FAR: Failure-Aware Retry for Test-Time Recovery and Continual Policy Improvement
Pith reviewed 2026-07-02 11:03 UTC · model grok-4.3
The pith
Robots recover from their own failures at test time by turning unsuccessful trajectories into preference data that steers the policy away from mistakes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
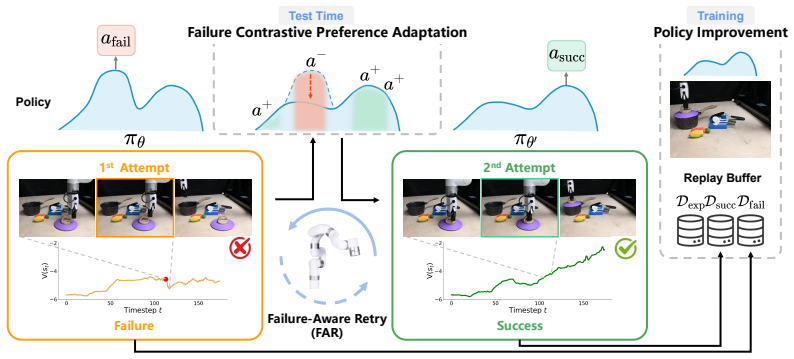
FAR enables test-time recovery and continual improvement by pairing Failure-Contrastive Preference Adaptation—which builds preference learning data directly from failure trajectories to steer the policy away from unsuccessful behaviors—with lightweight action perturbations during retries to encourage local exploration, then incorporating the resulting successful trajectories into a training loop.
What carries the argument
Failure-Contrastive Preference Adaptation that converts failure trajectories into preference pairs for steering the diffusion policy.
If this is right
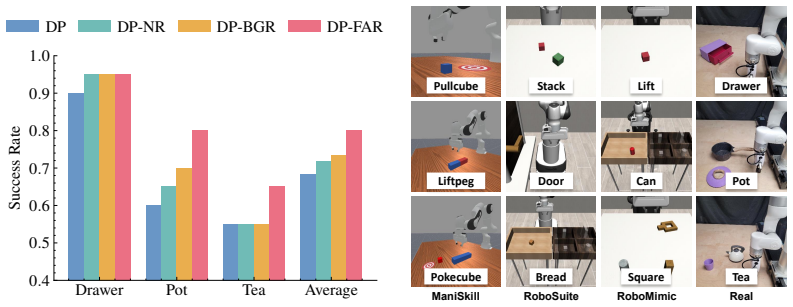
- Success rates rise by an average of 17.6 percent over a standard diffusion policy in simulation and 11.7 percent in real-world manipulation.
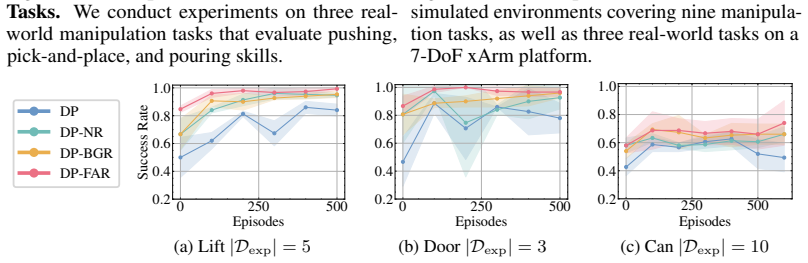
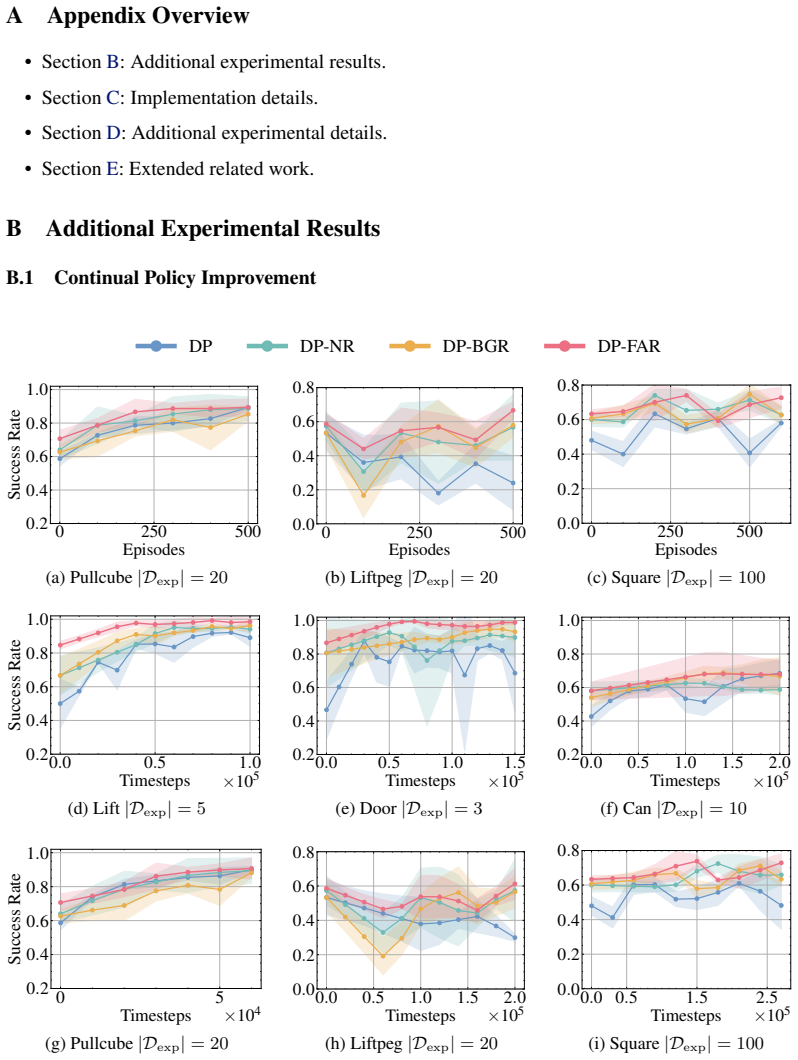
- Data efficiency improves under both reset budgets and timestep budgets during continual policy improvement.
- Robots complete tasks autonomously by learning from failures instead of repeating them or requiring human intervention.
- Robustness increases because the policy actively avoids previously observed failure modes on subsequent attempts.
Where Pith is reading between the lines
- The same failure-to-preference conversion could be tested on policy architectures other than diffusion models to check whether the gain is architecture-specific.
- Over many deployments the accumulated recovery data might reduce the size of the initial offline dataset needed to reach a given performance level.
- The method could be combined with existing safety filters to bound the risk introduced by the exploration perturbations.
Load-bearing premise
