SkillFuzz: Fuzzing Skill Composition for Implicit Intents Discovery in Open Skill Marketplaces
Pith reviewed 2026-07-03 08:35 UTC · model grok-4.3
The pith
Fuzzing skill compositions reveals over a thousand implicit intents that single-skill audits miss in LLM agent marketplaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
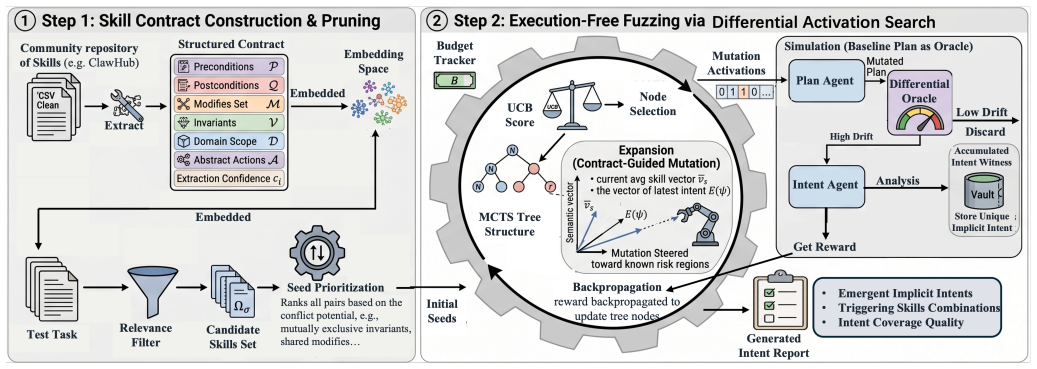
Implicit-intent discovery is formulated as a fuzzing problem over skill compositions, where planning artifacts expose agent intent before execution and deviations from a skill-free baseline serve as a differential oracle. SkillFuzz is proposed as the first execution-free testing approach that extracts structured skill contracts and uses contract-guided Monte Carlo Tree Search to prioritize potentially conflicting compositions.
What carries the argument
Contract-guided Monte Carlo Tree Search over extracted skill contracts, which prioritizes compositions likely to produce conflicting intents.
If this is right
- Marketplace operators can audit skill compositions at admission time without access to execution environments.
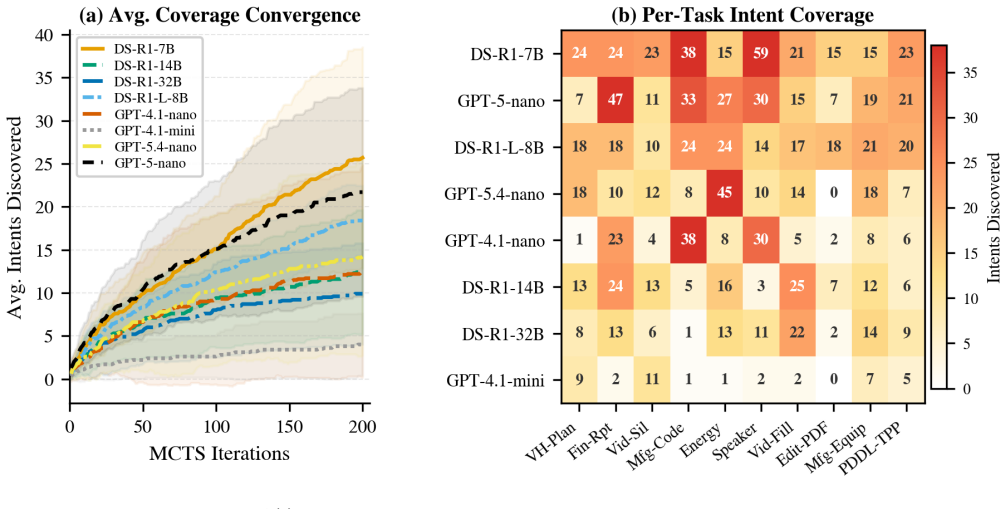
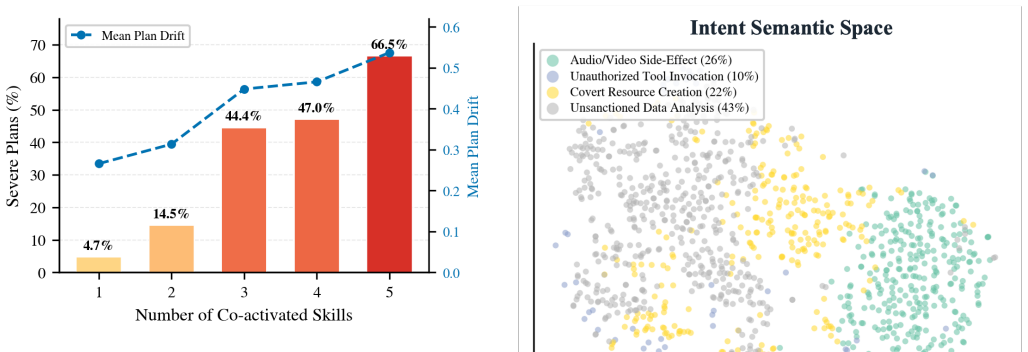
- Over 1000 distinct implicit intents can be discovered under a fixed query budget across representative workloads.
