MemLearner: Learning to Query Context memory for Video World Models
Pith reviewed 2026-07-01 05:28 UTC · model grok-4.3
The pith
Learned query tokens let video world models maintain scene consistency over long sequences with occlusions and motion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemLearner is a learning-based adaptive context query method that inserts query tokens to bridge stored context frames and newly predicted tokens. By letting the video generation model itself perform the querying, the approach exploits pre-trained visual priors and avoids training extra modules from scratch. Training uses a multi-dataset strategy on long videos with camera pose annotations, combining annotated rendered sequences and unannotated real-world footage. Experiments show this yields stronger scene consistency and memory than prior rule-based retrieval, especially when objects are occluded or moving.
What carries the argument
Query tokens inserted to bridge context frames and predicted tokens, allowing the pre-trained model to learn adaptive retrieval of relevant history.
If this is right
- Scene consistency improves in videos with frequent occlusions and dynamic objects.
- Training succeeds on mixed datasets of annotated rendered videos and unannotated real videos.
- No new modules need training from scratch because the existing generation model supplies the priors.
- Efficient training and inference strategies become possible once query tokens replace manual retrieval rules.
Where Pith is reading between the lines
- The same token-based querying idea could transfer to other sequence models that need long-term memory without extra retrieval networks.
- Performance on very long horizons beyond the training lengths would test whether the learned queries scale without drift.
- Combining the query mechanism with explicit action inputs might further stabilize predictions in interactive settings.
- The multi-dataset strategy suggests similar gains are possible in other domains that mix synthetic and real sequential data.
Load-bearing premise
That the pre-trained video generation model already holds enough visual knowledge for its own query tokens to retrieve useful context more effectively than any fixed rule-based method.
What would settle it
Run both MemLearner and a strong rule-based baseline on a held-out set of long videos containing repeated full occlusions of moving objects and measure whether object identities and layouts remain consistent for more than 30 seconds.
Figures

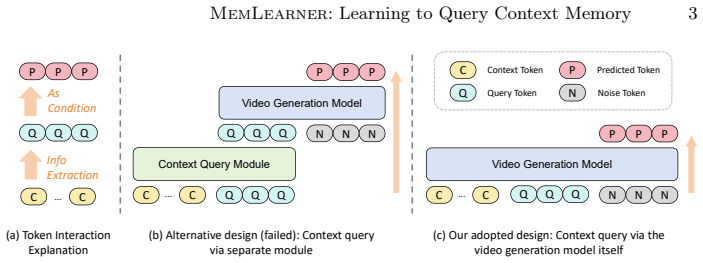
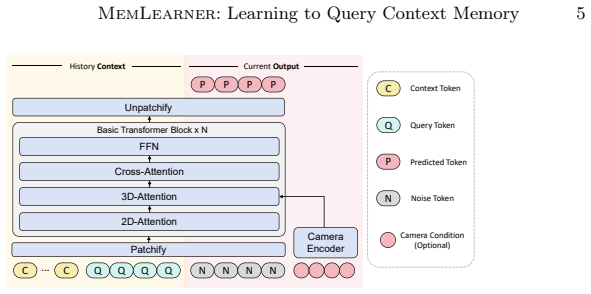





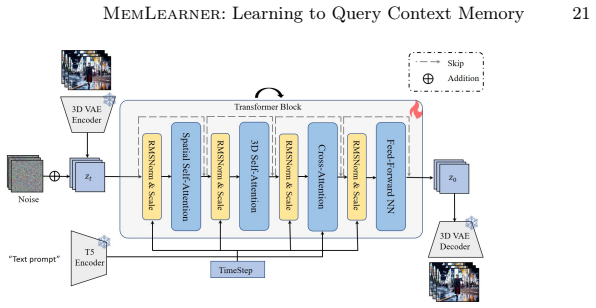


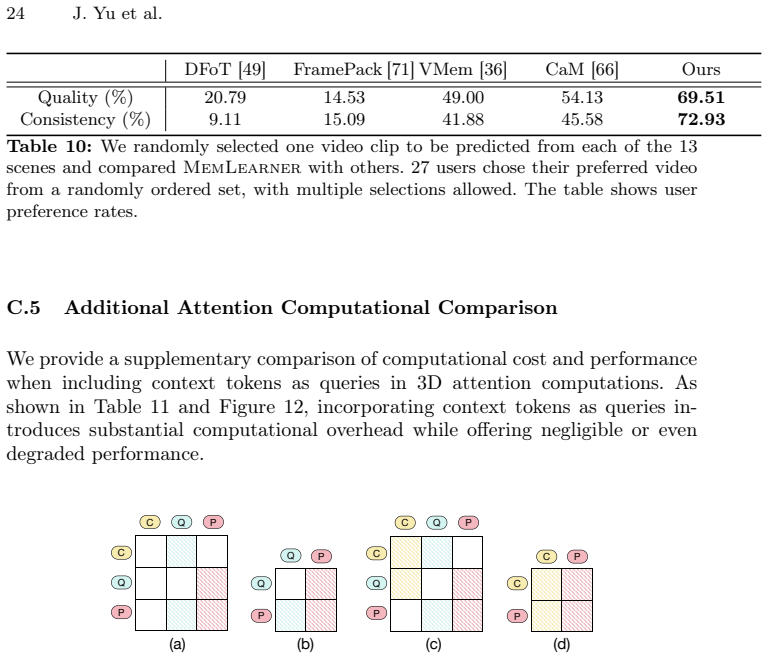


read the original abstract
