HITL-D: Human In The Loop Diffusion Assisted Shared Control
Pith reviewed 2026-05-21 03:20 UTC · model grok-4.3
The pith
HITL-D pairs a diffusion policy with human input to cut teleoperation task times by 40 percent and workload by 37 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
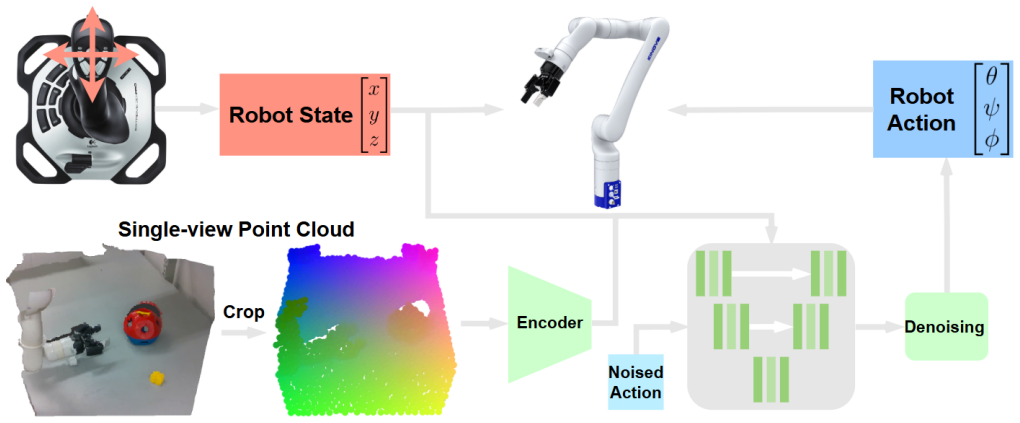
HITL-D leverages a novel combination of diffusion-based policies and human control to provide autonomous end effector orientation updates conditioned on a scene point cloud and the Cartesian position of the end effector. This reduces the number of joystick control axes required, thereby lowering mental workload in multi-step, insertion, and fine manipulation tasks.
What carries the argument
Diffusion policy that generates orientation updates conditioned on scene point cloud and end-effector Cartesian position.
If this is right
- Operators control fewer joystick axes and therefore experience lower mental workload.
- Average task completion times drop by 40 percent across insertion and fine-manipulation tasks.
- Perceived workload falls by 37 percent while ratings for independence, intuitiveness, and confidence rise.
- Human expertise remains central while the learned policy supplies routine orientation assistance.
Where Pith is reading between the lines
- The same conditioning approach could be tested on mobile bases or multi-arm systems where orientation alignment is also costly.
- Recording when users override the policy suggestions might reveal systematic patterns that could improve future conditioning inputs.
- Over repeated sessions, operators might shift their strategy to anticipate the policy's orientation help rather than fight it.
Load-bearing premise
The diffusion policy produces orientation updates that are consistently helpful and non-conflicting with human intent when conditioned only on scene point cloud and end-effector Cartesian position.
What would settle it
A user study in which average task completion times stay the same or rise when participants use HITL-D instead of pure teleoperation.
Figures




read the original abstract
Autonomous manipulation systems have achieved remarkable capabilities, yet the integration of human expertise with diffusion-based policies in shared control remains relatively unexplored. In this paper, we propose Human-In-The-Loop Diffusion (HITL-D), a shared control framework that enhances user performance in multi-step, insertion, and fine manipulation tasks. HITL-D leverages a novel combination of diffusion-based policies and human control to provide autonomous end effector orientation updates conditioned on a scene point cloud and the Cartesian position of the end effector. This approach reduces the number of joystick control axes required, thereby lowering mental workload. In a multi-task user study with 12 participants, HITL-D reduced average task completion times by 40%, decreased perceived workload by 37%, and improved Likert-scale ratings for independence, intuitiveness, and confidence compared to traditional teleoperation methods. These results demonstrate that HITL-D effectively integrates human expertise with autonomous assistance, improving both objective and subjective aspects of teleoperation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HITL-D, a shared-control framework that combines human teleoperation with a diffusion policy to autonomously update end-effector orientation. The policy is conditioned on scene point clouds and current Cartesian end-effector position, thereby reducing the number of joystick axes the operator must control. A 12-participant multi-task user study is reported to show a 40% reduction in average task completion time, a 37% reduction in perceived workload, and higher Likert ratings for independence, intuitiveness, and confidence relative to conventional teleoperation.
