LLVM-Bench: Benchmarking and Advancing Large Language Models for LLVM Compiler Issue Resolution
Pith reviewed 2026-07-02 08:39 UTC · model grok-4.3
The pith
LLVM-Ens resolves up to 21.99% of real LLVM compiler issues by ensembling patches from multiple LLMs and agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
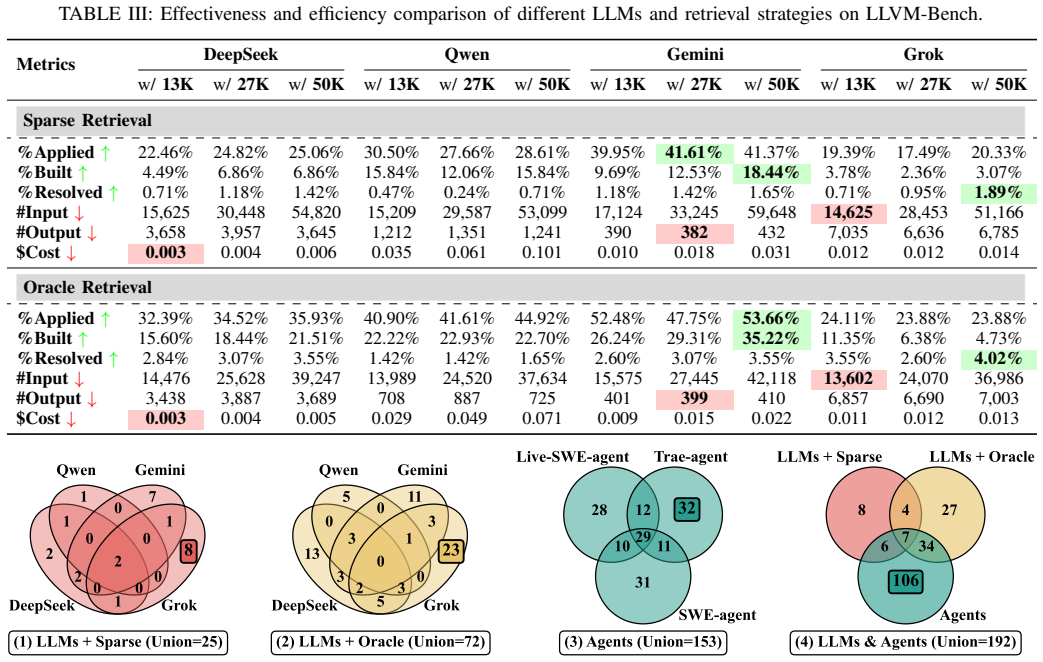
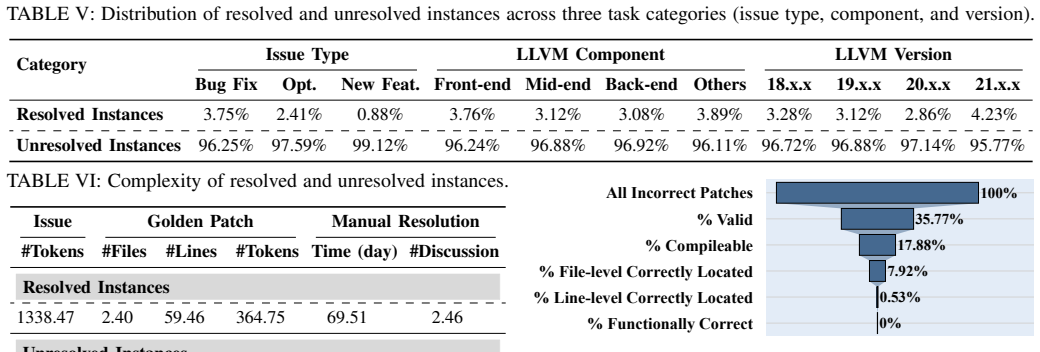
While current LLM-based issue resolution techniques remain limited on LLVM-Bench, with patch invalidity and build failures as the dominant failure modes, a lightweight ensemble called LLVM-Ens expands the patch space through integrating patches generated by diverse techniques, filters incorrect and redundant candidates, and identifies the most promising solution, achieving a resolution rate of up to 21.99%.