Video World Models are interactive video generation models that predict future world states based on user actions and history video frames. A critical challenge in video world models is the lack of memory, causing inconsistent generated scenes over extended durations. Previous methods explored rule-based context frame retrieval as memory, but they fail to generalize in scenarios with scene occlusions and dynamic objects. We propose MemLearner, a learning-based adaptive context query method using query tokens to bridge context and predicted tokens. By leveraging the video generation model itself for context querying, MemLearner exploits pre-trained visual priors without training additional modules from scratch, and incorporates efficient strategies for training and inference. We collect a dataset of long videos with scene occlusions and dynamic objects, paired with camera pose annotations, and propose a multi-dataset training strategy leveraging both annotated rendered and unannotated real-world videos. Extensive experiments demonstrate that MemLearner significantly outperforms prior video world models in terms of scene consistency and memory, particularly under challenging occlusion and dynamic scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemLearner, a learning-based method that inserts query tokens into a frozen pre-trained video generator to perform adaptive context retrieval as memory for video world models. It collects a dataset of long videos with occlusions and dynamic objects (with camera poses), uses a multi-dataset training regime on both rendered and real videos, and claims this yields better scene consistency than rule-based retrieval without training new modules from scratch.
Significance. If the empirical claims hold, the approach would demonstrate that query-token mechanisms can exploit pre-trained visual priors for memory in long-horizon video generation, offering a lightweight alternative to rule-based or fully retrained memory modules under occlusion and dynamics.
major comments (1)
- [Abstract] Abstract: the central claim that MemLearner 'significantly outperforms prior video world models in terms of scene consistency and memory' is asserted without any metrics, baselines, ablation results, or experimental details, so the primary empirical contribution cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for their feedback on the abstract. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that MemLearner 'significantly outperforms prior video world models in terms of scene consistency and memory' is asserted without any metrics, baselines, ablation results, or experimental details, so the primary empirical contribution cannot be assessed.