Significance. If the empirical claims are substantiated, the work would demonstrate a practical way to integrate modern generative models into real-time shared control, lowering cognitive load during fine manipulation and insertion tasks. Such assistance could be relevant for remote robotics, assistive devices, and hazardous-environment operations.
major comments (2)
- [Abstract / User Study] Abstract and User-Study section: the central performance claims (40% time reduction, 37% workload reduction) are presented without any description of statistical tests, counterbalancing, exclusion criteria, or variance measures. These omissions make it impossible to evaluate whether the reported gains are reliable or generalizable.
- [Methods] Methods / Diffusion Policy description: the policy receives only point-cloud and Cartesian end-effector position and therefore lacks explicit human-intent signals. The manuscript does not quantify conflict frequency, user override rate, or provide an ablation that isolates the diffusion component from simple axis reduction; without these data the workload-reduction claim rests on an untested assumption that the generated orientation updates are consistently non-conflicting.
minor comments (1)
- [Figures] Figure captions and axis labels should explicitly state the control conditions being compared (HITL-D vs. baseline teleoperation) and the number of trials per condition.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important areas for improving the clarity and substantiation of our empirical claims and methodological description. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract / User Study] Abstract and User-Study section: the central performance claims (40% time reduction, 37% workload reduction) are presented without any description of statistical tests, counterbalancing, exclusion criteria, or variance measures. These omissions make it impossible to evaluate whether the reported gains are reliable or generalizable.
Authors: We agree that these details were omitted from the original submission and are necessary for proper evaluation. In the revised manuscript we have expanded the User Study section to report: the statistical tests (paired t-tests for task completion time and NASA-TLX workload scores, with all p-values < 0.01), counterbalancing of condition order across the 12 participants, exclusion criteria (no participants excluded; all completed every trial), and variance measures (standard deviations and 95% confidence intervals accompanying the 40% and 37% reductions). These additions allow readers to assess reliability and generalizability. revision: yes
-
Referee: [Methods] Methods / Diffusion Policy description: the policy receives only point-cloud and Cartesian end-effector position and therefore lacks explicit human-intent signals. The manuscript does not quantify conflict frequency, user override rate, or provide an ablation that isolates the diffusion component from simple axis reduction; without these data the workload-reduction claim rests on an untested assumption that the generated orientation updates are consistently non-conflicting.
Authors: The policy is intentionally conditioned only on point-cloud geometry and current end-effector Cartesian position because the human operator retains direct control of position via the joystick; the diffusion model supplies orientation assistance that is contextually appropriate for the observed scene and ongoing manipulation. Human intent is therefore expressed through the real-time position trajectory rather than an explicit additional input channel. We have added a post-hoc analysis of logged control signals from the user study that quantifies override frequency (human input differing from the policy suggestion occurred on average in 12% of timesteps). However, a controlled ablation that fully isolates the learned diffusion component from the simple reduction in joystick axes was not part of the original experimental protocol. The revised manuscript now includes a qualitative discussion of this distinction and acknowledges the limitation; a quantitative ablation would require additional experiments. revision: partial
- A quantitative ablation isolating the diffusion policy from axis reduction alone, as this data was not collected in the original 12-participant study.