Failure trajectories supply unbiased preference signals that improve the policy without introducing new biases or needing extra task-specific tuning.
What would settle it
An experiment on the same tasks where the preference adaptation step produces no gain or a drop in success rate relative to plain retries would falsify the central claim.
Figures
read the original abstract
Robot policies inevitably encounter failures when deployed in real environments. Naive retries often repeat the same mistakes, while many existing recovery methods rely on human intervention. In this paper, we propose Failure-Aware Retry (FAR), a framework that enables robots to learn from previous failures at test time, adapt their behavior accordingly, and eventually complete the task autonomously. FAR combines Failure-Contrastive Preference Adaptation, which constructs preference learning data from failures to steer the policy away from previously unsuccessful behaviors, with lightweight action perturbations during retries to encourage local exploration. We further incorporate successful recovery trajectories into a training loop for continual policy improvement. Experiments in both simulation and real-world manipulation tasks show that FAR substantially improves success rates and robustness, with average gains of 17.6% over the standard diffusion policy in simulation and 11.7% in the real world. In addition, FAR significantly improves data efficiency under both reset and timestep budgets during continual policy improvement by exploiting informative failure cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Failure-Aware Retry (FAR), a test-time framework that converts observed failures into preference pairs via Failure-Contrastive Preference Adaptation, applies lightweight action perturbations on retries, and folds successful recoveries into a continual training loop. It claims this yields average success-rate gains of 17.6 % over a standard diffusion policy in simulation and 11.7 % in real-world manipulation, together with improved data efficiency under reset and timestep budgets.