What carries the argument
LLVM-Ens, which integrates patches from diverse LLMs and agents then filters incorrect and redundant candidates to select the best solution.
If this is right
- Individual LLMs and agents achieve limited resolution rates on complex system-level compiler issues.
- Patch invalidity and build failures dominate the failure modes for current techniques.
- Different LLMs and agents exhibit strong complementarity in the patches they generate.
- Integrating outputs and filtering candidates raises the resolution rate to 21.99%.
Where Pith is reading between the lines
- Ensemble filtering of LLM-generated patches could be tested on issue resolution for other large open-source codebases.
- LLVM-Gym's automation pipeline may support standardized tracking of progress across future LLM techniques for compilers.
- The observed complementarity suggests that diversity in model training data or agent designs is a key driver worth isolating in follow-up experiments.
Load-bearing premise
The 423 collected tasks and the automated reproduction steps in LLVM-Gym accurately represent the difficulty and failure modes of real LLVM issue resolution.
What would settle it
Evaluating LLVM-Ens and the individual methods on a fresh collection of LLVM issues outside the 423-task benchmark and finding that the ensemble no longer outperforms the best single method.
Figures

read the original abstract
LLVM is a widely used compiler infrastructure whose scale and complexity make issue resolution labor-intensive and challenging. Although large language models (LLMs) have recently achieved remarkable success in issue resolution, their effectiveness on complex system-level LLVM compiler remains largely unexplored. To address this gap, we introduce LLVM-Bench, the first large-scale benchmark for LLVM issue resolution, containing 423 real-world, validated tasks collected from the LLVM project. We further develop LLVM-Gym, a scalable evaluation platform that automates issue reproduction, patch application, compiler building, and test execution. Using LLVM-Bench and LLVM-Gym, we conduct a comprehensive study of four representative LLMs, six retrieval configurations, and three agents. Our results show that current LLM-based issue resolution techniques remain limited on LLVM-Bench, with patch invalidity and build failures as the dominant failure modes. We further reveal a strong complementarity among different LLMs and agents, motivating LLVM-Ens, a lightweight ensemble approach that expands the patch space through integrating the patches generated by diverse techniques, filters incorrect and redundant candidates, and identifies the most promising solution. Our results show that LLVM-Ens achieves a resolution rate of up to 21.99%, further improving LLVM issue resolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LLVM-Bench, a benchmark of 423 real-world, validated LLVM compiler issues collected from the project, together with LLVM-Gym, an automated platform for issue reproduction, patch application, building, and testing. It evaluates four LLMs across six retrieval settings and three agents, documents dominant failure modes (patch invalidity and build failures), and proposes LLVM-Ens, a lightweight ensemble that integrates patches from diverse sources, filters candidates, and reaches a resolution rate of up to 21.99%.
Significance. If the benchmark tasks and harness are representative, the work supplies the first large-scale empirical study of LLM-based issue resolution on a complex systems artifact such as LLVM. The observed complementarity among models and agents, together with the concrete failure-mode breakdown, supplies actionable guidance for future systems-oriented LLM research. LLVM-Gym itself constitutes a reusable evaluation harness that supports reproducibility.
major comments (2)
- [§3] §3 (Task Collection and Validation): the manuscript states that the 423 tasks are 'real-world, validated' yet provides no quantitative validation metrics (coverage across LLVM subcomponents, inter-rater agreement, or exclusion criteria). Because the headline 21.99% resolution rate and the complementarity claims rest directly on these tasks accurately reflecting real issue difficulty and failure modes, the absence of such metrics is load-bearing.
