ACID: Action Consistency via Inverse Dynamics for Planning with World Models
Pith reviewed 2026-07-03 11:02 UTC · model grok-4.3
The pith
ACID adds inverse-dynamics consistency to world-model planning so that predicted transitions must be recoverable from the conditioned actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
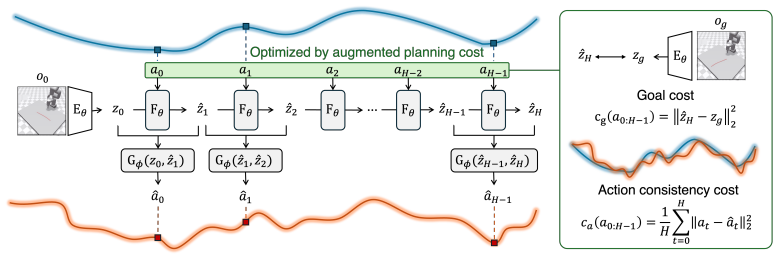
By requiring that the action recovered backward from a predicted state transition equals the action that was conditioned on, the cycle-consistency residual penalizes unrealizable trajectories at decision time and thereby improves both planning quality and efficiency without retraining the world model.
What carries the argument
Cycle action consistency residual: the per-step difference between the conditioned action and the action recovered by the inverse dynamics model from the predicted transition, added to the terminal goal cost via an adaptive scale-invariant weight.
If this is right
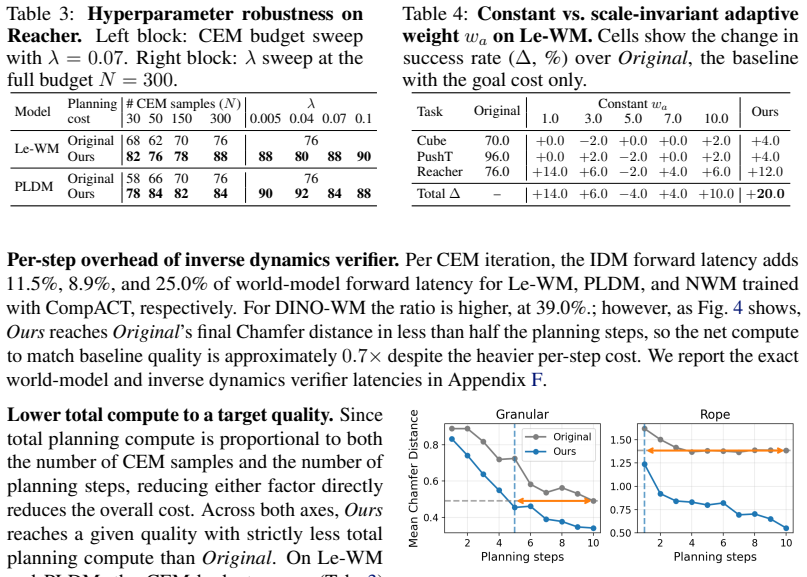
- Planning reaches the same success rate with fewer candidate evaluations or shorter search horizons.
- The improvement holds across rigid-body, deformable-object, and visual-navigation domains without task-specific retuning.
- The consistency term acts as a model-error proxy that does not require additional training data or world-model updates.
- Accuracy gains appear even when the underlying world model is already strong, indicating the check addresses a distinct failure mode.
Where Pith is reading between the lines
- The same per-step consistency idea could be applied to other prediction modalities such as visual features or contact forces.
- In longer-horizon problems the accumulated consistency penalty may limit compounding model drift more effectively than a terminal cost alone.
- If the inverse dynamics model is trained on the same offline data as the world model, both may share the same distribution shift when deployed.
Load-bearing premise
The mismatch between a conditioned action and the action recovered by the inverse dynamics model serves as a reliable proxy for whether that transition will actually occur when the action is executed in the environment.
What would settle it
Run the planner on a task where the inverse dynamics model has been deliberately degraded on a known subset of transitions; if ACID then produces lower success rates than the goal-only baseline, the consistency signal is not functioning as claimed.
Figures




read the original abstract
Decision-time planning with action-conditioned world models has become a popular paradigm for embodied control. However, the standard planning cost judges a candidate solely by how close its predicted terminal state lies to the goal, leaving the realizability of the intermediate transitions unchecked -- a predicted trajectory can look convincing while the environment rollout drifts away from it. In this paper, we propose ACID, a decision-time planning framework that introduces cycle action consistency: the action inferred backward from a predicted transition by an inverse dynamics model should recover the one that was conditioned on. We fold this per-step residual into the planning cost via a scale-invariant adaptive weight. Across four action-conditioned world models and six tasks spanning rigid and deformable manipulation, articulated control, and visual navigation, ACID consistently improves planning and matches the baseline's accuracy with substantially less planning compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ACID, a decision-time planning method for action-conditioned world models. It augments the standard terminal-state cost with a cycle-consistency residual ||a_t - IDM(ŝ_t, ŝ_{t+1})|| obtained from a separately trained inverse dynamics model, incorporated via a scale-invariant adaptive weight. The central claim is that this term enforces realizability of intermediate transitions and yields consistent planning improvements across four world models and six tasks (rigid/deformable manipulation, articulated control, visual navigation) while matching baseline accuracy at substantially lower planning compute.