Authors: We agree that the abstract presents the performance claim without supporting quantitative details, which limits immediate assessment of the empirical contribution. The full manuscript contains the requested elements (metrics, baselines, ablations) in the Experiments section. We will revise the abstract to include key quantitative results and baseline comparisons that substantiate the claim. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical ML architecture (query tokens inserted into a frozen pre-trained video generator) trained on a newly collected multi-dataset regime of long occluded/dynamic videos. No derivation chain, equations, or first-principles result is presented that reduces a claimed prediction to a quantity defined by the method's own fitted parameters. Performance claims rest on experimental comparisons rather than self-referential definitions or load-bearing self-citations. The construction is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Video world models lack memory causing inconsistent generated scenes over extended durations
- domain assumption Rule-based context frame retrieval fails to generalize in scenarios with scene occlusions and dynamic objects
invented entities (1)
-
query tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ai, S., Teng, H., Jia, H., Sun, L., Li, L., Li, M., Tang, M., Han, S., Zhang, T., Zhang, W.Q., Luo, W., Kang, X., Sun, Y., Cao, Y., Huang, Y., Lin, Y., Fang, Y., Tao, Z., Zhang, Z., Wang, Z., Liu, Z., Shi, D., Su, G., Sun, H., Pan, H., Wang, J., Sheng, J., Cui, M., Hu, M., Yan, M., Yin, S., Zhang, S., Liu, T., Yin, X., Yang, X., Song, X., Hu, X., Zhang, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022)
2022
-
[3]
arXiv preprint arXiv:2507.02001 (2025)
Arnab, A., Iscen, A., Caron, M., Fathi, A., Schmid, C.: Temporal chain of thought: Long-video understanding by thinking in frames. arXiv preprint arXiv:2507.02001 (2025)
-
[4]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al.: V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2503.11647 (2025)
Bai, J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H.,Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. arXiv preprint arXiv:2503.11647 (2025)
-
[6]
Yu et al
Ball, P.J., Bauer, J., Belletti, F., Brownfield, B., Ephrat, A., Fruchter, S., Gupta, A., Holsheimer, K., Holynski, A., Hron, J., Kaplanis, C., Limont, M., McGill, M., Oliveira, Y., Parker-Holder, J., Perbet, F., Scully, G., Shar, J., Spencer, S., Tov, O., Villegas, R., Wang, E., Yung, J., Baetu, C., Berbel, J., Bridson, D., Bruce, J., Buttimore, G., Chak...
2025
-
[7]
Bao, F., Xiang, C., Yue, G., He, G., Zhu, H., Zheng, K., Zhao, M., Liu, S., Wang, Y., Zhu, J.: Vidu: a highly consistent, dynamic and skilled text-to-video generator with diffusion models. arXiv preprint arXiv:2405.04233 (2024)
-
[8]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Buch, S., Nagrani, A., Arnab, A., Schmid, C.: Flexible frame selection for efficient video reasoning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29071–29082 (2025)
2025
-
[10]
In: arXiv (2025)
Cai, S., Yang, C., Zhang, L., Guo, Y., Xiao, J., Yang, Z., Xu, Y., Yang, Z., Yuille, A., Guibas, L., Agrawala, M., Jiang, L., Wetzstein, G.: Mixture of contexts for long video generation. In: arXiv (2025)
2025
-
[11]
arXiv preprint arXiv:2407.01392 (2024)
Chen, B., Monso, D.M., Du, Y., Simchowitz, M., Tedrake, R., Sitzmann, V.: Dif- fusion forcing: Next-token prediction meets full-sequence diffusion. arXiv preprint arXiv:2407.01392 (2024)
-
[12]
VRAG: Learning World Models for Interactive Video Generation