- [§5.3] §5.3 (LLVM-Ens description): the filtering step that removes 'incorrect and redundant candidates' is described at a high level but lacks the precise decision rules, similarity thresholds, or verification procedure used. Without these details it is impossible to determine whether the reported gains arise from genuine complementarity or from post-hoc selection effects.
minor comments (2)
- [Table 1] Table 1 and the abstract both report 'up to 21.99%'; the main text should state explicitly which configuration and random seed produce this figure and whether it is the single best run or an average.
- [§4] The paper would benefit from a short paragraph in §4 or §6 discussing the extent to which LLVM-Gym's automated reproduction scripts were manually inspected for fidelity to the original bug reports.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address each of the major comments below, indicating the revisions we plan to make to improve the paper.
read point-by-point responses
-
Referee: [§3] §3 (Task Collection and Validation): the manuscript states that the 423 tasks are 'real-world, validated' yet provides no quantitative validation metrics (coverage across LLVM subcomponents, inter-rater agreement, or exclusion criteria). Because the headline 21.99% resolution rate and the complementarity claims rest directly on these tasks accurately reflecting real issue difficulty and failure modes, the absence of such metrics is load-bearing.
Authors: We acknowledge that the manuscript would benefit from more explicit quantitative validation metrics. The tasks were collected by querying the LLVM issue tracker for issues with attached reproduction steps and patches. Validation involved manually reproducing each issue using the provided steps within our LLVM-Gym framework, retaining only those that could be successfully reproduced and built. Exclusion criteria included issues lacking sufficient reproduction information, those already resolved, or duplicates. To address the concern, we will revise §3 to include: (1) coverage statistics across LLVM subcomponents (e.g., percentages for Clang, LLVM core, etc.), (2) details on the validation protocol, and (3) a note on the single-team validation process (inter-rater agreement not computed). We will also clarify how these tasks represent real-world difficulty. This will be incorporated in the revised version. revision: yes
-
Referee: [§5.3] §5.3 (LLVM-Ens description): the filtering step that removes 'incorrect and redundant candidates' is described at a high level but lacks the precise decision rules, similarity thresholds, or verification procedure used. Without these details it is impossible to determine whether the reported gains arise from genuine complementarity or from post-hoc selection effects.
Authors: We agree that additional details on the filtering procedure are necessary to substantiate the claims. In the revised manuscript, we will expand the description in §5.3 with precise rules: A candidate patch is removed if (a) it fails to apply to the source code (git apply fails), (b) it leads to build errors during compilation, or (c) it is redundant with another candidate based on a similarity threshold of 0.8 using token-based Jaccard similarity on the unified diff. Verification consists of executing the relevant test cases post-build. We will also report the number of patches before and after filtering to show the effect. This will help demonstrate that the 21.99% resolution rate results from complementarity among the diverse sources rather than selection bias. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or fitted reductions
full rationale
