Hierarchical Semantic-Augmented Navigation: Optimal Transport and Graph-Driven Reasoning for Vision-Language Navigation
Pith reviewed 2026-06-28 14:47 UTC · model grok-4.3
The pith
A hierarchical semantic scene graph plus optimal transport planning improves success in language-guided indoor navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
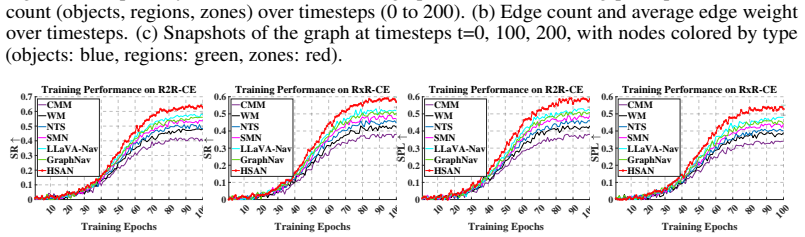
The central claim is that a dynamic hierarchical semantic scene graph built with vision-language models, paired with an optimal transport topological planner grounded in Kantorovich duality for goal selection and a graph-aware reinforcement learning policy for low-level actions, produces state-of-the-art navigation success and better generalization on VLN-CE benchmarks by supplying richer spatial reasoning and more reliable planning than static-map or heuristic baselines.
What carries the argument
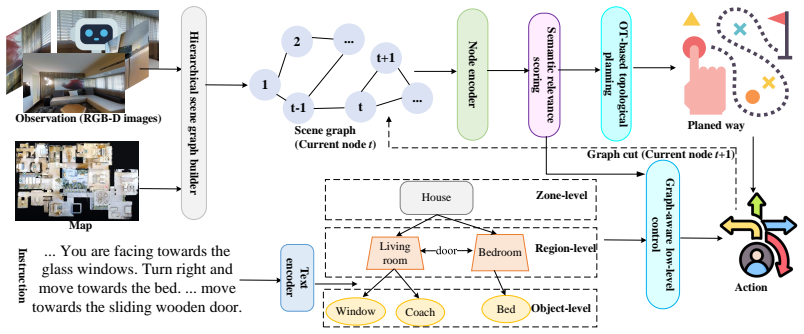
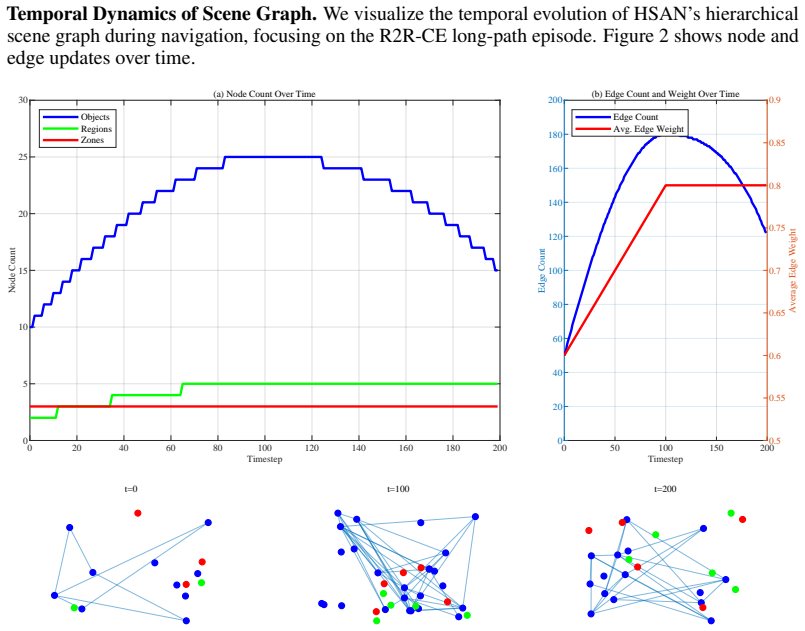
The hierarchical semantic scene graph that encodes multi-level representations from objects to regions to zones, which feeds the optimal transport planner that balances semantic relevance against spatial accessibility.
If this is right
- Navigation success and SPL scores rise on standard VLN-CE benchmarks.
- The system generalizes better to environments not seen during training.
- Goal selection carries formal optimality guarantees from the transport formulation.
- Low-level control avoids obstacles more reliably through the graph policy.
Where Pith is reading between the lines
- The same graph-plus-transport structure could be tested on related tasks such as object search or instruction following in larger buildings.
- Replacing the vision-language model backbone with a stronger future model would be a direct way to measure how much the semantic layer limits overall performance.
- Real-robot deployment would reveal whether simulation gains survive sensor noise and dynamics mismatch.
Load-bearing premise
Vision-language models can build accurate enough multi-level semantic maps to support reliable spatial reasoning and goal selection.
