Real-time body pose non-verbal communication with a consistency-based reliability measure
Pith reviewed 2026-06-27 17:22 UTC · model grok-4.3
The pith
A model's autoregressive self-consistency acts as an unsupervised reliability signal for body-pose communicative intent recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
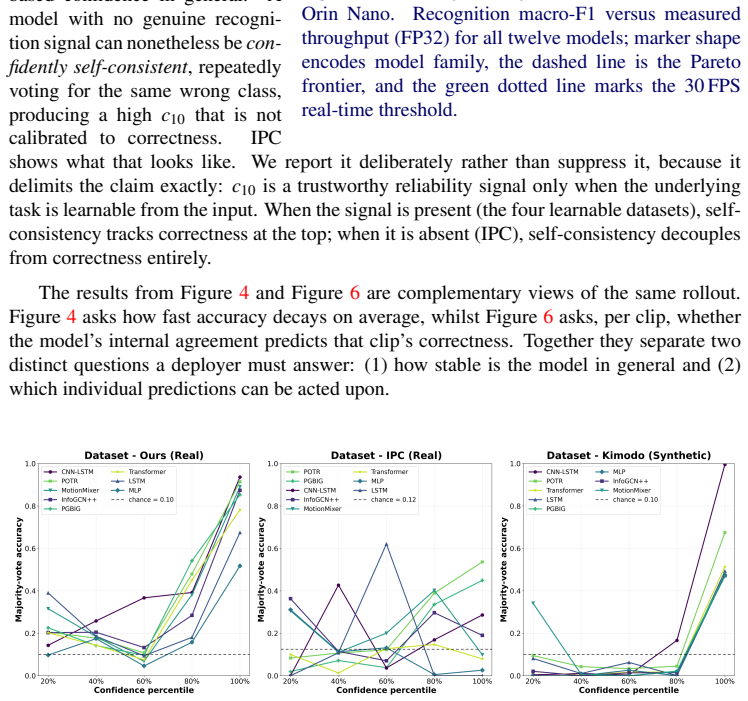
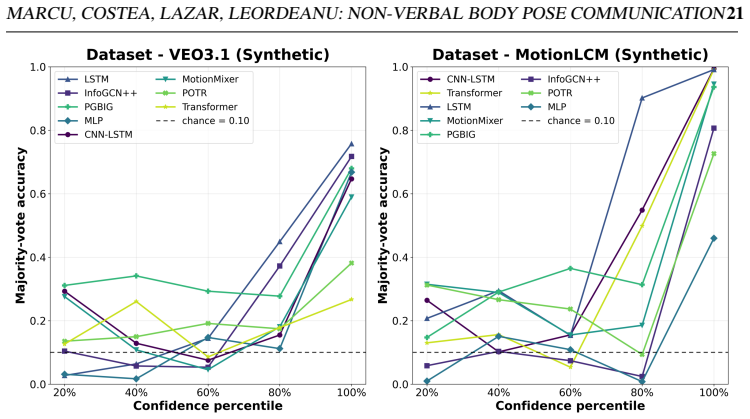
The central discovery is that for autoregressive models on body pose sequences, the probability a self-consistent prediction is correct is bounded below by a function that increases with the number of consistent steps, proven in a short argument, while identifying cases where confident but incorrect predictions remain possible.
What carries the argument
The autoregressive self-consistency reliability measure, which uses repeated consistent predictions to bound correctness probability without supervision.
If this is right
- Self-consistent predictions have a provably higher chance of being correct than inconsistent ones.
- The bound strengthens as more autoregressive steps remain consistent.
- Real-time performance is achievable on embedded hardware like the NVIDIA Orin Nano.
