Sampling-Based Coordination-Informed Multi-Objective Multi-Robot Reinforcement Learning
Pith reviewed 2026-07-01 01:13 UTC · model grok-4.3
The pith
CIMORL lets multi-robot teams optimize competing objectives in a fully decentralized way through distributed weight prediction and privileged training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The CIMORL framework integrates a distributed weight prediction mechanism, a privileged expert training strategy, and theoretical guarantees for Pareto-optimal solutions to produce coordinated multi-objective policies that transfer to fully decentralized deployment without access to privileged information.
What carries the argument
Distributed weight prediction mechanism combined with privileged expert training during learning, which supports sampling-based variants (tree search and MPPI) to generate coordinated policies for decentralized execution.
If this is right
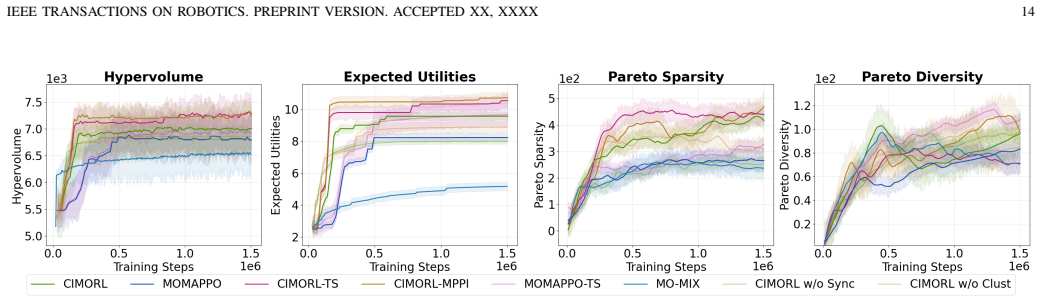
- 21.2% hypervolume improvement and superior policy stability compared to baselines in cooperative and adversarial multi-robot scenarios.
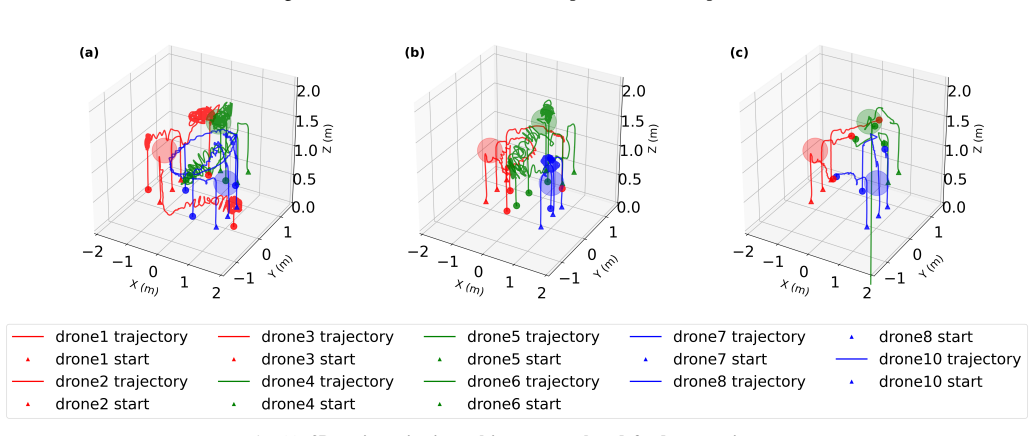
- Robust performance validated in real-world Crazyflie drone experiments for resource allocation and multi-attacker multi-defend tasks under partial observability.
- Pareto-optimal solutions with maintained coordination in decentralized multi-robot multi-objective settings.
- Fully decentralized deployment enabled after training that uses global privileged information.
Where Pith is reading between the lines
- The same privileged-training pattern could apply to other partially observable multi-agent tasks such as vehicle fleets or sensor networks.
- Removing the multi-robot coordination element might reveal whether the weight prediction alone improves single-robot multi-objective learning.
