PolicyGuard: From Organizational Policies to Neuro-SymbolicCompliance Review Engines
Pith reviewed 2026-07-01 05:02 UTC · model grok-4.3
The pith
PolicyGuard converts organizational policies into typed logic rules and local extraction questions so LLMs and symbolic evaluation can check document compliance explicitly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
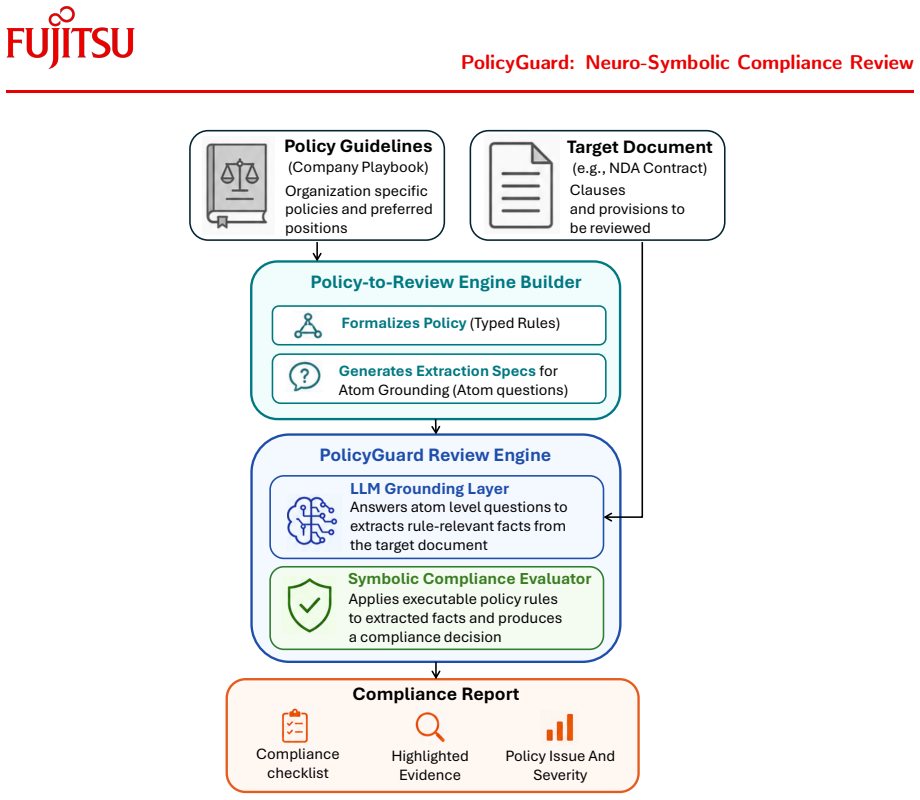
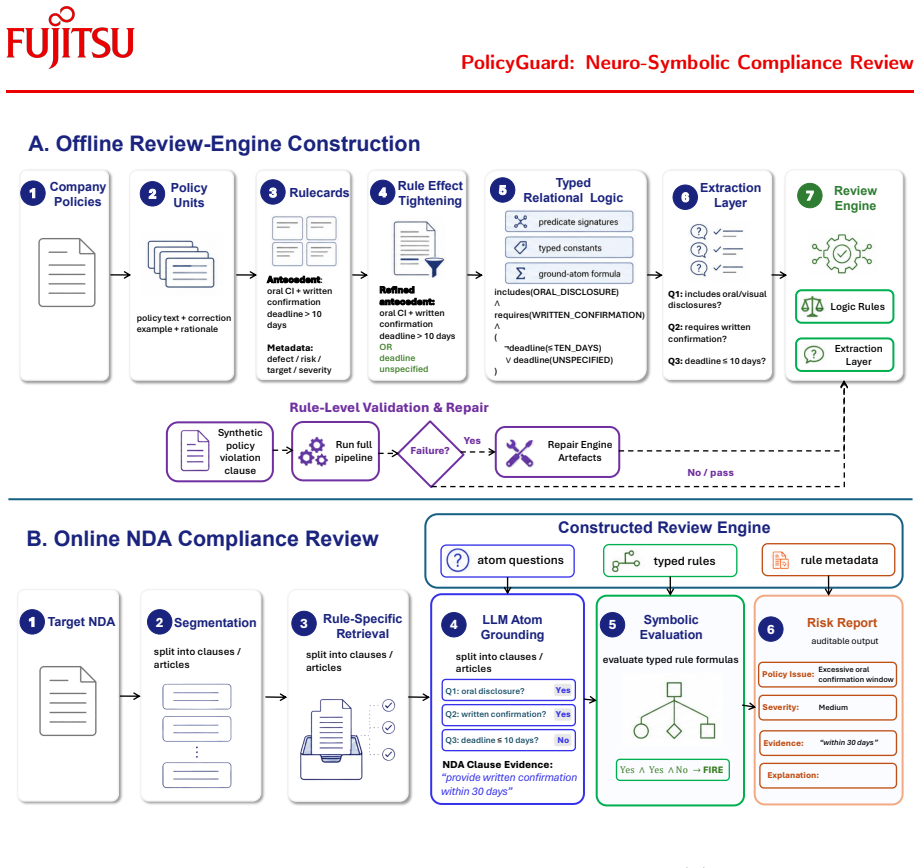
PolicyGuard converts organizational policy guidance into an executable review engine consisting of typed relational logic rules and atom-level extraction questions. During review, LLMs answer these local questions using retrieved document evidence, and a symbolic evaluator applies the formal rules to detect non-compliance. By separating policy formalization, local document interpretation, and symbolic compliance evaluation, the framework makes document review more explicit, maintainable, and systematically testable.
What carries the argument
The executable review engine built from typed relational logic rules and atom-level extraction questions, with LLMs limited to answering the questions and a symbolic evaluator applying the rules.
If this is right
- Compliance decisions become inspectable by tracing which rules fired and which LLM answers supported them.
- Policy changes require only editing the logic rules rather than retraining or rewriting prompts.
- Individual components can be tested and debugged separately instead of only evaluating final outputs.
- The same engine structure can be reused across different organizational policies by swapping the rule set.
Where Pith is reading between the lines
- The method could be applied to other high-stakes document checks such as regulatory filings or internal audit reports.
- Explicit rules might allow organizations to maintain version control over their compliance logic in the same way they version code.
- Combining the engine with human oversight loops could let reviewers focus only on disputed LLM answers rather than reading entire documents.
Load-bearing premise
Large language models can reliably and correctly answer the atom-level extraction questions when given retrieved document evidence.
