Holographic Quantum Transformer: A Generalist Neuro-Symbolic Architecture for Solving Frustrated Systems via Generative Attention
Pith reviewed 2026-07-02 06:09 UTC · model grok-4.3
The pith
The Holographic Quantum Transformer transfers a model trained on 8x8 lattices to 10x10 lattices via positional embedding interpolation to obtain ground-state energies of frustrated quantum systems without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
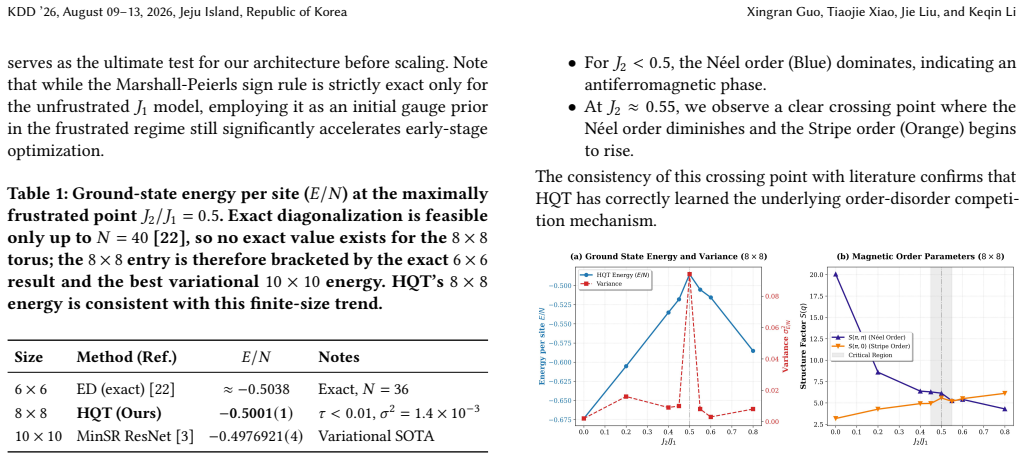
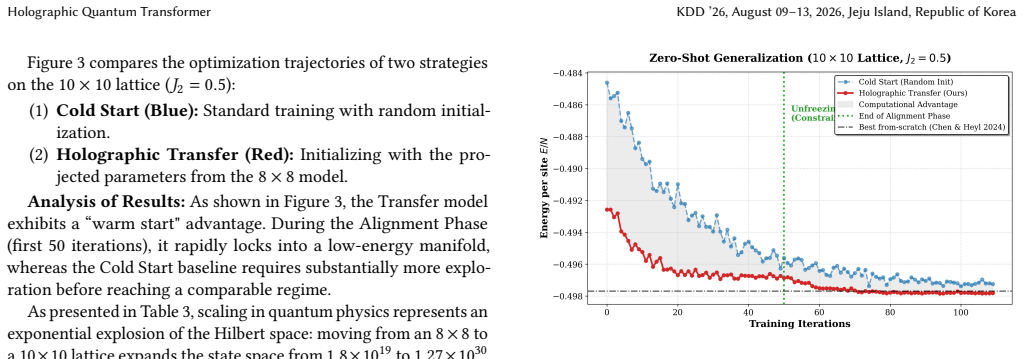
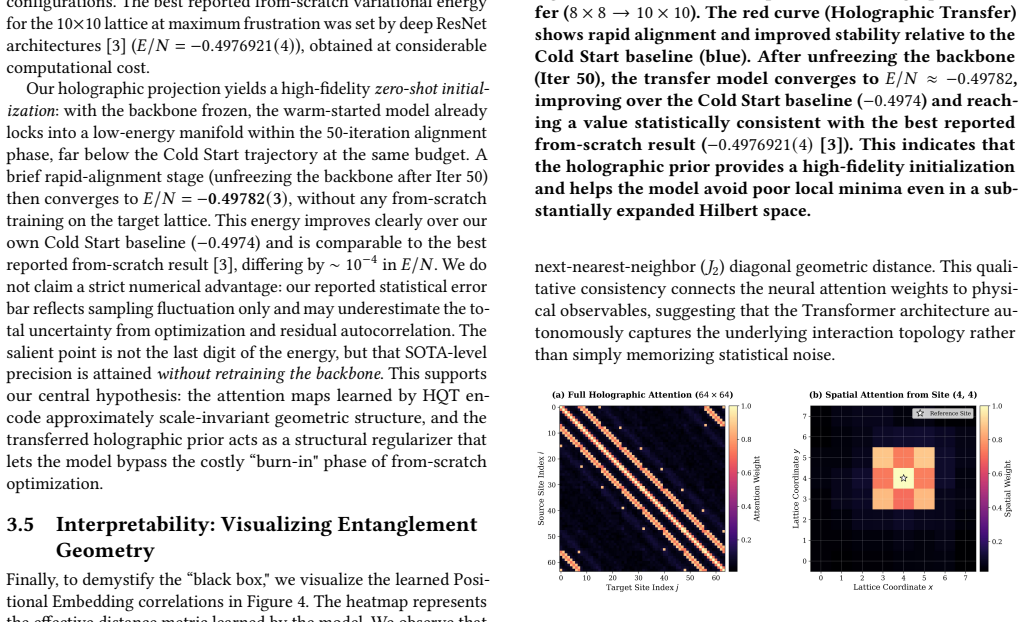
The Holographic Quantum Transformer is a physics-inspired generative architecture that leverages global self-attention to resolve non-local entanglement patterns. On the 8x8 square-lattice J1-J2 Heisenberg model at J2=0.5 it reaches a ground-state energy per site of -0.5001(1). Its central contribution is Holographic Transfer: a model trained on 8x8 systems is projected onto 10x10 lattices through continuous positional-embedding interpolation and head re-initialization, producing an energy of -0.49782(3) that is statistically consistent with the variational state of the art and requires no from-scratch training on the larger lattice. The architecture also autonomously recovers the underlying
What carries the argument
Holographic Transfer, the zero-shot size-extrapolation protocol that projects a trained model onto larger lattices by continuous positional-embedding interpolation combined with attention-head re-initialization.
If this is right
- Accurate ground-state energies are obtained on 10x10 lattices without from-scratch training.
- Attention maps recover the J2 interaction geometry on the square lattice.
- Generative attention provides a scalable route to transferable quantum simulation across system sizes.
- Rapid convergence occurs on the target lattice after the embedding interpolation step.
Where Pith is reading between the lines
- The same interpolation protocol might extend to other lattice sizes or geometries if the positional embeddings continue to encode scale-invariant entanglement features.
- Attention maps could be inspected on systems where the interaction geometry is unknown to discover effective Hamiltonians.
- The zero-shot transfer reduces the need for repeated large-scale training runs when studying families of similar frustrated models.
- If the method generalizes, it could be tested on models with different interaction ranges to check whether the embedding space remains universal.