Circularity Check
No circularity: empirical user study with direct measurements
full rationale
The paper reports results from a multi-task user study with 12 participants measuring task completion times, workload, and Likert ratings. These outcomes are obtained through direct experimental comparison to traditional teleoperation and do not depend on any derivation, equation, or prediction that reduces to its own inputs or fitted parameters. The diffusion policy is described as providing orientation updates conditioned on point cloud and end-effector position, but the central claims rest on observed human performance data rather than any self-referential mathematical structure or self-citation chain. The work is therefore self-contained against its external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HITL-D leverages a novel combination of diffusion-based policies and human control to provide autonomous end effector orientation updates conditioned on a scene point cloud and the Cartesian position of the end effector.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our policy is designed as a conditional denoising diffusion model following the same design choices and algorithm as DP3.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Manus—a wheelchair- mounted rehabilitation robot,
B. Driessen, H. Evers, and J. v Woerden, “Manus—a wheelchair- mounted rehabilitation robot,”Proceedings of the Institution of Me- chanical Engineers, Part H: Journal of engineering in medicine, vol. 215, no. 3, pp. 285–290, 2001
work page 2001
-
[2]
V . Maheu, P. S. Archambault, J. Frappier, and F. Routhier, “Evalu- ation of the jaco robotic arm: Clinico-economic study for powered wheelchair users with upper-extremity disabilities,” in2011 IEEE international conference on rehabilitation robotics. IEEE, 2011, pp. 1–5
work page 2011
-
[3]
L. Petrich, J. Jin, M. Dehghan, and M. Jagersand, “A quantitative analysis of activities of daily living: Insights into improving functional independence with assistive robotics,” in2022 International Confer- ence on Robotics and Automation (ICRA), 2022, pp. 6999–7006
work page 2022
-
[4]
Wheelchair- mounted robotic arms: a survey of occupational therapists’ practices and perspectives,
J. Bourassa, J. Faieta, J. Bouffard, and F. Routhier, “Wheelchair- mounted robotic arms: a survey of occupational therapists’ practices and perspectives,”Disability and Rehabilitation: Assistive Technology, vol. 18, no. 8, pp. 1421–1430, 2023
work page 2023
-
[5]
Assistive tele- operation of robot arms via automatic time-optimal mode switching,
L. V . Herlant, R. M. Holladay, and S. S. Srinivasa, “Assistive tele- operation of robot arms via automatic time-optimal mode switching,” in2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI). IEEE, 2016, pp. 35–42
work page 2016
-
[6]
Centers for disease control and prevention
“Centers for disease control and prevention.” [Online]. Available: https://www.cdc.gov/dhds/about/index.html
-
[7]
Evaluation of new user interface features for the manus robot arm,
H. A. Tijsma, F. Liefhebber, and J. L. Herder, “Evaluation of new user interface features for the manus robot arm,” in9th International Conference on Rehabilitation Robotics, 2005. ICORR 2005.IEEE, 2005, pp. 258–263
work page 2005
-
[8]
Intuitive adaptive orientation control for enhanced human–robot interaction,
A. Campeau-Lecours, U. C ˆot´e-Allard, D.-S. Vu, F. Routhier, B. Gos- selin, and C. Gosselin, “Intuitive adaptive orientation control for enhanced human–robot interaction,”IEEE Transactions on robotics, vol. 35, no. 2, pp. 509–520, 2018
work page 2018
-
[9]
T. B. Sheridan,Telerobotics, automation, and human supervisory control. MIT press, 1992
work page 1992
-
[10]
Human-wheelchair collaboration through prediction of intention and adaptive assistance,
T. Carlson and Y . Demiris, “Human-wheelchair collaboration through prediction of intention and adaptive assistance,” in2008 IEEE inter- national conference on robotics and automation. IEEE, 2008, pp. 3926–3931
