What Counts as an Error? Dual-Reference Benchmarking for Atypical ASR
Pith reviewed 2026-07-01 05:50 UTC · model grok-4.3
The pith
ASR model rankings on stuttered speech reverse when evaluators switch from intended to verbatim transcripts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using both verbatim and intended references on atypical stuttered speech reveals clear disparities in model performance and rankings across encoder-decoder, CTC, and transducer families. Most ASR evaluations conflate the two into a single ground truth and thereby reward deletion of disfluencies instead of verbatim faithfulness.
What carries the argument
Dual-reference benchmarking that measures word error rate against both the actual produced speech and the cleaned intended form on a stuttered speech dataset.
If this is right
- Model rankings can shift or reverse when the reference transcript style changes.
- Evaluations that use only intended references systematically favor systems that remove disfluencies.
- Valid model selection for atypical ASR requires matching the reference style to the intended use-case.
- Current single-reference benchmarks may not identify the best systems for applications needing verbatim output.
Where Pith is reading between the lines
- Similar ranking disparities could appear in other forms of atypical speech such as dysarthria if dual references are applied.
- Developers might need separate leaderboards for verbatim versus normalized transcription tasks.
- Training objectives could be adjusted to optimize for either reference style depending on downstream needs.
Load-bearing premise
That the verbatim and intended references are meaningfully distinct enough to affect rankings and that results on stuttered speech will hold for other atypical speech types.
What would settle it
Running the same eleven models on a larger, more diverse atypical speech corpus and finding that model rankings remain identical under both reference styles.
Figures

read the original abstract
ASR systems have been often reported to underperform on atypical speech. An often conflated compounding factor is the existence of two valid transcription references: verbatim (actual produced speech, including repetitions/prolongations) and intended (the canonical form of the text with disfluencies removed) in atypical speech recognition depending on context and use-case. Most ASR evaluations conflate this duality into a single ground truth and reward systems that delete disfluencies, ignoring verbatim faithfulness. We benchmark 11 ASR models from encoder-decoder, CTC and transducer families using both verbatim and intended references on atypical stuttered speech as a case study. Our quantitative assessment underlines the disparity in model performance and rankings using the two transcript styles. Through this analysis, we highlight the importance of selecting a suitable transcription reference for valid model selection depending on the use-case, particularly for atypical ASR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that ASR evaluations for atypical speech typically conflate two valid reference styles—verbatim (including disfluencies such as repetitions and prolongations) and intended (canonical form with disfluencies removed)—into a single ground truth, thereby rewarding deletion of disfluencies. Using stuttered speech as a case study, the authors benchmark 11 models spanning encoder-decoder, CTC, and transducer families on both reference styles and report that this produces disparities in model performance and rankings, underscoring the need to select the reference according to use-case.
Significance. If the reported ranking disparities are robust and the dual-reference distinction proves consequential beyond the specific dataset, the work would identify a systematic evaluation flaw in atypical ASR that affects model selection for applications requiring verbatim faithfulness versus fluent output. It would encourage context-aware benchmarking practices rather than defaulting to a single reference.
major comments (1)
- [Introduction and case-study description] The central claim that the findings apply to atypical ASR in general rests on the representativeness of the stuttered-speech dataset. The manuscript provides no evidence or comparison showing that the observed ranking shifts would arise under other atypical regimes (e.g., dysarthria or aphasia) whose disfluency/error patterns differ in structure and frequency; this assumption is load-bearing for the broader conclusion that most ASR evaluations are flawed for atypical speech.
minor comments (1)
- [Abstract] The abstract asserts a 'quantitative assessment' but supplies no numerical results, error bars, dataset sizes, or statistical tests; the full manuscript should make these explicit in the results section to allow verification of the disparity claim.
Simulated Author's Rebuttal
We thank the referee for this constructive comment on scope and generalizability. We agree that the manuscript's broader framing requires clarification to avoid overgeneralization from the stuttered-speech case study, and we will revise accordingly.
read point-by-point responses
-
Referee: [Introduction and case-study description] The central claim that the findings apply to atypical ASR in general rests on the representativeness of the stuttered-speech dataset. The manuscript provides no evidence or comparison showing that the observed ranking shifts would arise under other atypical regimes (e.g., dysarthria or aphasia) whose disfluency/error patterns differ in structure and frequency; this assumption is load-bearing for the broader conclusion that most ASR evaluations are flawed for atypical speech.