Significance. If the empirical claims are substantiated, the approach would provide a practical, human-free mechanism for test-time recovery and online policy improvement in robotics. The explicit use of failure trajectories as preference data and the closed-loop incorporation of recoveries into training constitute a concrete, falsifiable contribution to continual adaptation.
major comments (2)
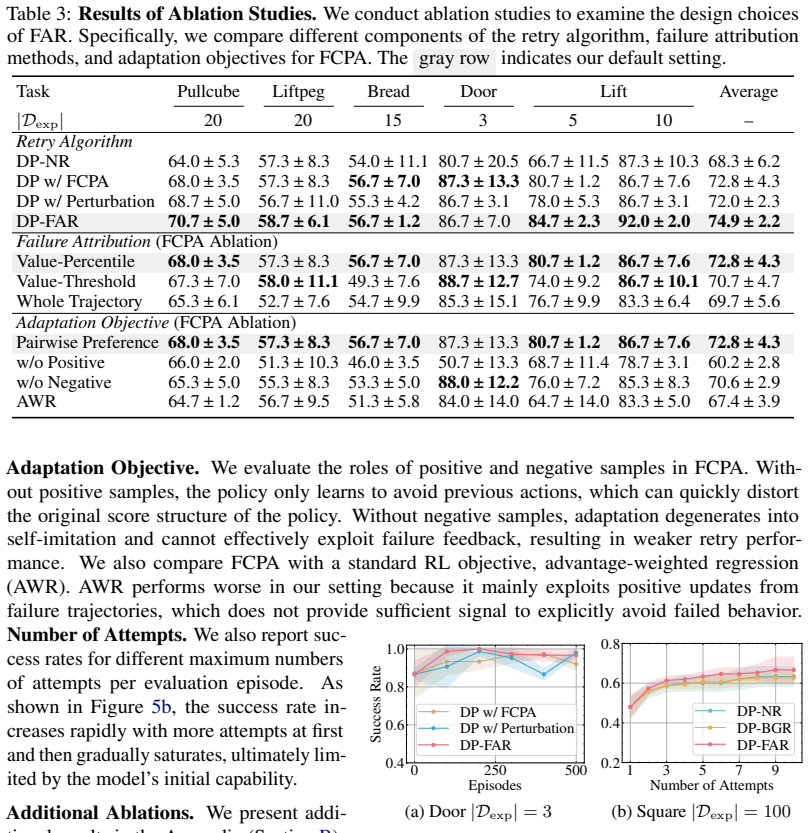
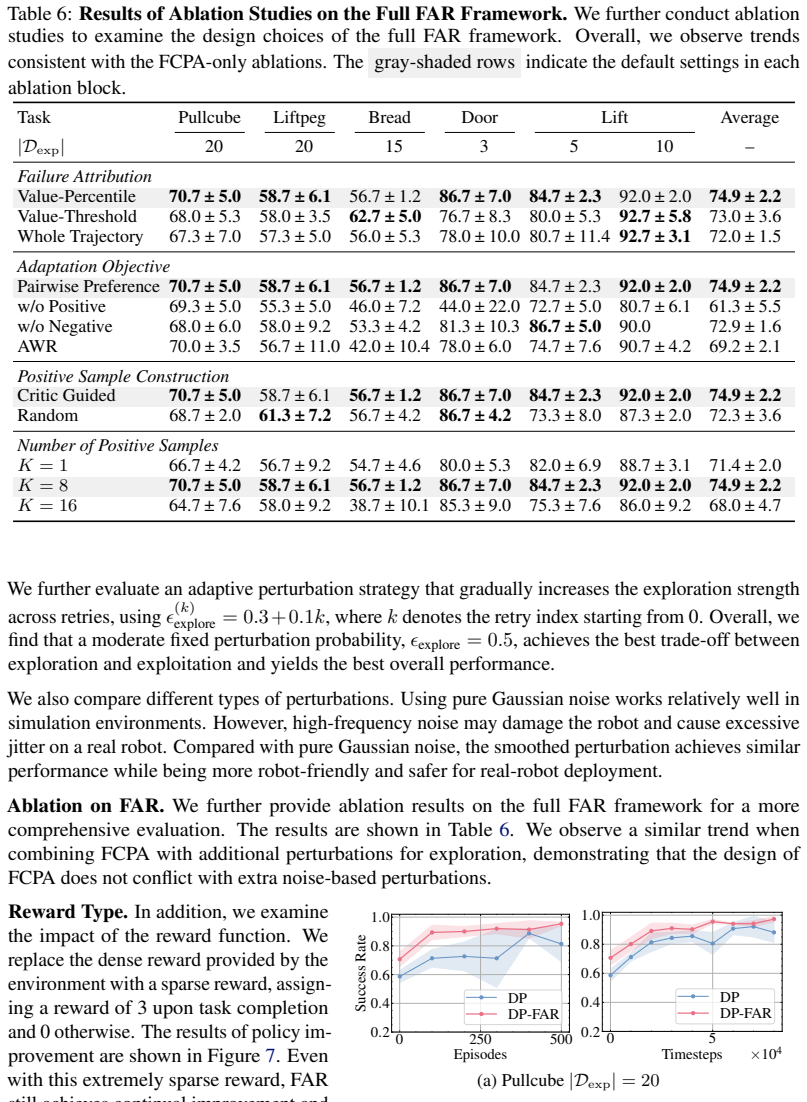
- [Abstract and §4] Abstract and §4 (Experiments): the headline performance numbers (17.6 % sim, 11.7 % real) and the data-efficiency claim are stated without any description of trial counts, random seeds, statistical tests, baseline implementations, or ablation results for the preference-adaptation component. Because these quantities are the sole support for the central claims, the manuscript cannot be evaluated as written.
- [§3] §3 (Failure-Contrastive Preference Adaptation): the construction that turns failure trajectories into preference pairs is described only at the level of “lightweight perturbations” and “steering away from unsuccessful behaviors.” No derivation, bias analysis, or controlled experiment shows that the induced preference distribution remains unbiased relative to the original task reward or that the contrastive objective does not amplify spurious correlations present only in the failure set. This step is load-bearing for both the robustness and continual-improvement claims.
minor comments (2)
- [§3] Notation for the preference loss and the perturbation schedule should be introduced with explicit equations rather than prose descriptions.