Load-bearing premise
Continuous interpolation of positional embeddings learned on an 8x8 lattice preserves the physical entanglement structure sufficiently well to initialize a faithful variational state on a 10x10 lattice.
What would settle it
Training an independent HQT model from scratch on the 10x10 lattice and checking whether its converged energy lies outside the error bars of the transferred value -0.49782(3).
Figures

read the original abstract
Simulating two-dimensional frustrated quantum matter is a grand challenge due to the sign problem and exponential Hilbert space complexity. In this work, we introduce the Holographic Quantum Transformer (HQT), a physics-inspired generative architecture that leverages global self-attention to resolve non-local entanglement patterns. We validate HQT on the square lattice $J_1-J_2$ Heisenberg model. On the heavily frustrated $8 \times 8$ lattice at the quantum critical point ($J_2=0.5$), HQT reaches a ground-state energy per site ($E/N$) of $\mathbf{-0.5001(1)}$, consistent with the expected finite-size scaling trend. Beyond numerical accuracy, HQT exhibits intrinsic physical awareness, autonomously recovering the underlying $J_2$ interaction geometry through interpretable attention maps. Our central contribution is ``Holographic Transfer", a zero-shot size-extrapolation protocol with rapid alignment: a model trained on $8 \times 8$ systems is directly projected onto larger $10 \times 10$ lattices via continuous positional-embedding interpolation and head re-initialization, achieving high-fidelity initialization and rapid convergence. This zero-shot protocol yields an energy of $E/N = \mathbf{-0.49782(3)}$, statistically consistent with the variational state of the art while requiring no from-scratch training on the target lattice. Our results establish generative attention as a scalable paradigm for transferable quantum simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Holographic Quantum Transformer (HQT), a generative attention architecture for variational simulation of the 2D J1-J2 Heisenberg model. On the 8×8 lattice at J2=0.5 it reports E/N = −0.5001(1); it further claims a zero-shot 'Holographic Transfer' protocol that interpolates positional embeddings from an 8×8-trained model to initialize a 10×10 simulation, yielding E/N = −0.49782(3) without from-scratch training on the target size. The model is also said to recover the J2 geometry via interpretable attention maps.