What would settle it
A set of NDA documents where the LLM returns incorrect answers to one or more extraction questions, causing the symbolic evaluator to reach a compliance verdict that differs from expert human review of the same clauses.
Figures
read the original abstract
Policy-grounded document review requires determining whether a target document complies with organization-specific policies, guidelines, or playbooks. While large language models can assist with policy interpretation and document analysis, end-to-end prompting leaves the applied policy logic implicit, making compliance decisions difficult to inspect, update, and test. We present PolicyGuard, a neuro-symbolic framework for policy-grounded document compliance review. PolicyGuard converts organizational policy guidance into an executable review engine consisting of typed relational logic rules and atom-level extraction questions. During review, LLMs answer these local questions using retrieved document evidence, and a symbolic evaluator applies the formal rules to detect non-compliance. We instantiate and evaluate PolicyGuard on company-specific NDA compliance review, where contract clauses must be checked against organization-specific negotiation policies. By separating policy formalization, local document interpretation, and symbolic compliance evaluation, PolicyGuard makes document review more explicit, maintainable, and systematically testable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PolicyGuard, a neuro-symbolic framework that converts organizational policy guidance into an executable review engine of typed relational logic rules and atom-level extraction questions. LLMs answer the local questions using retrieved document evidence, after which a symbolic evaluator applies the formal rules to detect non-compliance. The framework is instantiated on company-specific NDA compliance review, with the central claim that separating policy formalization, local document interpretation, and symbolic compliance evaluation makes document review more explicit, maintainable, and systematically testable.