Authors: We accept this critique. The paper explicitly positions stuttered speech as a case study chosen because repetitions and prolongations create a clear verbatim/intended distinction; it does not provide data or comparisons for dysarthria, aphasia, or other atypical regimes. We will revise the introduction, abstract, and conclusion to (1) foreground the case-study framing, (2) remove or qualify language implying the ranking disparities necessarily generalize, and (3) add a limitations paragraph discussing how disfluency structures in other conditions might produce different or smaller effects. This addresses the load-bearing assumption without requiring new experiments. revision: yes
Circularity Check
Empirical benchmarking study with no derivations or self-referential reductions
full rationale
This is an empirical benchmarking paper that evaluates 11 ASR models on a stuttered speech dataset using two reference transcript styles (verbatim and intended). No equations, parameters, or derivations are present that could reduce to fitted inputs or self-definitions. Claims rest on direct performance measurements and ranking comparisons, which are externally falsifiable via the reported metrics and dataset. No self-citation chains are load-bearing for the central results, and the analysis does not rename known results or smuggle ansatzes. The study is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
What Counts as an Error? Dual-Reference Benchmarking for Atypical ASR
Introduction Atypical speech of persons who stutter (PWS) includes dis- fluencies (e.g. repetitions, prolongations, interjections) with variable frequencies depending on the stuttering severity level. Prior works document that current ASR and voice assistant sys- tems often fail for such atypical speech, with failure rates in- creasing as severity increas...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Related Work Performance and Biases of ASR for Atypical Speech.Mu- jtaba et al. [5] evaluated six ASR systems on real and synthetic stuttered speech using intended transcripts as the sole reference, quantifying ASR bias by comparing performance on fluent ver- sus stuttered speech with both WER and BERTScore. Notably, some works explicitly optimize for int...
-
[3]
However the study is lim- ited to the Whisper family (v2/v3)
benchmarked Whisper’s performance on stuttered speech and were the first to evaluate ASR model’s output against both intended and verbatim references. However the study is lim- ited to the Whisper family (v2/v3). Our work standardizes and extends this line of inquiry by formalizingverbatimvs.in- tendedtranscripts as two valid references for atypical speec...
-
[4]
Methodology Benchmarked Models.Our benchmark covers various ASR modeling paradigms. We compare these paradigms under the hypothesis that architectural and decoding design choices can systematically favor one transcription reference over the other: verbatim versus intended, independent of dataset-specific fac- tors. Although not all benchmarked models (sho...
-
[5]
accurate
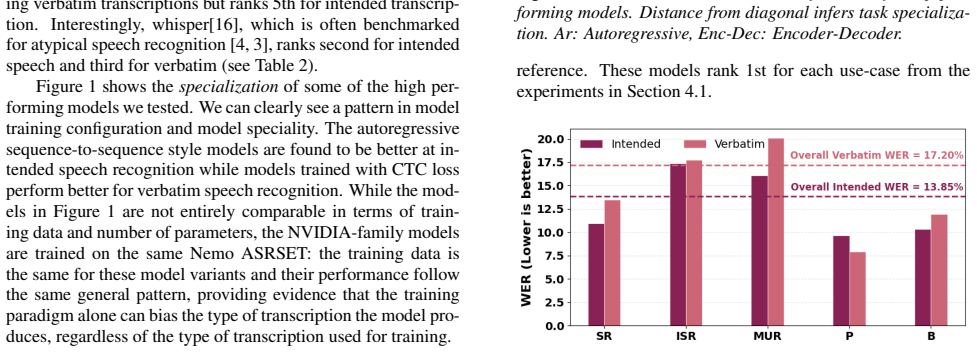
Results 4.1. ASR Model Ranking As we hypothesized, when we compare ASR models predic- tions against the two references we see inconsistent perfor- mance rankings. NVIDIA CTC model Ranks first for provid- ing verbatim transcriptions but ranks 5th for intended transcrip- tion. Interestingly, whisper[16], which is often benchmarked for atypical speech recogn...
-
[6]
Conclusion We argued that atypical ASR involves two valid transcription referencesintendedandverbatimand showed that conflating them into a single reference can misrepresent model capabil- ity. Benchmarking 11 ASR systems on FluencyBank Times- tamped with both references, we found substantial rank insta- bility: autoregressive seq2seq models tend to speci...