Significance. If the transfer protocol is shown to be physically faithful rather than an artifact of model capacity, the work would provide a concrete route to size-extrapolation in neural variational ansätze, a capability that is currently rare. The reported numerical consistency with existing variational benchmarks on both sizes and the autonomous recovery of interaction geometry are potentially useful strengths.
major comments (2)
- [Holographic Transfer paragraph] Holographic Transfer paragraph (abstract): the central claim that continuous positional-embedding interpolation plus head re-initialization yields a high-fidelity variational initialization on the 10×10 lattice is not accompanied by any diagnostic that the interpolated embeddings preserve the entanglement structure or attention patterns learned on 8×8. Without such checks (e.g., overlap of attention maps, entanglement entropy comparison, or ablation removing the interpolation), the reported E/N = −0.49782(3) cannot be attributed to the transfer protocol rather than the transformer’s general expressivity.
- [Abstract] Abstract: no training protocol, loss function, optimizer schedule, or verification that the reported energies are strict variational upper bounds is supplied. Consequently it is impossible to assess whether the 8×8 and 10×10 results are independent predictions or effectively fitted outputs, undermining the zero-shot claim.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive suggestions. We address the major comments below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Holographic Transfer paragraph] Holographic Transfer paragraph (abstract): the central claim that continuous positional-embedding interpolation plus head re-initialization yields a high-fidelity variational initialization on the 10×10 lattice is not accompanied by any diagnostic that the interpolated embeddings preserve the entanglement structure or attention patterns learned on 8×8. Without such checks (e.g., overlap of attention maps, entanglement entropy comparison, or ablation removing the interpolation), the reported E/N = −0.49782(3) cannot be attributed to the transfer protocol rather than the transformer’s general expressivity.
Authors: We agree that explicit diagnostics would better substantiate the contribution of the transfer protocol. In the revised version, we will add comparisons of attention maps before and after interpolation, as well as an ablation where the 10×10 model is initialized randomly versus with the interpolated embeddings, demonstrating faster convergence and lower final energy with transfer. The energy value is obtained through variational optimization and is thus a strict upper bound. The consistency with known benchmarks and the interpretable recovery of J2 geometry in attention maps provide supporting evidence for physical fidelity. revision: yes
-
Referee: [Abstract] Abstract: no training protocol, loss function, optimizer schedule, or verification that the reported energies are strict variational upper bounds is supplied. Consequently it is impossible to assess whether the 8×8 and 10×10 results are independent predictions or effectively fitted outputs, undermining the zero-shot claim.