- Scaling experiments with more robots or objectives would expose limits not tested in the current cooperative and adversarial cases.
- Replacing tree search or MPPI with other samplers could test whether the coordination benefit depends on the specific sampling method.
Load-bearing premise
Policies trained with access to privileged global information and expert guidance will remain Pareto-optimal and coordinated once that privileged information is removed at deployment.
What would settle it
A test showing that fully decentralized policies achieve lower hypervolume or lose coordination relative to the privileged training phase.
Figures




read the original abstract
Multi-robot systems must simultaneously optimize competing objectives while maintaining coordinated behavior. Existing multi-agent reinforcement learning approaches often rely on fixed or centralized coordination, which limits adaptability and violates distributed constraints. This work introduces the Coordination-Informed Multi-Objective Reinforcement Learning (CIMORL) framework, integrating a distributed weight prediction mechanism, a privileged expert training strategy, and theoretical guarantees for Pareto-optimal solutions. We present the base CIMORL method alongside two sampling-based variants, CIMORL-TS (Tree Search) and CIMORL-MPPI (MPPI), which leverage privileged global information during training to enable fully decentralized deployment. Experimental validation in cooperative and adversarial scenarios demonstrates a $21.2\%$ hypervolume improvement and superior policy stability compared to state-of-the-art baselines. Real-world experiments with Crazyflie drones further validate the framework's robustness in resource allocation and multi-attacker multi-defend scenarios under partial observability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Coordination-Informed Multi-Objective Reinforcement Learning (CIMORL) framework for multi-robot systems. It integrates a distributed weight prediction mechanism, privileged expert training during learning, and sampling-based variants (CIMORL-TS and CIMORL-MPPI) to produce Pareto-optimal policies that can be deployed in a fully decentralized manner. The central claims are a 21.2% hypervolume improvement over state-of-the-art baselines in cooperative and adversarial scenarios, superior policy stability, and real-world validation on Crazyflie drones for resource allocation and multi-attacker multi-defend tasks under partial observability, supported by theoretical guarantees for Pareto optimality.
Significance. If the transfer from privileged expert training to decentralized deployment without global state information can be shown to preserve both coordination and Pareto optimality, the framework would address a key limitation in multi-objective multi-agent RL by enabling adaptive, distributed coordination. The sampling-based extensions and real-world drone experiments would strengthen applicability to resource-constrained robotic systems.
major comments (3)
- [Abstract] Abstract: The assertion of 'theoretical guarantees for Pareto-optimal solutions' is presented without any derivation, proof sketch, or reference to specific equations or assumptions; this is load-bearing because the 21.2% hypervolume claim and the Crazyflie results both rely on the guarantee surviving the shift from privileged training to fully decentralized execution with only local observations.
- [Method] Method description (implied in abstract and skeptic note): No explicit mechanism is shown for how the distributed weight predictor compensates for the missing global state or privileged expert information at test time; without this, the central promise that policies remain Pareto-optimal and coordinated in deployment cannot be evaluated.
- [Experiments] Experimental validation: The 21.2% hypervolume improvement and 'superior policy stability' are stated without protocol details, baseline definitions, statistical tests, or ablation on the privileged-to-decentralized transfer; this undermines assessment of whether the results support the claims over centralized or fixed-weight baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the CIMORL framework. We address each major comment point-by-point below, agreeing where clarifications or additions are needed to strengthen the presentation of the theoretical guarantees, method details, and experimental validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of 'theoretical guarantees for Pareto-optimal solutions' is presented without any derivation, proof sketch, or reference to specific equations or assumptions; this is load-bearing because the 21.2% hypervolume claim and the Crazyflie results both rely on the guarantee surviving the shift from privileged training to fully decentralized execution with only local observations.