Significance. If the consistency residual reliably proxies environment realizability rather than shared model bias, the approach would address a recognized weakness in model-based planning without extra training or interaction. The multi-model, multi-task evaluation and reported compute reduction are strengths that would make the result relevant to embodied control if substantiated.
major comments (2)
- [Experiments / Method (central mechanism)] The central claim that the per-step residual serves as a reliable proxy for transition realizability is load-bearing, yet the manuscript provides no direct validation (e.g., correlation between the residual and actual environment rollout error on held-out transitions). This leaves open the possibility that the reported gains arise from reduced variance in the cost rather than genuine filtering of unrealizable trajectories.
- [Method (cycle consistency term)] Both the action-conditioned world model and the IDM are trained on the same offline dataset; the manuscript does not analyze or mitigate the risk that systematic biases or coverage gaps are shared, causing the residual to under-penalize jointly plausible but unrealizable transitions. This directly affects whether the adaptive weighting improves realizability or merely amplifies model agreement.
minor comments (1)
- [Method] Notation for the adaptive weight and its scale-invariance property should be defined explicitly with an equation, as the current description leaves the precise functional form unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the strengths of the multi-model evaluation and compute savings. We address the two major comments point-by-point below, agreeing that additional validation is warranted and proposing targeted revisions to strengthen the evidence.
read point-by-point responses
-
Referee: [Experiments / Method (central mechanism)] The central claim that the per-step residual serves as a reliable proxy for transition realizability is load-bearing, yet the manuscript provides no direct validation (e.g., correlation between the residual and actual environment rollout error on held-out transitions). This leaves open the possibility that the reported gains arise from reduced variance in the cost rather than genuine filtering of unrealizable trajectories.
Authors: We agree that a direct correlation analysis would provide stronger substantiation that the residual acts as a realizability proxy rather than simply reducing cost variance. In the revised manuscript we will add an experiment on held-out transitions that reports the Pearson correlation between the per-step ACID residual and the actual environment rollout error (state discrepancy after executing the planned action sequence). This analysis will appear in a new subsection of the experiments or an appendix. revision: yes
-
Referee: [Method (cycle consistency term)] Both the action-conditioned world model and the IDM are trained on the same offline dataset; the manuscript does not analyze or mitigate the risk that systematic biases or coverage gaps are shared, causing the residual to under-penalize jointly plausible but unrealizable transitions. This directly affects whether the adaptive weighting improves realizability or merely amplifies model agreement.
Authors: The shared-data concern is legitimate. While the forward and inverse objectives differ and can produce distinct error patterns, we will add an explicit discussion and supporting analysis in the revision: we will quantify disagreement between the world model and IDM on held-out data and show how the adaptive weight modulates the residual in those cases. We will also state the limitation clearly and note that training the IDM on a disjoint dataset (when available) is a natural future direction. These changes clarify assumptions without altering the method. revision: partial
Circularity Check
No significant circularity; consistency residual is an independent check
full rationale
The ACID framework trains an action-conditioned world model and a separate inverse dynamics model on the same offline dataset, then uses the per-step residual between a conditioned action and the IDM-recovered action as an additive term in the planning cost. This residual is computed from an external model rather than being defined in terms of the world model's own predictions or fitted parameters. No equations reduce the consistency term to a self-referential quantity by construction, no uniqueness theorems are imported from prior self-citations, and no ansatz is smuggled via citation. The reported gains are empirical across multiple models and tasks, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- scale-invariant adaptive weight
axioms (1)
- domain assumption An inverse dynamics model can accurately recover the conditioned action from a predicted state transition
Reference graph
Works this paper leans on
-
[1]
D. Ha and J. Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3), 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y . LeCun. Navigation world models. InProc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[3]
D. Kim, G. Seo, J. Lee, M. Cho, and S. Kwak. Planning in 8 tokens: A compact discrete tokenizer for latent world model. InProc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[4]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning. InProc. International Conference on Machine Learning (ICML), 2025
2025
-
[5]
L. Maes, Q. L. Lidec, D. Scieur, Y . LeCun, and R. Balestriero. Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Sobal, W
