FaithMed: Training LLMs For Faithful Evidence-Based Medical Reasoning
Pith reviewed 2026-07-03 21:05 UTC · model grok-4.3
The pith
FaithMed trains medical LLMs by assigning rewards to each reasoning step against clinician rubrics for evidence use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
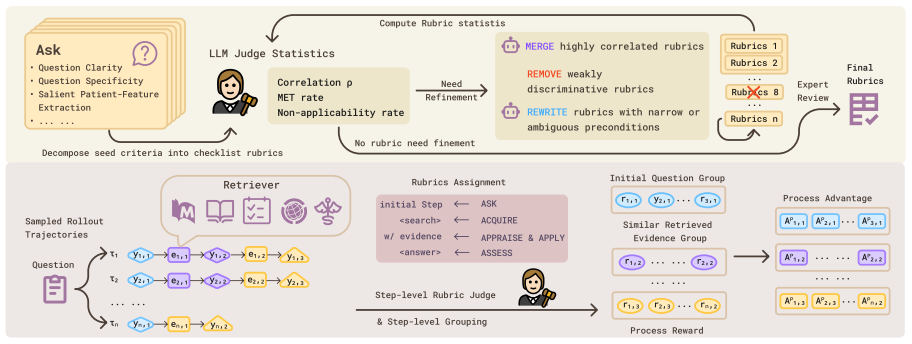
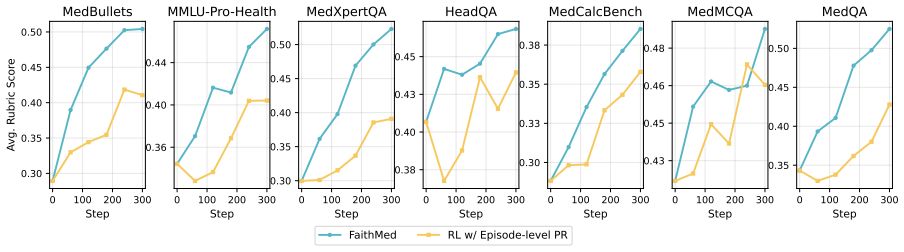
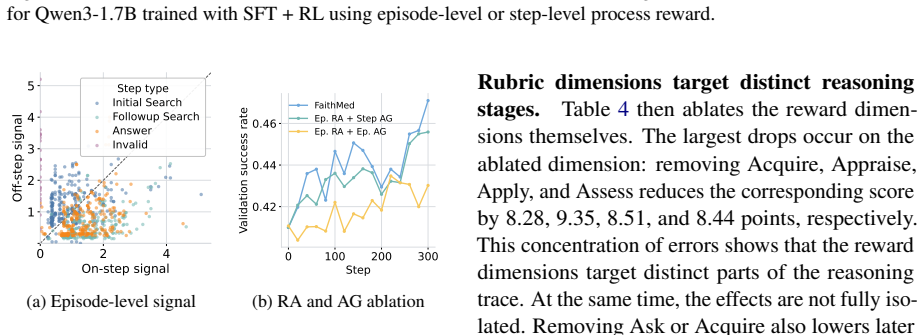
FaithMed improves average performance by 9 percent over agentic-search baselines and 5.8 percent over outcome-only RL across seven medical benchmarks, while increasing evidence-based medicine rubric scores by 15.5 percent over agentic-search Qwen3 baselines. The framework achieves this by combining clinician-designed rubrics with reinforcement learning that uses step-level process reward assignment and advantage grouping.
What carries the argument
Clinician-designed rubrics that encode process-level criteria for evidence appraisal and application, paired with step-level reward assignment inside reinforcement learning.
If this is right
- Medical LLMs trained this way produce both higher task accuracy and more transparent, evidence-grounded justifications.
- Step-level process rewards outperform training that rewards only final outcomes.
- The same rubric-plus-step-reward approach can be applied to any benchmark where process faithfulness matters.
- Explicit supervision of evidence use reduces reliance on ungrounded reasoning steps.
Where Pith is reading between the lines
- If the rubrics capture core clinical standards, the same training loop could transfer to legal or scientific reasoning tasks that also require traceable evidence use.
