DRS-GUI: Dynamic Region Search for Training-Free GUI Grounding
Pith reviewed 2026-05-19 14:20 UTC · model grok-4.3
pith:26GH5WOR Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{26GH5WOR}
Prints a linked pith:26GH5WOR badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
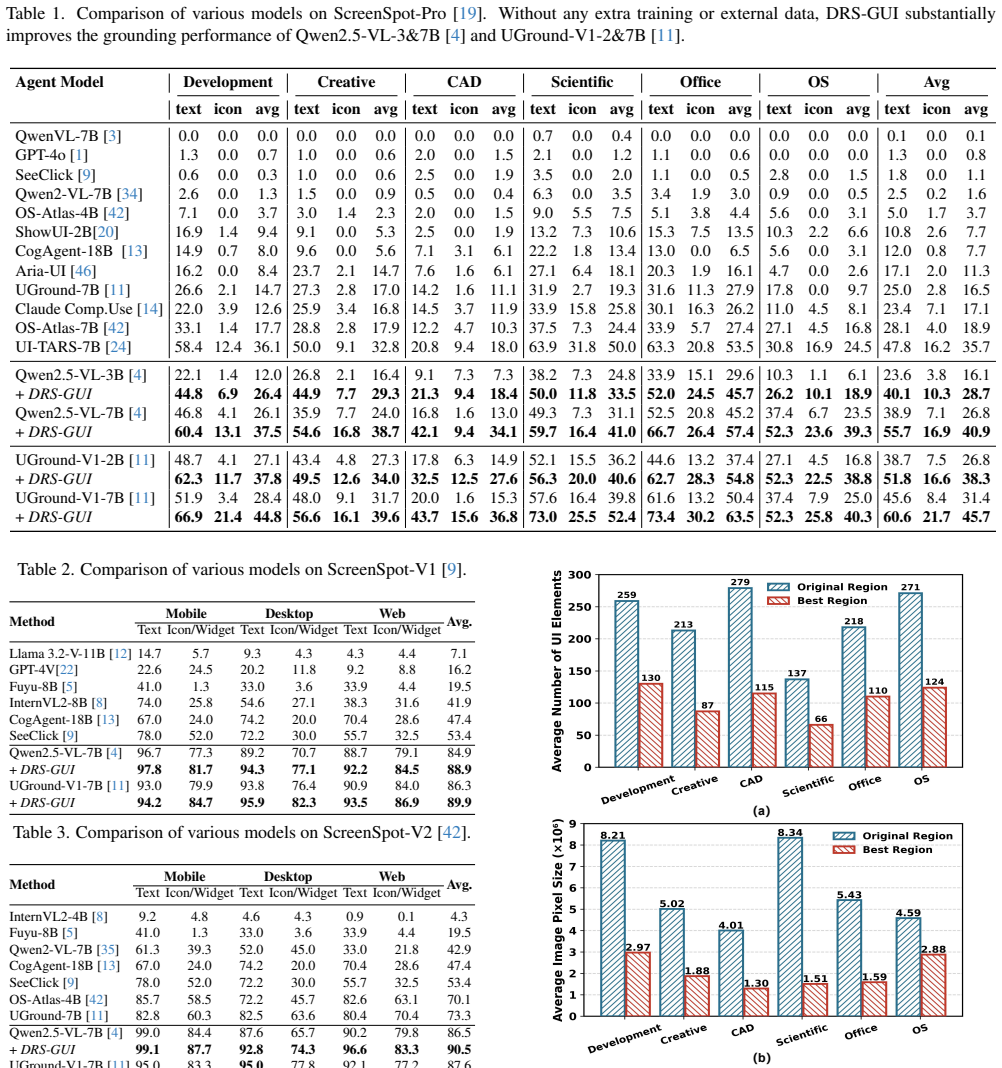
A training-free dynamic region search method improves GUI grounding performance by 14 percent in existing multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
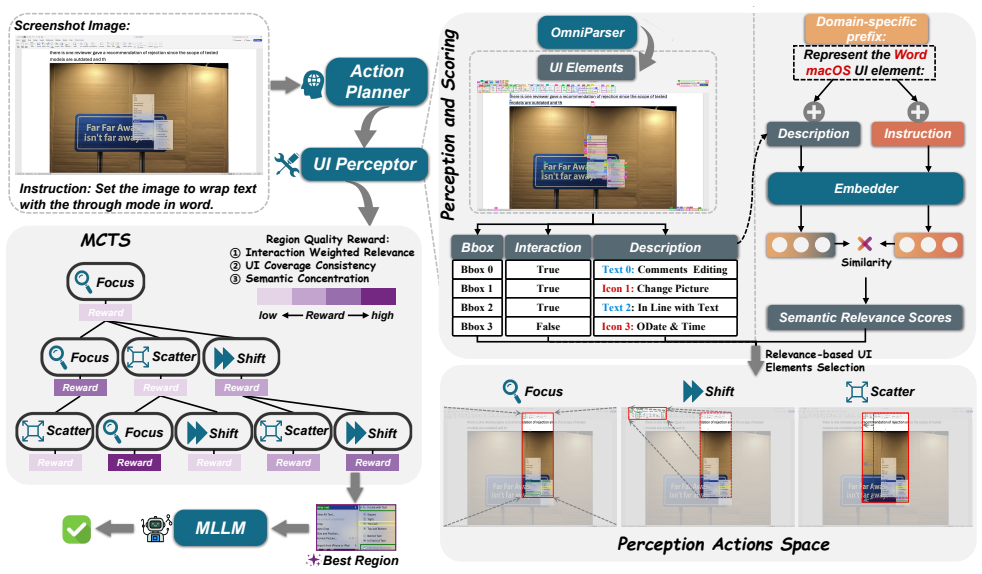
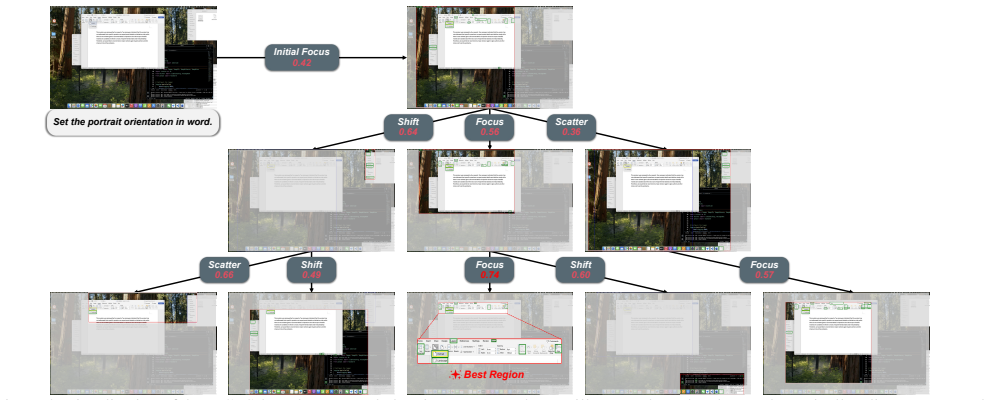
The paper claims that a training-free dynamic region search framework can improve instruction grounding on cluttered high-resolution GUI screenshots. It does so by equipping multimodal models with a lightweight UI Perceptor that executes Focus, Shift, and Scatter actions, scheduled dynamically by an MCTS-based Action Planner and evaluated through a region quality reward that selects highly relevant proposals and prunes irrelevant UI elements. This integration requires no model training or fine-tuning and produces measurable gains for both general and GUI-specific MLLMs.
What carries the argument
The central mechanism is the MCTS-based Action Planner that schedules the lightweight UI Perceptor's three perceptual actions (Focus, Shift, and Scatter) to generate, evaluate, and select instruction-relevant region proposals.
If this is right
- Existing MLLMs gain improved grounding accuracy on complex GUI interfaces by adding this module.
- No additional training or fine-tuning is needed to obtain the reported performance lift.
- The approach applies across both general-purpose and GUI-specialized multimodal models.
- Irrelevant UI components are removed efficiently through reward-driven selection of regions.
Where Pith is reading between the lines
- Similar search-based planning could help with other visual grounding problems where screens or scenes contain high visual clutter.
- The work points to planning algorithms as one route to strengthen perception inside large models that lack explicit exploration.