work page 2008
-
[11]
A policy-blending formalism for shared control,
A. D. Dragan and S. S. Srinivasa, “A policy-blending formalism for shared control,”The International Journal of Robotics Research, vol. 32, no. 7, pp. 790–805, 2013
work page 2013
-
[12]
Shared autonomy via hindsight optimization,
S. Javdani, S. S. Srinivasa, and J. A. Bagnell, “Shared autonomy via hindsight optimization,”Robotics science and systems: online proceedings, vol. 2015, pp. 10–15 607, 2015
work page 2015
-
[13]
Autonomy infused teleoperation with application to brain computer interface controlled manipulation,
K. Muelling, A. Venkatraman, J.-S. Valois, J. E. Downey, J. Weiss, S. Javdani, M. Hebert, A. B. Schwartz, J. L. Collinger, and J. A. Bagnell, “Autonomy infused teleoperation with application to brain computer interface controlled manipulation,”Autonomous Robots, vol. 41, no. 6, pp. 1401–1422, 2017
work page 2017
-
[14]
Learning Models for Shared Control of Human-Machine Systems with Unknown Dynamics
A. Broad, T. Murphey, and B. Argall, “Learning models for shared control of human-machine systems with unknown dynamics,”arXiv preprint arXiv:1808.08268, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Diffusion policy: Visuomotor policy learning via ac- tion diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via ac- tion diffusion,”The International Journal of Robotics Research, p. 02783649241273668, 2023
work page 2023
-
[16]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Z. Wang, J. J. Hunt, and M. Zhou, “Diffusion policies as an expres- sive policy class for offline reinforcement learning,”arXiv preprint arXiv:2208.06193, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Collaborative operation of robotic manipula- tors with human intent prediction and shared control,
Z. Jin and P. R. Pagilla, “Collaborative operation of robotic manipula- tors with human intent prediction and shared control,” in2020 IEEE International Conference on Human-Machine Systems (ICHMS), 2020, pp. 1–6
work page 2020
-
[18]
Asymmetric bilateral telerobotic system with shared autonomy control,
D. Sun and Q. Liao, “Asymmetric bilateral telerobotic system with shared autonomy control,”IEEE Transactions on Control Systems Technology, vol. 29, no. 5, pp. 1863–1876, 2021
work page 2021
-
[19]
Tasc: Task-aware shared con- trol for teleoperated manipulation,
Z. Fu, P. Song, Y . Hu, and R. Detry, “Tasc: Task-aware shared con- trol for teleoperated manipulation,”arXiv preprint arXiv:2509.10416, 2025
-
[20]
A topology of shared control systems—finding common ground in diversity,
D. A. Abbink, T. Carlson, M. Mulder, J. C. F. de Winter, F. Am- inravan, T. L. Gibo, and E. R. Boer, “A topology of shared control systems—finding common ground in diversity,”IEEE Transactions on Human-Machine Systems, vol. 48, no. 5, pp. 509–525, 2018
work page 2018
-
[21]
Path planning maximising human comfort for assistive robots,
P. Bevilacqua, M. Frego, E. Bertolazzi, D. Fontanelli, L. Palopoli, and F. Biral, “Path planning maximising human comfort for assistive robots,” in2016 IEEE conference on control applications (CCA). IEEE, 2016, pp. 1421–1427
work page 2016
-
[22]
Shared control templates for assistive robotics,
G. Quere, A. Hagengruber, M. Iskandar, S. Bustamante, D. Leidner, F. Stulp, and J. V ogel, “Shared control templates for assistive robotics,” in2020 IEEE international conference on robotics and automation (ICRA). IEEE, 2020, pp. 1956–1962
work page 2020
-
[23]
Human-intent detection and physically interactive control of a robot without force sensors,
M. S. Erden and T. Tomiyama, “Human-intent detection and physically interactive control of a robot without force sensors,”IEEE Transac- tions on Robotics, vol. 26, no. 2, pp. 370–382, 2010
work page 2010
-
[24]
Probabilistic human intent recognition for shared autonomy in assistive robotics,
S. Jain and B. Argall, “Probabilistic human intent recognition for shared autonomy in assistive robotics,”ACM Transactions on Human- Robot Interaction (THRI), vol. 9, no. 1, pp. 1–23, 2019