- Models trained under step-level rewards may show lower rates of unsupported claims when deployed in decision-support tools.
- Testing the trained models on live clinical vignettes with outcome tracking would reveal whether higher rubric scores translate to better patient-level decisions.
Load-bearing premise
The clinician-designed rubrics, even after automatic refinement, provide a valid and unbiased measure of reasoning faithfulness that generalizes across the seven benchmarks.
What would settle it
An independent clinician panel rates reasoning traces on new cases and finds that rubric scores do not predict human judgments of faithfulness or that the reported performance gains vanish under the new ratings.
Figures

read the original abstract
Faithful reasoning is essential in medicine, where clinical decisions require transparent justification grounded in reliable evidence. Current medical LLMs either lack active access to evidence or use retrieved evidence without supervising how it should be appraised and applied during reasoning. To address this, we formalize evidence-based medicine principles as process-level criteria and introduce FaithMed, a framework that combines clinician-designed, automatically refined rubrics with reinforcement learning using step-level process reward assignment and advantage grouping. Across seven medical benchmarks, FaithMed improves over agentic-search baselines (+9% on average) and outcome-only RL (+5.8%), while raising average evidence-based medicine rubric scores over agentic-search Qwen3 baselines (+15.5%). This work demonstrates that explicit step-level supervision can improve both task success and the faithfulness of the reasoning process. Code is available at https://github.com/cxcscmu/FaithMed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FaithMed, a framework that formalizes evidence-based medicine (EBM) principles as process-level criteria and trains LLMs via reinforcement learning with step-level process rewards derived from clinician-designed, automatically refined rubrics. It reports average gains of +9% over agentic-search baselines and +5.8% over outcome-only RL across seven medical benchmarks, plus a +15.5% increase in average EBM rubric scores versus agentic-search Qwen3 baselines, claiming that explicit step-level supervision improves both task success and reasoning faithfulness. Code is released at https://github.com/cxcscmu/FaithMed.
Significance. If the faithfulness gains can be shown to hold under evaluation independent of the training rubrics, the work would provide concrete evidence that process-level supervision grounded in EBM principles can simultaneously boost benchmark performance and the transparency of medical reasoning in LLMs. The public code release is a clear strength that supports reproducibility.
major comments (1)
- [Abstract] Abstract: The reported +15.5% improvement in average EBM rubric scores is obtained using the same family of clinician-designed (automatically refined) rubrics that supply the step-level process rewards during RL training. Because the evaluation metric is the direct optimization target, the faithfulness gain is at least partly by construction; an independent held-out rubric, human clinician ratings on a separate scale, or cross-benchmark rubric transfer experiment is required to substantiate the central claim that step-level supervision improves faithfulness rather than merely fitting the training signal.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation of reasoning faithfulness. We address the major comment point-by-point below and will revise the manuscript to incorporate the suggested clarifications and additional validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported +15.5% improvement in average EBM rubric scores is obtained using the same family of clinician-designed (automatically refined) rubrics that supply the step-level process rewards during RL training. Because the evaluation metric is the direct optimization target, the faithfulness gain is at least partly by construction; an independent held-out rubric, human clinician ratings on a separate scale, or cross-benchmark rubric transfer experiment is required to substantiate the central claim that step-level supervision improves faithfulness rather than merely fitting the training signal.
Authors: We agree that the +15.5% gain on EBM rubric scores is measured with the same clinician-designed rubrics used to generate the process-level rewards, so this particular metric improvement is partly by construction. The task-performance gains (+9% over agentic-search baselines and +5.8% over outcome-only RL) remain independent of the rubrics and provide separate evidence that the process supervision yields more effective reasoning. In the revision we will explicitly note this limitation of the current faithfulness evaluation and add results from at least one independent protocol (e.g., held-out rubric transfer or human clinician ratings on a held-out sample of traces) to better substantiate the faithfulness claim. revision: yes
Circularity Check
Rubric scores used for both RL training and evaluation risk non-independent measurement of faithfulness
specific steps
-
fitted input called prediction
[Abstract]
"we formalize evidence-based medicine principles as process-level criteria and introduce FaithMed, a framework that combines clinician-designed, automatically refined rubrics with reinforcement learning using step-level process reward assignment and advantage grouping. Across seven medical benchmarks, FaithMed improves over agentic-search baselines (+9% on average) and outcome-only RL (+5.8%), while raising average evidence-based medicine rubric scores over agentic-search Qwen3 baselines (+15.5%)."
