Beyond Pixel Diffs: Benchmarking Image Change Captioning for Web UI Visual Regression Testing
Pith reviewed 2026-07-03 16:45 UTC · model grok-4.3
The pith
Trained image change captioning methods already suppress non-meaningful visual noise more selectively than pixel-level comparisons in web UI visual regression testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that image difference captioning methods, when applied to pairs of web UI screenshots, tend to struggle due to the domain's layout diversity, dense text, and fine-grained changes, yet the trained methods already suppress non-meaningful visual noise far more selectively than the pixel-level comparison approach relied on by visual regression testing, providing a solid foundation for future domain-specific research.
What carries the argument
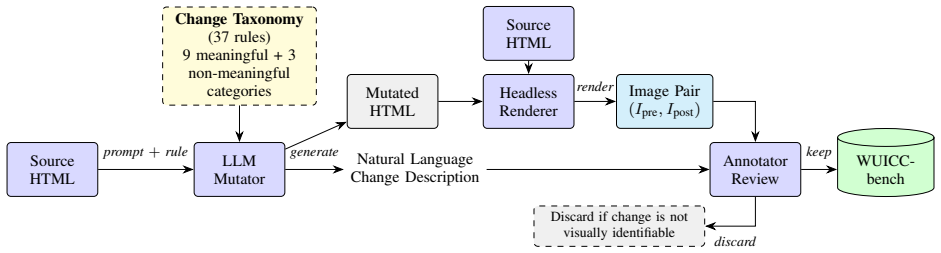
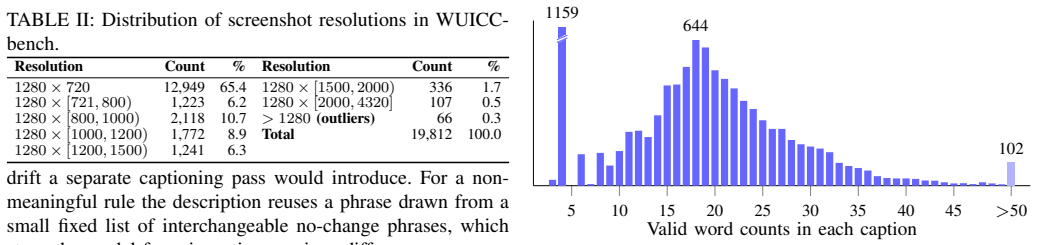
The WUICC-bench dataset, which supplies paired UI screenshots with change captions to benchmark image difference captioning methods for generating natural language descriptions of visual differences.
If this is right
- Natural language change descriptions can replace or supplement binary difference flags in visual regression testing workflows.
- The selective noise suppression already demonstrated reduces the time developers spend reviewing rendering artifacts at each release.
- Existing captioning methods provide a workable starting point for building web-UI-specific models rather than requiring entirely new architectures.
- The benchmark enables systematic comparison of future methods on the same web UI change data.
Where Pith is reading between the lines
- Fine-tuning captioning models on larger collections of real UI regression examples could close the remaining gap on fine-grained changes.
- Embedding the captioning output into existing VRT tools would let testers search or filter regressions by described change type.
- The same benchmark approach could be extended to mobile or desktop UI screenshots to test cross-platform generalizability.
Load-bearing premise
The WUICC-bench dataset and the selected image difference captioning methods are representative enough of real web UI changes and practical visual regression testing needs to support the superiority claim.
What would settle it
A side-by-side deployment in a production continuous-integration pipeline that measures whether the captioning outputs actually reduce the volume of false-positive reviews sent to human testers compared with standard pixel comparison.