Authors: We agree that the abstract would benefit from explicit linkage to the supporting theory. The full manuscript contains Theorem 1 (Section 4.3) with a proof sketch showing Pareto optimality preservation under the assumption of a sufficiently accurate distributed weight predictor; this assumption is validated in the privileged-to-decentralized transfer. We will revise the abstract to reference the theorem and its key assumptions. revision: yes
-
Referee: [Method] Method description (implied in abstract and skeptic note): No explicit mechanism is shown for how the distributed weight predictor compensates for the missing global state or privileged expert information at test time; without this, the central promise that policies remain Pareto-optimal and coordinated in deployment cannot be evaluated.
Authors: Section 3.2 details that the weight predictor is trained on privileged global information but uses only local observations at test time to output weights for the multi-objective policy, thereby approximating coordination. We will add a dedicated figure and pseudocode contrasting the training and deployment pipelines to make this compensation mechanism fully explicit. revision: yes
-
Referee: [Experiments] Experimental validation: The 21.2% hypervolume improvement and 'superior policy stability' are stated without protocol details, baseline definitions, statistical tests, or ablation on the privileged-to-decentralized transfer; this undermines assessment of whether the results support the claims over centralized or fixed-weight baselines.
Authors: We will expand the experimental section with full protocol descriptions, explicit definitions of all baselines (including centralized and fixed-weight variants), statistical significance results (t-tests across seeds), and a new ablation isolating the privileged-to-decentralized transfer. This will directly support the reported 21.2% hypervolume gain. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and description introduce CIMORL with a distributed weight prediction mechanism, privileged expert training, and theoretical guarantees for Pareto-optimal solutions, along with sampling-based variants. No equations, proof structures, or self-referential definitions are visible that reduce any claimed prediction or guarantee to a fitted input or self-citation by construction. The experimental claims (21.2% hypervolume improvement, Crazyflie validation) are presented as external validation rather than internal redefinitions. The central transfer from privileged training to decentralized deployment is an assumption but does not manifest as a circular reduction in the visible text. This is the expected honest non-finding for a methods paper whose core claims rest on empirical results and unshown theory.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The world is a multi-objective multi-agent system: Now what?
R. Radulescu, “The world is a multi-objective multi-agent system: Now what?” in27th European Conference on Artificial Intelligence. IOS Press, 2024, pp. 32–38
2024
-
[2]
Multi-agent deep reinforcement learning: a survey,
S. Gronauer and K. Diepold, “Multi-agent deep reinforcement learning: a survey,”Artificial Intelligence Review, vol. 55, no. 2, pp. 895–943, 2022
2022
-
[3]
Momaland: A set of benchmarks for multi-objective multi-agent reinforcement learning,
F. Felten, U. Ucak, H. Azmani, G. Peng, W. R ¨opke, H. Baier, P. Man- nion, D. M. Roijers, J. K. Terry, E.-G. Talbiet al., “Momaland: A set of benchmarks for multi-objective multi-agent reinforcement learning,” arXiv preprint arXiv:2407.16312, 2024. IEEE TRANSACTIONS ON ROBOTICS. PREPRINT VERSION. ACCEPTED XX, XXXX 20
-
[4]
A survey of monte carlo tree search methods,
C. B. Browne, E. Powley, D. Whitehouse, S. M. Lucas, P. I. Cowling, P. Rohlfshagen, S. Tavener, D. Perez, S. Samothrakis, and S. Colton, “A survey of monte carlo tree search methods,”IEEE Transactions on Computational Intelligence and AI in games, vol. 4, no. 1, pp. 1–43, 2012