work page 2019
-
[25]
J. Storms, K. Chen, and D. Tilbury, “A shared control method for obstacle avoidance with mobile robots and its interaction with com- munication delay,”The International Journal of Robotics Research, vol. 36, no. 5-7, pp. 820–839, 2017
work page 2017
-
[26]
Learning state conditioned linear mappings for low-dimensional control of robotic manipulators,
M. Przystupa, K. Johnstonbaugh, Z. Zhang, L. Petrich, M. Dehghan, F. Haghverd, and M. Jagersand, “Learning state conditioned linear mappings for low-dimensional control of robotic manipulators,”arXiv preprint arXiv:2410.21441, 2024
-
[27]
Behavioral Cloning from Observation
F. Torabi, G. Warnell, and P. Stone, “Behavioral cloning from obser- vation,”arXiv preprint arXiv:1805.01954, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın, “What matters in learning from offline human demonstrations for robot manipula- tion,”arXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Exploring the limitations of behavior cloning for autonomous driving,
F. Codevilla, E. Santana, A. M. L ´opez, and A. Gaidon, “Exploring the limitations of behavior cloning for autonomous driving,” inProceed- ings of the IEEE/CVF international conference on computer vision, 2019, pp. 9329–9338
work page 2019
-
[30]
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson, “Implicit behavioral cloning,” inConference on robot learning. PMLR, 2022, pp. 158– 168
work page 2022
-
[31]
J. Mahler, J. Liang, S. Niyaz, M. Laskey, R. Doan, X. Liu, J. A. Ojea, and K. Goldberg, “Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics,”arXiv preprint arXiv:1703.09312, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Grasp pose detection in point clouds,
A. Ten Pas, M. Gualtieri, K. Saenko, and R. Platt, “Grasp pose detection in point clouds,”The International Journal of Robotics Research, vol. 36, no. 13-14, pp. 1455–1473, 2017
work page 2017
-
[33]
The sense of agency in assistive robotics using shared autonomy,
M. A. Collier, R. Narayan, and H. Admoni, “The sense of agency in assistive robotics using shared autonomy,” in2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI). IEEE, 2025, pp. 880–888
work page 2025
-
[34]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
work page 2020
-
[35]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,”arXiv preprint arXiv:2403.03954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Conditional denoising diffusion for sequential recommendation,
Y . Wang, Z. Liu, L. Yang, and P. S. Yu, “Conditional denoising diffusion for sequential recommendation,” inPacific-Asia conference on knowledge discovery and data mining. Springer, 2024, pp. 156– 169
work page 2024
-
[37]
Conditional image synthesis with diffusion models: A survey,
Z. Zhan, D. Chen, J.-P. Mei, Z. Zhao, J. Chen, C. Chen, S. Lyu, and C. Wang, “Conditional image synthesis with diffusion models: A survey,”arXiv preprint arXiv:2409.19365, 2024
-
[38]
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki, “3d diffuser ac- tor: Policy diffusion with 3d scene representations,”arXiv preprint arXiv:2402.10885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660
work page 2017
-
[40]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,”arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[41]
Point and go: Intuitive reference frame reallocation in mode switching for assistive robotics,
A. Wang, C. Jiang, M. Przystupa, J. Valentine, and M. Jagersand, “Point and go: Intuitive reference frame reallocation in mode switching for assistive robotics,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 1–7
work page 2025
-
[42]
Development of nasa-tlx (task load index): Results of empirical and theoretical research,
S. G. Hart and L. E. Staveland, “Development of nasa-tlx (task load index): Results of empirical and theoretical research,” inAdvances in psychology. Elsevier, 1988, vol. 52, pp. 139–183
work page 1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.