On the Limits of Steering Vectors for Preference-Aligned Generation
Pith reviewed 2026-07-03 15:16 UTC · model grok-4.3
The pith
Steering vectors vary substantially in effectiveness across traits, degrade on task transfer, and lose expressibility when multiple vectors are composed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
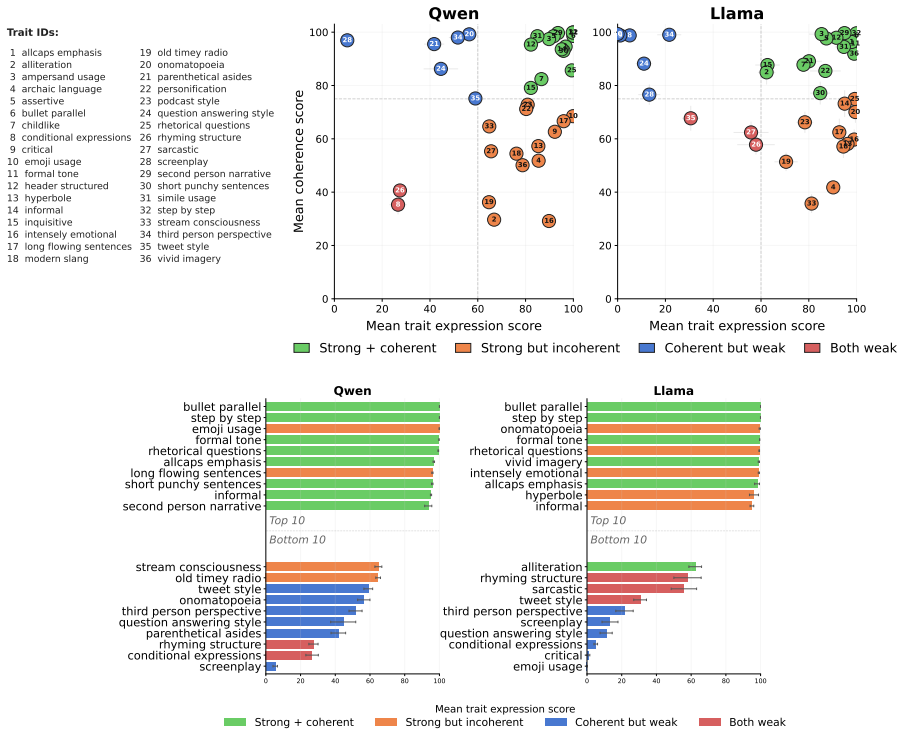
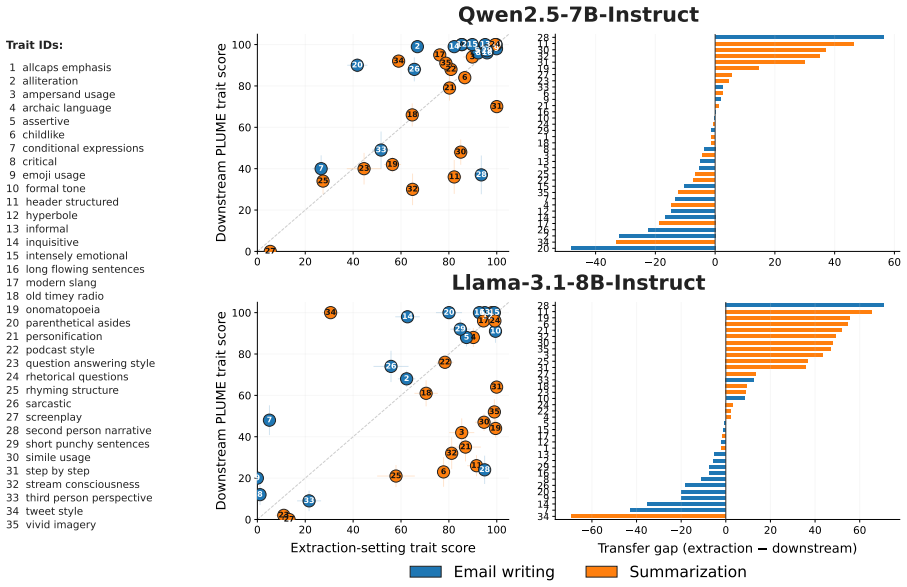
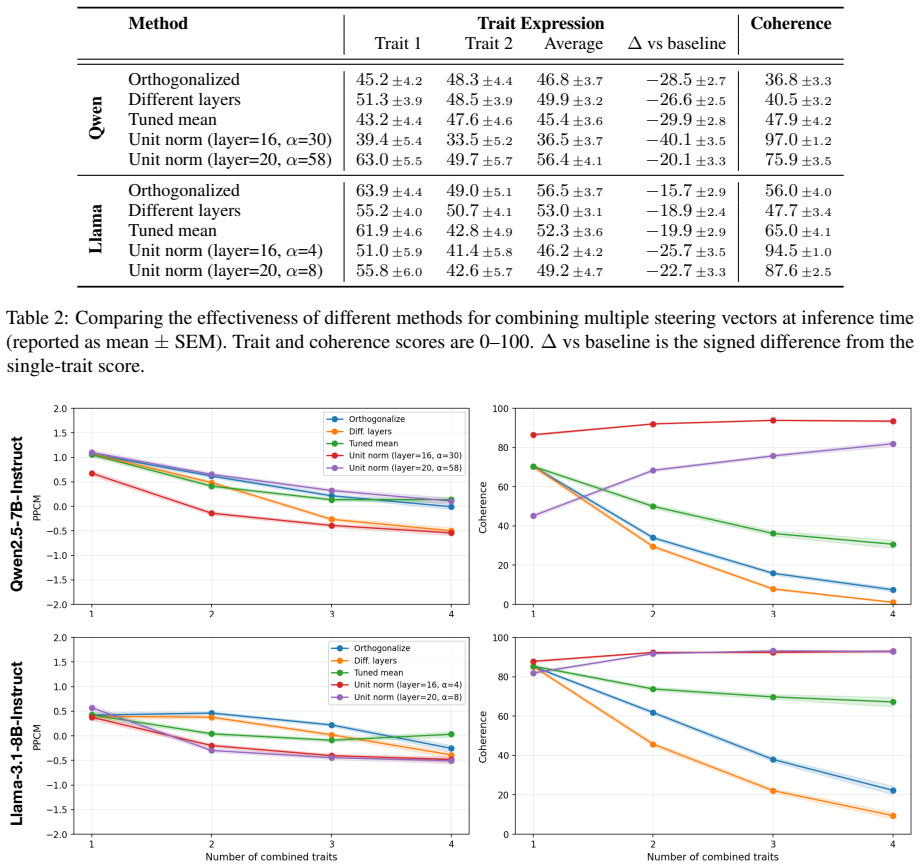
The central claim is that steering vectors face meaningful limits as a general-purpose tool for preference alignment. This is shown by substantial variation in how well vectors express different traits, by degraded performance when vectors extracted from positive and negative examples are applied to downstream writing tasks, and by consistent declines in trait expression across composition methods as the number of vectors increases, accompanied by a coherence-expressibility tradeoff that requires per-setting hyperparameter tuning.
What carries the argument
Steering vectors extracted from positive and negative style examples to guide model outputs toward specific traits.
If this is right
- Steering effectiveness varies substantially across traits.
- Effectiveness can degrade when vectors extracted from style examples are transferred to downstream writing tasks.
- All tested methods for composing multiple steering vectors suffer significant drops in trait expression as more vectors are added.
- A tradeoff between coherence and expressibility requires per-setting hyperparameter tuning.
Where Pith is reading between the lines
- Preference alignment techniques may need to combine steering vectors with other methods to handle varied traits reliably.
- Real-world applications involving diverse or changing user preferences could encounter even sharper performance drops than those observed here.
- Task-specific extraction or adaptation steps might mitigate some transfer degradation.
- The observed composition limits suggest that scaling to many simultaneous preferences will require new vector arithmetic or selection strategies.