U. Sobal, W. Zhang, K. Cho, R. Balestriero, T. G. Rudner, and Y . LeCun. Learning from reward-free offline data: A case for planning with latent dynamics models.Advances in Neural Information Processing Systems, 38:43905–43941, 2026
2026
-
[8]
H. Nam, Q. L. Lidec, L. Maes, Y . LeCun, and R. Balestriero. Causal-jepa: Learning world models through object-level latent interventions. InProc. International Conference on Machine Learning (ICML), 2026
2026
-
[9]
Hansen, H
N. Hansen, H. Su, and X. Wang. Td-mpc2: Scalable, robust world models for continuous control. InProc. International Conference on Learning Representations (ICLR), 2024
2024
-
[10]
Morari and J
M. Morari and J. H. Lee. Model predictive control: past, present and future.Computers & Chemical Engineering, 23:667–682, 1999
1999
-
[11]
De Boer, D
P.-T. De Boer, D. P. Kroese, S. Mannor, and R. Y . Rubinstein. A tutorial on the cross-entropy method.Annals of operations research, 134(1):19–67, 2005
2005
-
[12]
B. Chen, D. Mart´ı Mons´o, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InProc. Neural Information Processing Systems (NeurIPS), 2024
2024
-
[13]
Y . Du, M. Yang, P. Florence, F. Xia, A. Wahid, B. Ichter, P. Sermanet, T. Yu, P. Abbeel, J. B. Tenenbaum, et al. Video language planning. InProc. International Conference on Learning Representations (ICLR), 2024
2024
-
[14]
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
S. Gao, J. Yang, L. Chen, K. Chitta, Y . Qiu, A. Geiger, J. Zhang, and H. Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. InProc. Neural Information Processing Systems (NeurIPS), 2024
2024
-
[16]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Bruce, M
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, et al. Genie: Generative interactive environments. InProc. Interna- tional Conference on Machine Learning (ICML), 2024. 9
2024
-
[18]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation. InProc. Neural Information Processing Systems (NeurIPS), 2023
2023
- [19]
-
[20]
K. Song, B. Chen, M. Simchowitz, Y . Du, R. Tedrake, and V . Sitzmann. History-guided video diffusion. InProc. International Conference on Machine Learning (ICML), 2025
2025
-
[21]
D. Kim, N. Kim, and S. Kwak. Improving cross-modal retrieval with set of diverse embeddings. InProc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[22]
Song and M
Y . Song and M. Soleymani. Polysemous visual-semantic embedding for cross-modal retrieval. InProc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[23]
S. Chun, S. J. Oh, R. S. De Rezende, Y . Kalantidis, and D. Larlus. Probabilistic embeddings for cross-modal retrieval. InProc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[24]
Rigter, T
M. Rigter, T. Gupta, A. Hilmkil, and C. Ma. A VID: Adapting video diffusion models to world models. InReinforcement Learning Conference, 2025
2025
-
[25]
A. Xie, O. Rybkin, D. Sadigh, and C. Finn. Latent diffusion planning for imitation learning. In Proc. International Conference on Machine Learning (ICML), 2025
2025
- [26]
-
[27]
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. InRobotics: Science and Systems (RSS), 2025
2025
-
[28]
Brandfonbrener, O
D. Brandfonbrener, O. Nachum, and J. Bruna. Inverse dynamics pretraining learns good representations for multitask imitation. InProc. Neural Information Processing Systems (NeurIPS), 2023
2023
-
[29]
Baker, I
B. Baker, I. Akkaya, P. Zhokov, J. Huizinga, J. Tang, A. Ecoffet, B. Houghton, R. Sampedro, and J. Clune. Video pretraining (vpt): Learning to act by watching unlabeled online videos. In Proc. Neural Information Processing Systems (NeurIPS), 2022
2022
-
[30]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models.arXiv preprint arXiv:2505.12705, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Lipman, R
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InProc. International Conference on Learning Representations (ICLR), 2023
2023
-
[32]
Q. Liu. Rectified flow: A marginal preserving approach to optimal transport.arXiv preprint arXiv:2209.14577, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
D. Shah, B. Eysenbach, N. Rhinehart, and S. Levine. Rapid exploration for open-world navigation with latent goal models. InAnnual Conference on Robot Learning (CoRL), 2021. 10
2021
-
[35]
Sturm, W
J. Sturm, W. Burgard, and D. Cremers. Evaluating egomotion and structure-from-motion approaches using the tum rgb-d benchmark. InProc. of the Workshop on Color-Depth Camera Fusion in Robotics at the IEEE/RJS International Conference on Intelligent Robot Systems (IROS), 2012
2012
-
[36]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[37]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InProc. International Conference on Learning Representations (ICLR), 2019
2019
-
[38]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
R. Balestriero and Y . LeCun. Lejepa: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Y . Tassa, Y . Doron, A. Muldal, T. Erez, Y . Li, D. d. L. Casas, D. Budden, A. Abdolmaleki, J. Merel, A. Lefrancq, et al. Deepmind control suite.arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
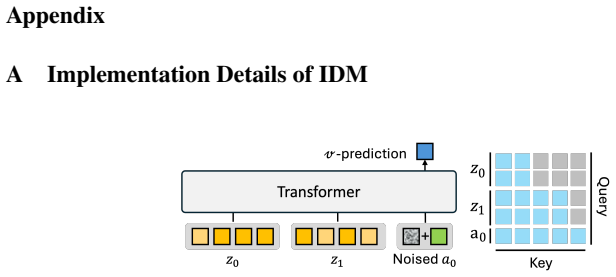
K. Zhang, B. Li, K. Hauser, and Y . Li. Adaptigraph: Material-adaptive graph-based neural dynamics for robotic manipulation.arXiv preprint arXiv:2407.07889, 2024. 11 Appendix A Implementation Details of IDM Figure 5:Inverse Dynamics Model(IDM) architecture.(Left): the prefix–suffix transformer that predicts the action between the latents of two consecutiv...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.