From I/O to Code with Discovery Agent
Pith reviewed 2026-05-19 15:56 UTC · model grok-4.3
pith:2QQIH7EN Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{2QQIH7EN}
Prints a linked pith:2QQIH7EN badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
DIO-Agent synthesizes code from input-output examples by framing the task as evolutionary search with an LLM mutation operator guided by a simplicity-first bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
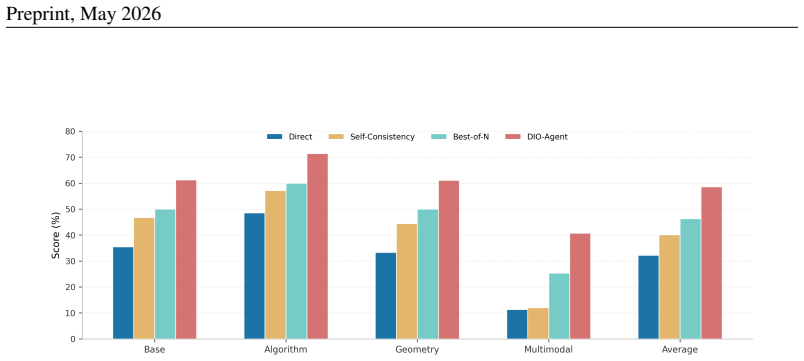
DIO-Agent consistently outperforms both traditional program-by-example methods and SOTA evolution-agent baselines across all difficulty levels and various LLMs by treating IO2Code as evolutionary search over discrete program space, with an LLM as the mutation operator and the Transformation Priority Premise as a mutation prior that biases toward the simplest hypothesis consistent with current evidence.
What carries the argument
The Transformation Priority Premise, a mutation prior that biases the LLM toward the simplest hypothesis consistent with current evidence by starting with constants, then conditionals, then iteration only when simpler constructs fail.
If this is right
- The method produces higher success rates than prior baselines on every difficulty tier of IO2CodeBench.
- Performance gains hold when the underlying LLM is swapped for different models.
- Equivalent gains cannot be obtained simply by increasing the number of independent LLM samples.
- The benchmark construction enables controlled measurement of how program complexity affects search difficulty.
Where Pith is reading between the lines
- A similar staged-simplicity bias could improve LLM-driven search in other discrete spaces such as circuit design or equation discovery.
- The approach may extend naturally to settings with noisy or partial input-output traces rather than complete examples.
- Hybrid systems could combine the evolutionary loop with occasional natural-language hints to accelerate discovery on very large programs.
Load-bearing premise
The Transformation Priority Premise successfully biases the LLM mutation operator toward the simplest hypothesis consistent with current evidence without missing valid complex solutions or introducing bias that harms search on harder instances.
What would settle it
A set of input-output pairs whose shortest correct program requires an early loop or conditional, yet the priority premise keeps the search inside constant-only programs and exhausts its budget without recovering the solution.
Figures








read the original abstract
The automatic synthesis of a program from any form of specification is regarded as a holy grail of computer science. Fueled by LLMs, NL2Code has achieved tremendous success, yet the fundamentally more challenging task of synthesizing programs from input-output behavior, which we refer to as IO2Code, remains largely unsolved. Whereas NL2Code can exploit the semantic alignment between natural language and code acquired during pretraining, IO2Code requires recovering underlying principles from concrete computational behavior, navigating a vast and underspecified hypothesis space. To address this, we propose DIO-Agent, a discovery agent for IO2Code. Our method frames IO2Code as an evolutionary search over discrete program space, in which an LLM serves as the mutation operator and concrete error signals from execution guide each mutation. To prevent the search from wandering into structurally complex yet incorrect dead ends, we introduce the Transformation Priority Premise as a mutation prior that biases the LLM toward the simplest hypothesis consistent with current evidence, progressively escalating from constants to conditionals to iteration only when simpler constructs are insufficient. To facilitate systematic study, we further construct an IO2CodeBench spanning multiple difficulty levels. Extensive experiments show that DIO-Agent consistently outperforms both traditional program-by-example method and SOTA evolution-agent baselines across all difficulty levels and various LLMs, while substantially surpassing test-time scaling strategies with equivalent sampling budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DIO-Agent for the IO2Code task of synthesizing programs from input-output examples. It frames the problem as evolutionary search over program space with an LLM as the mutation operator, guided by execution error signals. A key component is the Transformation Priority Premise, which biases mutations toward progressively more complex constructs (constants to conditionals to iteration) only when simpler ones fail to match evidence. The authors also introduce IO2CodeBench spanning difficulty levels and report that DIO-Agent outperforms traditional program-by-example methods, SOTA evolution-agent baselines, and test-time scaling approaches with equivalent budgets, across multiple LLMs and difficulty levels.