Figures



read the original abstract
Visual regression testing (VRT) is a standard quality assurance step in modern software release pipelines. On every change, it re-renders user interface (UI) screenshots, compares each one against an approved baseline image, and routes any detected difference to a human reviewer who decides whether it is an intended update or an unintended regression. A widely used approach, especially in open-source and continuous-integration pipelines, is pixel-level comparison, which is semantically blind and treats rendering noise and genuine defects identically, producing large volumes of false positives that force developers and testers to spend substantial time and effort manually reviewing flagged differences at every release cycle. Industry tools apply machine learning to VRT, but lack public evaluation. More critically, no dataset or benchmark exists to support natural language descriptions of UI changes, a capability that tells testers what changed in words instead of leaving them to interpret a binary flag or a highlighted region. To address the gap, we propose a new task, Web UI Image Change Captioning (WUICC), which sits at the intersection of VRT and image difference captioning (IDC), and release WUICC-bench, its first dataset and benchmark for the task. We evaluate eleven representative IDC methods, together with two zero-shot general-purpose LLMs. We find that: (1) these methods tend to struggle in the Web UI domain due to its layout diversity, dense text, and fine-grained changes, and (2) yet the trained methods already suppress non-meaningful visual noise far more selectively than the pixel-level comparison VRT relies on, providing a solid foundation for future domain-specific research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Web UI Image Change Captioning (WUICC) task at the intersection of visual regression testing (VRT) and image difference captioning (IDC), releases the WUICC-bench dataset and benchmark, evaluates eleven representative IDC methods plus two zero-shot LLMs, and reports two findings: (1) the methods struggle with Web UI characteristics such as layout diversity, dense text, and fine-grained changes, and (2) the trained methods suppress non-meaningful visual noise far more selectively than pixel-level comparison.
Significance. If the WUICC-bench dataset is shown to contain realistic instances of rendering noise paired with human judgments distinguishing noise from defects, the benchmark could support development of captioning approaches that reduce false positives in VRT pipelines and serve as a foundation for domain-specific research.
major comments (1)
- [Abstract] Abstract: the claim that trained methods 'suppress non-meaningful visual noise far more selectively than the pixel-level comparison VRT relies on' is load-bearing for the second finding, yet the manuscript supplies no dataset statistics, sampling strategy for noise-only pairs, annotation protocol for distinguishing noise from defects, or fraction of such cases, so the selectivity advantage cannot be verified from the reported results.
Simulated Author's Rebuttal
We thank the referee for identifying this issue with the abstract's second finding. We address the comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that trained methods 'suppress non-meaningful visual noise far more selectively than the pixel-level comparison VRT relies on' is load-bearing for the second finding, yet the manuscript supplies no dataset statistics, sampling strategy for noise-only pairs, annotation protocol for distinguishing noise from defects, or fraction of such cases, so the selectivity advantage cannot be verified from the reported results.
Authors: We agree the claim is insufficiently supported. The manuscript does not include the requested statistics, sampling details, annotation protocol, or case fractions for noise-only pairs. The evaluation results compare captioning outputs against pixel diffs on the WUICC-bench test set, but without explicit noise annotation breakdowns this does not directly verify selective suppression. We will revise the abstract to remove or qualify the claim (e.g., rephrase to note that captioning methods produce fewer spurious outputs in practice) and add a new subsection in the dataset section describing any noise handling, sampling, and annotation protocol used during construction. If such details are absent from the original data collection, the claim will be dropped entirely. revision: yes