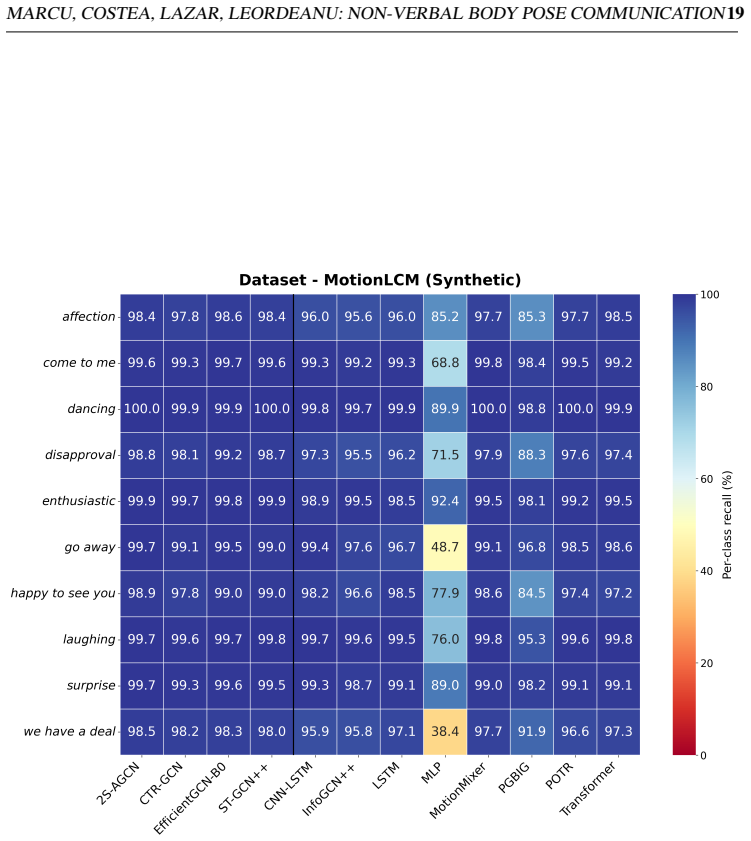
- Body pose alone isolates the signal for the ten intents in the new dataset.
- Industry-standard metrics can be compared directly to this consistency-based signal.
Where Pith is reading between the lines
- The approach may apply to other sequence-based prediction tasks where ground truth is hard to obtain.
- It could enable safer deployment in rescue scenarios by flagging unreliable predictions on the device.
- Extensions might test the bound under varying hardware constraints or pose estimation noise.
- Neighboring problems like action recognition could adopt similar consistency checks for reliability.
Load-bearing premise
Sequences of body pose alone contain enough unambiguous information to distinguish the ten communicative intents without needing face, voice, or additional context.
What would settle it
A real-world test on embedded hardware where the fraction of incorrect self-consistent predictions exceeds the theoretical upper bound given by the proof.
Figures

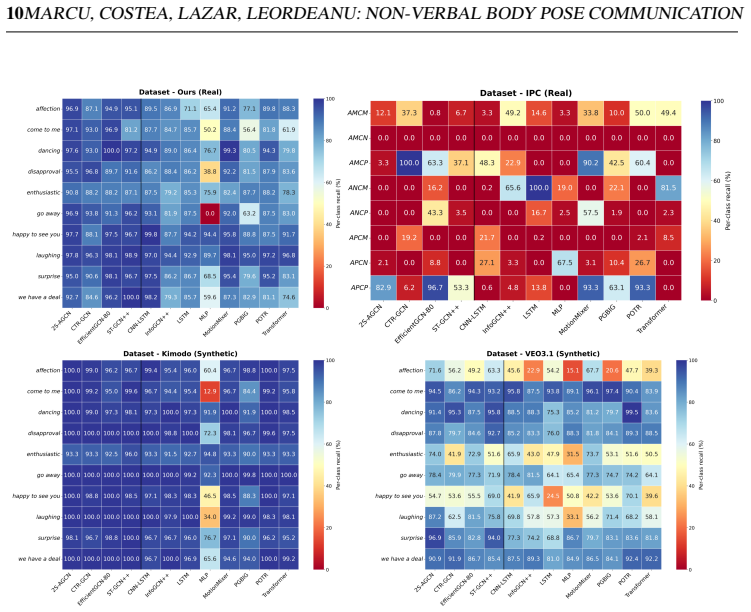
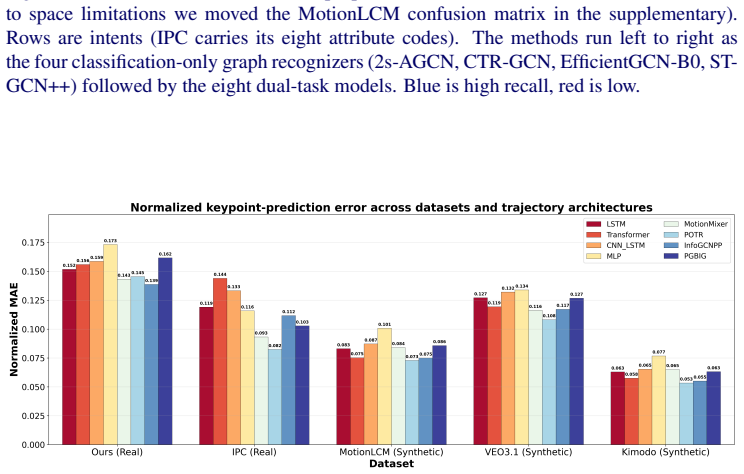
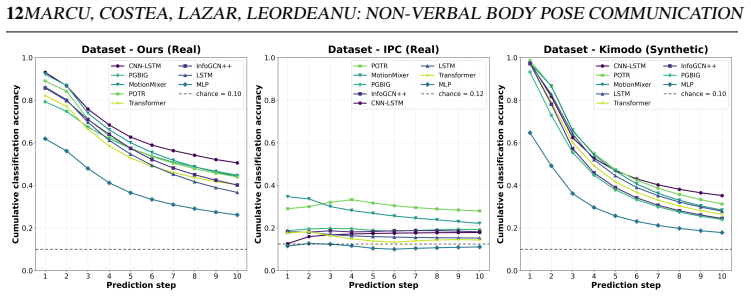
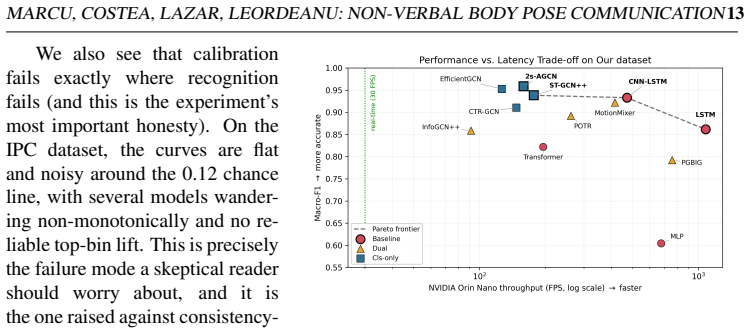






read the original abstract
Body movement communicates intent at distances and in conditions where neither the face, nor speech can be captured. We study the recognition of communicative intent from 2D body pose alone. We argue that body motion is a reliable signal especially in scenarios that require real time low-cost on-device person-to-robot communication in long distance environments, such as rescue missions. However, existing resources do not isolate this signal. Affective corpora combine