What would settle it
Running the full HSAN pipeline on a held-out VLN-CE test set and finding no statistically significant gain in success rate or SPL over strong baselines would falsify the performance claim.
Figures
read the original abstract
Vision-Language Navigation in Continuous Environments (VLN-CE) poses a formidable challenge for autonomous agents, requiring seamless integration of natural language instructions and visual observations to navigate complex 3D indoor spaces. Existing approaches often falter in long-horizon tasks due to limited scene understanding, inefficient planning, and lack of robust decision-making frameworks. We introduce the \textbf{Hierarchical Semantic-Augmented Navigation (HSAN)} framework, a groundbreaking approach that redefines VLN-CE through three synergistic innovations. First, HSAN constructs a dynamic hierarchical semantic scene graph, leveraging vision-language models to capture multi-level environmental representations, from objects to regions to zones, enabling nuanced spatial reasoning. Second, it employs an optimal transport-based topological planner, grounded in Kantorovich's duality, to select long-term goals by balancing semantic relevance and spatial accessibility with theoretical guarantees of optimality. Third, a graph-aware reinforcement learning policy ensures precise low-level control, navigating subgoals while robustly avoiding obstacles. By integrating spectral graph theory, optimal transport, and advanced multi-modal learning, HSAN addresses the shortcomings of static maps and heuristic planners prevalent in prior work. Extensive experiments on multiple challenging VLN-CE datasets demonstrate that HSAN achieves state-of-the-art performance, with significant improvements in navigation success and generalization to unseen environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Hierarchical Semantic-Augmented Navigation (HSAN) for Vision-Language Navigation in Continuous Environments (VLN-CE). The framework comprises three components: a dynamic hierarchical semantic scene graph built from vision-language models (objects to regions to zones), an optimal transport topological planner grounded in Kantorovich duality for long-term goal selection with claimed optimality guarantees, and a graph-aware reinforcement learning policy for low-level obstacle-avoiding control. The central claim is that the integration yields state-of-the-art navigation success rates and improved generalization on multiple VLN-CE datasets.
Significance. If the empirical SOTA results and the optimality guarantees are substantiated, the work would offer a principled combination of multi-level semantic reasoning, optimal transport, and graph-structured RL that could meaningfully advance long-horizon VLN-CE by reducing reliance on static maps and heuristics.
Simulated Author's Rebuttal
We thank the referee for their summary of the HSAN framework. The report does not enumerate any specific major comments, so we have no individual points to address at this time. We remain available to substantiate the reported SOTA results or the optimality guarantees from the Kantorovich duality formulation if the referee provides further questions.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description outline a framework combining VLM-based hierarchical graphs, optimal transport planning via Kantorovich duality (a standard external theorem), and graph-aware RL. No equations, derivations, or self-citations are exhibited that reduce any claimed prediction or optimality result to a fitted input or prior self-result by construction. The central claims rest on empirical evaluation on standard VLN-CE datasets and integration of independent components, making the derivation self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Point clouds meets physics: Dynamic acoustic field fitting network for point cloud understanding
Changshuo Wang, Shuting He, Xiang Fang, Jiawei Han, Zhonghang Liu, Xin Ning, Weijun Li, and Prayag Tiwari. Point clouds meets physics: Dynamic acoustic field fitting network for point cloud understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22182–22192, 2025b. Xiang Fang, Arvind Easwaran, Blaise Genest, and Ponnu...
2024
-
[2]
Slap: The semantic least action principle for variational video- language modeling
Xiang Fang and Wanlong Fang. Slap: The semantic least action principle for variational video- language modeling. InInternational Conference on Machine Learning, 2026a. Changshuo Wang, Shuting He, Xiang Fang, Zhijian Hu, Jia-Hong Huang, Yixian Shen, and Prayag Tiwari. Reasoning beyond points: A visual introspective approach for few-shot 3d segmentation. Ad...
2025
-
[3]
Rethinking video- language model from the language input perspective
Xiang Fang, Wanlong Fang, Changshuo Wang, Xiaoye Qu, and Daizong Liu. Rethinking video- language model from the language input perspective. InProceedings of the AAAI Conference on Artificial Intelligence, 2026e. Changshuo Wang, Shuting He, Xiang Fang, Fangzhe Nan, and Prayag Tiwari. Seeing the overlooked: Bio-visual inspired weak saliency feedback transfo...
2023
-
[4]
Xiang Fang, Yuchong Hu, Pan Zhou, and Dapeng Oliver Wu. Unbalanced incomplete multi-view clustering via the scheme of view evolution: Weak views are meat; strong views do eat.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(4):913–927, 2021a. Junyi Wang, Jinjiang Li, Guodong Fan, Yakun Ju, Xiang Fang, and Alex C Kot. Prototype-driven ...