Circularity Check
No circularity: purely empirical benchmark and evaluation
full rationale
The paper introduces the WUICC task, releases WUICC-bench, and reports empirical results from evaluating eleven existing IDC methods plus two LLMs on that dataset. No derivations, equations, fitted parameters, predictions, or self-citation chains appear in the abstract or described content. All claims rest on direct performance measurements rather than any reduction to inputs by construction, self-definition, or imported uniqueness theorems. This is the standard case of a self-contained benchmark paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Web UI domain exhibits layout diversity, dense text, and fine-grained changes that make standard IDC methods struggle
Reference graph
Works this paper leans on
-
[1]
On the long-term use of visual gui testing in industrial practice: a case study,
E. Alégroth and R. Feldt, “On the long-term use of visual gui testing in industrial practice: a case study,”Empirical Software Engineering, vol. 22, no. 6, pp. 2937–2971, 2017
2017
-
[2]
Detection and localization of html presentation failures using computer vision-based techniques,
S. Mahajan and W. G. Halfond, “Detection and localization of html presentation failures using computer vision-based techniques,” in2015 IEEE 8th International Conference on Software Testing, Verification and Validation (ICST). IEEE, 2015, pp. 1–10
2015
-
[3]
Reducing redundant check- ing for visual regression testing,
Y . Adachi, H. Tanno, and Y . Yoshimura, “Reducing redundant check- ing for visual regression testing,” in2018 25th Asia-Pacific Software Engineering Conference (APSEC). IEEE, 2018, pp. 721–722
2018
-
[4]
Continuous delivery: Huge benefits, but challenges too,
L. Chen, “Continuous delivery: Huge benefits, but challenges too,”IEEE software, vol. 32, no. 2, pp. 50–54, 2015
2015
-
[5]
Why machine learning is revolution- izing visual regression testing,
SQA Experts, “Why machine learning is revolution- izing visual regression testing,” https://sqaexperts.com/ machine-learning-in-visual-regression-testing/, Apr. 2025, accessed: 2026-04-10
2025
-
[6]
Region-based detection of essential differences in image-based visual regression testing,
H. Tanno, Y . Adachi, Y . Yoshimura, K. Natsukawa, and H. Iwasaki, “Region-based detection of essential differences in image-based visual regression testing,”Journal of Information Processing, vol. 28, pp. 268– 278, 2020
2020
-
[7]
Mixvrt: Mix visual regression testing tool which mixes image comparison and html code comparison,
N. Aridome, N. Takahashi, T. Katayama, Y . Kita, H. Yamaba, K. Abu- rada, and N. Okazaki, “Mixvrt: Mix visual regression testing tool which mixes image comparison and html code comparison,”Journal of Robotics, Networking and Artificial Life, vol. 11, no. 3, pp. 214–219, 2026
2026
-
[8]
A method to mask dynamic content areas based on positional relationship of screen elements for visual regression testing,
Y . Adachi, H. Tanno, and Y . Yoshimura, “A method to mask dynamic content areas based on positional relationship of screen elements for visual regression testing,” in2020 IEEE 44th Annual Computers, Soft- ware, and Applications Conference (COMPSAC). IEEE, 2020, pp. 1755–1760
2020
-
[9]
Applitools eyes: AI-powered visual testing,
Applitools, “Applitools eyes: AI-powered visual testing,” https:// applitools.com/platform/eyes/, 2024, accessed: 2026-06-01
2024
-
[10]
Percy: Visual testing and review,
BrowserStack, “Percy: Visual testing and review,” https://percy.io, 2024, accessed: 2026-06-01
2024
-
[11]
Xbidetective: Leveraging vision language models for identifying cross-browser visual inconsistencies,
B. Grewal, J. Graham, J. Muizelaar, J. H. Odvarko, S. Mujahid, M. Castelluccio, and C.-P. Bezemer, “Xbidetective: Leveraging vision language models for identifying cross-browser visual inconsistencies,” inProceedings of the IEEE/ACM 48th International Conference on Software Engineering (ICSE), 2026
2026
-
[12]
Seeing is fixing: Cross-modal reasoning with multimodal llms for visual software issue repair,
K. Huang, J. Zhang, X. Xie, and C. Chen, “Seeing is fixing: Cross-modal reasoning with multimodal llms for visual software issue repair,” in 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2025, pp. 1156–1168
2025
-
[13]
Interactive change-aware transformer network for remote sensing image change captioning,