Significance. If the empirical premise holds, the explicit separation of concerns would address the opacity of end-to-end LLM prompting for policy-grounded review, enabling more inspectable, updatable, and testable compliance engines in organizational settings. The neuro-symbolic design is a clear strength in principle for domains requiring auditability.
major comments (1)
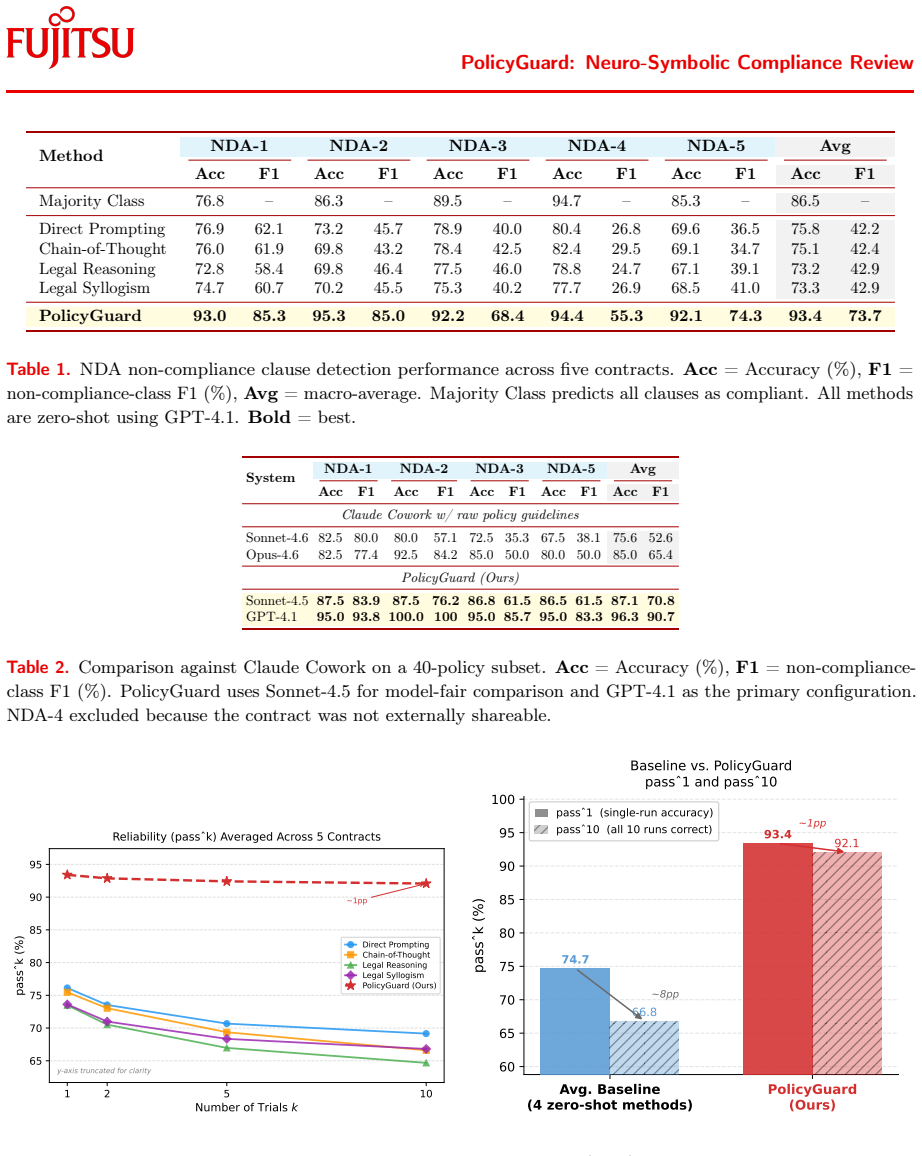
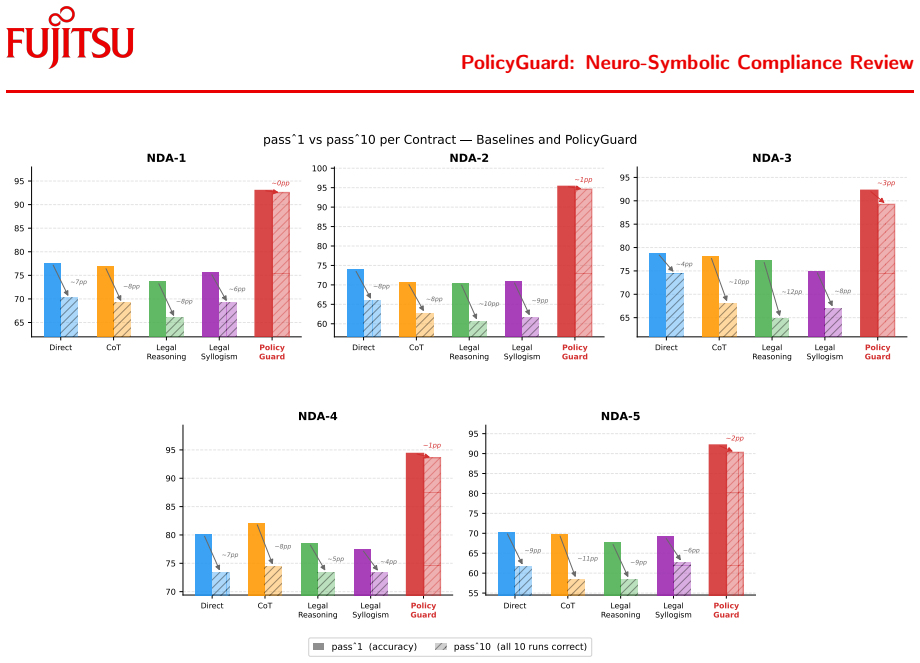
- [Abstract] Abstract and high-level description: the claim that PolicyGuard makes review 'systematically testable' depends on reliable LLM answers to atom-level extraction questions, yet the manuscript supplies no quantitative results on extraction accuracy, inter-annotator agreement with human experts, or error analysis on the NDA task, leaving the load-bearing assumption unverified.
Simulated Author's Rebuttal
We thank the referee for highlighting this important empirical gap. The point is well-taken and directly affects the strength of our central claim.
read point-by-point responses
-
Referee: [Abstract] Abstract and high-level description: the claim that PolicyGuard makes review 'systematically testable' depends on reliable LLM answers to atom-level extraction questions, yet the manuscript supplies no quantitative results on extraction accuracy, inter-annotator agreement with human experts, or error analysis on the NDA task, leaving the load-bearing assumption unverified.