The paper presents an empirical benchmark (LLVM-Bench with 423 tasks) and evaluation harness (LLVM-Gym) followed by direct measurement of LLM resolution rates and an ensemble method (LLVM-Ens). No equations, parameter fits, uniqueness theorems, or self-citations are used to derive the headline 21.99% figure; it is obtained by running the described agents on the collected tasks and counting successful patches. The central claim therefore does not reduce to its inputs by construction and remains externally falsifiable via replication on the released benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llvm: A compilation framework for lifelong program analysis & transformation,
C. Lattner and V . Adve, “Llvm: A compilation framework for lifelong program analysis & transformation,”International symposium on code generation and optimization, 2004. CGO 2004., pp. 75–86, 2004
2004
-
[2]
A survey of compiler testing,
J. Chen, J. Patra, M. Pradel, Y . Xiong, H. Zhang, D. Hao, and L. Zhang, “A survey of compiler testing,”Acm Computing Surveys (Csur), vol. 53, no. 1, pp. 1–36, 2020
2020
-
[3]
An empirical study of optimization bugs in gcc and llvm,
Z. Zhou, Z. Ren, G. Gao, and H. Jiang, “An empirical study of optimization bugs in gcc and llvm,”Journal of Systems and Software, vol. 174, p. 110884, 2021
2021
-
[4]
Toward understanding compiler bugs in gcc and llvm,
C. Sun, V . Le, Q. Zhang, and Z. Su, “Toward understanding compiler bugs in gcc and llvm,”Proceedings of the 25th international symposium on software testing and analysis, pp. 294–305, 2016
2016
-
[5]
Clang: a c language family frontend for llvm,
Clang, “Clang: a c language family frontend for llvm,” https://clang. llvm.org/, 2026
2026
-
[6]
The flang compiler,
Flang, “The flang compiler,” https://flang.llvm.org/docs/, 2026
2026
-
[7]
Multi-level ir compiler framework,
MLIR, “Multi-level ir compiler framework,” https://mlir.llvm.org/, 2026
2026
-
[8]
Numba: A llvm-based python jit compiler,
S. K. Lam, A. Pitrou, and S. Seibert, “Numba: A llvm-based python jit compiler,”Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, pp. 1–6, 2015
2015
-
[9]
Obfuscator-llvm– software protection for the masses,
P. Junod, J. Rinaldini, J. Wehrli, and J. Michielin, “Obfuscator-llvm– software protection for the masses,”2015 ieee/acm 1st international workshop on software protection, pp. 3–9, 2015
2015
-
[10]
Rust compiler development guide,
Rustc, “Rust compiler development guide,” https://rustc-dev-guide. rust-lang.org/backend/codegen.html, 2026
2026
-
[11]
The retdec decompiler,
RetDec, “The retdec decompiler,” https://github.com/avast/retdec, 2026
2026
-
[12]
KLEE: unassisted and automatic generation of high-coverage tests for complex systems programs,
C. Cadar, D. Dunbar, and D. R. Engler, “KLEE: unassisted and automatic generation of high-coverage tests for complex systems programs,” in8th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2008, December 8-10, 2008, San Diego, California, USA, Proceedings, R. Draves and R. van Renesse, Eds. USENIX Association, 2008, pp. 209–224. [On...
2008
-
[13]
Phasar: An inter- procedural static analysis framework for C/C++,
P. D. Schubert, B. Hermann, and E. Bodden, “Phasar: An inter- procedural static analysis framework for C/C++,” inTools and Algorithms for the Construction and Analysis of Systems - 25th International Conference, TACAS 2019, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2019, Prague, Czech Republic, April 6-11, 20...
-
[14]
Issues of llvm project,
LLVM, “Issues of llvm project,” https://github.com/llvm/llvm-project/ issues, 2026
2026
-
[15]
Swe-bench: Can language models resolve real- world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “Swe-bench: Can language models resolve real- world github issues?”The Twelfth International Conference on Learning Representations, 2023
2023
-
[16]
Swe-debate: Competitive multi-agent debate for software issue resolution,