The rubrics supply the process rewards that drive RL optimization; the identical rubric family is then used to compute the reported +15.5% EBM rubric score improvement. Because the evaluation metric is the training reward signal, the faithfulness gain is a direct consequence of successful optimization against that signal rather than an independent test.
full rationale
The paper's central empirical claim rests on two reported gains: task accuracy on external medical benchmarks (+9% avg) and EBM rubric scores (+15.5%). The latter is obtained by optimizing the policy directly against step-level rewards derived from the same clinician-designed, automatically refined rubrics that are later used to compute the evaluation scores. While the benchmark accuracy numbers are independent, the faithfulness improvement reduces to the training objective by construction and therefore cannot serve as external validation of the rubrics as an unbiased proxy. This matches the fitted-input-called-prediction pattern at the level of the reward signal rather than a mathematical equation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[9]
2015 , publisher=
Improving Diagnosis in Health Care , author=. 2015 , publisher=
2015
-
[10]
2024 , eprint=
ED-Copilot: Reduce Emergency Department Wait Time with Language Model Diagnostic Assistance , author=. 2024 , eprint=
2024
-
[11]
2023 , eprint=
Towards Expert-Level Medical Question Answering with Large Language Models , author=. 2023 , eprint=
2023
-
[13]
Applied Sciences , volume =
What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams , author =. Applied Sciences , volume =. 2021 , doi =
2021
-
[15]
Proceedings of the Conference on Health, Inference, and Learning , pages =
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering , author =. Proceedings of the Conference on Health, Inference, and Learning , pages =. 2022 , editor =
2022
-
[16]
Advances in Neural Information Processing Systems 37 , year =
MedCalc-Bench: Evaluating Large Language Models for Medical Calculations , author =. Advances in Neural Information Processing Systems 37 , year =
-
[17]
2024 , url =
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and Li, Tianle and Ku, Max and Wang, Kai and Zhuang, Alex and Fan, Rongqi and Yue, Xiang and Chen, Wenhu , booktitle =. 2024 , url =
2024
-
[20]
2026 , eprint =
Medmarks: A Comprehensive Open-Source LLM Benchmark Suite for Medical Tasks , author =. 2026 , eprint =
2026
-
[21]
The Western Journal of Emergency Medicine , volume=
Clinical Reasoning: Defining It, Teaching It, Assessing It, Studying It , author=. The Western Journal of Emergency Medicine , volume=. 2017 , publisher=
2017
-
[22]
Information , VOLUME =
Yang, Hua and Li, Shilong and Gonçalves, Teresa , TITLE =. Information , VOLUME =. 2024 , NUMBER =
2024
-
[23]
2025 , eprint=
MedS ^3 : Towards Medical Slow Thinking with Self-Evolved Soft Dual-sided Process Supervision , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Med-PRM: Medical Reasoning Models with Stepwise, Guideline-verified Process Rewards , author=. 2025 , eprint=
2025
-
[25]
2024 , eprint=
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs , author=. 2024 , eprint=
2024
-
[26]
2023 , eprint=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
2023
-
[27]
2023 , eprint=
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine , author=. 2023 , eprint=
2023
-
[28]
2024 , eprint=
Effective Large Language Model Adaptation for Improved Grounding and Citation Generation , author=. 2024 , eprint=
2024
-
[30]
2025 , eprint=
Fact-Aware Multimodal Retrieval Augmentation for Accurate Medical Radiology Report Generation , author=. 2025 , eprint=
2025
-
[31]
2021 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
2021
-
[32]
2024 , eprint=
Capabilities of Gemini Models in Medicine , author=. 2024 , eprint=
2024
-
[33]
2023 , eprint=
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models , author=. 2023 , eprint=
2023
-
[34]
, title =
Schwartz, Alan and Elstein, Arthur S. , title =. Clinical Reasoning in the Health Professions , editor =
-
[35]
Healthcare , volume=