- Because the method adds no training cost, it could be tested quickly on additional benchmarks or real-world GUI agent tasks.
Load-bearing premise
The three perceptual actions performed by the UI Perceptor will reliably produce and allow selection of instruction-relevant regions when scheduled by the MCTS planner.
What would settle it
Direct evaluation on ScreenSpot-Pro showing that adding DRS-GUI produces no accuracy gain or a loss compared to the same MLLMs without the module would falsify the central claim.
Figures





read the original abstract
GUI agents powered by Multimodal Large Language Models (MLLMs) have demonstrated impressive capability in understanding and executing user instructions. However, accurately grounding instruction-relevant elements from high-resolution screenshots cluttered with irrelevant UI components remains challenging for existing approaches. Inspired by how humans dynamically adjust their perceptual scope to locate task-related regions on complex screens, we propose DRS-GUI, a training-free dynamic region search framework for GUI grounding that can be seamlessly integrated into existing MLLMs. DRS-GUI introduces a lightweight UI Perceptor that performs three human-like perceptual actions (Focus, Shift, and Scatter) to progressively explore the interface and generate region proposals. To dynamically schedule these actions, we further design an Action Planner based on Monte Carlo Tree Search (MCTS). A region quality reward is employed to evaluate and select the highly instruction-relevant region, efficiently pruning redundant UI elements. Experiments demonstrate that DRS-GUI yields a 14\% improvement on ScreenSpot-Pro for general and GUI-specific MLLMs (Qwen2.5-VL-7B and UGround-V1-7B), significantly enhancing grounding performance and generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DRS-GUI, a training-free framework for GUI grounding in multimodal large language models. It features a lightweight UI Perceptor that executes three perceptual actions—Focus, Shift, and Scatter—to generate region proposals from high-resolution screenshots, scheduled dynamically via a Monte Carlo Tree Search (MCTS) based Action Planner using a region quality reward. The approach is evaluated on the ScreenSpot-Pro benchmark, reporting a 14% performance improvement for both general (Qwen2.5-VL-7B) and GUI-specific (UGround-V1-7B) MLLMs.
Significance. Should the central claims hold after addressing the experimental gaps, the work could offer a practical, training-free method to enhance the grounding accuracy and generalization of existing MLLMs on cluttered GUI interfaces by mimicking human-like dynamic perceptual adjustment. This has potential implications for improving the reliability of GUI agents without the need for model fine-tuning or additional training data.
major comments (3)
- Experiments section: The reported 14% gain on ScreenSpot-Pro lacks information on the number of MLLM forward passes required per test case, which is necessary to determine if the improvement stems from the dynamic region search or simply from additional model queries.
- Method section: The paper does not include ablations demonstrating that the MCTS-based scheduling of Focus, Shift, and Scatter actions outperforms simpler strategies such as random region sampling or direct evaluation on the full screenshot.
- §3.3 Action Planner: Details on the exact formulation of the region quality reward function are missing, making it unclear how the planner reliably ranks and selects instruction-relevant regions over the original cluttered input.
minor comments (1)
- Abstract: Consider specifying the exact evaluation metric (e.g., accuracy at a given IoU threshold) underlying the 14% improvement claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of our work. We address each major comment below and indicate revisions to the manuscript.
read point-by-point responses
-
Referee: Experiments section: The reported 14% gain on ScreenSpot-Pro lacks information on the number of MLLM forward passes required per test case, which is necessary to determine if the improvement stems from the dynamic region search or simply from additional model queries.
Authors: We agree this detail is important for interpreting the source of gains. In the revised manuscript we have added the average number of MLLM forward passes per test case (approximately 6.2 for DRS-GUI versus 1 for direct baselines). We further include a controlled comparison showing that simply increasing query budget on the full screenshot does not reproduce the observed accuracy lift, indicating the benefit arises from targeted region selection and pruning rather than query volume alone. revision: yes
-
Referee: Method section: The paper does not include ablations demonstrating that the MCTS-based scheduling of Focus, Shift, and Scatter actions outperforms simpler strategies such as random region sampling or direct evaluation on the full screenshot.