- More than 80% of the highest-risk flagged compositions are confirmed during later execution-time validation.
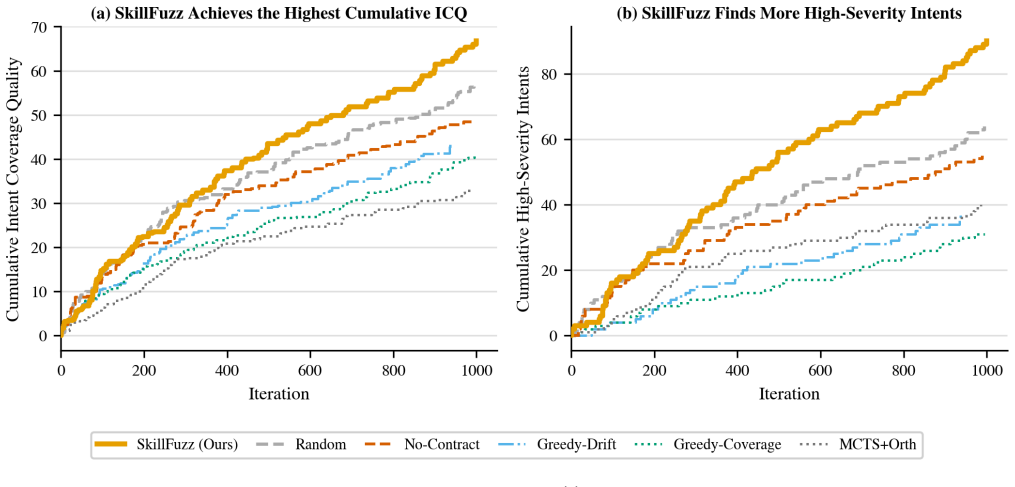
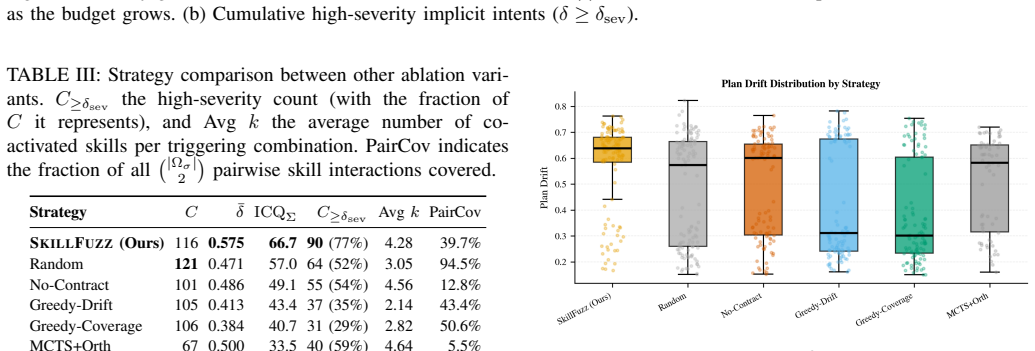
- Substantially more high-severity implicit intents are identified while exploring only a fraction of the pairwise interaction space required by alternatives.
Where Pith is reading between the lines
- Similar fuzzing techniques could apply to detecting unintended behaviors in other multi-component AI systems beyond skill marketplaces.
- Developers might use the same contract extraction to improve skill design and reduce conflicts proactively.
- The differential oracle based on planning artifacts might extend to other intent-revealing artifacts in agent planning.
Load-bearing premise
Planning artifacts produced before execution reliably expose the agent's intent and deviations from a skill-free baseline constitute a sound differential oracle for implicit intents.
What would settle it
Running execution-time validation on the flagged compositions and finding that fewer than half actually produce the implied implicit intents would undermine the discovery claims.