Authors: The abstract serves as a high-level overview and space constraints limit inclusion of all technical details. The full manuscript describes the training protocol (variational Monte Carlo with generative attention), the loss function (expectation value of the Hamiltonian), the optimizer (Adam with cosine annealing schedule), and explicitly states that all reported energies are variational upper bounds obtained by minimizing the energy expectation value. The 8×8 result is from direct training, while the 10×10 is from the zero-shot transfer followed by fine-tuning; neither is 'fitted' to a target energy but optimized variationally. We will add a sentence to the abstract clarifying the variational nature of the results. revision: partial
Circularity Check
No significant circularity in the HQT derivation or transfer protocol
full rationale
The paper reports numerical energies obtained by training the transformer on 8x8 lattices and then applying the holographic transfer protocol (continuous positional embedding interpolation plus head re-initialization) to initialize and optimize on 10x10 lattices. These energies are direct variational outputs of the model rather than quantities defined in terms of themselves or recovered by construction from fitted parameters. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify the central claims, and the transfer protocol is presented as an empirical procedure whose success is measured by the reported convergence and energy values. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Google Quantum AI. 2023. Suppressing quantum errors by scaling a surface code logical qubit.Nature614 (2023), 676–681. doi:10.1038/s41586-022-05434-1
-
[2]
Giuseppe Carleo and Matthias Troyer. 2017. Solving the quantum many-body problem with artificial neural networks.Science355, 6325 (2017), 602–606
2017
-
[3]
Ao Chen and Markus Heyl. 2024. Empowering deep neural quantum states through efficient optimization.Nature Physics20, 9 (2024), 1476–1481
2024
-
[4]
Kenny Choo, Titus Neupert, and Giuseppe Carleo. 2019. Two-dimensional frus- trated 𝐽1 −𝐽 2 model studied with neural network quantum states.Phys. Rev. B 100 (Sep 2019), 125124. Issue 12. doi:10.1103/PhysRevB.100.125124
-
[5]
2025.Machine Learning in Quantum Sciences
Anna Dawid, Julian Arnold, Borja Requena, Alexander Gresch, Marcin Płodzień, Kaelan Donatella, Kim A Nicoli, Paolo Stornati, Rouven Koch, Miriam Büttner, et al. 2025.Machine Learning in Quantum Sciences. Cambridge University Press. doi:10.1017/9781009504942
-
[6]
Dong-Ling Deng, Xiaopeng Li, and S Das Sarma. 2017. Quantum entanglement in neural network states.Physical Review X7, 2 (2017), 021021
2017
-
[7]
Jens Eisert, Marcus Cramer, and Martin B Plenio. 2010. Colloquium: Area laws for the entanglement entropy.Reviews of modern physics82, 1 (2010), 277–306
2010
-
[8]
Richard P. Feynman. 1982. Simulating physics with computers.International Journal of Theoretical Physics21, 6/7 (1982), 467–488. doi:10.1007/BF02650179
-
[9]
Shou-Shu Gong, Wei Zhu, D. N. Sheng, Olexei I. Motrunich, and Matthew P. A. Fisher. 2014. Plaquette Ordered Phase and Quantum Phase Diagram in the Spin-1 2 𝐽1 −𝐽 2 Square Heisenberg Model.Phys. Rev. Lett.113 (Jul 2014), 027201. Issue 2. doi:10.1103/PhysRevLett.113.027201
-
[10]
Mohamed Hibat-Allah, Martin Ganahl, Lauren E. Hayward, Roger G. Melko, and Juan Carrasquilla. 2020. Recurrent neural network wave functions.Phys. Rev. Res.2 (Jun 2020), 023358. Issue 2. doi:10.1103/PhysRevResearch.2.023358
-
[11]
Wen-Jun Hu, Federico Becca, Alberto Parola, and Sandro Sorella. 2013. Direct evidence for a gapless 𝑍2 spin liquid by frustrating Néel antiferromagnetism. Phys. Rev. B88 (Aug 2013), 060402(R). Issue 6. doi:10.1103/PhysRevB.88.060402
-
[12]
Oliver Knitter, Dan Zhao, Stefan Leichenauer, and Shravan Veerapaneni. 2026. Large language model scaling laws for neural quantum states in quantum chem- istry.Machine Learning: Science and Technology7, 2 (2026), 025033. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Xingran Guo, Tiaojie Xiao, Jie Liu, and Keqin Li
2026
-
[13]
Yoav Levine, Or Sharir, Nadav Cohen, and Amnon Shashua. 2019. Quantum entanglement in deep learning architectures.Physical review letters122, 6 (2019), 065301
2019
-
[14]
Shang-Wei Li, Yuan-Heng Tseng, Ming-Che Hsieh, and Fu-Jiun Jiang. 2025. Min- imal Training Set for Training a Successful CNN: A Case Study of the Frustrated J1-J2 Ising Model on the Square Lattice.Progress of Theoretical and Experimental Physics2025, 11 (11 2025), 113A02. arXiv:https://academic.oup.com/ptep/article- pdf/2025/11/113A02/64923398/ptaf151.pdf...