Authors: We acknowledge the value of such ablations. The revised manuscript now includes an ablation study (new Section 4.3) comparing MCTS scheduling against random action selection and direct full-screenshot evaluation. Results confirm MCTS yields higher grounding accuracy; random sampling frequently selects irrelevant regions while direct evaluation is hindered by visual clutter. These additions directly address the concern. revision: yes
-
Referee: §3.3 Action Planner: Details on the exact formulation of the region quality reward function are missing, making it unclear how the planner reliably ranks and selects instruction-relevant regions over the original cluttered input.
Authors: We apologize for the omission. The region quality reward is formulated as r = α · sim(MLLM_embed(region), MLLM_embed(instruction)) − β · (area(region)/area(screenshot)), where sim denotes cosine similarity of embeddings and α, β are tuned hyperparameters. This formulation prioritizes semantically aligned yet compact regions. We have inserted the exact equation, hyperparameter values, and usage within the MCTS backup step into the revised §3.3, together with a short derivation of why it favors relevant regions over cluttered input. revision: yes
Circularity Check
No significant circularity: method is training-free with externally evaluated gains and no self-referential derivations or fitted predictions.
full rationale
The paper presents DRS-GUI as a training-free framework using a lightweight UI Perceptor with Focus/Shift/Scatter actions scheduled by MCTS and a region quality reward. No equations, parameter fits, or derivations are described that reduce the reported 14% ScreenSpot-Pro improvement to an internal definition or self-citation chain. The central claims rely on external benchmarks (Qwen2.5-VL-7B, UGround-V1-7B) rather than any quantity defined inside the paper itself. Self-citations, if present in the full text, are not load-bearing for the core performance claim, which remains independently falsifiable via the stated evaluation protocol. This is a standard honest non-finding for a descriptive systems paper without mathematical self-reference.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DRS-GUI introduces a lightweight UI Perceptor that performs three human-like perceptual actions (Focus, Shift, and Scatter) ... an Action Planner based on Monte Carlo Tree Search (MCTS). A region quality reward is employed...
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The MCTS planner runs with a rollout budget of N=8, depth limit H=3...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Introducing our multimodal models, 2023
Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, and Sa ˘gnak Tas ¸ırlar. Introducing our multimodal models, 2023. 6
work page 2023
-
[6]
Meng Cao, Haoze Zhao, Can Zhang, Xiaojun Chang, Ian Reid, and Xiaodan Liang. Ground-r1: Incentivizing grounded visual reasoning via reinforcement learning.arXiv preprint arXiv:2505.20272, 2025. 2
-
[7]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks.arXiv preprint arXiv:2312.14238, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.arXiv preprint arXiv:2404.16821, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Seeclick: Harness- ing GUI grounding for advanced visual GUI agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yan- tao Li, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harness- ing GUI grounding for advanced visual GUI agents. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 9313–
work page 2024
- [10]
-
[11]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samual Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. InAdvances in Neu- ral Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. 2
work page 2023
-
[12]
Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for gui agents.arXiv preprint arXiv:2410.05243, 2024. 1, 2, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Cogagent: A visual lan- guage model for GUI agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, and Jie Tang. Cogagent: A visual lan- guage model for GUI agents. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 14281–14290. IEEE, 2024. 6
work page 2024
-
[15]