- [§4] Figure captions should state the exact number of evaluation episodes and whether error bars represent standard error or standard deviation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the current manuscript requires substantial additions to experimental reporting and methodological detail. Below we respond point-by-point and commit to the necessary revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the headline performance numbers (17.6 % sim, 11.7 % real) and the data-efficiency claim are stated without any description of trial counts, random seeds, statistical tests, baseline implementations, or ablation results for the preference-adaptation component. Because these quantities are the sole support for the central claims, the manuscript cannot be evaluated as written.
Authors: We agree that the reported success rates and data-efficiency claims lack the necessary statistical and implementation details. In the revised manuscript we will add: the exact number of trials per condition, the random seeds employed, results of statistical significance tests (including p-values), full descriptions of baseline implementations, and dedicated ablations isolating the preference-adaptation component. These changes will allow proper evaluation of the 17.6 % and 11.7 % gains. revision: yes
-
Referee: [§3] §3 (Failure-Contrastive Preference Adaptation): the construction that turns failure trajectories into preference pairs is described only at the level of “lightweight perturbations” and “steering away from unsuccessful behaviors.” No derivation, bias analysis, or controlled experiment shows that the induced preference distribution remains unbiased relative to the original task reward or that the contrastive objective does not amplify spurious correlations present only in the failure set. This step is load-bearing for both the robustness and continual-improvement claims.