body, face, voice and text, while skeleton action-recognition benchmarks label the action performed rather than the message conveyed. We release a dataset of real frames of full-body pose covering ten communicative intents and we compare it against other real (IPC) and synthetic (MotionLCM, VEO3.1, Kimodo) ones that span a range of difficulty. We target systems that can run on a robot's limited onboard hardware. We benchmark multiple models, from skeleton graph classifiers to joint motion-forecasting networks, and report performance metrics together with frame rate on an embedded GPU (NVIDIA Orin~Nano), since speed matters as much as accuracy in our scenario. Finally, we show that a model's own autoregressive self-consistency works as an unsupervised reliability signal. We give a short proof that bounds the probability that a self-consistent prediction is correct, show that this probability grows with the number of consistent steps, and identify the conditions under which a confident prediction can still be false, benchmarked against industry-standard metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that communicative intent can be recognized from 2D body pose sequences alone, releases a new dataset of real frames covering ten intents (compared against IPC, MotionLCM, VEO3.1, and Kimodo), benchmarks skeleton graph classifiers and joint motion-forecasting networks for accuracy and frame rate on an NVIDIA Orin Nano, and introduces an autoregressive self-consistency reliability signal together with a short proof that bounds P(correct | k consistent steps), shows the bound increases with k, and identifies conditions under which a confident prediction can still be false.