Authors: We agree that the manuscript does not currently report quantitative metrics on the accuracy of the atom-level LLM extractions, inter-annotator agreement, or a dedicated error analysis for the NDA task. While the end-to-end compliance results provide indirect support, they do not isolate extraction reliability, which is indeed required to substantiate the claim that the framework enables systematic testing. In the revised manuscript we will add a new subsection under Evaluation that reports (i) precision, recall, and F1 of the LLM answers against human gold annotations on a held-out set of NDA clauses, (ii) inter-annotator agreement statistics, and (iii) a qualitative error analysis categorizing failure modes. This will directly verify the assumption underlying the testability claim. revision: yes
Circularity Check
No circularity; framework description contains no derivations or self-referential reductions
full rationale
The paper describes a neuro-symbolic framework separating policy formalization, local LLM-based interpretation via atom-level questions, and symbolic rule evaluation. No equations, parameters, or derivations are present in the provided text. The central claim that the separation makes review 'more explicit, maintainable, and systematically testable' is a descriptive assertion about system design, not a mathematical result that reduces to its inputs by construction. LLM reliability on extraction questions is an unverified empirical premise (as noted in the skeptic attack), but this is a correctness risk rather than circularity. No self-citations, ansatzes, or renamings of known results are invoked in a load-bearing way. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can reliably answer atom-level extraction questions using retrieved document evidence.