Authors: We acknowledge that §3 currently provides only a high-level description. We will expand the section with a formal derivation of the preference-pair construction from failure trajectories, an explicit bias analysis relative to the task reward, and controlled experiments that test whether the contrastive objective introduces or amplifies spurious correlations unique to the failure set. These additions will directly address the load-bearing nature of this component. revision: yes
Circularity Check
No significant circularity; empirical claims rest on experimental validation
full rationale
The paper proposes FAR as a new framework that constructs preference data from observed failures and incorporates successful recoveries into a training loop. All reported gains (17.6% sim, 11.7% real) and data-efficiency improvements are presented as outcomes of simulation and real-world experiments. No equations, derivations, or first-principles results are described that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The method is self-contained against external benchmarks and does not rename known results or smuggle ansatzes via prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[2]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[4]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.016
-
[5]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glossop, T. Godden, I. Goryachev, L. Groom, H. Hancock, K. Hausman, G. Hussein, B. Ichter, S. Jakubczak, R. Jen, T. Jones, B. Katz, L. Ke, C. Kuchi, M. Lamb, D. LeBlanc, S. Levin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
J. Luo, C. Xu, J. Wu, and S. Levine. Precise and dexterous robotic manipulation via human-in- the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
2025
-
[8]
Mandlekar, C
A. Mandlekar, C. R. Garrett, D. Xu, and D. Fox. Human-in-the-loop task and motion planning for imitation learning. In7th Annual Conference on Robot Learning, 2023. URL https: //openreview.net/forum?id=G_FEL3OkiR
2023
-
[9]
Hoque, L
R. Hoque, L. Y . Chen, S. Sharma, K. Dharmarajan, B. Thananjeyan, P. Abbeel, and K. Goldberg. Fleet-dagger: Interactive robot fleet learning with scalable human supervision. InConference on Robot Learning, pages 368–380. PMLR, 2023
2023
-
[10]
Hoque, A
R. Hoque, A. Balakrishna, C. Putterman, M. Luo, D. S. Brown, D. Seita, B. Thananjeyan, E. Novoseller, and K. Goldberg. Lazydagger: Reducing context switching in interactive imitation learning. In2021 IEEE 17th international conference on automation science and engineering (case), pages 502–509. IEEE, 2021
2021
-
[11]
Hoque, A
R. Hoque, A. Balakrishna, E. Novoseller, A. Wilcox, D. S. Brown, and K. Goldberg. ThriftyDAg- ger: Budget-aware novelty and risk gating for interactive imitation learning. In5th An- nual Conference on Robot Learning, 2021. URL https://openreview.net/forum?id= KKBfrCzCVOn. 9
2021
-
[12]
Ebert, S
F. Ebert, S. Dasari, A. X. Lee, S. Levine, and C. Finn. Robustness via retrying: Closed-loop robotic manipulation with self-supervised learning. InConference on robot learning, pages 983–993. PMLR, 2018
2018
- [13]
-
[14]
S. Xu, R. Jin, H. Zhou, B. Yue, G. Qiao, Y . Deng, Y . Tai, K. Jia, and G. Liu. From reaction to anticipation: Proactive failure recovery through agentic task graph for robotic manipulation. In Robotics: Science and Systems (RSS), 2026
2026
-
[15]
Z. Liu, A. Bahety, and S. Song. REFLECT: Summarizing robot experiences for failure explanation and correction. In7th Annual Conference on Robot Learning, 2023. URL https: //openreview.net/forum?id=8yTS_nAILxt
2023
-
[16]