-
[7]
All experimentation and inter- pretations were carried out solely by the authors
Generative AI Use Disclosure Generative AI tool (Writefull) use is limited to sentence polish- ing for clarity of presentation. All experimentation and inter- pretations were carried out solely by the authors
-
[8]
C. Lea, Z. Huang, J. Narain, L. Tooley, D. Yee, T. D. Tran, P. Georgiou, J. Bigham, and L. Findlater, “From user percep- tions to technical improvement: Enabling people who stutter to better use speech recognition,” inCHI, 2023, available at: https: //arxiv.org/abs/2302.09044
-
[9]
Analysis and tuning of a voice assistant system for dysfluent speech,
V . Mitra, Z. Huang, C. S. Lea, L. Tooley, S. Wu, D. Botten, A. Palekar, S. Thelapurath, P. G. Georgiou, S. S. Kajarekar, and J. Bigham, “Analysis and tuning of a voice assistant system for dysfluent speech,” inInterspeech, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:235593228
2021
-
[10]
Fine-Tuning ASR for Stut- tered Speech: Personalized vs. Generalized Approaches,
D. Mujtaba and N. R. Mahapatra, “Fine-Tuning ASR for Stut- tered Speech: Personalized vs. Generalized Approaches,” inIn- terspeech 2025, 2025, pp. 3568–3572
2025
-
[11]
J-j-j-just stutter: Benchmark- ing whisper’s performance disparities on different stut- tering patterns,
C. Sridhar and S. Wu, “J-j-j-just stutter: Benchmark- ing whisper’s performance disparities on different stut- tering patterns,”Interspeech, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:281308675
2025
-
[12]
Lost in transcription: Identifying and quantifying the accuracy biases of automatic speech recognition systems against disfluent speech,
D. Mujtaba, N. Mahapatra, M. Arney, J. Yaruss, H. Gerlach- Houck, C. Herring, and J. Bin, “Lost in transcription: Identifying and quantifying the accuracy biases of automatic speech recognition systems against disfluent speech,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Langu...
2024
-
[13]
Findings of the 2024 mandarin stuttering event detection and automatic speech recognition challenge,
H. Xue, R. Gong, M. Shao, X. Xu, L. Wang, L. Xie, H. Bu, J. Zhou, Y . Qin, J. Du, M. Li, B. Zhang, and B. Jia, “Findings of the 2024 mandarin stuttering event detection and automatic speech recognition challenge,”2024 IEEE Spoken Language Technology Workshop (SLT), pp. 385–392, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:272524924
2024
-
[14]
Using clinician annotations to improve automatic speech recognition of stuttered speech,
P. A. Heeman, R. Lunsford, A. McMillin, and J. S. Yaruss, “Using clinician annotations to improve automatic speech recognition of stuttered speech,” inInterspeech, 2016. [Online]. Available: https://api.semanticscholar.org/CorpusID:1906213
2016
-
[15]
Fluencybank timestamped: An updated data set for disfluency detection and automatic intended speech recognition,
A. Romana, M. Niu, M. Perez, and E. M. Provost, “Fluencybank timestamped: An updated data set for disfluency detection and automatic intended speech recognition,”Journal of Speech, Language, and Hearing Research : JSLHR, vol. 67, pp. 4203 – 4215, 2024. [Online]. Available: https://api.semanticscholar.org/ CorpusID:273200647
2024
-
[16]
Clinical Annotations for Automatic Stuttering Severity Assessment,
A. Valente, R. Marew, H. Toyin, H. Al-Ali, A. Bohnen, I. Becerra, E. Soares, G. Leal, and H. Aldarmaki, “Clinical Annotations for Automatic Stuttering Severity Assessment,” inInterspeech 2025, 2025, pp. 4318–4322
2025
-
[17]
Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection,
J. Zhang, X. Zhou, J. Lian, S. Li, W. Li, Z. Ezzes, R. Bogley, L. Wauters, Z. Miller, J. V onk, B. Morin, M. Gorno-Tempini, and G. Anumanchipalli, “Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection,” inInterspeech, 2025, pp. 1853–1857
2025
-
[18]
Unconstrained dysfluency modeling for dysfluent speech transcription and detection,
J. Lian, C. Feng, N. Farooqi, S. Li, A. Kashyap, C. J. Cho, P. Wu, R. Netzorg, T. Li, and G. K. Anumanchipalli, “Unconstrained dysfluency modeling for dysfluent speech transcription and detection,”2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 1–8, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:266374895