Significance. If the results hold, the work offers a practical method for LLM-guided program synthesis from behavioral specifications, addressing the large hypothesis space via a simplicity bias and external feedback. The benchmark construction supports systematic evaluation in this area. The approach avoids parameter fitting on the same data, strengthening the empirical claims relative to purely fitted models.
major comments (2)
- [§3.2] §3.2, Transformation Priority Premise: The escalation rule (constants → conditionals → iteration) is presented as preventing dead ends, but no coverage argument or experiment demonstrates that every reachable correct program remains accessible. For instances where a correct solution requires an early complex construct (e.g., iteration to satisfy the IO pairs), the bias may cause repeated proposals of insufficient simpler variants, exhausting the sampling budget before discovery. This directly affects the central claim of consistent outperformance on harder IO2CodeBench levels.
- [§4.2] §4.2, Results tables: The abstract states consistent outperformance across levels and LLMs, yet the manuscript provides no concrete success rates, error bars, statistical tests, or details on how IO2CodeBench tasks were constructed, filtered, or whether any exclusions were applied. Without these, the load-bearing empirical claim cannot be verified and the comparison to baselines and test-time scaling remains under-specified.
minor comments (2)
- [Abstract] Abstract: Add one sentence summarizing the size of IO2CodeBench and the primary metric (e.g., success rate at k samples).
- [§3] Notation: Define the exact form of the mutation prompt and the error signal used for guidance in the method section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [§3.2] The escalation rule (constants → conditionals → iteration) is presented as preventing dead ends, but no coverage argument or experiment demonstrates that every reachable correct program remains accessible. For instances where a correct solution requires an early complex construct (e.g., iteration to satisfy the IO pairs), the bias may cause repeated proposals of insufficient simpler variants, exhausting the sampling budget before discovery. This directly affects the central claim of consistent outperformance on harder IO2CodeBench levels.
Authors: The Transformation Priority Premise functions as a heuristic bias inspired by simplicity principles in program synthesis rather than a complete search procedure with formal reachability guarantees. We do not provide a coverage argument because proving that every correct program remains accessible under the escalation rule would require exhaustive characterization of the hypothesis space for arbitrary IO pairs, which is computationally intractable. Our empirical results across IO2CodeBench nevertheless show that the bias improves performance relative to unbiased LLM mutation and other baselines. In the revised manuscript we have added a limitations paragraph in §3.2 that explicitly discusses failure modes where an early complex construct may be required and report an ablation that removes the priority escalation on a subset of hard tasks. revision: partial
-
Referee: [§4.2] The abstract states consistent outperformance across levels and LLMs, yet the manuscript provides no concrete success rates, error bars, statistical tests, or details on how IO2CodeBench tasks were constructed, filtered, or whether any exclusions were applied. Without these, the load-bearing empirical claim cannot be verified and the comparison to baselines and test-time scaling remains under-specified.