Load-bearing premise
The PLUME benchmark, the two chosen models, and the specific summarization and email-writing tasks are representative enough to support conclusions about the general limits of steering vectors.
What would settle it
An experiment that finds high and consistent trait expression, successful transfer to new tasks, and stable multi-vector composition without per-setting tuning across a wider range of models and benchmarks would falsify the claim of meaningful limits.
Figures


read the original abstract
Steering vectors have emerged as a promising approach to controlled text generation, offering interpretable, training-free mechanisms for shaping model outputs. However, their practical generality remains poorly understood. We study the limits of steering vector generalization along three dimensions: trait expressibility, task transfer, and multi-trait composition. Using the PLUME writing personalization benchmark, we extract steering vectors for a range of preferences and evaluate them on summarization and email-writing tasks across two open-source models (Qwen2.5-7B-Instruct and Llama3.1-8B-Instruct). We find that steering effectiveness varies substantially across traits. We further show that steering effectiveness can degrade when vectors extracted from positive and negative style examples are transferred to downstream writing personalization tasks. Finally, we compare common methods for composing multiple steering vectors and find that all methods suffer significant drops in trait expression as more vectors are added, with a tradeoff between coherence and expressibility that requires per-setting hyperparameter tuning. Taken together, our results suggest that steering vectors face meaningful limits as a general-purpose tool for preference alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that steering vectors have meaningful limits as a general-purpose tool for preference alignment. Using the PLUME benchmark, it extracts vectors for various preferences and evaluates them on summarization and email-writing tasks with Qwen2.5-7B-Instruct and Llama3.1-8B-Instruct. Key findings include substantial variation in trait expressibility, degradation when transferring vectors from positive/negative examples to downstream tasks, and significant drops in trait expression (with coherence-expressibility tradeoffs) when composing multiple vectors via common methods.
Significance. If the empirical patterns hold beyond the tested setup, the work would usefully document practical constraints on steering vectors, including the need for per-setting hyperparameter tuning in composition and the risks of transfer degradation. This could inform more robust methods for controlled generation and preference alignment.
major comments (1)
- [Abstract (and implied experimental sections)] The central claim that steering vectors 'face meaningful limits as a general-purpose tool' rests on experiments limited to two 7-8B models and two PLUME tasks (summarization, email-writing). No results are reported for larger models, other architectures, or domains such as dialogue or code generation, leaving open whether the observed variation, transfer degradation, and composition drops are artifacts of scale, training data, or task type rather than general limits.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the number of traits tested and the specific composition methods compared (e.g., addition, concatenation) to allow readers to assess the scope of the composition results.
Simulated Author's Rebuttal
We thank the referee for highlighting the scope of our experimental evaluation. We address this point directly below.
read point-by-point responses
-
Referee: [Abstract (and implied experimental sections)] The central claim that steering vectors 'face meaningful limits as a general-purpose tool' rests on experiments limited to two 7-8B models and two PLUME tasks (summarization, email-writing). No results are reported for larger models, other architectures, or domains such as dialogue or code generation, leaving open whether the observed variation, transfer degradation, and composition drops are artifacts of scale, training data, or task type rather than general limits.