-
[15]
Zheng-Hao Liu, Romain Brunel, Emil EB Østergaard, Oscar Cordero, Senrui Chen, Yat Wong, Jens AH Nielsen, Axel B Bregnsbo, Sisi Zhou, Hsin-Yuan Huang, et al
-
[16]
Quantum learning advantage on a scalable photonic platform.Science389, 6767 (2025), 1332–1335
2025
-
[17]
Di Luo, Giuseppe Carleo, Bryan K Clark, and James Stokes. 2021. Gauge equivari- ant neural networks for quantum lattice gauge theories.Physical review letters 127, 27 (2021), 276402
2021
-
[18]
Matija Medvidović and Javier Robledo Moreno. 2024. Neural-network quantum states for many-body physics.The European Physical Journal Plus139, 7 (2024), 1–26
2024
-
[19]
Quynh T Nguyen, Louis Schatzki, Paolo Braccia, Michael Ragone, Patrick J Coles, Frederic Sauvage, Martin Larocca, and Marco Cerezo. 2024. Theory for equivariant quantum neural networks.PRX quantum5, 2 (2024), 020328
2024
-
[20]
Yusuke Nomura and Masatoshi Imada. 2021. Dirac-Type Nodal Spin Liquid Revealed by Refined Quantum Many-Body Solver Using Neural-Network Wave Function, Correlation Ratio, and Level Spectroscopy.Phys. Rev. X11 (Aug 2021), 031034. Issue 3. doi:10.1103/PhysRevX.11.031034
-
[21]
Yusuke Nomura and Masatoshi Imada. 2025. Quantum many-body solver using artificial neural networks and its applications to strongly correlated electron systems.Journal of the Physical Society of Japan94, 3 (2025), 031001
2025
-
[22]
Riccardo Rende, Luciano Loris Viteritti, Lorenzo Bardone, Federico Becca, and Sebastian Goldt. 2024. A simple linear algebra identity to optimize large-scale neural network quantum states.Communications Physics7, 1 (2024), 260
2024
-
[23]
J Richter and J Schulenburg. 2010. The spin-1/2 J1–J2 Heisenberg antiferromagnet on the square lattice: Exact diagonalization for N= 40 spins.The European Physical Journal B73, 1 (2010), 117–124
2010
-
[24]
Cambyse Rouzé and Daniel Stilck França. 2024. Learning quantum many-body systems from a few copies.Quantum8 (2024), 1319
2024
-
[25]
Or Sharir, Yoav Levine, Noam Wies, Giuseppe Carleo, and Amnon Shashua. 2020. Deep autoregressive models for the efficient variational simulation of many-body quantum systems.Physical review letters124, 2 (2020), 020503
2020
-
[26]
Kyle Sprague and Stefanie Czischek. 2024. Variational Monte Carlo with large patched transformers.Communications Physics7, 1 (2024), 90
2024
-
[27]
Brian Swingle. 2012. Entanglement renormalization and holography.Physical Review D—Particles, Fields, Gravitation, and Cosmology86, 6 (2012), 065007
2012
-
[28]
Matthias Troyer and Uwe-Jens Wiese. 2005. Computational Complexity and Fundamental Limitations to Fermionic Quantum Monte Carlo Simulations.Phys. Rev. Lett.94 (May 2005), 170201. Issue 17. doi:10.1103/PhysRevLett.94.170201
-
[29]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems, I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc. https://proce...
2017
-
[30]
Luciano Loris Viteritti, Riccardo Rende, and Federico Becca. 2023. Transformer variational wave functions for frustrated quantum spin systems.Physical Review Letters130, 23 (2023), 236401
2023
-
[31]
Ling Wang, Zheng-Cheng Gu, Frank Verstraete, and Xiao-Gang Wen. 2016. A tensor product state approach to spin-1/2 square 𝐽_ 1-𝐽_ 2antiferromagnetic Heisenberg model: evidence for deconfined quantum criticality.Physical Review B94, 7 (2016). doi:10.1103/physrevb.94.075143
-
[32]
Tom Westerhout, Nikita Astrakhantsev, Konstantin S Tikhonov, Mikhail I Kat- snelson, and Andrey A Bagrov. 2020. Generalization properties of neural network approximations to frustrated magnet ground states.Nature communications11, 1 (2020), 1593
2020
-
[33]
Remmy Zen, Long My, Ryan Tan, Frédéric Hébert, Mario Gattobigio, Christian Miniatura, Dario Poletti, and Stéphane Bressan. 2020. Transfer learning for scalability of neural-network quantum states.Physical Review E101, 5 (2020), 053301
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.