Figures

read the original abstract
Large Language Model (LLM)-based agents increasingly automate software engineering tasks through reusable skills, natural-language instruction documents that guide planning and execution. Open skill marketplaces enable users to assemble agents by co-activating community-contributed skills, but marketplace operators typically audit skills in isolation. As a result, individually benign skills may interact to redirect an agent toward unintended objectives, which we term implicit intents. Detecting such intents is challenging because the effect emerges only through skill composition, execution environments are often unavailable at admission time, and the space of possible co-activations grows exponentially with marketplace size. In this paper, we formulate implicit-intent discovery as a fuzzing problem over skill compositions, where skill compositions are the unit under test, planning artifacts expose agent intent before execution, and deviations from a skill-free baseline serve as a differential oracle. Based on this formulation, we propose skillfuzz, the first execution-free testing approach that extracts structured skill contracts and uses contract-guided Monte Carlo Tree Search to prioritize potentially conflicting compositions. Across representative skill-marketplace workloads, skillfuzz discovers over 1,000 distinct implicit intents under a fixed query budget, confirms more than 80% of the highest-risk flagged compositions during execution-time validation, and identifies substantially more high-severity implicit intents than alternative search strategies while exploring only a fraction of the pairwise interaction space they require.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates implicit-intent discovery in LLM agent skill marketplaces as a fuzzing problem over skill compositions. It proposes SkillFuzz, an execution-free approach that extracts structured skill contracts and applies contract-guided Monte Carlo Tree Search to prioritize conflicting compositions. Evaluation on representative workloads reports discovery of over 1,000 distinct implicit intents under a fixed query budget, >80% confirmation of highest-risk compositions via execution-time validation, and superior identification of high-severity intents compared to alternatives while exploring a smaller fraction of the interaction space.
Significance. If the planning-artifact differential oracle is shown to be a valid proxy, the work would provide a practical, scalable method for marketplace operators to audit skill compositions for unintended objectives prior to admission. The scale of reported discoveries and the comparative efficiency results indicate potential utility for LLM agent security in software engineering contexts.
major comments (1)
- [Abstract (formulation paragraph)] Abstract (formulation paragraph): The central claim rests on the assumptions that (1) planning artifacts reliably expose agent intent and (2) deviations from a skill-free baseline form a sound differential oracle for implicit intents. The manuscript supplies no independent evidence or ablation that this subtraction isolates unintended objectives rather than planner artifacts, skill-description noise, or normal variation. This assumption is load-bearing for the interpretation of the >1,000 discovered intents and the 80% confirmation statistic (which applies only to the already-filtered highest-risk subset).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the foundational assumptions of our approach. We address the major comment below and commit to revisions that strengthen the manuscript's claims regarding the differential oracle.
read point-by-point responses
-
Referee: The central claim rests on the assumptions that (1) planning artifacts reliably expose agent intent and (2) deviations from a skill-free baseline form a sound differential oracle for implicit intents. The manuscript supplies no independent evidence or ablation that this subtraction isolates unintended objectives rather than planner artifacts, skill-description noise, or normal variation. This assumption is load-bearing for the interpretation of the >1,000 discovered intents and the 80% confirmation statistic (which applies only to the already-filtered highest-risk subset).