Siyuan Hu, Mingyu Ouyang, Difei Gao, and Mike Zheng Shou. The dawn of gui agent: A preliminary case study with claude 3.5 computer use.arXiv preprint arXiv:2411.10323,
-
[16]
Bandit based monte- carlo planning
Levente Kocsis and Csaba Szepesv ´ari. Bandit based monte- carlo planning. InEuropean conference on machine learn- ing, pages 282–293, 2006. 4
work page 2006
-
[17]
A training-free, task-agnostic framework for enhancing mllm performance on high-resolution images
Jaeseong Lee, Yeeun Choi, Heechan Choi, Hanjung Kim, and Seonjoo Kim. A training-free, task-agnostic framework for enhancing mllm performance on high-resolution images. arXiv preprint arXiv:2507.10202, 2025. 1, 2
-
[18]
Ground- ing multimodal large language model in gui world
Weixian Lei, Difei Gao, and Mike Zheng Shou. Ground- ing multimodal large language model in gui world. InThe Thirteenth International Conference on Learning Represen- tations. 1
-
[19]
Geng Li, Jinglin Xu, Yunzhen Zhao, and Yuxin Peng. Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9098–9108, 2025. 2
work page 2025
-
[20]
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: Gui grounding for professional high- resolution computer use.arXiv preprint arXiv:2504.07981,
-
[21]
Showui: One vision-language-action model for gener- alist gui agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Zechen Bai, Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gener- alist gui agent. InNeurIPS 2024 Workshop on Open-World Agents, 2024. 1, 6
work page 2024
-
[22]
Omniparser for pure vision based gui agent
Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadallah. Omniparser for pure vision based gui agent. arXiv preprint arXiv:2408.00203, 2024. 2, 3
- [23]
-
[24]
Joonhyung Park, Peng Tang, Sagnik Das, Srikar Appalaraju, Kunwar Yashraj Singh, R Manmatha, and Shabnam Ghadar. R-vlm: Region-aware vision language model for precise gui grounding.arXiv preprint arXiv:2507.05673, 2025. 1, 2
-
[25]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shi- jue Huang, et al. Ui-tars: Pioneering automated gui inter- action with native agents.arXiv preprint arXiv:2501.12326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Grounded Reinforcement Learning for Visual Reasoning
Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J Tarr, Aviral Kumar, and Katerina Fragki- adaki. Grounded reinforcement learning for visual reason- ing.arXiv preprint arXiv:2505.23678, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Melanie Sclar, Gaston Bujia, Sebastian Vita, Guillermo Solovey, and Juan Esteban Kamienkowski. Modeling human visual search: A combined bayesian searcher and saliency map approach for eye movement guidance in natural scenes. InNeurIPS Workshop SVRHM, 2020. 2
work page 2020
-
[28]
Huawen Shen, Chang Liu, Gengluo Li, Xinlong Wang, Yu Zhou, Can Ma, and Xiangyang Ji. Falcon-ui: Understand- ing gui before following user instructions.arXiv preprint arXiv:2412.09362, 2024. 1
-
[29]
Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrit- twieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016. 2
work page 2016
-
[30]
One embedder, any task: Instruction-finetuned text embeddings.arXiv preprint arXiv:2212.09741, 2022
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A Smith, Luke Zettlemoyer, and Tao Yu. One embedder, any task: Instruction-finetuned text embeddings.arXiv preprint arXiv:2212.09741, 2022. 2, 3
-
[31]
Visual agents as fast and slow thinkers.arXiv preprint arXiv:2408.08862, 2024
Guangyan Sun, Mingyu Jin, Zhenting Wang, Cheng-Long Wang, Siqi Ma, Qifan Wang, Tong Geng, Ying Nian Wu, Yongfeng Zhang, and Dongfang Liu. Visual agents as fast and slow thinkers.arXiv preprint arXiv:2408.08862, 2024. 2
-
[32]
Antonio Torralba, Aude Oliva, Monica S Castelhano, and John M Henderson. Contextual guidance of eye movements and attention in real-world scenes: the role of global features in object search.Psychological Review, 2006. 2, 4
work page 2006
-
[33]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception.arXiv preprint arXiv:2401.16158, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Wanfu Wang, Qipeng Huang, Guangquan Xue, Xiaobo Liang, and Juntao Li. Learning active perception via self- evolving preference optimization for gui grounding.arXiv preprint arXiv:2509.04243, 2025. 1, 2