H. Li, Y . Shi, S. Lin, X. Gu, H. Lian, X. Wang, Y . Jia, T. Huang, and Q. Wang, “Swe-debate: Competitive multi-agent debate for software issue resolution,”2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE), 2026
2026
-
[17]
Are” solved issues
Y . Wang, M. Pradel, and Z. Liu, “Are” solved issues” in swe-bench really solved correctly? an empirical study,”2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE), 2026
2026
-
[18]
Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,”Advances in Neural Information Processing Systems, vol. 37, pp. 50 528–50 652, 2024
2024
-
[19]
Demystifying llm-based software engineering agents,
C. S. Xia, Y . Deng, S. Dunn, and L. Zhang, “Demystifying llm-based software engineering agents,”Proc. ACM Softw. Eng., vol. 2, no. FSE, 2025
2025
-
[20]
Large language models for software engi- neering: A systematic literature review,
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large language models for software engi- neering: A systematic literature review,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 8, pp. 1–79, 2024
2024
-
[21]
Specrover: Code intent extraction via llms,
H. Ruan, Y . Zhang, and A. Roychoudhury, “Specrover: Code intent extraction via llms,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 963–974
2025
-
[22]
Swe-gpt: A process-centric language model for automated software improvement,
Y . Ma, R. Cao, Y . Cao, Y . Zhang, J. Chen, Y . Liu, Y . Liu, B. Li, F. Huang, and Y . Li, “Swe-gpt: A process-centric language model for automated software improvement,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 2362–2383, 2025
2025
-
[23]
Leaderboard of swe-bench-verified,
V . AI, “Leaderboard of swe-bench-verified,” https://www.vals.ai/ benchmarks/swebench, 2026
2026
-
[24]
Django: The web framework for perfectionists with deadlines
D. S. Foundation, “Django: The web framework for perfectionists with deadlines.” https://www.djangoproject.com/, 2026
2026
-
[25]
Pytest: helps you write better programs,
P. dev Team, “Pytest: helps you write better programs,” https://docs. pytest.org/en/stable/, 2026
2026
-
[26]
How to submit an llvm bug report,
LLVM, “How to submit an llvm bug report,” https://llvm.org/docs/ HowToSubmitABug.html, 2026
2026
-
[27]
Introducing swe-bench verified,
OpenAI, “Introducing swe-bench verified,” https://openai.com/index/ introducing-swe-bench-verified/, 2026
2026
-
[28]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
xAI, “Grok,” https://x.ai/grok, 2026
2026
-
[30]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Trae agent: An llm-based agent for software engineering with test-time scaling,
P. Gao, Z. Tian, X. Meng, X. Wang, R. Hu, Y . Xiao, Y . Liu, Z. Zhang, J. Chen, C. Gaoet al., “Trae agent: An llm-based agent for software engineering with test-time scaling,”arXiv preprint arXiv:2507.23370, 2025
-
[33]
Live-SWE-agent: Can software engineering agents self-evolve on the fly?
C. S. Xia, Z. Wang, Y . Yang, Y . Wei, and L. Zhang, “Live-swe-agent: Can software engineering agents self-evolve on the fly?”arXiv preprint arXiv:2511.13646, 2025
-
[34]
Ninja, a small build system with a focus on speed,
Ninja, “Ninja, a small build system with a focus on speed,” https:// ninja-build.org/, 2026
2026
-
[35]
Evaluating and improving automated repository-level rust issue resolution with llm-based agents,
J. Xiang, W. He, X. Wang, H. Tian, and Y . Zhang, “Evaluating and improving automated repository-level rust issue resolution with llm-based agents,”2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE), 2026
2026
-
[36]
Openhands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “Openhands: An open platform for AI software developers as generalist agents,”The Thirteenth International Conference on Learn...