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti. SAFE: Multitask failure detection for vision-language-action models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id= XPyAukgsFf
2026
-
[17]
J. Duan, W. Pumacay, N. Kumar, Y . R. Wang, S. Tian, W. Yuan, R. Krishna, D. Fox, A. Man- dlekar, and Y . Guo. AHA: A vision-language-model for detecting and reasoning over failures in robotic manipulation. InThe Thirteenth International Conference on Learning Representations,
-
[18]
URLhttps://openreview.net/forum?id=JVkdSi7Ekg
-
[19]
C. Grislain, H. Rahimi, O. Sigaud, and M. Chetouani. I-failsense: Towards general robotic failure detection with vision-language models. InProceedings of the International Conference on Robotics and Automation (ICRA), 2026. URLhttps://arxiv.org/abs/2509.16072
- [20]
-
[21]
Z. Lin, J. Duan, H. Fang, D. Fox, R. Krishna, C. Tan, and B. Wen. Failsafe: Reasoning and recovery from failures in vision-language-action models, 2025. URL https://arxiv.org/ abs/2510.01642
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
H. Chen, Y . Yao, R. Liu, C. Liu, and J. Ichnowski. Robot failure recovery using vision- language models with optimized prompts. In2025 American Control Conference (ACC), pages 1983–1988, 2025. doi:10.23919/ACC63710.2025.11107751
-
[23]
Y . Hong, H. Huang, M. Li, L. F.-F. Li, J. Wu, and Y . Choi. Learning from trials and errors: Reflective test-time planning for embodied llms, 2026. URL http://arxiv.org/abs/2602. 21198
2026
-
[24]
B. Thananjeyan, A. Balakrishna, S. Nair, M. Luo, K. Srinivasan, M. Hwang, J. E. Gonzalez, J. Ibarz, C. Finn, and K. Goldberg. Recovery rl: Safe reinforcement learning with learned recovery zones.IEEE Robotics and Automation Letters, 6(3):4915–4922, 2021. doi:10.1109/ LRA.2021.3070252
-
[25]
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Z. Luo, Y . Xie, F. Hu, L. Fan, G. Shi, and Y . Zhu. Self-improving vision-language-action models with data generation via residual RL. InThe F ourteenth International Conference on Learning Representations, 2026. URL https:// openreview.net/forum?id=eUGoqrZ6Ea
2026
- [26]
-
[27]
X. Xu, Y . Hou, Z. Liu, and S. Song. Compliant residual DAgger: Improving real-world contact- rich manipulation with human corrections. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025. URL https://openreview.net/forum? id=cjcm5LYVWm
2025
-
[28]
Liang, R
J. Liang, R. He, and T. Tan. A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025
2025
-
[29]
Z. Wang, Y . Luo, L. Zheng, Z. Chen, S. Wang, and Z. Huang. In search of lost online test-time adaptation: A survey.International Journal of Computer Vision, 133(3):1106–1139, 2025
2025
-
[30]
D. Chen, D. Wang, T. Darrell, and S. Ebrahimi. Contrastive test-time adaptation. InCVPR, 2022
2022
-
[31]
Y . Sun, X. Wang, Z. Liu, J. Miller, A. Efros, and M. Hardt. Test-time training with self- supervision for generalization under distribution shifts. In H. D. III and A. Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 ofPro- ceedings of Machine Learning Research, pages 9229–9248. PMLR, 13–18 Jul 2020. URL ht...
2020
-
[32]
H. S. Yoon, E. Yoon, J. T. J. Tee, M. A. Hasegawa-Johnson, Y . Li, and C. D. Yoo. C-TPT: Calibrated test-time prompt tuning for vision-language models via text feature dispersion. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=jzzEHTBFOT
2024
-
[33]
Iwasawa and Y
Y . Iwasawa and Y . Matsuo. Test-time classifier adjustment module for model-agnostic domain generalization. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 2427–2440. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/ paper/202...