Authors: We agree that our evaluation is restricted to Qwen2.5-7B-Instruct and Llama3.1-8B-Instruct on summarization and email-writing tasks from PLUME. The patterns we report (trait variation, transfer degradation, and composition trade-offs) are nevertheless consistent across these two distinct model families. This cross-model replication provides some evidence that the observed limits are not idiosyncratic to a single training run or architecture. We do not claim universality across all scales or domains; the paper positions the results as documenting practical constraints within a controlled writing-personalization benchmark. Expanding to larger models, additional architectures, and domains such as dialogue or code generation would be valuable but constitutes a substantial separate study. We will add an explicit limitations paragraph in the revised manuscript clarifying the evaluated scope and noting that generalization beyond these settings remains an open question. revision: partial
Circularity Check
No significant circularity; empirical evaluation only
full rationale
The paper is a purely empirical study that extracts steering vectors from PLUME data, applies them to summarization and email-writing tasks on two 7-8B models, and reports observational results on expressibility, transfer, and composition. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. Results are presented as experimental findings rather than reductions to inputs by construction, so the work is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Personal
Thomas P Zollo and Andrew Wei Tung Siah and Naimeng Ye and Ang Li and Hongseok Namkoong , booktitle=. Personal. 2025 , url=
2025
-
[3]
Do Anything Now
"Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models , author=. 2024 , eprint=
2024
-
[4]
2024 , eprint=
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models , author=. 2024 , eprint=
2024
-
[5]
2025 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
Improving Instruction-Following in Language Models through Activation Steering , author=. 2025 , eprint=
2025
-
[7]
2025 , eprint=
Aligning Large Language Models with Implicit Preferences from User-Generated Content , author=. 2025 , eprint=
2025
-
[8]
2025 , url=
Xinyu Ma and Yifeng Xu and Yang Lin and Tianlong Wang and Xu Chu and Xin Gao and Junfeng Zhao and Yasha Wang , booktitle=. 2025 , url=
2025
-
[9]
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[10]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[11]
Extracting Latent Steering Vectors from Pretrained Language Models
Subramani, Nishant and Suresh, Nivedita and Peters, Matthew. Extracting Latent Steering Vectors from Pretrained Language Models. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.48
-
[12]
Aligning
St. Aligning. Forty-second International Conference on Machine Learning , year=
-
[13]
Style Vectors for Steering Generative Large Language Models
Konen, Kai and Jentzsch, Sophie and Diallo, Diaoul. Style Vectors for Steering Generative Large Language Models. Findings of the Association for Computational Linguistics: EACL 2024. 2024
2024
-
[14]
2024 , eprint=
Art or Artifice? Large Language Models and the False Promise of Creativity , author=. 2024 , eprint=
2024
-
[15]
2025 , eprint=
Frontier Models are Capable of In-context Scheming , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
We're Different, We're the Same: Creative Homogeneity Across LLMs , author=. 2025 , eprint=
2025
-
[17]
2025 , eprint=
Shifting Perspectives: Steering Vectors for Robust Bias Mitigation in LLMs , author=. 2025 , eprint=
2025
-
[18]
2025 , eprint=
Controlling Large Language Models Through Concept Activation Vectors , author=. 2025 , eprint=
2025
-
[19]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[20]
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Tan, Zhaoxuan and Li, Zheng and Liu, Tianyi and Wang, Haodong and Yun, Hyokun and Zeng, Ming and Chen, Pei and Zhang, Zhihan and Gao, Yifan and Wang, Ruijie and Nigam, Priyanka and Yin, Bing and Jiang, Meng. Aligning Large Language Models with Implicit Preferences from User-Generated Content. Proceedings of the 63rd Annual Meeting of the Association for C...
-
[21]
The Thirteenth International Conference on Learning Representations , year=
Improving Instruction-Following in Language Models through Activation Steering , author=. The Thirteenth International Conference on Learning Representations , year=
-
[22]
The Thirteenth International Conference on Learning Representations , year=