2012
-
[5]
Information-theoretic model predictive control: Theory and applications to autonomous driving,
G. Williams, P. Drews, B. Goldfain, J. M. Rehg, and E. A. Theodorou, “Information-theoretic model predictive control: Theory and applications to autonomous driving,”IEEE Transactions on Robotics, vol. 34, no. 6, pp. 1603–1622, 2018
2018
-
[6]
A survey of multi-objective sequential decision-making,
D. M. Roijers, P. Vamplew, S. Whiteson, and R. Dazeley, “A survey of multi-objective sequential decision-making,”Journal of Artificial Intelligence Research, vol. 48, pp. 67–113, 2013
2013
-
[7]
Empirical evaluation methods for multiobjective reinforcement learning algorithms,
P. Vamplew, R. Dazeley, A. Berry, R. Issabekov, and E. Dekker, “Empirical evaluation methods for multiobjective reinforcement learning algorithms,”Machine learning, vol. 84, no. 1, pp. 51–80, 2011
2011
-
[8]
A practical guide to multi-objective reinforcement learning and planning,
C. F. Hayes, R. R ˘adulescu, E. Bargiacchi, J. K ¨allstr¨om, M. Macfarlane, M. Reymond, T. Verstraeten, L. M. Zintgraf, R. Dazeley, F. Heintz et al., “A practical guide to multi-objective reinforcement learning and planning,”arXiv preprint arXiv:2103.09568, 2021
-
[9]
Multi-objective reinforcement learning using sets of pareto dominating policies,
K. Van Moffaert and A. Now ´e, “Multi-objective reinforcement learning using sets of pareto dominating policies,”The Journal of Machine Learning Research, vol. 15, no. 1, pp. 3483–3512, 2014
2014
-
[10]
Multi-objective reinforcement learning based on decomposition: A taxonomy and framework,
F. Felten, E.-G. Talbi, and G. Danoy, “Multi-objective reinforcement learning based on decomposition: A taxonomy and framework,”Journal of Artificial Intelligence Research, vol. 79, pp. 679–723, 2024
2024
-
[11]
Prediction- guided multi-objective reinforcement learning for continuous robot con- trol,
J. Xu, Y . Tian, P. Ma, D. Rus, S. Sueda, and W. Matusik, “Prediction- guided multi-objective reinforcement learning for continuous robot con- trol,” inInternational conference on machine learning. PMLR, 2020, pp. 10 607–10 616
2020
-
[12]
Sample-efficient multi-objective learning via generalized policy improvement prioritization,
L. N. Alegre, A. L. Bazzan, D. M. Roijers, A. Now ´e, and B. C. da Silva, “Sample-efficient multi-objective learning via generalized policy improvement prioritization,”arXiv preprint arXiv:2301.07784, 2023
-
[13]
Multi-objective reinforcement learning: Convexity, stationarity and pareto optimality,
H. Lu, D. Herman, and Y . Yu, “Multi-objective reinforcement learning: Convexity, stationarity and pareto optimality,” inThe Eleventh Interna- tional Conference on Learning Representations, 2023
2023
-
[14]
A two-stage multi-objective evolutionary reinforcement learning framework for con- tinuous robot control,
H.-L. Tran, L. Doan, N. H. Luong, and H. T. T. Binh, “A two-stage multi-objective evolutionary reinforcement learning framework for con- tinuous robot control,” inProceedings of the Genetic and Evolutionary Computation Conference, 2023, pp. 577–585
2023
-
[15]
Multi-objective multiagent credit assignment in reinforcement learning and nsga-ii,
L. Yliniemi and K. Tumer, “Multi-objective multiagent credit assignment in reinforcement learning and nsga-ii,”Soft Computing, vol. 20, no. 10, pp. 3869–3887, 2016
2016
-
[16]
Multi- objective dynamic dispatch optimisation using multi-agent reinforcement learning,
P. Mannion, K. Mason, S. Devlin, J. Duggan, and E. Howley, “Multi- objective dynamic dispatch optimisation using multi-agent reinforcement learning,” inProceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems, 2016, pp. 1345–1346
2016
-
[17]