ChatGPT and the Future of Digital Health: A Study on Healthcare Workers' Perceptions and Expectations , author=. Healthcare , volume=. 2023 , publisher=
2023
-
[38]
2019 , url =
Subramanya, Suhas Jayaram and Devvrit, Fnu and Simhadri, Harsha Vardhan and Krishnawamy, Ravishankar and Kadekodi, Rohan , booktitle =. 2019 , url =
2019
-
[42]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , journal=. 2024 , eprint=
2024
-
[43]
2025 , eprint=
Jin, Bowen and Zeng, Hansi and Yue, Zhenrui and Yoon, Jinsung and Arik, Sercan and Wang, Dong and Zamani, Hamed and Han, Jiawei , journal=. 2025 , eprint=
2025
-
[45]
Group-in-Group Policy Optimization for
Feng, Lang and Xue, Zhenghai and Liu, Tingcong and An, Bo , journal=. Group-in-Group Policy Optimization for. 2025 , eprint=
2025
-
[46]
and Qiu, Xinchi and Whitehouse, Chenxi and Alazraki, Lisa and Goel, Shashwat and Barbieri, Francesco and Willi, Timon and Mathur, Akhil and Leontiadis, Ilias , journal=
Shen, William F. and Qiu, Xinchi and Whitehouse, Chenxi and Alazraki, Lisa and Goel, Shashwat and Barbieri, Francesco and Willi, Timon and Mathur, Akhil and Leontiadis, Ilias , journal=. Rethinking Rubric Generation for Improving
-
[47]
2025 , address=
Lee, Yukyung and Kim, JoongHoon and Kim, Jaehee and Cho, Hyowon and Kang, Jaewook and Kang, Pilsung and Kim, Najoung , booktitle=. 2025 , address=
2025
-
[49]
Hanjie Chen, Zhouxiang Fang, Yash Singla, and Mark Dredze. 2025. https://doi.org/10.18653/v1/2025.naacl-long.182 Benchmarking large language models on answering and explaining challenging medical questions . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technol...
-
[50]
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. 2024. https://arxiv.org/abs/2412.18925 Huatuogpt-o1, towards medical complex reasoning with llms . Preprint, arXiv:2412.18925
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Zeming Chen, Alejandro Hernández Cano, Angelika Romanou, Antoine Bonnet, Kyle Matoba, Francesco Salvi, Matteo Pagliardini, Simin Fan, Andreas Köpf, Amirkeivan Mohtashami, Alexandre Sallinen, Alireza Sakhaeirad, Vinitra Swamy, Igor Krawczuk, Deniz Bayazit, Axel Marmet, Syrielle Montariol, Mary-Anne Hartley, Martin Jaggi, and Antoine Bosselut. 2023. https:/...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Jarrod Dusin, Andrea Melanson, and Lisa Mische-Lawson. 2023. https://doi.org/10.1136/bmjopen-2022-071188 Evidence-based practice models and frameworks in the healthcare setting: a scoping review . BMJ Open, 13(5):e071188
-
[53]
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. 2025. https://arxiv.org/abs/2505.10978 Group-in-group policy optimization for LLM agent training . arXiv preprint arXiv:2505.10978
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [54]
-
[55]
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.398 Enabling large language models to generate text with citations . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6465--6488, Singapore. Association for Computational Linguistics
-
[56]
Larry D Gruppen. 2017. https://doi.org/10.5811/westjem.2016.11.33191 Clinical reasoning: Defining it, teaching it, assessing it, studying it . The Western Journal of Emergency Medicine, 18(1):4--7
-
[57]
Siqing Huo, Negar Arabzadeh, and Charles Clarke. 2023. https://doi.org/10.1145/3624918.3625336 Retrieving supporting evidence for generative question answering . In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, SIGIR-AP ’23, page 11–20. ACM
- [58]
-
[59]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. https://arxiv.org/abs/2503.09516 Search-R1 : Training LLMs to reason and leverage search engines with reinforcement learning . arXiv preprint arXiv:2503.09516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. https://doi.org/10.3390/app11146421 What disease does this patient have? a large-scale open domain question answering dataset from medical exams . Applied Sciences, 11(14):6421
-
[61]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. https://doi.org/10.18653/v1/D19-1259 P ub M ed QA : A dataset for biomedical research question answering . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-I...