Significance. If the bound is valid and the modeling assumptions survive deployment, the unsupervised reliability signal would be a useful addition for real-time, on-device intent recognition where face/voice are unavailable. Dataset release and embedded-hardware benchmarks are concrete strengths that support the target use case of person-to-robot communication.
major comments (2)
- [reliability measure and proof] The short proof bounding P(correct | k consistent steps) (final paragraph of the abstract and the reliability section) assumes idealized autoregression whose conditional independence or dynamics-matching properties are not shown to survive the low-precision, real-time regime on the Orin Nano; correlated joint-angle or velocity drift would produce spurious consistency exactly in the regime the paper flags as possible but does not quantify.
- [experimental results] Table or figure reporting the reliability experiments (industry-standard metrics comparison) does not include a direct empirical check of the derived bound against observed correctness rates under the same hardware constraints used for the frame-rate numbers, leaving the claim that the probability grows with k unverified in the reported deployment setting.
minor comments (2)
- The abstract states performance metrics and frame rates are reported but supplies neither the equations for the bound nor any numerical results or tables, preventing assessment of effect sizes or whether post-hoc choices affect the numbers.
- Clarify the precise labeling protocol for the ten communicative intents and whether body-pose sequences alone were judged sufficient by multiple annotators without face or context cues.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the reliability measure and its validation. We address the two major comments point by point below.
read point-by-point responses
-
Referee: The short proof bounding P(correct | k consistent steps) (final paragraph of the abstract and the reliability section) assumes idealized autoregression whose conditional independence or dynamics-matching properties are not shown to survive the low-precision, real-time regime on the Orin Nano; correlated joint-angle or velocity drift would produce spurious consistency exactly in the regime the paper flags as possible but does not quantify.
Authors: The bound is derived from the observed sequence of model predictions under autoregression and holds mathematically under the stated conditions. We acknowledge that the manuscript does not empirically quantify the effect of low-precision drift or correlated errors on the Orin Nano. We will add a dedicated paragraph in the reliability section discussing these hardware-specific factors and include new experiments measuring consistency under FP16/INT8 inference on the target device. revision: yes
-
Referee: Table or figure reporting the reliability experiments (industry-standard metrics comparison) does not include a direct empirical check of the derived bound against observed correctness rates under the same hardware constraints used for the frame-rate numbers, leaving the claim that the probability grows with k unverified in the reported deployment setting.
Authors: We agree that a direct comparison of the theoretical bound to measured correctness rates on the Orin Nano is missing. We will revise the reliability experiments section to add a table (or figure) that reports observed P(correct) for increasing k under the identical hardware and precision settings used for the frame-rate benchmarks, thereby verifying the growth of the bound in the deployment regime. revision: yes
Circularity Check
No significant circularity detected in the consistency bound derivation
full rationale
The paper introduces an autoregressive self-consistency reliability signal and supplies a short proof bounding P(correct | k consistent steps). No load-bearing self-citations, fitted-parameter renamings, or definitional loops are described; the bound is presented as derived from modeling assumptions on the forecast process rather than reducing tautologically to the input predictions themselves. The derivation remains self-contained because the proof is offered as an independent mathematical result with explicit conditions for when it may fail, separate from the dataset labeling or hardware benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vasu Agrawal et al. Seamless interaction: Dyadic audiovisual motion modeling and large-scale dataset.arXiv preprint arXiv:2506.22554, 2025
arXiv 2025
-
[2]
Introducing the Geneva Multimodal Expression corpus for experimental research on emotion perception.Emo- tion, 12(5):1161–1179, 2012
Tanja Bänziger, Marcello Mortillaro, and Klaus R Scherer. Introducing the Geneva Multimodal Expression corpus for experimental research on emotion perception.Emo- tion, 12(5):1161–1179, 2012
2012
-
[3]
MotionMixer: Mlp-based 3d human body pose forecasting
Arij Bouazizi, Adrian Holzbock, Ulrich Kressel, Klaus Dietmayer, and Vasileios Bela- giannis. MotionMixer: Mlp-based 3d human body pose forecasting. InProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2022
2022
-
[4]
Iemocap: Inter- active emotional dyadic motion capture database.Language resources and evaluation, 42:335–359, 2008
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N Chang, Sungbok Lee, and Shrikanth S Narayanan. Iemocap: Inter- active emotional dyadic motion capture database.Language resources and evaluation, 42:335–359, 2008
2008
-
[5]
First impressions in human–agent virtual encounters.ACM Transactions on Computer-Human Interac- tion (TOCHI), 23(4):1–40, 2016
Angelo Cafaro, Hannes Högni Vilhjálmsson, and Timothy Bickmore. First impressions in human–agent virtual encounters.ACM Transactions on Computer-Human Interac- tion (TOCHI), 23(4):1–40, 2016
2016
-
[6]
SAM 3: Segment any- thing with concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Rong- hang Hu, Didac Surís, Chaitanya Ryali, et al. SAM 3: Segment any- thing with concepts. Technical report, Meta Superintelligence Labs, Novem- ber 2025. URLhttps://ai.meta.com/research/publications/ sam-3-segment-anything-with-concepts/. 28MARCU, COSTEA, LAZAR, LEORDEANU: NON-VERBAL BODY...