C. Cai, Y . Wang, and K.-H. Yap, “Interactive change-aware transformer network for remote sensing image change captioning,”Remote Sensing, vol. 15, no. 23, p. 5611, 2023
2023
-
[14]
Inter-temporal interaction and symmetric difference learning for remote sensing image change captioning,
Y . Li, X. Zhang, X. Cheng, P. Chen, and L. Jiao, “Inter-temporal interaction and symmetric difference learning for remote sensing image change captioning,”IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[15]
Dynamic and asymmetric enhancement for remote sensing image change captioning,
T. Xian, Z. Zhou, D. Zeng, and B. Li, “Dynamic and asymmetric enhancement for remote sensing image change captioning,”IEEE Trans- actions on Geoscience and Remote Sensing, vol. 63, pp. 1–15, 2025
2025
-
[16]
Towards comprehensive interactive change under- standing in remote sensing: A large-scale dataset and dual-granularity enhanced vlm,
J. Xue, Q. Deng, X. Wu, K. Yao, X. Yin, F. Yu, W. Zhou, Y . Zhong, Y . Liu, and D. Yang, “Towards comprehensive interactive change under- standing in remote sensing: A large-scale dataset and dual-granularity enhanced vlm,”IEEE Transactions on Geoscience and Remote Sensing, 2026
2026
-
[17]
Change-up: Advancing visualization and inference capability for multi-level remote sensing change interpre- tation,
M. Yang, L. Chen, and J. Zhou, “Change-up: Advancing visualization and inference capability for multi-level remote sensing change interpre- tation,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 15–24
2025
-
[18]
Exploring difference semantic prior guidance for remote sensing image change captioning,
Y . Li, X. Zhang, G. Wang, and T. Zhang, “Exploring difference semantic prior guidance for remote sensing image change captioning,”Remote Sensing, vol. 18, no. 2, p. 232, 2026
2026
-
[19]
Image difference captioning with pre-training and contrastive learning,
L. Yao, W. Wang, and Q. Jin, “Image difference captioning with pre-training and contrastive learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 3, 2022, pp. 3108– 3116
2022
-
[20]
Learning to describe differences between pairs of similar images,
H. Jhamtani and T. Berg-Kirkpatrick, “Learning to describe differences between pairs of similar images,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 4024– 4034
2018
-
[21]
Adaptive representation disentanglement network for change captioning,
Y . Tu, L. Li, L. Su, J. Du, K. Lu, and Q. Huang, “Adaptive representation disentanglement network for change captioning,”IEEE Transactions on Image Processing, vol. 32, pp. 2620–2635, 2023
2023
-
[22]
Self-supervised cross-view representation reconstruction for change captioning,
Y . Tu, L. Li, L. Su, Z.-J. Zha, C. Yan, and Q. Huang, “Self-supervised cross-view representation reconstruction for change captioning,” inPro- ceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 2805–2815
2023
-
[23]
Vixen: Visual text comparison network for image difference captioning,
A. Black, J. Shi, Y . Fan, T. Bui, and J. Collomosse, “Vixen: Visual text comparison network for image difference captioning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 2, 2024, pp. 846–854
2024
-
[24]
Omnidiff: A comprehensive benchmark for fine-grained image difference captioning,
Y . Liu, S. Hou, S. Hou, J. Du, S. Meng, and Y . Huang, “Omnidiff: A comprehensive benchmark for fine-grained image difference captioning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 21 440–21 449
2025
-
[25]
Remote sens- ing spatiotemporal vision–language models: A comprehensive survey,
C. Liu, J. Zhang, K. Chen, M. Wang, Z. Zou, and Z. Shi, “Remote sens- ing spatiotemporal vision–language models: A comprehensive survey,” IEEE Geoscience and Remote Sensing Magazine, 2025
2025
-
[26]
H. Laurençon, L. Tronchon, and V . Sanh, “Unlocking the conversion of web screenshots into html code with the websight dataset,”arXiv preprint arXiv:2403.09029, 2024
-
[27]
Prototype of mixvrt which is a visual regression testing tool that highlights layout defects in web pages,
N. Aridome, T. Katayama, Y . Kita, H. Yamaba, K. Aburada, and N. Okazaki, “Prototype of mixvrt which is a visual regression testing tool that highlights layout defects in web pages,” inProceedings of International Conference on Artificial Life and Robotics, vol. 30. ALife Robotics, 2025, pp. 575–579
2025
-
[28]
Chromatic: Visual testing for Storybook,
Chromatic, “Chromatic: Visual testing for Storybook,” https://www. chromatic.com, 2024, accessed: 2026-06-01
2024
-
[29]
Changes to captions: An attentive network for remote sensing change captioning,
