Namkoong, and T. Peng. Llm generated persona is a promise with a catch,
- [47]
-
[48]
B. S. Manning, K. Zhu, and J. J. Horton. Automated social science: Language models as scientist and subjects. Technical report, National Bureau of Economic Research, 2024
2024
-
[49]
Q. Mei, Y. Xie, W. Yuan, and M. O. Jackson. A turing test of whether ai chatbots are behaviorally similar to humans.Proceedings of the National Academy of Sciences of the United States of America, 121, 2024. ISSN 10916490. doi: 10.1073/pnas.2313925121
-
[50]
Metaxa, J
D. Metaxa, J. S. Park, J. A. Landay, and J. Hancock. Search media and elections: A longi- tudinal investigation of political search results.Proceedings of the ACM on Human-Computer Interaction, 3(CSCW):1–17, 2019
2019
-
[51]
Auditing algorithms: Understanding algorithmic systems from the outside in.Foundations and Trends®in Human–Computer Interaction, 14(4):272–344, 2021
D.Metaxa, J.S.Park, R.E.Robertson, K.Karahalios, C.Wilson, J.Hancock, C.Sandvig, etal. Auditing algorithms: Understanding algorithmic systems from the outside in.Foundations and Trends®in Human–Computer Interaction, 14(4):272–344, 2021
2021
-
[52]
Milli, M
S. Milli, M. Carroll, Y. Wang, S. Pandey, S. Zhao, and A. D. Dragan. Engagement, user satisfaction, and the amplification of divisive content on social media.PNAS nexus, 4(3): pgaf062, 2025
2025
-
[53]
E. Mustafaraj, E. Lurie, and C. Devine. The case for voter-centered audits of search engines during political elections. InFAT* 2020 - Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, 2020. doi: 10.1145/3351095.3372835
-
[54]
U. Naseem, J. Ren, S. Anwar, S. Kohail, R. A. G. Veliz, R. Geislinger, A. Jabr, I. Abdulmumin, L. Qureshi, A. A. Borkar, M. I. Mukhtar, A. A. Ayele, I. S. Ahmad, A. Ali, M. Semmann, S. H. Muhammad, and S. M. Yimam. Polar: A benchmark for multilingual, multicultural, and multi-event online polarization, 2025. URLhttps://arxiv.org/abs/2505.20624
-
[55]
Nyhan, J
B. Nyhan, J. Settle, E. Thorson, M. Wojcieszak, P. Barberá, A. Y. Chen, H. Allcott, T. Brown, A. Crespo-Tenorio, D. Dimmery, et al. Like-minded sources on facebook are prevalent but not polarizing.Nature, 620(7972):137–144, 2023. 23
2023
-
[56]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, :, S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y. Bai, B. Baker, H. Bao, B. Barak, A. Bennett, T. Bertao, N. Brett, E. Brevdo, G. Brockman, S. Bubeck, C. Chang, K. Chen, M. Chen, E. Cheung, A. Clark, D. Cook, M. Dukhan, C. Dvo- rak, K. Fives, V. Fomenko, T. Garipov, K. Georgiev, M. Glaese, T. Gogineni, A. Goucher, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Generativeagents: Interactive simulacra of human behavior
J.S.Park, J.O’Brien, C.J.Cai, M.R.Morris, P.Liang, andM.S.Bernstein. Generativeagents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[58]
Pasquale.The Black Box Society: The Secret Algorithms That Control Money and In- formation
F. Pasquale.The Black Box Society: The Secret Algorithms That Control Money and In- formation. Harvard University Press, 2015. URLhttps://www.hup.harvard.edu/books/ 9780674970847
2015
-
[59]
Patel and J
F. Patel and J. Melendi. Meta’s oversight board needs access to Facebook’s algorithms to do its job, 2024. URLhttps://www.brennancenter.org/our-work/analysis-opinion/ metas-oversight-board-needs-access-facebooks-algorithms-do-its-job. Accessed: 2026-03-10
2024
-
[60]
B. Perreault, J. H. Lee, R. Shava, and E. Mustafaraj. Algorithmic misjudgement in google search results: Evidence from auditing the us online electoral information environment. In 2024 ACM Conference on Fairness, Accountability, and Transparency, FAccT 2024, 2024. doi: 10.1145/3630106.3658916
-
[61]
Beyond red vs
Pew Research Center. Beyond red vs. blue: The political typology. Technical report, November 2021. URLhttps://www.pewresearch.org/politics/2021/11/09/ beyond-red-vs-blue-the-political-typology-2/
2021
-
[62]
Piccardi, M
T. Piccardi, M. Saveski, C. Jia, J. Hancock, J. L. Tsai, and M. S. Bernstein. Reranking partisan animosity in algorithmic social media feeds alters affective polarization.Science, 390(6776): eadu5584, 2025