2023
-
[19]
Au- tomatic recognition of children’s read speech for stuttering appli- cation,
S. Alharbi, A. J. H. Simons, S. Brumfitt, and P. D. Green, “Au- tomatic recognition of children’s read speech for stuttering appli- cation,” inWorkshop on Child, Computer and Interaction, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID: 14030764
2017
-
[20]
Improved robustness to disfluencies in rnn-transducer based speech recognition,
V . Mendelev, T. Raissi, G. Camporese, and M. Giollo, “Improved robustness to disfluencies in rnn-transducer based speech recognition,”IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6878–6882, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID: 228376178
2021
-
[21]
Conformer: Convolution-augmented Transformer for Speech Recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition,” in Interspeech 2020, 2020, pp. 5036–5040
2020
-
[22]
Proceedings of the 23rd International Conference on Machine Learning , series =
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” inProceedings of the 23rd International Conference on Machine Learning, ser. ICML ’06. New York, NY , USA: Association for Computing Machinery, 2006, p. 369–376. [Online]. Available: https://...
-
[23]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023
2023
-
[24]
SpeechBrain: A general- purpose speech toolkit,
M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong, J.-C. Chou, S.-L. Yeh, S.-W. Fu, C.-F. Liao, E. Rastorgueva, F. Grondin, W. Aris, H. Na, Y . Gao, R. D. Mori, and Y . Ben- gio, “SpeechBrain: A general-purpose speech toolkit,” 2021, arXiv:2106.04624
-
[25]
M. Sekoyan, N. R. Koluguri, N. Tadevosyan, P. Zelasko, T. Bartley, N. Karpov, J. Balam, and B. Ginsburg, “Canary- 1b-v2 & parakeet-tdt-0.6b-v3: Efficient and high-performance models for multilingual asr and ast,” 2025. [Online]. Available: https://arxiv.org/abs/2509.14128
-
[26]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 29, p. 3451–3460, Oct. 2021. [Online]. Available: https://doi.org/10.1109/TASLP.2021.3122291
-
[27]
wav2vec 2.0: a framework for self-supervised learning of speech representa- tions,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: a framework for self-supervised learning of speech representa- tions,” inProceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Associates Inc., 2020
2020
-
[28]
Fast conformer with linearly scalable attention for efficient speech recognition,
D. Rekesh, N. R. Koluguri, S. Kriman, S. Majumdar, V . Noroozi, H. Huang, O. Hrinchuk, K. C. Puvvada, A. Kumar, J. Balam, and B. Ginsburg, “Fast conformer with linearly scalable attention for efficient speech recognition,” inIEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2023, Taipei, Taiwan, December 16-20, 2023. IEEE, 2023, pp. 1–8. ...
-
[29]
Quartznet: Deep automatic speech recognition with 1d time-channel separable con- volutions,
S. Kriman, S. Beliaev, B. Ginsburg, J. Huang, O. Kuchaiev, V . Lavrukhin, R. Leary, J. Li, and Y . Zhang, “Quartznet: Deep automatic speech recognition with 1d time-channel separable con- volutions,”IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6124–6128, 2020
2020
-
[30]
Fluency bank: A new resource for fluency research and practice,
N. Ratner and B. Macwhinney, “Fluency bank: A new resource for fluency research and practice,”Journal of Fluency Disorders, vol. 56, 03 2018
2018
-
[31]
SeMaScore: A new evaluation metric for automatic speech recognition tasks,
Z. Sasindran, H. Yelchuri, and T. V . Prabhakar, “SeMaScore: A new evaluation metric for automatic speech recognition tasks,” in Interspeech, 2024, pp. 4558–4562
2024
-
[32]
Bertscore: Evaluating text generation with BERT,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with BERT,” in8th International Conference on Learning Representations, ICLR, Addis Ababa, Ethiopia, April 26-30, 2020. [Online]. Available: https://openreview.net/forum?id=SkeHuCVFDr
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.