S. Chang and P. Ghamisi, “Changes to captions: An attentive network for remote sensing change captioning,”IEEE Transactions on Image Processing, vol. 32, pp. 6047–6060, 2023
2023
-
[30]
Remote sensing image change captioning with dual-branch transformers: A new method and a large scale dataset,
C. Liu, R. Zhao, H. Chen, Z. Zou, and Z. Shi, “Remote sensing image change captioning with dual-branch transformers: A new method and a large scale dataset,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–20, 2022
2022
-
[31]
Change captioning: A new paradigm for multitemporal remote sensing image analysis,
G. Hoxha, S. Chouaf, F. Melgani, and Y . Smara, “Change captioning: A new paradigm for multitemporal remote sensing image analysis,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2022
2022
-
[32]
Change detection methods for remote sensing in the last decade: A comprehensive review,
G. Cheng, Y . Huang, X. Li, S. Lyu, Z. Xu, H. Zhao, Q. Zhao, and S. Xiang, “Change detection methods for remote sensing in the last decade: A comprehensive review,”Remote Sensing, vol. 16, no. 13, p. 2355, 2024
2024
-
[33]
Gpt-5.1,
OpenAI, “Gpt-5.1,” https://platform.openai.com, 2025, accessed: 2026- 04-30
2025
-
[34]
Expressing visual relationships via language,
H. Tan, F. Dernoncourt, Z. Lin, T. Bui, and M. Bansal, “Expressing visual relationships via language,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 1873–1883
2019
-
[35]
Single-stream extractor network with contrastive pre-training for remote-sensing change caption- ing,
Q. Zhou, J. Gao, Y . Yuan, and Q. Wang, “Single-stream extractor network with contrastive pre-training for remote-sensing change caption- ing,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–14, 2024
2024
-
[36]
Rscama: Remote sensing image change captioning with state space model,
C. Liu, K. Chen, B. Chen, H. Zhang, Z. Zou, and Z. Shi, “Rscama: Remote sensing image change captioning with state space model,”IEEE Geoscience and Remote Sensing Letters, vol. 21, pp. 1–5, 2024
2024
-
[37]
A lightweight sparse focus transformer for remote sensing image change captioning,
D. Sun, Y . Bao, J. Liu, and X. Cao, “A lightweight sparse focus transformer for remote sensing image change captioning,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024
2024
-
[38]
Rmnet: Dual-dimensional differ- ence recalibration-guided cnn-vmamba synergistic network for remote sensing image change captioning,
X. Cao, W. Dong, J. Qu, and Y . Li, “Rmnet: Dual-dimensional differ- ence recalibration-guided cnn-vmamba synergistic network for remote sensing image change captioning,”IEEE Transactions on Geoscience and Remote Sensing, 2026
2026
-
[39]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Geet al., “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Context-aware difference distilling for multi-change captioning,
Y . Tu, L. Li, L. Su, Z.-J. Zha, C. Yan, and Q. Huang, “Context-aware difference distilling for multi-change captioning,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 7941–7956
2024
-
[42]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
2002
-
[43]
Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,
S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,” inProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72
2005
-
[44]
Rouge: A package for automatic evaluation of sum- maries,
L. Chin-Yew, “Rouge: A package for automatic evaluation of sum- maries,” inProceedings of the Workshop on Text Summarization Branches Out, 2004, 2004
2004
-
[45]
Cider: Consensus- based image description evaluation,
R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider: Consensus- based image description evaluation,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2015, pp. 4566–4575
2015
-
[46]
Spice: Semantic propositional image caption evaluation,
P. Anderson, B. Fernando, M. Johnson, and S. Gould, “Spice: Semantic propositional image caption evaluation,” inEuropean conference on computer vision. Springer, 2016, pp. 382–398
2016
-
[47]
The measurement of observer agreement for categorical data,
J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data,”biometrics, pp. 159–174, 1977
1977
-
[48]
Region-aware difference distilling with attribute-guided contrastive regularization for change captioning,
R. Li, L. Li, J. Zhang, Q. Zhao, H. Wang, and C. Yan, “Region-aware difference distilling with attribute-guided contrastive regularization for change captioning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 5, 2025, pp. 4887–4895