Authors: We acknowledge that the current manuscript does not include an explicit ablation or independent validation isolating the differential oracle from potential confounds such as planner artifacts or description noise. The execution-time validation (>80% confirmation on the highest-risk subset) provides empirical support that the oracle surfaces compositions with observable unintended effects, but we agree this is indirect. In revision we will add: (1) expanded justification in Section 3 for why planning artifacts serve as a reliable intent proxy (they capture the agent's pre-execution reasoning trace, which is the direct output of the planner), and (2) a new ablation subsection comparing differential vs. non-differential scoring, plus a noise-injection experiment on skill descriptions. These additions will clarify the oracle's contribution while preserving the reported discovery counts and efficiency results. revision: yes
Circularity Check
No circularity; empirical method with independent experimental claims
full rationale
The paper presents SkillFuzz as an execution-free fuzzing technique that extracts skill contracts and applies contract-guided Monte Carlo Tree Search. Its central claims consist of empirical counts (over 1,000 intents discovered, >80% confirmation on a filtered subset, comparison to alternatives) obtained from representative workloads under a fixed query budget. No equations, fitted parameters, or derivation steps are described that reduce by construction to the method's own inputs or definitions. The formulation paragraph defines the differential oracle explicitly as part of the approach rather than deriving a result from it. No self-citations appear in the provided text as load-bearing premises. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
invented entities (2)
-
implicit intents
no independent evidence
-
skill contracts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Van Vliet, H
H. Van Vliet, H. Van Vliet, and J. Van Vliet,Software engineering: principles and practice. John Wiley & Sons Hoboken, NJ, 2008, vol. 13
2008
-
[2]
Methods and techniques of agentic software engineering: A systematic literature review,
N. Otoum and N. Elkhalili, “Methods and techniques of agentic software engineering: A systematic literature review,”IEEE Access, vol. 14, pp. 7443–7465, 2026
2026
-
[3]
Describe, explain, plan and select: interactive planning with llms enables open- world multi-task agents,
Z. Wang, S. Cai, G. Chen, A. Liu, X. S. Ma, and Y . Liang, “Describe, explain, plan and select: interactive planning with llms enables open- world multi-task agents,”Advances in Neural Information Processing Systems, vol. 36, pp. 34 153–34 189, 2023
2023
-
[4]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Y . Jiang, D. Li, H. Deng, B. Ma, X. Wang, Q. Wang, and G. Yu, “Sok: Agentic skills–beyond tool use in llm agents,”arXiv preprint arXiv:2602.20867, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Tapas are free! training-free adaptation of programmatic agents via llm-guided program synthesis in dynamic environments,
J. Hu, Y . Dong, Y . Sun, and X. Huang, “Tapas are free! training-free adaptation of programmatic agents via llm-guided program synthesis in dynamic environments,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 35, pp. 29 477–29 485, Mar
-
[6]
Available: https://ojs.aaai.org/index.php/AAAI/article/ view/40189
[Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/ view/40189
-
[7]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
X. Li, W. Chen, Y . Liu, S. Zheng, X. Chen, Y . He, Y . Li, B. You, H. Shen, J. Sunet al., “Skillsbench: Benchmarking how well agent skills work across diverse tasks,”arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
ClawHub: Skill registry and marketplace for OpenClaw agents,
Openclaw, “ClawHub: Skill registry and marketplace for OpenClaw agents,” https://clawhub.ai/, 2026
2026
-
[9]
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Y . Liu, W. Wang, R. Feng, Y . Zhang, G. Xu, G. Deng, Y . Li, and L. Zhang, “Agent skills in the wild: An empirical study of security vulnerabilities at scale,”arXiv preprint arXiv:2601.10338, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
2, 4, 8 Zihan Guo, Zhiyu Chen, Xiaohang Nie, Jianghao Lin, Yuanjian Zhou, and Weinan Zhang
Z. Guo, Z. Chen, X. Nie, J. Lin, Y . Zhou, and W. Zhang, “Skillprobe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration,”arXiv preprint arXiv:2603.21019, 2026
-
[11]
Software fault interactions and implications for software testing,
D. R. Kuhn, D. R. Wallace, and A. M. Gallo, “Software fault interactions and implications for software testing,”IEEE transactions on software engineering, vol. 30, no. 6, pp. 418–421, 2004
2004
-
[12]
Dynamic analysis for diagnosing integration faults,
L. Mariani, F. Pastore, and M. Pezze, “Dynamic analysis for diagnosing integration faults,”IEEE Transactions on Software Engineering, vol. 37, no. 4, pp. 486–508, 2011