- domain assumption Organizational policies can be converted into typed relational logic rules without significant loss of intended meaning.
invented entities (1)
-
PolicyGuard review engine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[3]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[4]
Dan Gusfield , title =. 1997
1997
-
[5]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[6]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[7]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =
2022
-
[8]
Proceedings of the Nineteenth International Conference on Artificial Intelligence and Law , pages =
Legal Syllogism Prompting: Teaching Large Language Models for Legal Judgment Prediction , author =. Proceedings of the Nineteenth International Conference on Artificial Intelligence and Law , pages =. 2023 , publisher =. doi:10.1145/3594536.3595170 , url =
-
[9]
Advances in Neural Information Processing Systems , volume =
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed Chi and Quoc Le and Denny Zhou , title =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =
2022
-
[10]
Findings of the Association for Computational Linguistics:
Sergio Servantez and Joe Barrow and Kristian Hammond and Rajiv Jain , title =. Findings of the Association for Computational Linguistics:
-
[11]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao and Noah Shinn and Pedram Razavi and Karthik Narasimhan , title =. arXiv preprint arXiv:2406.12045 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing
Nils Reimers and Iryna Gurevych , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 2019 , publisher =
2019
-
[13]
2025 , howpublished =
Introducing GPT-4.1 in the API , author =. 2025 , howpublished =
2025
-
[14]
2025 , howpublished =
Claude Sonnet 4.5 System Card , author =. 2025 , howpublished =
2025
-
[15]
Qwen3 Technical Report , author =. arXiv preprint arXiv:2505.09388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2024 , howpublished =
Llama 3.3 Model Card , author =. 2024 , howpublished =
2024
-
[17]
Tools and Algorithms for the Construction and Analysis of Systems, 14th International Conference,
Z3: An Efficient SMT Solver , author =. Tools and Algorithms for the Construction and Analysis of Systems, 14th International Conference,
-
[18]
Proceedings of the Workshop on Natural Legal Language Processing (NLLP 2022) , year =
Fangyi Yu and Lee Quartey and Frank Schilder , title =. Proceedings of the Workshop on Natural Legal Language Processing (NLLP 2022) , year =
2022
-
[19]
Proceedings of the Nineteenth International Conference on Artificial Intelligence and Law , pages =
Cong Jiang and Xiaolei Yang , title =. Proceedings of the Nineteenth International Conference on Artificial Intelligence and Law , pages =. 2023 , publisher =
2023
-
[20]
Advances in Neural Information Processing Systems , volume =
Takeshi Kojima and Shixiang Shane Gu and Machel Reid and Yutaka Matsuo and Yusuke Iwasawa , title =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[21]
Hendrycks, Dan and Burns, Collin and Chen, Anya and Ball, Spencer , booktitle =
-
[22]
, booktitle =
Koreeda, Yuta and Manning, Christopher D. , booktitle =
-
[23]
Guha, Neel and Nyarko, Julian and Ho, Daniel E. and R. Advances in Neural Information Processing Systems , year =
-
[24]
Journal of Legal Analysis , volume =
Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models , author =. Journal of Legal Analysis , volume =
-
[25]
Chen, Zhaorun and Kang, Mintong and Li, Bo , year =. 2503.22738 , archivePrefix =
-
[26]
Miculicich, Lesly and Parmar, Mihir and Palangi, Hamid and Dvijotham, Krishnamurthy Dj and Montanari, Mirko and Pfister, Tomas and Le, Long T. , year =. 2510.05156 , archivePrefix =
-
[27]
Publication Manual of the American Psychological Association , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.