Artificial Intelligence for Mathematical Reasoning: An Integrated Survey of Language Models, Neuro-symbolic Systems, and Verified Discovery
Pith reviewed 2026-06-27 18:38 UTC · model grok-4.3
The pith
AI mathematical reasoning is organized into four axes: informal solving over text and diagrams, formal proving in assistants, mathematical discovery, and the inference and training techniques that link them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
This survey organizes the AI mathematical reasoning landscape along four axes: informal reasoning over text and diagrams that includes math word problems, multimodal geometry, and vision-language models; formal reasoning inside proof assistants covering autoformalization, tactic prediction, and proof search; mathematical discovery where systems propose constructions or improve bounds on open problems; and inference and training techniques such as chain-of-thought prompting, tool use, process reward models, and reinforcement learning with verification that increasingly tie generation to checking.
What carries the argument
The four-axis taxonomy that partitions the field into informal reasoning, formal reasoning in proof assistants, mathematical discovery, and inference/training techniques while also cataloging benchmarks and failure modes.
If this is right
- Progress can be tracked separately along each of the four axes while noting where techniques from one axis improve another.
- Benchmark issues such as contamination and the difference between pass@1 and verifier-assisted scoring affect how results are interpreted across informal and formal settings.
- Failure modes like brittleness under perturbation and reward hacking appear in both language-model and neuro-symbolic systems.
- Future systems are expected to combine generation with verification in verified-discovery workflows.
Where Pith is reading between the lines
- The taxonomy could serve as a checklist when designing new hybrid systems that move fluidly between informal exploration and formal checking.
- Attention to energy cost and inference efficiency may become a fifth practical axis as model scale grows.
- Making formalization tools usable by working mathematicians would test whether the survey's identified directions actually accelerate open-problem work.
Load-bearing premise
That the chosen papers, benchmarks, and listed failure modes give a representative picture of a fast-moving field without major gaps or biases in coverage.
What would settle it
A later review that identifies a large body of work falling outside the four axes or that documents dominant failure modes not listed in the survey would show the organization is incomplete.
Figures