Aligning Language Models with Demonstrated Feedback , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
L a MP : When Large Language Models Meet Personalization
Salemi, Alireza and Mysore, Sheshera and Bendersky, Michael and Zamani, Hamed. L a MP : When Large Language Models Meet Personalization. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.399
-
[24]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[25]
Xiaogeng Liu and Nan Xu and Muhao Chen and Chaowei Xiao , booktitle=. Auto. 2024 , url=
2024
-
[26]
First Conference on Language Modeling , year=
Measuring and Controlling Instruction (In)Stability in Language Model Dialogs , author=. First Conference on Language Modeling , year=
-
[27]
2024 , eprint=
Model Editing with Canonical Examples , author=. 2024 , eprint=
2024
-
[28]
2024 , eprint=
Aligning LLM Agents by Learning Latent Preference from User Edits , author=. 2024 , eprint=
2024
-
[29]
Aligning
Ge Gao and Alexey Taymanov and Eduardo Salinas and Paul Mineiro and Dipendra Misra , booktitle=. Aligning. 2024 , url=
2024
-
[30]
2020 , eprint=
Language Models are Few-Shot Learners , author=. 2020 , eprint=
2020
-
[31]
Zamfirescu-Pereira, J.D. and Wong, Richmond Y. and Hartmann, Bjoern and Yang, Qian , title =. Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems , articleno =. 2023 , isbn =. doi:10.1145/3544548.3581388 , abstract =
-
[32]
2025 , eprint=
Aligning Language Models with Demonstrated Feedback , author=. 2025 , eprint=
2025
-
[33]
2022 , eprint=
Emergent Abilities of Large Language Models , author=. 2022 , eprint=
2022
-
[34]
2025 , eprint=
KCIF: Knowledge-Conditioned Instruction Following , author=. 2025 , eprint=
2025
-
[35]
2024 , eprint=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. 2024 , eprint=
2024
-
[36]
2024 , eprint=
LaMP: When Large Language Models Meet Personalization , author=. 2024 , eprint=
2024
-
[37]
2024 , eprint=
Measuring and Controlling Instruction (In)Stability in Language Model Dialogs , author=. 2024 , eprint=
2024
-
[38]
2025 , eprint=
Examining Identity Drift in Conversations of LLM Agents , author=. 2025 , eprint=
2025
-
[39]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[40]
2024 , eprint=
In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering , author=. 2024 , eprint=
2024
-
[41]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[42]
International Conference on Learning Representations , year=
Finetuned Language Models are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[43]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[44]
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Amy Yang and Angela Fan and Anirudh Goyal and Anthony Hartshorn and Aobo Yang and Archi Mitra and Archie Sravankumar and Artem Korenev and Arthur Hinsvark and Arun Rao and Aston Zhang and Aurélien Rodriguez ...
2024
-
[45]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler and Nisan Stiennon and Jeffrey Wu and Tom B. Brown and Alec Radford and Dario Amodei and Paul F. Christiano and Geoffrey Irving , title =. CoRR , volume =. 2019 , url =. 1909.08593 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[46]
One-shot Optimized Steering Vectors Mediate Safety-relevant Behaviors in
Jacob Dunefsky and Arman Cohan , booktitle=. One-shot Optimized Steering Vectors Mediate Safety-relevant Behaviors in. 2025 , url=
2025
-
[47]
2025 , eprint=
Whose story is it? Personalizing story generation by inferring author styles , author=. 2025 , eprint=
2025
-
[48]
Neurips Safe Generative AI Workshop 2024 , year=
Towards Inference-time Category-wise Safety Steering for Large Language Models , author=. Neurips Safe Generative AI Workshop 2024 , year=
2024
-
[49]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[50]
Unsupervised Human Preference Learning , url=
Shashidhar, Sumuk and Chinta, Abhinav and Sahai, Vaibhav and Tur, Dilek Hakkani , year=. Unsupervised Human Preference Learning , url=. doi:10.18653/v1/2024.emnlp-main.200 , booktitle=
-
[51]
2025 , eprint=
Do LLMs Recognize Your Preferences? Evaluating Personalized Preference Following in LLMs , author=. 2025 , eprint=
2025
-
[52]
2025 , eprint=
A Survey on Personalized and Pluralistic Preference Alignment in Large Language Models , author=. 2025 , eprint=
2025
-
[53]
2023 , eprint=
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
2023
-
[54]
2023 , eprint=
Eliciting Human Preferences with Language Models , author=. 2023 , eprint=
2023
-
[55]
What Should We Engineer in Prompts? Training Humans in Requirement-Driven LLM Use , volume=