2011
-
[13]
Common trends in software fault and failure data,
M. Hamill and K. Goseva-Popstojanova, “Common trends in software fault and failure data,”IEEE Transactions on Software Engineering, vol. 35, no. 4, pp. 484–496, 2009
2009
-
[14]
Agentic large language models, a survey,
A. Plaat, M. van Duijn, N. Van Stein, M. Preuss, P. van der Putten, and K. J. Batenburg, “Agentic large language models, a survey,”Journal of Artificial Intelligence Research, vol. 84, 2025
2025
-
[15]
Plan-and-act: Improving planning of agents for long-horizon tasks,
L. E. Erdogan, H. Furuta, S. Kim, N. Lee, S. Moon, G. Anumanchipalli, K. Keutzer, and A. Gholami, “Plan-and-act: Improving planning of agents for long-horizon tasks,” inForty-second International Conference on Machine Learning, 2025. [Online]. Available: https: //openreview.net/forum?id=ybA4EcMmUZ
2025
-
[16]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=WE_vluYUL-X
2023
-
[17]
Exe- cutable code actions elicit better llm agents,
X. Wang, Y . Chen, L. Yuan, Y . Zhang, Y . Li, H. Peng, and H. Ji, “Exe- cutable code actions elicit better llm agents,” inForty-first International Conference on Machine Learning, 2024
2024
-
[18]
Reason for future, act for now: A principled architecture for autonomous LLM agents,
Z. Liu, H. Hu, S. Zhang, H. Guo, S. Ke, B. Liu, and Z. Wang, “Reason for future, act for now: A principled architecture for autonomous LLM agents,” inForty-first International Conference on Machine Learning, 2024. [Online]. Available: https://openreview.net/forum?id= MGkeWJxQVl
2024
-
[19]
Plan-then-execute: An empirical study of user trust and team performance when using llm agents as a daily assistant,
G. He, G. Demartini, and U. Gadiraju, “Plan-then-execute: An empirical study of user trust and team performance when using llm agents as a daily assistant,” inProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025, pp. 1–22
2025
-
[20]
Plangenllms: A modern survey of llm planning capabilities,
H. Wei, Z. Zhang, S. He, T. Xia, S. Pan, and F. Liu, “Plangenllms: A modern survey of llm planning capabilities,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 19 497–19 521
2025
-
[21]
Metagpt: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, S. Yau, Z. Lin, L. Zhouet al., “Metagpt: Meta programming for a multi-agent collaborative framework,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 23 247–23 275
2024
-
[22]
ChatDev: Communicative agents for software development,
C. Qian, W. Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Yang, W. Chen, Y . Su, X. Cong, J. Xu, D. Li, Z. Liu, and M. Sun, “ChatDev: Communicative agents for software development,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: ...
2024
-
[23]
Enhancing robustness of llm-driven multi-agent systems through randomized smoothing,
J. HU, Y . DONG, Z. DING, and X. HUANG, “Enhancing robustness of llm-driven multi-agent systems through randomized smoothing,” Chinese Journal of Aeronautics, p. 103779, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1000936125003851
2025
-
[24]
Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,”Advances in Neural Information Processing Systems, vol. 37, pp. 50 528–50 652, 2024
2024
-
[25]
Lying with truths: Open-channel multi-agent collusion for belief manipulation via generative montage,
J. Hu, X. Huang, Y . Sun, Y . Dong, and X. Huang, “Lying with truths: Open-channel multi-agent collusion for belief manipulation via generative montage,” inProceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), M. Liakata, V . P. Moreira, J. Zhang, and D. Jurgens, Eds. San Diego, California, United...
2026
-
[26]
Demystifying llm-based software engineering agents,
C. S. Xia, Y . Deng, S. Dunn, and L. Zhang, “Demystifying llm-based software engineering agents,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 801–824, 2025
2025
-
[27]
Theagentcompany: benchmarking llm agents on consequential real world tasks,
F. F. Xu, Y . Song, B. Li, Y . Tang, K. Jain, M. Bao, Z. Wang, X. Zhou, Z. Guo, M. Caoet al., “Theagentcompany: benchmarking llm agents on consequential real world tasks,”Advances in Neural Information Processing Systems, vol. 38, 2026
2026
-
[28]
Not what you’ve signed up for: Compromising real-world llm- integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world llm- integrated applications with indirect prompt injection,” inProceedings of the 16th ACM workshop on artificial intelligence and security, 2023, pp. 79–90
2023
-
[29]
Injecagent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “Injecagent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 10 471–10 506
2024
-
[30]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tramèr, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,”Advances in Neural Information Processing Systems, vol. 37, pp. 82 895–82 920, 2024
2024
-
[31]
Identifying the risks of lm agents with an lm-emulated sandbox,