2025
-
[49]
Change-agent: Towards interactive comprehensive remote sensing change interpretation and analysis,
C. Liu, K. Chen, H. Zhang, Z. Qi, Z. Zou, and Z. Shi, “Change-agent: Towards interactive comprehensive remote sensing change interpretation and analysis,”IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[50]
Changechat: An interactive model for remote sensing change analysis via multimodal instruction tuning,
P. Deng, W. Zhou, and H. Wu, “Changechat: An interactive model for remote sensing change analysis via multimodal instruction tuning,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[51]
Teochat: A large vision-language assistant for temporal earth observation data,
J. A. Irvin, E. R. Liu, J. C. Chen, I. Dormoy, J. Kim, S. Khanna, Z. Zheng, and S. Ermon, “Teochat: A large vision-language assistant for temporal earth observation data,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[52]
Dependent- test-aware regression testing techniques,
W. Lam, A. Shi, R. Oei, S. Zhang, M. D. Ernst, and T. Xie, “Dependent- test-aware regression testing techniques,” inProceedings of the 29th ACM SIGSOFT international symposium on software testing and anal- ysis, 2020, pp. 298–311
2020
-
[53]
Captioning changes in bi-temporal remote sensing images,
S. Chouaf, G. Hoxha, Y . Smara, and F. Melgani, “Captioning changes in bi-temporal remote sensing images,” in2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS. IEEE, 2021, pp. 2891–2894
2021
-
[54]
Scene graph and dependency gram- mar enhanced remote sensing change caption network (sgd-rsccn),
Q. Sun, Y . Wang, and X. Song, “Scene graph and dependency gram- mar enhanced remote sensing change caption network (sgd-rsccn),” in Proceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 2121–2130
2025
-
[55]
Cd4c: Change detection for remote sensing image change captioning,
X. Li, B. Sun, Z. Wu, S. Li, and H. Guo, “Cd4c: Change detection for remote sensing image change captioning,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025
2025
-
[56]
Frequency–spatial–temporal domain fusion network for remote sensing image change captioning,
S. Zou, Y . Wei, Y . Xie, and X. Luan, “Frequency–spatial–temporal domain fusion network for remote sensing image change captioning,” Remote Sensing, vol. 17, no. 8, p. 1463, 2025
2025
-
[57]
Change captioning for satellite images time series,
W. Peng, P. Jian, Z. Mao, and Y . Zhao, “Change captioning for satellite images time series,”IEEE Geoscience and Remote Sensing Letters, vol. 21, pp. 1–5, 2024
2024
-
[58]
Restricted supervised cascade information network for remote sensing change captioning with serial sentences,
K. Yang, J. Wei, C. Chen, Z. Wang, J. Lan, X. Li, D. Hua, D. Xue, and Y . Wu, “Restricted supervised cascade information network for remote sensing change captioning with serial sentences,”International Journal of Applied Earth Observation and Geoinformation, vol. 142, p. 104686, 2025
2025
-
[59]
Remote sensing image change captioning using multi-attentive network with diffusion model,
Y . Yang, T. Liu, Y . Pu, L. Liu, Q. Zhao, and Q. Wan, “Remote sensing image change captioning using multi-attentive network with diffusion model,”Remote Sensing, vol. 16, no. 21, p. 4083, 2024
2024
-
[60]
Diffusion-rscc: Diffusion probabilistic model for change captioning in remote sensing images,
X. Yu, Y . Li, J. Ma, C. Li, and H. Wu, “Diffusion-rscc: Diffusion probabilistic model for change captioning in remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[61]
Mask approximation net: A novel diffusion model approach for remote sens- ing change captioning,
D. Sun, J. Yao, W. Xue, C. Zhou, P. Ghamisi, and X. Cao, “Mask approximation net: A novel diffusion model approach for remote sens- ing change captioning,”IEEE transactions on geoscience and remote sensing, 2025
2025
-
[62]
Cross-temporal remote sensing image change captioning: A manifold mapping and bayesian diffusion approach for land use monitoring,
Q. Bai and X. Wang, “Cross-temporal remote sensing image change captioning: A manifold mapping and bayesian diffusion approach for land use monitoring,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025
2025
-
[63]
A cross-spatial differential localization network for remote sensing change captioning,
R. Wu, H. Ye, X. Liu, Z. Li, C. Sun, and J. Wu, “A cross-spatial differential localization network for remote sensing change captioning,” Remote Sensing, vol. 17, no. 13, p. 2285, 2025
2025
-
[64]