Chen, T., Hu, X., Ding, Z., Jin, C.: Learning world models for interactive video generation. arXiv preprint arXiv:2505.21996 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Cui, J., Wu, J., Li, M., Yang, T., Li, X., Wang, R., Bai, A., Ban, Y., Hsieh, C.J.: Self-forcing++: Towards minute-scale high-quality video generation. arXiv preprint arXiv:2510.02283 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Cui, Y., Chen, H., Deng, H., Huang, X., Li, X., Liu, J., Liu, Y., Luo, Z., Wang, J., Wang, W., Wang, Y., Wang, C., Zhang, F., Zhao, Y., Pan, T., Li, X., Hao, Z., Ma, W., Chen, Z., Ao, Y., Huang, T., Wang, Z., Wang, X.: Emu3.5: Native multimodal models are world learners (2025),https://arxiv.org/abs/2510.26583
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
In: Proceedings of the European Conference on Computer Vision (ECCV) (2018)
Damen, D., Doughty, H., Farinella, G.M., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., Wray, M.: Scaling egocentric vision: The epic-kitchens dataset. In: Proceedings of the European Conference on Computer Vision (ECCV) (2018)
2018
-
[16]
Decart, E.: Oasis: A universe in a transformer.https://oasis-model.github.io/ (2024)
2024
-
[17]
DeepMind, G.: Veo 2: Our state-of-the-art video generation model.https:// deepmind.google/technologies/veo/veo-2/(2024)
2024
-
[18]
Autoregressive Video Generation without Vector Quantization
Deng, H., Pan, T., Diao, H., Luo, Z., Cui, Y., Lu, H., Shan, S., Qi, Y., Wang, X.: Autoregressive video generation without vector quantization. arXiv preprint arXiv:2412.14169 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
In: ICLR (2025)
Fu, X., Liu, X., Wang, X., Peng, S., Xia, M., Shi, X., Yuan, Z., Wan, P., Zhang, D., Lin, D.: 3dtrajmaster: Mastering 3d trajectory for multi-entity motion in video generation. In: ICLR (2025)
2025
-
[20]
Long-Context Autoregressive Video Modeling with Next-Frame Prediction
Gu, Y., Mao, W., Shou, M.Z.: Long-context autoregressive video modeling with next-frame prediction. arXiv preprint arXiv:2503.19325 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
arXiv preprint arXiv:2503.10589 (2025)
Guo, Y., Yang, C., Yang, Z., Ma, Z., Lin, Z., Yang, Z., Lin, D., Jiang, L.: Long context tuning for video generation. arXiv preprint arXiv:2503.10589 (2025)
-
[22]
Ha, D., Schmidhuber, J.: Recurrent world models facilitate policy evolution31 (2018)
2018
-
[23]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022) MemLearner: Learning to Query Context Memory 17
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Hong, Y., Mei, Y., Ge, C., Xu, Y., Zhou, Y., Bi, S., Hold-Geoffroy, Y., Roberts, M., Fisher, M., Shechtman, E., et al.: Relic: Interactive video world model with long-horizon memory. arXiv preprint arXiv:2512.04040 (2025)
-
[26]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: Vbench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[28]
Nature638(8051), 656–663 (2025)
Kanervisto, A., Bignell, D., Wen, L.Y., Grayson, M., Georgescu, R., Valcar- cel Macua, S., Tan, S.Z., Rashid, T., Pearce, T., Cao, Y., et al.: World and human action models towards gameplay ideation. Nature638(8051), 656–663 (2025)
2025
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, S.W., Zhou, Y., Philion, J., Torralba, A., Fidler, S.: Learning to simulate dy- namic environments with gamegan. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1231–1240 (2020)
2020
-
[30]
Kingma, D.P., Welling, M., et al.: Auto-encoding variational bayes (2013)
2013
-
[31]
Kling: Kling ai: Next-generation ai creative studio.https://app.klingai.com/ (2024)
2024
-
[32]
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Kondratyuk, D., Yu, L., Gu, X., Lezama, J., Huang, J., Schindler, G., Hornung, R., Birodkar, V., Yan, J., Chiu, M.C., et al.: Videopoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Labs, W.: Generating worlds.https://www.worldlabs.ai/blog/generating- worlds(2024)
2024
-
[35]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[36]
arXiv preprint arXiv:2506.18903 (2025)