2021
-
[34]
A. Chen, Z. Liu, J. Zhang, A. Prabhakar, Z. Liu, S. Heinecke, S. Savarese, V . Zhong, and C. Xiong. Test-time adaptation for LLM agents via environment interaction. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=OH4PE0TDo0
2026
-
[35]
J. Hu, Z. Zhang, G. Chen, X. Wen, C. Shuai, W. Luo, B. Xiao, Y . Li, and M. Tan. Test-time learning for large language models. InF orty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=iCYbIaGKSR
2025
-
[36]
S. Niu, C. Miao, G. Chen, P. Wu, and P. Zhao. Test-time model adaptation with only forward passes. InThe International Conference on Machine Learning, 2024
2024
-
[37]
S. Kim, G. Oh, H. Ko, D. Ji, D. Lee, B.-J. Lee, S. Jang, and S. Kim. Test-time adaptation for online vision-language navigation with feedback-based reinforcement learning. InF orty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=K4GaB4fdIq
2025
-
[38]
Wagenmaker, Z
A. Wagenmaker, Z. Zhou, and S. Levine. Behavioral exploration: Learning to explore via in-context adaptation. InF orty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=tlLkY9E2bZ
2025
-
[39]
M. Yoo, J. Jang, S. Yoon, and H. Woo. World model implanting for test-time adaptation of embodied agents. InF orty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=tpbtodnI1p
2025
-
[40]
M. Liu, D. Pathak, and A. Agarwal. Locoformer: Generalist locomotion via long-context adaptation. In9th Annual Conference on Robot Learning, 2025. 11
2025
- [41]
-
[42]
T. Xie, N. Jiang, H. Wang, C. Xiong, and Y . Bai. Policy finetuning: Bridging sample-efficient offline and online reinforcement learning.Advances in neural information processing systems, 34:27395–27407, 2021
2021
-
[43]
Zhang, W
H. Zhang, W. Xu, and H. Yu. Policy expansion for bridging offline-to-online reinforcement learning. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=-Y34L45JR6z
2023
-
[44]
S. Lee, Y . Seo, K. Lee, P. Abbeel, and J. Shin. Offline-to-online reinforcement learning via balanced replay and pessimistic Q-ensemble. InConference on Robot Learning, pages 1702–1712. PMLR, 2022
2022
-
[45]
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
2023
-
[46]
Nakamoto, Y
M. Nakamoto, Y . Zhai, A. Singh, M. S. Mark, Y . Ma, C. Finn, A. Kumar, and S. Levine. Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum? id=GcEIvidYSw
2023
-
[47]
Q. Li, J. Zhang, D. Ghosh, A. Zhang, and S. Levine. Accelerating exploration with unlabeled prior data. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=Itorzn4Kwf
2023
-
[48]
Q. Li, Z. Zhou, and S. Levine. Reinforcement learning with action chunking. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2026. URL https: //openreview.net/forum?id=XUks1Y96NR
2026
-
[49]
Kostrikov, A
I. Kostrikov, A. Nair, and S. Levine. Offline reinforcement learning with implicit q-learning. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=68n2s9ZJWF8
2022
-
[50]
A. Z. Ren, J. Lidard, L. L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization. InarXiv preprint arXiv:2409.00588, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
S. Park, Q. Li, and S. Levine. Flow q-learning. InF orty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=KVf2SFL1pi
2025
-
[52]
Zhang, C
T. Zhang, C. Yu, S. Su, and Y . Wang. Reinflow: Fine-tuning flow matching policy with online reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=ACagRwCCqu
2026
-
[53]
J. Liu, F. Gao, B. Wei, X. Chen, Q. Liao, Y . Wu, C. Yu, and Y . Wang. What can RL bring to VLA generalization? an empirical study. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2026. URLhttps://openreview.net/forum?id=qmBMPInbZC
2026
-
[54]
H. Li, Y . Zuo, J. Yu, Y . Zhang, Y . Zhaohui, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, D. Wang, D. Luo, Y . Fan, Y . Sun, J. Zeng, J. Pang, S. Zhang, Y . Wang, Y . Mu, B. Zhou, and N. Ding. SimpleVLA-RL: Scaling VLA training via reinforcement learning. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openrevi...