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. Maddison, and T. Hashimoto, “Identifying the risks of lm agents with an lm-emulated sandbox,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 27 031–27 098
2024
-
[32]
Fuzzing: State of the art,
H. Liang, X. Pei, X. Jia, W. Shen, and J. Zhang, “Fuzzing: State of the art,”IEEE Transactions on Reliability, vol. 67, no. 3, pp. 1199–1218, 2018
2018
-
[33]
Fuzzing: a survey for roadmap,
X. Zhu, S. Wen, S. Camtepe, and Y . Xiang, “Fuzzing: a survey for roadmap,”ACM Computing Surveys (CSUR), vol. 54, no. 11s, pp. 1–36, 2022
2022
-
[34]
Directed or undirected: Investigating fuzzing strategies in a ci/cd setup—rcr report,
M. Huang and C. Lemieux, “Directed or undirected: Investigating fuzzing strategies in a ci/cd setup—rcr report,”ACM Transactions on Software Engineering and Methodology, 2026
2026
-
[35]
Dissecting american fuzzy lop: a fuzzbench evaluation,
A. Fioraldi, A. Mantovani, D. Maier, and D. Balzarotti, “Dissecting american fuzzy lop: a fuzzbench evaluation,”ACM transactions on software engineering and methodology, vol. 32, no. 2, pp. 1–26, 2023
2023
-
[36]
Coverage-based grey- box fuzzing as markov chain,
M. Böhme, V .-T. Pham, and A. Roychoudhury, “Coverage-based grey- box fuzzing as markov chain,” inProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 2016, pp. 1032–1043
2016
-
[37]
The art, science, and engineering of fuzzing: A survey,
V . J. Manès, H. Han, C. Han, S. K. Cha, M. Egele, E. J. Schwartz, and M. Woo, “The art, science, and engineering of fuzzing: A survey,”IEEE Transactions on Software Engineering, vol. 47, no. 11, pp. 2312–2331, 2019
2019
-
[38]
A little goes a long way: Tuning configuration selection for continuous kernel fuzzing,
S. Hasanov, S. Nagy, and P. Gazzillo, “A little goes a long way: Tuning configuration selection for continuous kernel fuzzing,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), 2025, pp. 795–807
2025
-
[39]
Variability-aware fuzzing,
M. T. Ahmed, A. Dev, and S. Wei, “Variability-aware fuzzing,” in2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE), 2026
2026
-
[40]
Directed greybox fuzzing,
M. Böhme, V .-T. Pham, M.-D. Nguyen, and A. Roychoudhury, “Directed greybox fuzzing,” inProceedings of the 2017 ACM SIGSAC conference on computer and communications security, 2017, pp. 2329–2344
2017
-
[41]
On interaction effects in greybox fuzzing,
K. Kitsios, M. Böhme, and A. Bacchelli, “On interaction effects in greybox fuzzing,” inProceedings of the 48th IEEE/ACM International Conference on Software Engineering, 2026
2026
-
[42]
Differential testing for software,
W. M. McKeeman, “Differential testing for software,”Digital Technical Journal, vol. 10, no. 1, pp. 100–107, 1998
1998
-
[43]
Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models,
C. Lemieux, J. P. Inala, S. K. Lahiri, and S. Sen, “Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023, pp. 919–931
2023
-
[44]
Fuzz4all: Universal fuzzing with large language models,
C. S. Xia, M. Paltenghi, J. Le Tian, M. Pradel, and L. Zhang, “Fuzz4all: Universal fuzzing with large language models,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[45]
Ckgfuzzer: Llm-based fuzz driver generation enhanced by code knowledge graph,
H. Xu, W. Ma, T. Zhou, Y . Zhao, K. Chen, Q. Hu, Y . Liu, and H. Wang, “Ckgfuzzer: Llm-based fuzz driver generation enhanced by code knowledge graph,” in2025 IEEE/ACM 47th International Conference on Software Engineering: Companion Proceedings (ICSE- Companion). IEEE, 2025, pp. 243–254
2025
-
[46]
Whitefox: White-box compiler fuzzing empowered by large language models,
C. Yang, Y . Deng, R. Lu, J. Yao, J. Liu, R. Jabbarvand, and L. Zhang, “Whitefox: White-box compiler fuzzing empowered by large language models,”Proceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA2, pp. 709–735, 2024
2024
-
[47]
Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models,
Y . Deng, C. S. Xia, H. Peng, C. Yang, and L. Zhang, “Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models,” inProceedings of the 32nd ACM SIGSOFT interna- tional symposium on software testing and analysis, 2023, pp. 423–435
2023
-
[48]
Locus: Agentic predicate synthesis for directed fuzzing,
J. Zhu, C. Shen, Z. Li, J. Yu, Y . Chen, and K. Pei, “Locus: Agentic predicate synthesis for directed fuzzing,”Proceedings of the 48th IEEE/ACM International Conference on Software Engineering, 2026
2026
-
[49]
Learning seed-adaptive mutation strategies for greybox fuzzing,
M. Lee, S. Cha, and H. Oh, “Learning seed-adaptive mutation strategies for greybox fuzzing,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023, pp. 384–396
2023
-
[50]
Reachable coverage: Estimating saturation in fuzzing,
D. Liyanage, M. Böhme, C. Tantithamthavorn, and S. Lipp, “Reachable coverage: Estimating saturation in fuzzing,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023, pp. 371–383
2023
-
[51]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), 2019, pp. 3982–3992
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.