Li, R., Torr, P., Vedaldi, A., Jakab, T.: Vmem: Consistent interactive video scene generation with surfel-indexed view memory. arXiv preprint arXiv:2506.18903 (2025)
-
[37]
arXiv preprint arXiv:2406.11838 (2024)
Li, T., Tian, Y., Li, H., Deng, M., He, K.: Autoregressive image generation without vector quantization. arXiv preprint arXiv:2406.11838 (2024)
-
[38]
Li, W., Pan, W., Luan, P.C., Gao, Y., Alahi, A.: Stable video infinity: Infinite- length video generation with error recycling. arXiv preprint arXiv:2510.09212 (2025)
-
[39]
arXiv preprint arXiv:2506.15675 (2025)
Li, Z., Li, C., Mao, X., Lin, S., Li, M., Zhao, S., Xu, Z., Li, X., Feng, Y., Sun, J., Li, Z., Zhang, F., Ai, J., Wang, Z., Wu, Y., He, T., Pang, J., Qiao, Y., Jia, Y., Zhang, K.: Sekai: A video dataset towards world exploration. arXiv preprint arXiv:2506.15675 (2025)
-
[40]
In: Proceedings of the IEEE/CVF international conference on computer vision (2025)
Li, Z., Yu, H.X., Liu, W., Yang, Y., Herrmann, C., Wetzstein, G., Wu, J.: Wonder- play: Dynamic 3d scene generation from a single image and actions. In: Proceedings of the IEEE/CVF international conference on computer vision (2025)
2025
-
[41]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Liu, K., Hu, W., Xu, J., Shan, Y., Lu, S.: Rolling forcing: Autoregressive long video diffusion in real time. arXiv preprint arXiv:2509.25161 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
arXiv preprint arXiv:2412.06699 (2024) 18 J
Ma, B., Gao, H., Deng, H., Luo, Z., Huang, T., Tang, L., Wang, X.: You see it, you got it: Learning 3d creation on pose-free videos at scale. arXiv preprint arXiv:2412.06699 (2024) 18 J. Yu et al
-
[43]
OpenAI: Creating video from text.https://openai.com/index/sora/(2024)
2024
-
[44]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2023)
2023
-
[45]
Po, R., Nitzan, Y., Zhang, R., Chen, B., Dao, T., Shechtman, E., Wetzstein, G., Huang, X.: Long-context state-space video world models (2025),https://arxiv. org/abs/2505.20171
-
[46]
In: International conference on machine learning (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning (2021)
2021
-
[47]
arXiv preprint arXiv:2503.03751 (2025)
Ren,X.,Shen,T.,Huang,J.,Ling,H.,Lu,Y.,Nimier-David,M.,Müller,T.,Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video generation with precise camera control. arXiv preprint arXiv:2503.03751 (2025)
-
[48]
Runway: Runway : Tools for human imagination.https://runwayml.com/(2024)
2024
-
[49]
History-Guided Video Diffusion
Song, K., Chen, B., Simchowitz, M., Du, Y., Tedrake, R., Sitzmann, V.: History- guided video diffusion. arXiv preprint arXiv:2502.06764 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Sun, W., Zhang, H., Wang, H., Wu, J., Wang, Z., Wang, Z., Wang, Y., Zhang, J., Wang, T., Guo, C.: Worldplay: Towards long-term geometric consistency for real-time interactive world modeling. arXiv preprint arXiv:2512.14614 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Diffusion Models Are Real-Time Game Engines
Valevski, D., Leviathan, Y., Arar, M., Fruchter, S.: Diffusion models are real-time game engines. arXiv preprint arXiv:2408.14837 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Wan: Open and Advanced Large-Scale Video Generative Models
Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [53]
-
[54]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
In: ACM SIGGRAPH 2024 Conference Papers (2024)
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers (2024)
2024
- [56]
-
[57]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, Z., Xiong, C., Ma, C.Y., Socher, R., Davis, L.S.: Adaframe: Adaptive frame selection for fast video recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1278–1287 (2019)
2019
-
[58]
arXiv preprint arXiv:2504.12369 (2025)
Xiao, Z., Lan, Y., Zhou, Y., Ouyang, W., Yang, S., Zeng, Y., Pan, X.: Worldmem: Long-term consistent world simulation with memory. arXiv preprint arXiv:2504.12369 (2025)