A multi-task network and two large scale datasets for change detection and captioning in remote sensing images,
J. Shi, M. Zhang, Y . Hou, R. Zhi, and J. Liu, “A multi-task network and two large scale datasets for change detection and captioning in remote sensing images,”IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[65]
Multi-scale attentive fusion network for remote sensing image change captioning,
C. Chen, Y . Wang, and K.-H. Yap, “Multi-scale attentive fusion network for remote sensing image change captioning,” in2024 IEEE Interna- tional Symposium on Circuits and Systems (ISCAS). IEEE, 2024, pp. 1–5
2024
-
[66]
Robust change captioning in remote sensing: Second-cc dataset and mmodalcc framework,
A. C. Karaca, E. Ozelbas, S. Berber, O. Karimli, T. Yildirim, and M. F. Amasyali, “Robust change captioning in remote sensing: Second-cc dataset and mmodalcc framework,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025
2025
-
[67]
Text-augmented semantic feature extraction and difference information learning for remote sensing image change captioning,
R. Hang, J. Luo, H. Lin, and Q. Liu, “Text-augmented semantic feature extraction and difference information learning for remote sensing image change captioning,”IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[68]
Cross-layer attention enhanced remote sensing image change captioning via mamba-transformer inter- action,
C. Ma, X. Lv, Q. Xie, and Z. Luo, “Cross-layer attention enhanced remote sensing image change captioning via mamba-transformer inter- action,” in2025 6th International Conference on Geology, Mapping and Remote Sensing (ICGMRS). IEEE, 2025, pp. 245–248
2025
-
[69]
Ihm-snet: An interactive hierarchical mamba-based screening network for remote sensing image change cap- tioning,
C. Ma, X. Lv, and H. Zhang, “Ihm-snet: An interactive hierarchical mamba-based screening network for remote sensing image change cap- tioning,” in2025 28th International Conference on Computer Supported Cooperative Work in Design (CSCWD). IEEE, 2025, pp. 2397–2403
2025
-
[70]
A decoupling paradigm with prompt learning for remote sensing image change cap- tioning,
C. Liu, R. Zhao, J. Chen, Z. Qi, Z. Zou, and Z. Shi, “A decoupling paradigm with prompt learning for remote sensing image change cap- tioning,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–18, 2023
2023
-
[71]
Rs- llava: A large vision-language model for joint captioning and question answering in remote sensing imagery,
Y . Bazi, L. Bashmal, M. M. Al Rahhal, R. Ricci, and F. Melgani, “Rs- llava: A large vision-language model for joint captioning and question answering in remote sensing imagery,”Remote Sensing, vol. 16, no. 9, p. 1477, 2024
2024
-
[72]
Enhancing perception of key changes in remote sensing image change captioning,
C. Yang, Z. Li, H. Jiao, Z. Gao, and L. Zhang, “Enhancing perception of key changes in remote sensing image change captioning,”IEEE Transactions on Image Processing, 2025
2025
-
[73]
Semantic- cc: Boosting remote sensing image change captioning via foundational knowledge and semantic guidance,
Y . Zhu, L. Li, K. Chen, C. Liu, F. Zhou, and Z. Shi, “Semantic- cc: Boosting remote sensing image change captioning via foundational knowledge and semantic guidance,”IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[74]
Describing and localizing multiple changes with trans- formers,
Y . Qiu, S. Yamamoto, K. Nakashima, R. Suzuki, K. Iwata, H. Kataoka, and Y . Satoh, “Describing and localizing multiple changes with trans- formers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1971–1980
2021
-
[75]
Onediff: A generalist model for image difference captioning,
E. Hu, L. Guo, T. Yue, Z. Zhao, S. Xue, and J. Liu, “Onediff: A generalist model for image difference captioning,” inProceedings of the Asian Conference on Computer Vision, 2024, pp. 2439–2455
2024
-
[76]
Reframing image difference captioning with blip2idc and synthetic augmentation,
G. Evennou, A. Chaffin, V . Chappelier, and E. Kijak, “Reframing image difference captioning with blip2idc and synthetic augmentation,” in 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2025, pp. 1392–1402
2025
-
[77]
Describing differences in image sets with natural language,
L. Dunlap, Y . Zhang, X. Wang, R. Zhong, T. Darrell, J. Steinhardt, J. E. Gonzalez, and S. Yeung-Levy, “Describing differences in image sets with natural language,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 24 199–24 208
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.