2025
-
[37]
Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval,
S. E. Robertson and S. Walker, “Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval,” inSIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Con- ference on Research and Development in Information Retrieval, organ- ised by Dublin City University. Springer, 1994, pp. 232–241. 11
1994
-
[38]
Kgym: A platform and dataset to benchmark large language models on linux kernel crash resolution,
A. Mathai, C. Huang, P. Maniatis, A. Nogikh, F. Ivan ˇci´c, J. Yang, and B. Ray, “Kgym: A platform and dataset to benchmark large language models on linux kernel crash resolution,”Advances in Neural Information Processing Systems, vol. 37, pp. 78 053–78 078, 2024
2024
-
[39]
Fea-bench: A benchmark for evaluating repository-level code generation for feature implementation,
W. Li, X. Zhang, Z. Guo, S. Mao, W. Luo, G. Peng, Y . Huang, H. Wang, and S. Li, “Fea-bench: A benchmark for evaluating repository-level code generation for feature implementation,”Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 17 160–17 176, 2025
2025
-
[40]
Multi-swe-bench: A multilingual benchmark for issue resolving,
D. Zan, Z. Huang, W. Liu, H. Chen, S. Xin, L. Zhang, Q. Liu, L. Aoyan, L. Chen, X. Zhonget al., “Multi-swe-bench: A multilingual benchmark for issue resolving,”Advances in Neural Information Processing Sys- tems, vol. 38, 2026
2026
-
[41]
Agent-based ensemble reasoning for repository-level issue resolution,
Z. Tian, P. Gao, J. Chen, and C. Peng, “Agent-based ensemble reasoning for repository-level issue resolution,”2026 IEEE/ACM 48th Interna- tional Conference on Software Engineering (ICSE), 2026
2026
-
[42]
Unified diff python parsing/metadata extraction library,
M. Bordese, “Unified diff python parsing/metadata extraction library,” https://github.com/matiasb/python-unidiff, 2026
2026
-
[43]
Clangformat,
T. C. Team, “Clangformat,” https://clang.llvm.org/docs/ClangFormat. html, 2026
2026
-
[44]
Clang-tidy,
T. C.-T. Team, “Clang-tidy,” https://clang.llvm.org/extra/clang-tidy/, 2026
2026
-
[45]
Claude code: Ai-powered coding assistant for develop- ers,
T. C. C. Team, “Claude code: Ai-powered coding assistant for develop- ers,” https://www.anthropic.com/claude-code, 2026
2026
-
[46]
Introducing claude opus 4.8,
Anthropic, “Introducing claude opus 4.8,” https://www.anthropic.com/ news/claude-opus-4-8, 2026
2026
-
[47]
B. J. Gough and R. Stallman,An Introduction to GCC.Network Theory Limited Bristol, UK, 2004
2004
-
[48]
Douglas and S
K. Douglas and S. Douglas,PostgreSQL: a comprehensive guide to building, programming, and administering PostgresSQL databases. SAMS publishing, 2003
2003
-
[49]
Burns, J
B. Burns, J. Beda, K. Hightower, and L. Evenson,Kubernetes: up and running: dive into the future of infrastructure. ” O’Reilly Media, Inc.”, 2022
2022
-
[50]
M. S. Rashid, C. Bock, Y . Zhuang, A. Buchholz, T. Esler, S. Valentin, L. Franceschi, M. Wistuba, P. T. Sivaprasad, W. J. Kimet al., “Swe- polybench: A multi-language benchmark for repository level evaluation of coding agents,”arXiv preprint arXiv:2504.08703, 2025
-
[51]
Swe-smith: Scaling data for software engineering agents,
J. Yang, K. Lieret, C. Jimenez, A. Wettig, K. Khandpur, Y . Zhang, B. Hui, O. Press, L. Schmidt, and D. Yang, “Swe-smith: Scaling data for software engineering agents,”Advances in Neural Information Processing Systems, vol. 38, 2026
2026
-
[52]
Swe-bench goes live!
L. Zhang, S. He, C. Zhang, Y . Kang, B. Li, C. Xie, J. Wang, M. Wang, Y . Huang, S. Fuet al., “Swe-bench goes live!”Advances in Neural Information Processing Systems, vol. 38, 2026
2026
-
[53]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
X. Deng, J. Da, E. Pan, Y . Y . He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Raneet al., “Swe-bench pro: Can ai agents solve long- horizon software engineering tasks?”arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Outrunning LLM Cutoffs: A Live Kernel Crash Resolution Benchmark for All
C. Huang, A. Mathai, F. Yu, A. Nogikh, P. Maniatis, F. Ivan ˇci´c, E. Wu, K. Kaffes, J. Yang, and B. Ray, “Outrunning llm cutoffs: A live kernel crash resolution benchmark for all,”arXiv preprint arXiv:2602.02690, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Google, “Syzbot,” https://syzkaller.appspot.com/upstream, 2026. 12
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.