2025
-
[63]
I. D. Raji, A. Smart, R. N. White, M. Mitchell, T. Gebru, B. Hutchinson, J. Smith-Loud, D. Theron, and P. Barnes. Closing the ai accountability gap: Defining an end-to-end frame- work for internal algorithmic auditing. InProceedings of the 2020 conference on fairness, accountability, and transparency, pages 33–44, 2020
2020
-
[64]
Ramesh, M
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever. Zero-shot text-to-image generation. InInternational conference on machine learning, pages 8821–8831. Pmlr, 2021. 24
2021
-
[65]
M. H. Ribeiro, R. Ottoni, R. West, V. A. Almeida, and W. Meira Jr. Auditing radicalization pathways on youtube. InProceedings of the 2020 conference on fairness, accountability, and transparency, pages 131–141, 2020
2020
-
[66]
F. Rowland. The filter bubble: What the internet is hiding from you.portal: Libraries and the Academy, 11(4):1009–1011, 2011
2011
-
[67]
Sandvig, K
C. Sandvig, K. Hamilton, K. Karahalios, and C. Langbort. Auditing algorithms: Research methods for detecting discrimination on internet platforms.Data and discrimination: convert- ing critical concerns into productive inquiry, 22(2014):4349–4357, 2014
2014
-
[68]
Siddiqui and J
F. Siddiqui and J. B. Merrill. Elon musk’s twitter pushes hate speech, extremist content into “for you” pages.The Washington Post, Mar. 2023. URLhttps://www.washingtonpost.com/ technology/2023/03/30/elon-musk-twitter-hate-speech/. Accessed: 2026-02-07
2023
-
[69]
Simchon, W
A. Simchon, W. J. Brady, and J. J. Van Bavel. Troll and divide: the language of online polarization.PNAS nexus, 1(1):pgac019, 2022
2022
-
[70]
I. Srba, R. Moro, M. Tomlein, B. Pecher, J. Simko, E. Stefancova, M. Kompan, A. Hrckova, J. Podrouzek, A. Gavornik, et al. Auditing youtube’s recommendation algorithm for misinfor- mation filter bubbles.ACM Transactions on Recommender Systems, 1(1):1–33, 2023
2023
-
[71]
C. R. Sunstein. Republic: Divided democracy in the age of social media. 2018
2018
-
[72]
Talat and D
Z. Talat and D. Hovy. Hateful symbols or hateful people? predictive features for hate speech detection on twitter. InProceedings of the NAACL student research workshop, pages 88–93, 2016
2016
- [73]
-
[74]
P. Törnberg, D. Valeeva, J. Uitermark, and C. Bail. Simulating social media using large language models to evaluate alternative news feed algorithms.arXiv preprint arXiv:2310.05984, 2023
-
[75]
Tranchero, C.-F
M. Tranchero, C.-F. Brenninkmeijer, A. Murugan, and A. Nagaraj. Theorizing with large language models. Working Paper 33033, National Bureau of Economic Research, October
-
[76]
URLhttp://www.nber.org/papers/w33033
-
[77]
Census Bureau
U.S. Census Bureau. 2020 census urban areas facts.https://www.census.gov/ programs-surveys/geography/guidance/geo-areas/urban-rural/2020-ua-facts.html,
2020
-
[78]
Census Bureau
U.S. Census Bureau. American community survey and current population survey demographic tables, 2021. URLhttps://www.census.gov/data.html. Accessed: 2025
2021
-
[79]
House of Representatives, Committee on Energy and Commerce, Subcommittee on Com- munications and Technology and Subcommittee on Consumer Protection and Commerce
U.S. House of Representatives, Committee on Energy and Commerce, Subcommittee on Com- munications and Technology and Subcommittee on Consumer Protection and Commerce. Dis- information Nation: Social Media’s Role in Promoting Extremism and Misinformation, 2021. URLhttps://docs.house.gov/Committee/Calendar/ByEvent.aspx?EventID=111407. Ac- cessed: 2026-06-28
2021
-
[80]
House of Representatives, Committee on Energy and Commerce, Subcommittee on Con- sumer Protection and Commerce
U.S. House of Representatives, Committee on Energy and Commerce, Subcommittee on Con- sumer Protection and Commerce. Holding Big Tech Accountable: Legislation to Build a 25 Safer Internet, 2021. URLhttps://docs.house.gov/Committee/Calendar/ByEvent.aspx? EventID=114299. Accessed: 2026-06-28
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.