Authors: We apologize for insufficient detail in the initial presentation. The full manuscript reports per-level success rates and standard deviations (from five independent runs) in Tables 1 and 2, together with Wilcoxon signed-rank tests (p < 0.05) comparing DIO-Agent against baselines. Section 4.1 describes benchmark construction: tasks were synthesized from templates and LLM-generated candidates, then filtered for syntactic validity and unique behavior; no additional post-generation exclusions were performed. We have expanded §4.1 with explicit filtering criteria and moved all numerical results and test statistics into the main text for easier verification. revision: yes
- Formal coverage argument proving that the Transformation Priority Premise preserves reachability for every correct program under arbitrary IO pairs
Circularity Check
No circularity: empirical evolutionary search with external execution feedback
full rationale
The paper frames IO2Code as an evolutionary search where an LLM acts as mutation operator and concrete execution error signals provide guidance. The Transformation Priority Premise is introduced as a heuristic bias toward simpler constructs, but no equations, fitted parameters, or self-citations reduce the reported performance gains to quantities defined by the same data or prior author work. The method is presented as a self-contained empirical procedure evaluated on IO2CodeBench against baselines, with outperformance claims resting on external test execution rather than internal redefinitions or load-bearing self-references. This matches the default case of an honest non-finding for a search-based approach without derivation chains that collapse by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM can act as an effective mutation operator when guided by concrete execution error signals
- ad hoc to paper Transformation Priority Premise prevents wandering into complex incorrect programs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce the Transformation Priority Premise as a mutation prior that biases the LLM toward the simplest hypothesis consistent with current evidence, progressively escalating from constants to conditionals to iteration only when simpler constructs are insufficient
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Henrique Assumpc ¸˜ao, Diego Ferreira, Leandro Campos, and Fabricio Murai. Codeevolve: An open source evolutionary coding agent for algorithm discovery and optimization.arXiv preprint arXiv:2510.14150,
-
[2]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, et al. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and...
work page 1901
-
[3]
Hongzheng Chen, Alexander Novikov, Ng ˆan V ˜u, Hanna Alam, Zhiru Zhang, Aiden Grossman, Mircea Trofin, and Amir Yazdanbakhsh. Magellan: Autonomous discovery of novel compiler optimization heuristics with alphaevolve.arXiv preprint arXiv:2601.21096,
-
[4]
Evaluating Large Language Models Trained on Code
10 Preprint, May 2026 Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.eprint arXiv: 2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li
doi: 10.1145/3425898.3426952. Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li. Self-collaboration code generation via chatgpt.ACM Trans. Softw. Eng. Methodol., 33(7):189:1–189:38,
-
[6]
Codebert: A pre-trained model for programming and natural languages
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. Codebert: A pre-trained model for programming and natural languages. InFindings of the association for computational linguistics: EMNLP 2020, pp. 1536–1547,
work page 2020
-
[7]
Mapping language to code in programmatic context
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. Mapping language to code in programmatic context. InProceedings of the 2018 Conference on Empirical Methods in Natu- ral Language Processing, pp. 1643–1652,