2024
-
[5]
Bangguo Yu, Yuzhen Liu, Lei Han, Hamidreza Kasaei, Tingguang Li, and Ming Cao. Vln- game: Vision-language equilibrium search for zero-shot semantic navigation.arXiv preprint arXiv:2411.11609,
-
[6]
Navigating the nuances: A fine-grained evaluation of vision-language navigation
Zehao Wang, Minye Wu, Yixin Cao, Yubo Ma, Meiqi Chen, and Tinne Tuytelaars. Navigating the nuances: A fine-grained evaluation of vision-language navigation. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4681–4704,
2024
-
[7]
Learning affordance landscapes for interaction exploration in 3d environments.Advances in Neural Information Processing Systems, 33:2005–2015,
Tushar Nagarajan and Kristen Grauman. Learning affordance landscapes for interaction exploration in 3d environments.Advances in Neural Information Processing Systems, 33:2005–2015,
2005
-
[8]
Beyond the nav-graph: Vision-and-language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language navigation in continuous environments. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16, pages 104–120. Springer,
2020
-
[9]
Navila: Legged robot vision-language-action model for navigation.arXiv preprint arXiv:2412.04453,
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, and Xiaolong Wang. Navila: Legged robot vision-language-action model for navigation.arXiv preprint arXiv:2412.04453,
-
[10]
Chengguang Xu, Hieu T Nguyen, Christopher Amato, and Lawson LS Wong. Vision and language navigation in the real world via online visual language mapping.arXiv preprint arXiv:2310.10822,
-
[11]
Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding
Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4392–4412,
2020
-
[12]
Devendra Singh Chaplot, Ruslan Salakhutdinov, Abhinav Gupta, and Saurabh Gupta
doi: 10.1109/ 3DV .2017.00081. Devendra Singh Chaplot, Ruslan Salakhutdinov, Abhinav Gupta, and Saurabh Gupta. Neural topological slam for visual navigation.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 12875–12884,
arXiv 2017
-
[13]
doi: 10.1109/CVPR42600.2020. 01289. Siying Wu, Xueyang Fu, Feng Wu, and Zheng-Jun Zha. Vision-and-language navigation via latent semantic alignment learning.IEEE Transactions on Multimedia, 26:8406–8418,
-
[14]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[15]
Proximal Policy Optimization Algorithms
doi: 10.48550/arXiv.1707.06347. Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning.Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS), pages 627–635,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347
-
[16]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR)
doi: 10.1109/CVPR52688. 2022.01503. Benjamin Kuipers. The spatial semantic hierarchy.Artificial Intelligence, 119(1-2):191–233,
-
[17]
Shizhe Chen, Pierre-Luc Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev
doi: 10.1016/S0004-3702(00)00017-5. Shizhe Chen, Pierre-Luc Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Think global, act local: Dual-scale graph transformer for vision-and-language navigation.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 16537–16547,
-
[18]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
doi: 10.1109/CVPR52688.2022.01606. Cédric Villani.Optimal Transport: Old and New. Springer Science & Business Media,
-
[19]
Springer, Berlin, Heidelberg, 2009
doi: 10.1007/978-3-540-71050-9. Jacob Krantz, Arjun Majumdar, and Stefan Lee. Sim-to-real transfer for vision-and-language navigation.Conference on Robot Learning (CoRL), pages 1789–1799,
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
doi: 10.1109/ICCV .2019.00943. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision.International Conference on Machine Learning (ICML), pages 8748–8763,
-
[21]
Sigmoid loss for language- image pre-training.arXiv preprint arXiv:2303.15343,
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language- image pre-training.arXiv preprint arXiv:2303.15343,
-
[22]
Sigmoid Loss for Language Image Pre-Training
doi: 10.48550/arXiv.2303.15343. Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Dhruv Batra, and Gaurav S. Sukhatme. Improving vision-and-language navigation with image-text pairs from the web. European Conference on Computer Vision (ECCV), pages 259–274,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.15343
-
[23]
Deep Residual Learning for Image Recognition
doi: 10.1109/CVPR. 2018.00387. Shizhe Chen, Pierre-Luc Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-and-language navigation.Advances in Neural Information Processing Systems (NeurIPS), 34:2554–2567, 2021a. Kevin Chen, Junshen K Chen, Jo Chuang, Marynel Vázquez, and Silvio Savarese. Topological planning with tran...
-
[24]
Jacob Devlin Ming-Wei Chang Kenton and Kristina Toutanova Lee. Bert: Pre-training of deep bidirectional transformers for language understanding.Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186,
2019
-
[25]
NeMo guardrails: A toolkit for controllable and safe LLM applications with pro- grammable rails
doi: 10.18653/v1/ N19-1423. NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: Yes, the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope. They provide a clear overview...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.