Ma, Qianou and Peng, Weirui and Yang, Chenyang and Shen, Hua and Koedinger, Ken and Wu, Tongshuang , year=. What Should We Engineer in Prompts? Training Humans in Requirement-Driven LLM Use , volume=. ACM Transactions on Computer-Human Interaction , publisher=. doi:10.1145/3731756 , number=
-
[56]
2024 , eprint=
TinyStyler: Efficient Few-Shot Text Style Transfer with Authorship Embeddings , author=. 2024 , eprint=
2024
-
[57]
2025 , eprint=
Persona Vectors: Monitoring and Controlling Character Traits in Language Models , author=. 2025 , eprint=
2025
-
[58]
Training large language models on narrow tasks can lead to broad misalignment , volume=
Betley, Jan and Warncke, Niels and Sztyber-Betley, Anna and Tan, Daniel and Bao, Xuchan and Soto, Martín and Srivastava, Megha and Labenz, Nathan and Evans, Owain , year=. Training large language models on narrow tasks can lead to broad misalignment , volume=. Nature , publisher=. doi:10.1038/s41586-025-09937-5 , number=
-
[59]
2024 , eprint=
Low-Resource Authorship Style Transfer: Can Non-Famous Authors Be Imitated? , author=. 2024 , eprint=
2024
-
[60]
2025 , eprint=
Rethinking Theory of Mind Benchmarks for LLMs: Towards A User-Centered Perspective , author=. 2025 , eprint=
2025
-
[61]
Lost in the Middle: How Language Models Use Long Contexts
Subbiah, Melanie and Zhang, Sean and Chilton, Lydia B. and McKeown, Kathleen. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl\_a\_00702
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[62]
Behavioral and Brain Sciences , author=
Does the chimpanzee have a theory of mind? , volume=. Behavioral and Brain Sciences , author=. 1978 , pages=. doi:10.1017/S0140525X00076512 , number=
-
[63]
Rashkin, Hannah and Sap, Maarten and Allaway, Emily and Smith, Noah A. and Choi, Yejin. E vent2 M ind: Commonsense Inference on Events, Intents, and Reactions. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1043
-
[64]
2024 , eprint=
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
2024
-
[65]
Is the Top Still Spinning? Evaluating Subjectivity in Narrative Understanding
Subbiah, Melanie and Mishra, Akankshya and Kim, Grace and Tang, Liyan and Durrett, Greg and McKeown, Kathleen. Is the Top Still Spinning? Evaluating Subjectivity in Narrative Understanding. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.10
-
[66]
Probing Classifiers: Promises, Shortcomings, and Advances
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics. 2022. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[67]
2025 , eprint=
Literary Evidence Retrieval via Long-Context Language Models , author=. 2025 , eprint=
2025
-
[68]
Feuding Families and Former F riends: Unsupervised Learning for Dynamic Fictional Relationships
Iyyer, Mohit and Guha, Anupam and Chaturvedi, Snigdha and Boyd-Graber, Jordan and Daum \'e III, Hal. Feuding Families and Former F riends: Unsupervised Learning for Dynamic Fictional Relationships. Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016. doi:10.1...
-
[69]
2019 , eprint=
ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning , author=. 2019 , eprint=
2019
-
[70]
Evaluating Theory of Mind in Question Answering
Nematzadeh, Aida and Burns, Kaylee and Grant, Erin and Gopnik, Alison and Griffiths, Tom. Evaluating Theory of Mind in Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1261
-
[71]
Revisiting the Evaluation of Theory of Mind through Question Answering
Le, Matthew and Boureau, Y-Lan and Nickel, Maximilian. Revisiting the Evaluation of Theory of Mind through Question Answering. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1598
-
[72]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
STORYSUMM: Evaluating Faithfulness in Story Summarization , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
2024
-
[73]
Wimmer, Heinz and Perner, Josef , title =. Cognition , year =. doi:10.1016/0010-0277(83)90004-5 , pmid =
-
[74]
2023 , eprint=
Understanding Social Reasoning in Language Models with Language Models , author=. 2023 , eprint=
2023
-
[75]
2023 , eprint=
FANToM: A Benchmark for Stress-testing Machine Theory of Mind in Interactions , author=. 2023 , eprint=
2023
-
[76]
2026 , eprint =
Emotion Concepts and their Function in a Large Language Model , author =. 2026 , eprint =
2026
-
[77]
Publications Manual , year = "1983", publisher =
1983
-
[78]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[79]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[80]
Dan Gusfield , title =. 1997
1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.