work page 2018
-
[8]
Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wen- pin Jiao
doi: 10.18653/v1/D18-1192. Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wen- pin Jiao. Self-planning code generation with large language models.ACM Trans. Softw. Eng. Methodol., 33(7):182:1–182:30,
-
[9]
Llm-guided compositional program synthesis.arXiv preprint arXiv:2503.15540,
Ruhma Khan, Sumit Gulwani, Vu Le, Arjun Radhakrishna, Ashish Tiwari, and Gust Verbruggen. Llm-guided compositional program synthesis.arXiv preprint arXiv:2503.15540,
-
[10]
Alexey Kravatskiy, Valentin Khrulkov, and Ivan Oseledets. Improvevolve: Ask alphaevolve to im- prove the input solution and then improvise.arXiv preprint arXiv:2602.10233,
-
[11]
Discovering Multiagent Learning Algorithms with Large Language Models
Zun Li, John Schultz, Daniel Hennes, and Marc Lanctot. Discovering multiagent learning algorithms with large language models.arXiv preprint arXiv:2602.16928,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Pan, Alexander Du, Kurt Keutzer, Alvin Cheung, Alexandros G
Shu Liu, Shubham Agarwal, Monishwaran Maheswaran, Mert Cemri, Zhifei Li, Qiuyang Mang, Ashwin Naren, Ethan Boneh, Audrey Cheng, Melissa Z Pan, et al. Evox: Meta-evolution for automated discovery.arXiv preprint arXiv:2602.23413,
-
[14]
Codexglue: A machine learning benchmark dataset for code understanding and generation
11 Preprint, May 2026 Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al. Codexglue: A machine learning benchmark dataset for code understanding and generation. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track,
work page 2026
-
[15]
Eric J Michaud, Isaac Liao, Vedang Lad, Ziming Liu, Anish Mudide, Chloe Loughridge, Zifan Carl Guo, Tara Rezaei Kheirkhah, Mateja Vukeli ´c, and Max Tegmark. Opening the ai black box: program synthesis via mechanistic interpretability.arXiv preprint arXiv:2402.05110,
-
[16]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis.arXiv preprint arXiv:2203.13474,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngˆan V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Flashmeta: A framework for inductive program synthe- sis
Oleksandr Polozov and Sumit Gulwani. Flashmeta: A framework for inductive program synthe- sis. InProceedings of the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, pp. 107–126,
work page 2015
-
[19]
Accessed: 2026-05-07. Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475,
work page 2026
-
[20]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven CH Hoi. Codet5: Identifier-aware unified pre- trained encoder-decoder models for code understanding and generation. InProceedings of the 2021 conference on empirical methods in natural language processing, pp. 8696–8708,
work page 2021
-
[21]
Pbe meets llm: When few examples aren’t few-shot enough
Shuning Zhang and Yongjoo Park. Pbe meets llm: When few examples aren’t few-shot enough. arXiv preprint arXiv:2507.05403,
-
[22]
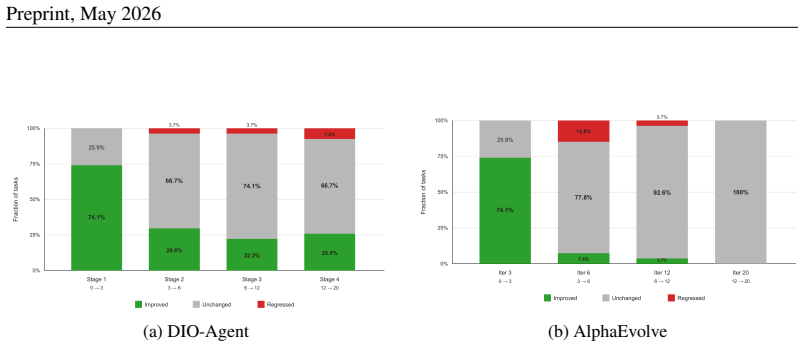
12 Preprint, May 2026 A Stage-wise Analysis of Curriculum Refinement We distinguish between the strict task-level success metric used for final evaluation and a diagnostic sample-level pass ratio used only for analyzing the search process. In the final evaluation, we follow the strict all-pass criterion: a task is considered solved only if the generated p...
work page 2026
-
[23]
In contrast, AlphaEvolve remains around 50% under the same checkpoints, with sample pass ratios of 49.6%, 47.9%, 50.6%, and 50.6%, respec- tively. Therefore, although DIO-Agent is initially lower than AlphaEvolve at the first checkpoint, it continues to benefit from later curriculum stages and eventually surpasses AlphaEvolve. We further analyze how each ...