-
[38]
Visual search: How do we find what we are looking for?Annual review of vision science, 2020
Jeremy M Wolfe. Visual search: How do we find what we are looking for?Annual review of vision science, 2020. 2
work page 2020
-
[39]
Jeremy M Wolfe, Melissa L-H V ˜o, Karla K Evans, and Michelle R Greene. Visual search in scenes involves se- lective and nonselective pathways.Trends in Cognitive Sci- ences, 2011. 2, 4
work page 2011
-
[40]
Hang Wu, Hongkai Chen, Yujun Cai, Chang Liu, Qing- wen Ye, Ming-Hsuan Yang, and Yiwei Wang. Dimo-gui: Advancing test-time scaling in gui grounding via modality- aware visual reasoning.arXiv preprint arXiv:2507.00008,
-
[41]
V*: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024. 2
work page 2024
-
[42]
Gui-actor: Coordinate-free visual grounding for gui agents.arXiv preprint arXiv:2506.03143,
Qianhui Wu, Kanzhi Cheng, Rui Yang, Chaoyun Zhang, Jianwei Yang, Huiqiang Jiang, Jian Mu, Baolin Peng, Bo Qiao, Reuben Tan, et al. Gui-actor: Coordinate-free visual grounding for gui agents.arXiv preprint arXiv:2506.03143,
-
[43]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents.arXiv preprint arXiv:2410.23218, 2024. 1, 2, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tian- bao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous gui interaction.arXiv preprint arXiv:2412.04454, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
McAuley, Zicheng Gao, Lijuan Liu, and Lijuan Wang
An Yan, Zhengyuan Yang, Wanrong Zhu, Kevin Lin, Lin- jie Li, Jianfeng Wang, Jianwei Yang, Yiwu Zhong, Julian McAuley, Jianfeng Gao, et al. Gpt-4v in wonderland: Large multimodal models for zero-shot smartphone gui navigation. arXiv preprint arXiv:2311.07562, 2023. 2
-
[46]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Aria-ui: Visual grounding for gui instructions
Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, and Junnan Li. Aria-ui: Visual grounding for gui instructions. InFindings of the Association for Compu- tational Linguistics: ACL 2025, pages 22418–22433, 2025. 1, 6
work page 2025
-
[48]
Qilang Ye, Zitong Yu, Rui Shao, Xinyu Xie, Philip Torr, and Xiaochun Cao. CAT: enhancing multimodal large language model to answer questions in dynamic audio-visual scenar- ios. InComputer Vision - ECCV 2024 - 18th European Con- ference, Milan, Italy, September 29-October 4, 2024, Pro- ceedings, Part X, pages 146–164, 2024. 2
work page 2024
-
[49]
Qilang Ye, Zitong Yu, Rui Shao, Yawen Cui, Xiangui Kang, Xin Liu, Philip Torr, and Xiaochun Cao. Cat+: Investigating and enhancing audio-visual understanding in large language models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 2
work page 2025
-
[50]
Qilang Ye, Wei Zeng, Meng Liu, Jie Zhang, Yupeng Hu, Zi- tong Yu, and Yu Zhou. When eyes and ears disagree: Can mllms discern audio-visual confusion? InAAAI Conference on Artificial Intelligence, 2026. 2
work page 2026
-
[51]
Enhancing visual grounding for gui agents via self-evolutionary reinforcement learning
Xinbin Yuan, Jian Zhang, Kaixin Li, Zhuoxuan Cai, Lujian Yao, Jie Chen, Enguang Wang, Qibin Hou, Jinwei Chen, Peng-Tao Jiang, et al. Enhancing visual grounding for gui agents via self-evolutionary reinforcement learning.arXiv preprint arXiv:2505.12370, 2025. 1
-
[52]
Mengmi Zhang, Jiashi Feng, Keng Teck Ma, Joo Hwee Lim, Qi Zhao, and Gabriel Kreiman. Finding any waldo with zero- shot invariant and efficient visual search.Nature communi- cations, 2018. 2
work page 2018
-
[53]
Yu Zhao, Wei-Ning Chen, Huseyin Atahan Inan, Samuel Kessler, Lu Wang, Lukas Wutschitz, Fangkai Yang, Chaoyun Zhang, Pasquale Minervini, Saravan Rajmohan, et al. Learn- ing gui grounding with spatial reasoning from visual feed- back.arXiv preprint arXiv:2509.21552, 2025. 2
-
[54]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deep- eyes: Incentivizing” thinking with images” via reinforce- ment learning.arXiv preprint arXiv:2505.14362, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Muzhi Zhu, Hao Zhong, Canyu Zhao, Zongze Du, Zheng Huang, Mingyu Liu, Hao Chen, Cheng Zou, Jingdong Chen, Ming Yang, et al. Active-o3: Empowering multimodal large language models with active perception via grpo.arXiv preprint arXiv:2505.21457, 2025. 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.