-
[62]
Applebaum, Zain Anwar, Maame Sarfo-Gyamfi, Conrad W
Nikhil Khandekar, Qiao Jin, Guangzhi Xiong, Soren Dunn, Serina S. Applebaum, Zain Anwar, Maame Sarfo-Gyamfi, Conrad W. Safranek, Abid A. Anwar, Andrew Zhang, Aidan Gilson, Maxwell B. Singer, Amisha Dave, Andrew Taylor, Aidong Zhang, Qingyu Chen, and Zhiyong Lu. 2024. https://papers.nips.cc/paper_files/paper/2024/hash/99e81750f3fdfcaf9613db2dbf4bd623-Abstr...
2024
-
[63]
Yukyung Lee, JoongHoon Kim, Jaehee Kim, Hyowon Cho, Jaewook Kang, Pilsung Kang, and Najoung Kim. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.796 C heck E val: A reliable LLM -as-a-judge framework for evaluating text generation using checklists . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15771--1...
-
[64]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. https://arxiv.org/abs/2005.11401 Retrieval-augmented generation for knowledge-intensive nlp tasks . Preprint, arXiv:2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[65]
Harsha Nori, Yin Tat Lee, Sheng Zhang, Dean Carignan, Richard Edgar, Nicolo Fusi, Nicholas King, Jonathan Larson, Yuanzhi Li, Weishung Liu, Renqian Luo, Scott Mayer McKinney, Robert Osazuwa Ness, Hoifung Poon, Tao Qin, Naoto Usuyama, Chris White, and Eric Horvitz. 2023. https://arxiv.org/abs/2311.16452 Can generalist foundation models outcompete special-p...
-
[66]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2022. https://proceedings.mlr.press/v174/pal22a.html Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering . In Proceedings of the Conference on Health, Inference, and Learning, volume 174 of Proceedings of Machine Learning Research, pages 248--260. PMLR
2022
-
[67]
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, Juanma Zambrano Chaves, Szu-Yeu Hu, Mike Schaekermann, Aishwarya Kamath, Yong Cheng, David G. T. Barrett, Cathy Cheung, Basil Mustafa, Anil Palepu, Daniel McDuff, Le Hou, Tomer Golany, Luyang Liu, Jean baptiste Alayrac, Nei...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
David L Sackett, William MC Rosenberg, J A Muir Gray, R Brian Haynes, and W Scott Richardson. 1996. https://doi.org/10.1136/bmj.312.7023.71 Evidence based medicine: what it is and what it isn't . BMJ, 312(7023):71--72
-
[69]
Alan Schwartz and Arthur S. Elstein. 2008. Clinical reasoning in medicine. In Joy Higgs, Mark A. Jones, Stephen Loftus, and Nicole Christensen, editors, Clinical Reasoning in the Health Professions, 3 edition. Elsevier, Edinburgh
2008
-
[70]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 DeepSeekMath : Pushing the limits of mathematical reasoning in open language models . arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. https://doi.org/10.1145/3689031.3696075 Hybridflow: A flexible and efficient RLHF framework . In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys '25, Rotterdam, Netherlands. Association for Computing Machinery
-
[72]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Seneviratne, Paul Gamble, Chris Kelly, Abubakr Babiker, Nathanael Schärli, Aakanksha Chowdhery, Philip Mansfield, Dina Demner-Fushman, Blaise Agüera y Arcas, Dale Webster, Greg S. Corrado,...