2026
-
[55]
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen. Improving vision-language- action model with online reinforcement learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15665–15672, 2025. doi:10.1109/ICRA55743.2025. 11127299
-
[56]
A. K. Jain, V . Mohta, S. Kim, A. Bhardwaj, J. Ren, Y . Feng, S. Choudhury, and G. Swamy. A smooth sea never made a skilled SAILOR: Robust imitation via learning to search. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=qN5hmLkBtC
2025
-
[57]
C. Gokmen, D. Ho, and M. Khansari. Asking for help: Failure prediction in behavioral cloning through value approximation. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5821–5828, 2023. doi:10.1109/ICRA48891.2023.10161004
-
[58]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum? id=HPuSIXJaa9
2023
-
[59]
Wallace, M
B. Wallace, M. Dang, R. Rafailov, L. Zhou, A. Lou, S. Purushwalkam, S. Ermon, C. Xiong, S. Joty, and N. Naik. Diffusion model alignment using direct preference optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
2024
-
[60]
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.Robotics: Science and Systems, 2025
2025
-
[61]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, S. Nasiriany, Y . Zhu, and K. Lin. robosuite: A modular simulation framework and benchmark for robot learning. InarXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[62]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021
2021
-
[63]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. In5th Annual Conference on Robot Learning, 2021. URL https: //openreview.net/forum?id=JrsfBJtDFdI
2021
-
[64]
Wu and K
Y . Wu and K. He. Group normalization. InProceedings of the European conference on computer vision (ECCV), pages 3–19, 2018
2018
-
[65]
D. Misra. Mish: A self regularized non-monotonic neural activation function, 2019
2019
-
[66]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 6840–6851. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
2020
-
[67]
A. Q. Nichol and P. Dhariwal. Improved denoising diffusion probabilistic models. InInterna- tional conference on machine learning, pages 8162–8171. PMLR, 2021
2021
-
[68]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=St1giarCHLP. 13
2021
-
[69]
Fujimoto, H
S. Fujimoto, H. Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018
2018
-
[70]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InInternational Con- ference on Learning Representations, 2019. URL https://openreview.net/forum?id= Bkg6RiCqY7
2019
-
[71]
D. A. Pomerleau. Alvinn: An autonomous land vehicle in a neural network.Advances in neural information processing systems, 1, 1988
1988
-
[72]
Zhang, Z
T. Zhang, Z. McCarthy, O. Jow, D. Lee, X. Chen, K. Goldberg, and P. Abbeel. Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. In2018 IEEE International Conference on Robotics and Automation (ICRA), pages 5628–5635. IEEE, 2018
2018
-
[73]
Florence, L
P. Florence, L. Manuelli, and R. Tedrake. Self-supervised correspondence in visuomotor policy learning.IEEE Robotics and Automation Letters, 5(2):492–499, 2019
2019
-
[74]
Rahmatizadeh, P
R. Rahmatizadeh, P. Abolghasemi, L. B¨ol¨oni, and S. Levine. Vision-based multi-task manip- ulation for inexpensive robots using end-to-end learning from demonstration. In2018 IEEE international conference on robotics and automation (ICRA), pages 3758–3765. IEEE, 2018
2018
-
[75]
Florence, C
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson. Implicit behavioral cloning. In5th Annual Conference on Robot Learning, 2021
2021
-
[76]
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V . Sindhwani, et al. Transporter networks: Rearranging the visual world for robotic manipulation. InConference on Robot Learning, pages 726–747. PMLR, 2021
2021
-
[77]
J. Wu, X. Sun, A. Zeng, S. Song, J. Lee, S. Rusinkiewicz, and T. Funkhouser. Spatial action maps for mobile manipulation. InProceedings of Robotics: Science and Systems (RSS), 2020
2020
-
[78]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[79]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[80]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.