Mo-mix: Multi-objective multi-agent cooperative decision-making with deep reinforcement learn- ing,
T. Hu, B. Luo, C. Yang, and T. Huang, “Mo-mix: Multi-objective multi-agent cooperative decision-making with deep reinforcement learn- ing,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 10, pp. 12 098–12 112, 2023
2023
-
[18]
Learning synergies for multi-objective op- timization in asymmetric multiagent systems,
G. Dixit and K. Tumer, “Learning synergies for multi-objective op- timization in asymmetric multiagent systems,” inProceedings of the Genetic and Evolutionary Computation Conference, 2023, pp. 447–455
2023
-
[19]
A novel multi-objective optimization based multi-agent deep reinforcement learning approach for microgrid resources planning,
M. S. Abid, H. J. Apon, S. Hossain, A. Ahmed, R. Ahshan, and M. H. Lipu, “A novel multi-objective optimization based multi-agent deep reinforcement learning approach for microgrid resources planning,” Applied Energy, vol. 353, p. 122029, 2024
2024
-
[20]
Moma-ac: A preference- driven actor-critic framework for continuous multi-objective multi-agent reinforcement learning,
A. Callaghan, K. Mason, and P. Mannion, “Moma-ac: A preference- driven actor-critic framework for continuous multi-objective multi-agent reinforcement learning,”Neurocomputing, p. 132032, 2025
2025
-
[21]
D. M. Roijers, S. Whiteson, R. Brachman, and P. Stone,Multi-objective decision making. Springer, 2017
2017
-
[22]
An algorithm for multi-objective multi- agent optimization,
M. J. Blondin and M. Hale, “An algorithm for multi-objective multi- agent optimization,” in2020 American Control Conference (ACC). IEEE, 2020, pp. 1489–1494
2020
-
[23]
Cluster synchronization of diffusively coupled nonlinear systems: A contraction- based approach,
Z. Aminzare, B. Dey, E. N. Davison, and N. E. Leonard, “Cluster synchronization of diffusively coupled nonlinear systems: A contraction- based approach,”Journal of Nonlinear Science, vol. 30, pp. 2235–2257, 2020
2020
-
[24]
Nonlinear opinion dynamics with tunable sensitivity,
A. Bizyaeva, A. Franci, and N. E. Leonard, “Nonlinear opinion dynamics with tunable sensitivity,”IEEE Transactions on Automatic Control, vol. 68, no. 3, pp. 1415–1430, 2022
2022
-
[25]
A generalized kuramoto model for opinion dynamics on the unit sphere,
Z. Zhang, S. Al-Abri, and F. Zhang, “A generalized kuramoto model for opinion dynamics on the unit sphere,”Automatica, vol. 171, p. 111957, 2025
2025
-
[26]
Liquid-Graph Time-Constant Network for Multi-Agent Systems Control,
A. Marino, C. Pacchierotti, and P. Robuffo Giordano, “Liquid-Graph Time-Constant Network for Multi-Agent Systems Control,” inCDC 2024 - 63rd IEEE Conference on Decision and Control. Milan (Italie), Italy: IEEE, Dec. 2024
2024
-
[27]
Multi-objective monte-carlo tree search,
W. Wang and M. Sebag, “Multi-objective monte-carlo tree search,” in Asian conference on machine learning. PMLR, 2012, pp. 507–522
2012
-
[28]
Monte carlo tree search algorithms for risk-aware and multi-objective reinforcement learning,
C. F. Hayes, M. Reymond, D. M. Roijers, E. Howley, and P. Mannion, “Monte carlo tree search algorithms for risk-aware and multi-objective reinforcement learning,”Autonomous Agents and Multi-Agent Systems, vol. 37, no. 2, p. 26, 2023
2023
-
[29]
Multi-objective reinforcement learning with path integral policy improvement,
R. Ariizumi, H. Sago, T. Asai, and S.-I. Azuma, “Multi-objective reinforcement learning with path integral policy improvement,” in2023 62nd Annual Conference of the Society of Instrument and Control Engineers (SICE). IEEE, 2023, pp. 1418–1423
2023
-
[30]
F. A. Oliehoek, C. Amatoet al.,A concise introduction to decentralized POMDPs. Springer, 2016, vol. 1
2016
-
[31]
Branke,Multiobjective optimization: Interactive and evolutionary approaches
J. Branke,Multiobjective optimization: Interactive and evolutionary approaches. Springer Science & Business Media, 2008, vol. 5252