2025
-
[7]
Drone & me: An exploration into natural human–drone interaction
Jessica R Cauchard, Jane L E, Kevin Y Zhai, and James A Landay. Drone & me: An exploration into natural human–drone interaction. InProceedings of the ACM Inter- national Joint Conference on Pervasive and Ubiquitous Computing (UbiComp), pages 361–365. ACM, 2015
2015
-
[8]
Channel-wise topology refinement graph convolution for skeleton-based action recog- nition
Yuxin Chen, Ziqi Zhang, Chunfeng Yuan, Bing Li, Ying Deng, and Weiming Hu. Channel-wise topology refinement graph convolution for skeleton-based action recog- nition. InICCV, pages 13359–13368, 2021
2021
-
[9]
Hyung-gun Chi, Seunggeun Chi, Stanley Chan, and Karthik Ramani. InfoGCN++: Learning representation by predicting the future for online skeleton-based action recog- nition.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
2025
-
[10]
Emotions and non-verbal behaviour in human-computer interactions
Teodora Cristescu and Katherine Isbister. Emotions and non-verbal behaviour in human-computer interactions. In2008 10th International Conference on Development and Application Systems, pages 68–73. IEEE, 2008
2008
-
[11]
Motionlcm: Real-time controllable motion generation via latent consistency model
Wenxun Dai, Ling-Hao Chen, Jingbo Wang, Jinpeng Liu, Bo Dai, and Yansong Tang. Motionlcm: Real-time controllable motion generation via latent consistency model. arXiv preprint arXiv:2404.19759, 2024
arXiv 2024
-
[12]
PYSKL: Towards good prac- tices for skeleton action recognition
Haodong Duan, Jiaqi Wang, Kai Chen, and Dahua Lin. PYSKL: Towards good prac- tices for skeleton action recognition. InProceedings of the ACM International Confer- ence on Multimedia (ACM MM), 2022
2022
-
[13]
Dropout as a Bayesian approximation: Represent- ing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a Bayesian approximation: Represent- ing model uncertainty in deep learning. InICML, pages 1050–1059, 2016
2016
-
[14]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. InNeurIPS, pages 4878–4887, 2017
2017
-
[15]
Bias-reduced uncertainty estimation for deep neural classifiers
Yonatan Geifman, Guy Uziel, and Ran El-Yaniv. Bias-reduced uncertainty estimation for deep neural classifiers. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[16]
Veo: a state-of-the-art model for video generation.https:// deepmind.google/technologies/veo/, May 2024
Google DeepMind. Veo: a state-of-the-art model for video generation.https:// deepmind.google/technologies/veo/, May 2024. Last accessed: 2026-02- 12
2024
-
[17]
Google DeepMind. Veo 3.1: Improved text-to-video generation with native audio and narrative control.https://developers.googleblog.com/ introducing-veo-3-1-and-new-creative-capabilities-in-the-gemini-api/, October 2025. Released 15 October 2025 via the Gemini API
2025
-
[18]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InICML, pages 1321–1330, 2017
2017
-
[19]
Using transformers for multimodal emotion recognition.Engi- neering Applications of Artificial Intelligence, 133, 2024
Soufiane Hazmoune. Using transformers for multimodal emotion recognition.Engi- neering Applications of Artificial Intelligence, 133, 2024
2024
-
[20]
Ultralytics YOLO11, 2024
Glenn Jocher and Jing Qiu. Ultralytics YOLO11, 2024. URLhttps://github. com/ultralytics/ultralytics. MARCU, COSTEA, LAZAR, LEORDEANU: NON-VERBAL BODY POSE COMMUNICA TION29
2024
-
[21]
Cotracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker: It is better to track together. InEuropean confer- ence on computer vision, pages 18–35. Springer, 2024
2024
-
[22]