work page 2026
-
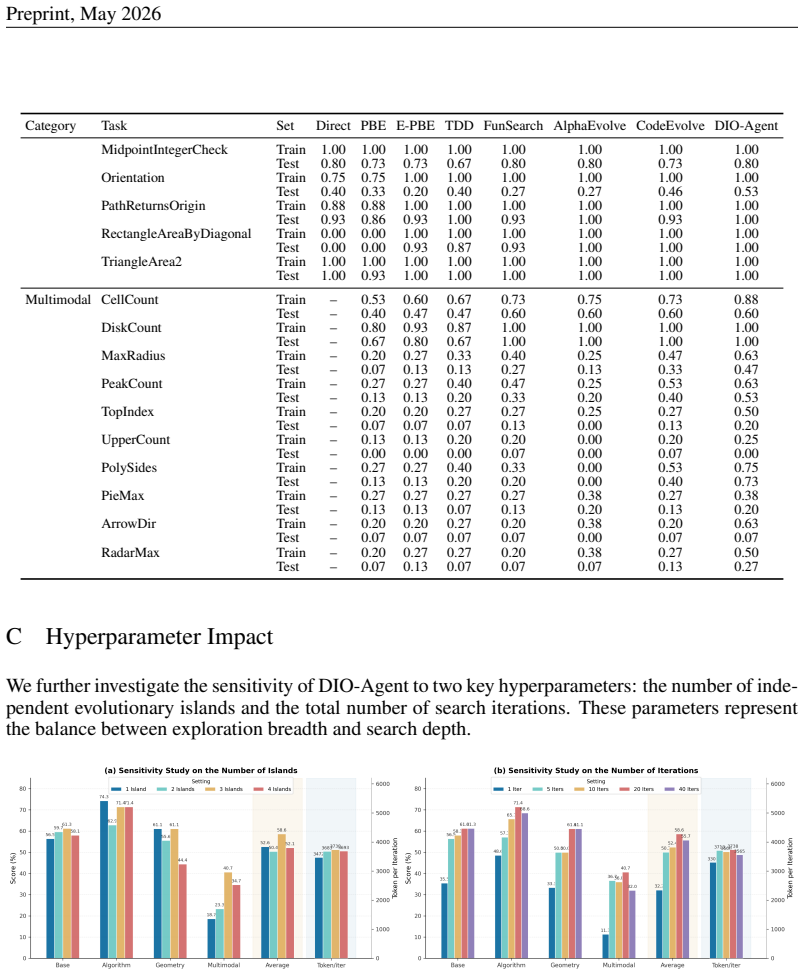
[24]
The most critical component is Curriculum- wise Evolution (CE). Removing it results in the largest performance drop, with the average pass rate falling from 58.63% to 51.33%. This decline is particularly pronounced in the Algorithm level (from 71.43% to 62.86%). Furthermore, its absence increases the token cost per iteration to 4244.31, suggesting that th...
work page 2026
-
[25]
The input image contains circles of various colors (where the color variations serve as distractors), and the output is the total count of circles. In this instance, the LLM chose to directly utilize the cv2 package, calling specific functions for information extraction to achieve the final solution. These experiments demonstrate that DIO-Agent can learn ...
work page 2026
-
[26]
Integer- valued tasks sample each element from a task-specific bounded interval, bit-valued tasks sample 22 Preprint, May 2026 each element from{0,1}, floating-point tasks sample from a bounded real interval, and two-stream tasks generate two aligned sequences of the same length. The target output is then obtained by directly applying the hidden oracle fu...
work page 2026
-
[27]
The split procedure is designed to avoid leakage at the input level
This separation is hard-coded in the generation pipeline and is also stated explicitly in the prompt shown to the model. The split procedure is designed to avoid leakage at the input level. For each task, we first sample an oversized candidate pool for training and testing, deduplicate examples by input, and then remove any test input that also appears in...
work page 2026
-
[28]
In the Autonomous Discovery setting, the model initially constructs 2 I/O examples. Once the evolved code successfully passes all existing examples, the model is permitted to generate additional I/O pairs, increasing the sample count by 2 in each subsequent step. We set the maximum number of iterations to 50 and implement an early stopping strategy if the...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.