2008
-
[32]
Clustering in diffusively coupled networks,
W. Xia and M. Cao, “Clustering in diffusively coupled networks,” Automatica, vol. 47, no. 11, pp. 2395–2405, 2011
2011
-
[33]
Regret-based sampling of pareto fronts for multi-objective robot plan- ning problems,
A. Botros, N. Wilde, A. Sadeghi, J. Alonso-Mora, and S. L. Smith, “Regret-based sampling of pareto fronts for multi-objective robot plan- ning problems,”IEEE Transactions on Robotics, 2024
2024
-
[34]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estimation,” arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[35]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Learning by cheating,
D. Chen, B. Zhou, V . Koltun, and P. Kr¨ahenb¨uhl, “Learning by cheating,” inConference on Robot Learning. PMLR, 2020, pp. 66–75
2020
-
[37]
Neural tree expansion for multi-robot planning in non-cooperative environments,
B. Riviere, W. H ¨onig, M. Anderson, and S.-J. Chung, “Neural tree expansion for multi-robot planning in non-cooperative environments,” IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 6868–6875, 2021
2021
-
[38]
Non-asymptotic analysis of monte carlo tree search,
D. Shah, Q. Xie, and Z. Xu, “Non-asymptotic analysis of monte carlo tree search,” inAbstracts of the 2020 SIGMETRICS/Performance Joint International Conference on Measurement and Modeling of Computer Systems, 2020, pp. 31–32
2020
-
[39]
On contraction analysis for non-linear systems,
W. Lohmiller and J.-J. E. Slotine, “On contraction analysis for non-linear systems,”Automatica, vol. 34, no. 6, pp. 683–696, 1998
1998
-
[40]
A contraction approach to the hierarchical analysis and design of networked systems,
G. Russo, M. Di Bernardo, and E. D. Sontag, “A contraction approach to the hierarchical analysis and design of networked systems,”IEEE Transactions on Automatic Control, vol. 58, no. 5, pp. 1328–1331, 2012
2012
-
[41]
Contraction theory for nonlinear stability analysis and learning-based control: A tutorial overview,
H. Tsukamoto, S.-J. Chung, and J.-J. E. Slotine, “Contraction theory for nonlinear stability analysis and learning-based control: A tutorial overview,”Annual Reviews in Control, vol. 52, pp. 135–169, 2021
2021
-
[42]
Spectral Normalization for Generative Adversarial Networks
T. Miyato, T. Kataoka, M. Koyama, and Y . Yoshida, “Spectral normalization for generative adversarial networks,”arXiv preprint arXiv:1802.05957, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
The hypervolume indicator: Computational problems and algorithms,
A. P. Guerreiro, C. M. Fonseca, and L. Paquete, “The hypervolume indicator: Computational problems and algorithms,”ACM Computing Surveys (CSUR), vol. 54, no. 6, pp. 1–42, 2021
2021
-
[44]
A review of pareto pruning methods for multi-objective optimization,
S. Petchrompo, D. W. Coit, A. Brintrup, A. Wannakrairot, and A. K. Parlikad, “A review of pareto pruning methods for multi-objective optimization,”Computers & Industrial Engineering, vol. 167, p. 108022, 2022
2022
-
[45]
Observer design for stochastic nonlinear systems via contraction-based incremental stability,
A. P. Dani, S.-J. Chung, and S. Hutchinson, “Observer design for stochastic nonlinear systems via contraction-based incremental stability,” IEEE Transactions on Automatic Control, vol. 60, no. 3, pp. 700–714, 2014
2014
-
[46]
Construction of lyapunov functions for interconnected parabolic systems: an iiss approach,
A. Mironchenko and H. Ito, “Construction of lyapunov functions for interconnected parabolic systems: an iiss approach,”SIAM Journal on Control and Optimization, vol. 53, no. 6, pp. 3364–3382, 2015
2015
-
[47]
Deep sets,
M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Poczos, R. R. Salakhutdinov, and A. J. Smola, “Deep sets,”Advances in neural information processing systems, vol. 30, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.