Jeonghyeon Kim et al. A human-following drone providing gesture recognition to control IoT devices based on 3D body-landmark detection.International Journal of Control, Automation and Systems, 2025. doi: 10.1007/s12555-025-0012-y
-
[23]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ra- manan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[24]
NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding
Jun Liu, Amir Shahroudy, Mauricio Perez, Gang Wang, Ling-Yu Duan, and Alex C Kot. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(10):2684–2701, 2020
2020
-
[25]
Kenneth D. Locke. Circumplex measures of interpersonal constructs. In Leonard M. Horowitz and Stephen Strack, editors,Handbook of Interpersonal Psychology: Theory, Research, Assessment, and Therapeutic Interventions, pages 313–324. Wiley, Hobo- ken, NJ, 2011. doi: 10.1002/9781118001868.ch19
-
[26]
An open framework for nonverbal communication in human-robot interaction
Ernesto A Lozano, Carlos E Sánchez-Torres, Irvin H López-Nava, and Jesús Favela. An open framework for nonverbal communication in human-robot interaction. InInterna- tional Conference on Ubiquitous Computing and Ambient Intelligence, pages 21–32. Springer, 2023
2023
-
[27]
Pro- gressively generating better initial guesses towards next stages for high-quality human motion prediction
Tiezheng Ma, Yongwei Nie, Chengjiang Long, Qing Zhang, and Guiqing Li. Pro- gressively generating better initial guesses towards next stages for high-quality human motion prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[28]
Amass: Archive of motion capture as surface shape
Naureen Mahmood, Nima Ghorbani, Nikolaus Farsa, Oncel Tuzel, and Michael J Black. Amass: Archive of motion capture as surface shape. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5442–5451, 2019
2019
-
[29]
Pose trans- formers (POTR): Human motion prediction with non-autoregressive transformers
Angel Martínez-González, Michael Villamizar, and Jean-Marc Odobez. Pose trans- formers (POTR): Human motion prediction with non-autoregressive transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision Work- shops (ICCVW), 2021
2021
-
[30]
Survey on emotional body gesture recognition
Fatemeh Noroozi, Dorota Kaminska, Ciprian Corneanu, Tomasz Sapinski, Sergio Es- calera, and Gholamreza Anbarjafari. Survey on emotional body gesture recognition. IEEE Transactions on Affective Computing, 12(2):505–523, 2021
2021
-
[31]
Automatic differentiation in pytorch, 2017
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch, 2017
2017
-
[32]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10975–10985, 2019. 30MARCU, COSTEA, LAZAR, LEORDEANU: NON-VERBAL BODY POSE COMMU...
2019
-
[33]
Real-time human detection and gesture recognition for on-board UA V rescue.Sensors, 21(6): 2180, 2021
Asanka G Perera, Yee Wei Law, Titilayo T Ogunwa, and Javaan Chahl. Real-time human detection and gesture recognition for on-board UA V rescue.Sensors, 21(6): 2180, 2021
2021
-
[34]
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cam- bria, and Rada Mihalcea. Meld: A multimodal multi-party dataset for emotion recog- nition in conversations.arXiv preprint arXiv:1810.02508, 2018
Pith/arXiv arXiv 2018
-
[35]
Kimodo: Scaling controllable human motion generation.arXiv preprint arXiv:2603.15546, 2026
Davis Rempe, Mathis Petrovich, Ye Yuan, Haotian Zhang, Xue Bin Peng, Yifeng Jiang, Tingwu Wang, Umar Iqbal, David Minor, Michael de Ruyter, Jiefeng Li, Chen Tessler, Edy Lim, Eugene Jeong, Sam Wu, Ehsan Hassani, Michael Huang, Jin-Bey Yu, Chaeyeon Chung, Lina Song, Olivier Dionne, Jan Kautz, Simon Yuen, and Sanja Fidler. Kimodo: Scaling controllable human...