-
[59]
VideoGPT: Video Generation using VQ-VAE and Transformers
Yan, W., Zhang, Y., Abbeel, P., Srinivas, A.: Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[60]
In: Proceedings of the 41st International Conference on Machine Learning (2024)
Yang, S., Walker, J.C., Parker-Holder, J., Du, Y., Bruce, J., Barreto, A., Abbeel, P., Schuurmans, D.: Position: Video as the new language for real-world decision making. In: Proceedings of the 41st International Conference on Machine Learning (2024)
2024
-
[61]
Yang, S., Huang, W., Chu, R., Xiao, Y., Zhao, Y., Wang, X., Li, M., Xie, E., Chen, Y., Lu, Y., Chen, S.H.Y.: Longlive: Real-time interactive long video generation (2025) MemLearner: Learning to Query Context Memory 19
2025
-
[62]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yao, Y., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., Cai, T., Li, H., Zhao, W., He, Z., et al.: Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yu, H.X., Duan, H., Herrmann, C., Freeman, W.T., Wu, J.: Wonderworld: Inter- active 3d scene generation from a single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5916–5926 (June 2025)
2025
-
[65]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, H.X., Duan, H., Hur, J., Sargent, K., Rubinstein, M., Freeman, W.T., Cole, F., Sun, D., Snavely, N., Wu, J., et al.: Wonderjourney: Going from anywhere to everywhere. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6658–6667 (2024)
2024
-
[66]
Yu, J., Bai, J., Qin, Y., Liu, Q., Wang, X., Wan, P., Zhang, D., Liu, X.: Context as memory: Scene-consistent interactive long video generation with memory retrieval. arXiv preprint arXiv:2506.03141 (2025)
-
[67]
A survey of interactive generative video,
Yu, J., Qin, Y., Che, H., Liu, Q., Wang, X., Wan, P., Zhang, D., Gai, K., Chen, H., Liu, X.: A survey of interactive generative video. arXiv preprint arXiv:2504.21853 (2025)
-
[68]
arXiv preprint arXiv:2503.17359 (2025)
Yu, J., Qin, Y., Che, H., Liu, Q., Wang, X., Wan, P., Zhang, D., Liu, X.: Posi- tion: Interactive generative video as next-generation game engine. arXiv preprint arXiv:2503.17359 (2025)
-
[69]
Yu, J., Qin, Y., Wang, X., Wan, P., Zhang, D., Liu, X.: Gamefactory: Creating new games with generative interactive videos (2025)
2025
-
[70]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. arXiv preprint arXiv:2409.02048 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Zhang, L., Agrawala, M.: Packing input frame context in next-frame prediction models for video generation. arXiv preprint arXiv:2504.12626 (2025)
-
[72]
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
Zhou, G., Pan, H., LeCun, Y., Pinto, L.: Dino-wm: World models on pre-trained visual features enable zero-shot planning. arXiv preprint arXiv:2411.04983 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Learning 3d persistent embodied world models.arXiv preprint arXiv:2505.05495, 2025
Zhou, S., Du, Y., Yang, Y., Han, L., Chen, P., Yeung, D.Y., Gan, C.: Learning 3d persistent embodied world models. arXiv preprint arXiv:2505.05495 (2025)
-
[74]
Zhou, Y., Wang, Y., Zhou, J., Chang, W., Guo, H., Li, Z., Ma, K., Li, X., Wang, Y., Zhu, H., Liu, M., Liu, D., Yang, J., Fu, Z., Chen, J., Shen, C., Pang, J., Zhang, K., He, T.: Omniworld: A multi-domain and multi-modal dataset for 4d world modeling (2025),https://arxiv.org/abs/2509.12201
-
[75]
Irasim: Learning interactive real-robot action simulators
Zhu, F., Wu, H., Guo, S., Liu, Y., Cheang, C., Kong, T.: Irasim: Learning interac- tive real-robot action simulators. arXiv preprint arXiv:2406.14540 (2024) 20 J. Yu et al. A Details of Collected Dataset 3D Scenes and Dynamic Objects.We collect 13 diverse 3D scene assets from Fab.com5. To minimize the domain gap between rendered data and real-world videos...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.