-
[73]
Towards Expert-Level Medical Question Answering with Large Language Models
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, Mike Schaekermann, Amy Wang, Mohamed Amin, Sami Lachgar, Philip Mansfield, Sushant Prakash, Bradley Green, Ewa Dominowska, Blaise Aguera y Arcas, Nenad Tomasev, Yun Liu, Renee Wong, Christopher Semturs, S. Sara Mahdavi,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[74]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. https://papers.nips.cc/paper/9527-diskann-fast-accurate-billion-point-nearest-neighbor-search-on-a-single-node DiskANN : Fast accurate billion-point nearest neighbor search on a single node . In Advances in Neural Information Processing Systems 32
2019
- [75]
- [76]
-
[77]
Mohamad-Hani Temsah, Fadi Aljamaan, Khalid H. Malki, Khalid Alhasan, Ibraheem Altamimi, Razan Aljarbou, Faisal Bazuhair, Abdulmajeed Alsubaihin, Naif Abdulmajeed, Fatimah S. Alshahrani, Reem Temsah, Turki Alshahrani, Lama Al-Eyadhy, Serin Mohammed Alkhateeb, Basema Saddik, Rabih Halwani, Amr Jamal, Jaffar A. Al-Tawfiq, and Ayman Al-Eyadhy. 2023. https://d...
-
[78]
David Vilares and Carlos G \'o mez-Rodr \'i guez. 2019. https://doi.org/10.18653/v1/P19-1092 HEAD - QA : A healthcare dataset for complex reasoning . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 960--966, Florence, Italy. Association for Computational Linguistics
-
[79]
Xiao Wang, Mengjue Tan, Qiao Jin, Guangzhi Xiong, Yu Hu, Aidong Zhang, Zhiyong Lu, and Minjia Zhang. 2025. https://doi.org/10.18653/v1/2025.findings-acl.967 M ed C ite: Can language models generate verifiable text for medicine? In Findings of the Association for Computational Linguistics: ACL 2025, pages 18891--18913, Vienna, Austria. Association for Comp...
-
[80]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. 2024. https://papers.nips.cc/paper_files/paper/2024/hash/ad236edc564f3e3156e1b2feafb99a24-Abstract-Datasets_and_Benchmarks_Track.html MMLU -pro: A...
2024
-
[81]
Benjamin Warner, Ratna Sagari Grandhi, Max Kieffer, Aymane Ouraq, Saurav Panigrahi, Geetu Ambwani, Kunal Bagga, Nikhil Khandekar, Arya Hariharan, Nishant Mishra, Manish Ram, Shamus Sim Zi Yang, Ahmed Essouaied, Adepoju Jeremiah Moyondafoluwa, Robert Scholz, Bofeng Huang, Molly Beavers, Srishti Gureja, Anish Mahishi, Sameed Khan, Maxime Griot, Hunar Batra,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[82]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. https://arxiv.org/abs/2201.11903 Chain-of-thought prompting elicits reasoning in large language models . Preprint, arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[83]
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.372 Benchmarking retrieval-augmented generation for medicine . In Findings of the Association for Computational Linguistics: ACL 2024, pages 6233--6251, Bangkok, Thailand. Association for Computational Linguistics
-
[84]
Hua Yang, Shilong Li, and Teresa Gonçalves. 2024. https://doi.org/10.3390/info15080494 Enhancing biomedical question answering with large language models . Information, 15(8)
-
[85]
Xi Ye, Ruoxi Sun, Sercan Ö. Arik, and Tomas Pfister. 2024. https://arxiv.org/abs/2311.09533 Effective large language model adaptation for improved grounding and citation generation . Preprint, arXiv:2311.09533
-
[86]
Jaehoon Yun, Jiwoong Sohn, Jungwoo Park, Hyunjae Kim, Xiangru Tang, Yanjun Shao, Yonghoe Koo, Minhyeok Ko, Qingyu Chen, Mark Gerstein, Michael Moor, and Jaewoo Kang. 2025. https://arxiv.org/abs/2506.11474 Med-prm: Medical reasoning models with stepwise, guideline-verified process rewards . Preprint, arXiv:2506.11474
-
[87]
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. 2025. https://arxiv.org/abs/2501.18362 Medxpertqa: Benchmarking expert-level medical reasoning and understanding . arXiv preprint arXiv:2501.18362
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.