arXiv 2026
-
[36]
Emotion recognition from facial images, body gestures, and skeletal posture keypoints: The ber2024 dataset.Computer Methods and Programs in Biomedicine, 2024
Fernando Pujaico Rivera, Paulo Sergio Rodrigues, and Oscar Eduardo Hidetoshi Fugita. Emotion recognition from facial images, body gestures, and skeletal posture keypoints: The ber2024 dataset.Computer Methods and Programs in Biomedicine, 2024
2024
-
[37]
Robots with dif- ferent non-verbal communication styles: How the way a robot gestures, moves and looks affects people’s ratings of the robot’s social qualities
Sam Saunderson, Chrystopher L Nehaniv, and Kerstin Dautenhahn. Robots with dif- ferent non-verbal communication styles: How the way a robot gestures, moves and looks affects people’s ratings of the robot’s social qualities. InCompanion of the 2019 ACM/IEEE International Conference on Human-Robot Interaction, pages 551–559, 2019
2019
-
[38]
Two-stream adaptive graph convolutional networks for skeleton-based action recognition
Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12026–12035, 2019
2019
-
[39]
Two-stream adaptive graph convo- lutional networks for skeleton-based action recognition
Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Two-stream adaptive graph convo- lutional networks for skeleton-based action recognition. InCVPR, pages 12026–12035, 2019
2019
-
[40]
Soohyun Shin, Trevor Evetts, Hunter Saylor, Hyunji Kim, Soojin Woo, Wonhwha Rhee, and Seong-Woo Kim. Skybound magic: Enabling body-only drone piloting through a lightweight vision–pose interaction framework.International Journal of Human–Computer Interaction, 2025. doi: 10.1080/10447318.2025.2546039
-
[41]
Constructing stronger and faster baselines for skeleton-based action recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
Yi-Fan Song, Zhang Zhang, Caifeng Shan, and Liang Wang. Constructing stronger and faster baselines for skeleton-based action recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
2022
-
[42]
Natural user interfaces for human-drone multi-modal interaction
Roberto Suarez-Fernandez, Jose Luis Sanchez-Lopez, Carlos Sampedro, Hriday Bavle, Martin Molina, and Pascual Campoy. Natural user interfaces for human-drone multi-modal interaction. InInternational Conference on Unmanned Aircraft Systems (ICUAS), pages 1013–1022. IEEE, 2016. MARCU, COSTEA, LAZAR, LEORDEANU: NON-VERBAL BODY POSE COMMUNICA TION31
2016
-
[43]
Nonverbal cues in human–robot interaction: A communication studies perspective.ACM Transactions on Human-Robot Interaction, 12(2):1–21, 2023
Jacqueline Urakami and Katie Seaborn. Nonverbal cues in human–robot interaction: A communication studies perspective.ACM Transactions on Human-Robot Interaction, 12(2):1–21, 2023
2023
-
[44]
MoGe-2: Accurate monocular geom- etry with metric scale and sharp details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. MoGe-2: Accurate monocular geom- etry with metric scale and sharp details. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[45]
Jerry S. Wiggins. A psychological taxonomy of trait-descriptive terms: The interper- sonal domain.Journal of Personality and Social Psychology, 37(3):395–412, 1979. doi: 10.1037/0022-3514.37.3.395
-
[46]
ViTPose++: Vision trans- former for generic body pose estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(2):1212–1230, 2024
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. ViTPose++: Vision trans- former for generic body pose estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(2):1212–1230, 2024
2024
-
[47]
Spatial temporal graph convolutional net- works for skeleton-based action recognition
Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial temporal graph convolutional net- works for skeleton-based action recognition. InAAAI, pages 7444–7452, 2018
2018
-
[48]
Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph
Amir Zadeh, Paul Pu Liang, Soujanya Poria Mazumder, Erik Cambria, and Louis- Philippe Morency. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph. InACL, pages 2236–2246, 2018
2018
-
[49]
The moving pose: An efficient 3d kinematics descriptor for low-latency action recognition and detection
Mihai Zanfir, Marius Leordeanu, and Cristian Sminchisescu. The moving pose: An efficient 3d kinematics descriptor for low-latency action recognition and detection. In Proceedings of the IEEE international conference on computer vision, pages 2752– 2759, 2013
2013
-
[50]
MotionBERT: A unified perspective on learning human motion representations
Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. MotionBERT: A unified perspective on learning human motion representations. In ICCV, pages 15085–15099, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.