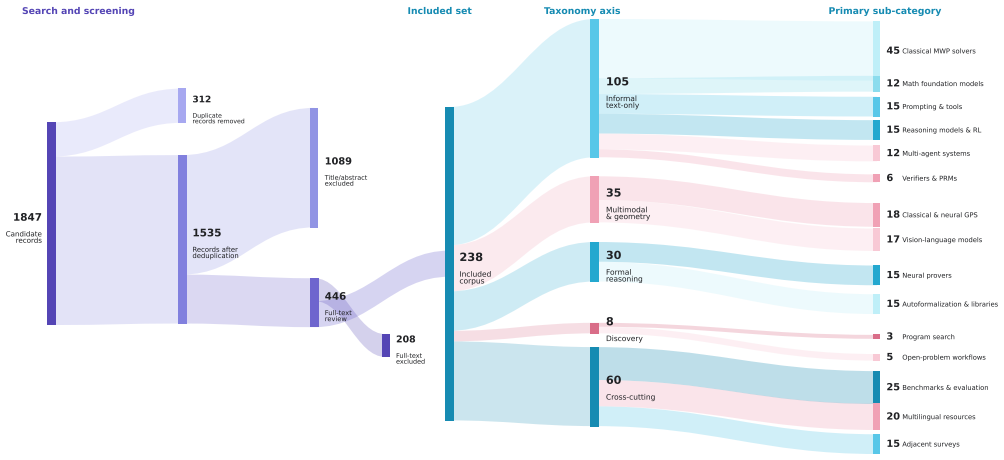

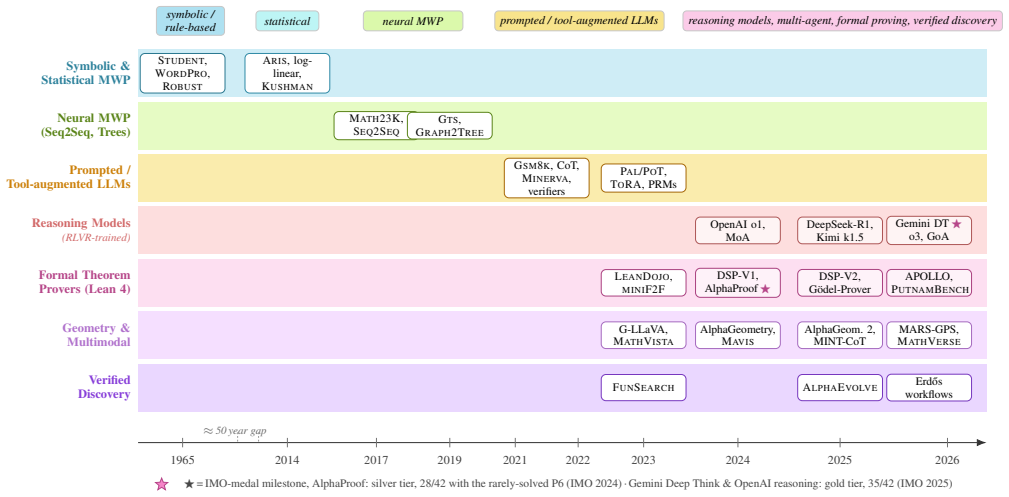






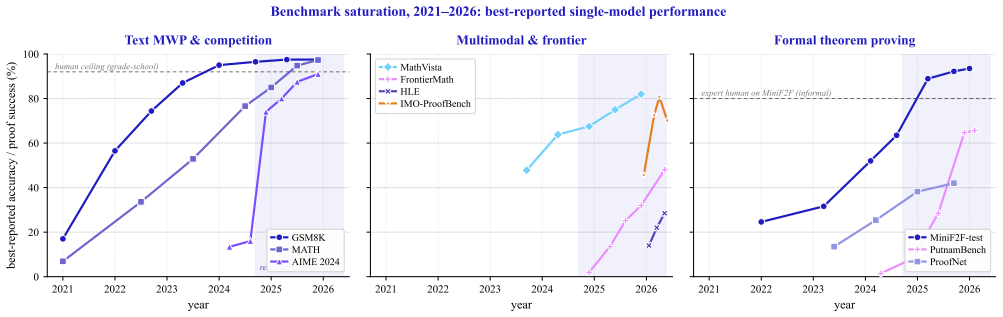
read the original abstract
Mathematical reasoning has long served as a stringent test of machine intelligence; over the past decade, it has moved from a niche problem within NLP to one of the most consequential AI frontiers. This survey provides a unified account of the field's evolution, from early rule-based math word problem (MWP) solvers and template-driven geometry systems, through neural expression generation and LLM prompting, to contemporary reasoning models, multi-agent systems, neuro-symbolic theorem provers, and verified discovery workflows. We organize the landscape along four axes: (i) informal reasoning over text and diagrams, spanning MWP solving, multimodal geometry, and VLMs; (ii) formal reasoning in proof assistants, including autoformalization, tactic prediction, compiler-guided repair, and proof search; (iii) mathematical discovery, where systems propose constructions, improve bounds, or assist attacks on open problems; and (iv) the inference and training-time techniques, including CoT prompting, tool use, process reward models, and RLVR, that increasingly connect generation with verification. We catalog major benchmarks across grade-school arithmetic, competition mathematics, geometry, formal proving, multimodal and multilingual reasoning, and expert evaluation, and we examine benchmark saturation, contamination, reporting mismatches, and the distinction between pass@1, majority voting, and verifier-assisted pass@$k$. We critically assess failure modes: brittleness under perturbation, reward hacking, multimodal grounding failures, fragile formalization, and the energy cost of reasoning-scale inference. Drawing on recent perspectives from working mathematicians, we identify future directions centered on verified-discovery workflows, reasoning efficiency, and infrastructure to make AI-assisted formalization broadly usable. Companion materials: https://github.com/Starscream-11813/awesome-AI4Math.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a literature survey that organizes AI approaches to mathematical reasoning into four axes—informal reasoning over text and diagrams, formal reasoning in proof assistants, mathematical discovery, and inference/training techniques—while cataloging benchmarks across arithmetic, competition math, geometry, and formal proving, and critically examining failure modes such as benchmark contamination, reward hacking, and multimodal grounding failures. It concludes with future directions emphasizing verified-discovery workflows and efficiency improvements, supported by a companion GitHub repository.
Significance. If the synthesis is representative, the four-axis taxonomy and benchmark catalog could provide a useful organizing framework for a fast-moving area, with the explicit discussion of pass@k distinctions and energy costs of inference adding practical value. The companion GitHub repository (awesome-AI4Math) is a concrete strength that supports reproducibility and ongoing updates.
major comments (1)
- [Abstract and §1] Abstract and §1 (Introduction): the central claim that the survey constitutes a 'unified account' and 'critically assesses' failure modes rests on the assumption of representative literature selection, yet no explicit inclusion criteria, coverage metrics, or search methodology are stated; this directly affects the weakest assumption identified in the review and requires a dedicated subsection to make the representativeness claim verifiable.
minor comments (2)
- The abstract lists 'multimodal and multilingual reasoning' benchmarks but the corresponding catalog section should include a table or explicit enumeration to improve scannability.
- Future-directions paragraph would benefit from concrete, falsifiable milestones (e.g., specific open problems or benchmark thresholds) rather than high-level aspirations.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation of minor revision. The single major comment identifies a genuine gap in methodological transparency that we can readily address without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1 (Introduction): the central claim that the survey constitutes a 'unified account' and 'critically assesses' failure modes rests on the assumption of representative literature selection, yet no explicit inclusion criteria, coverage metrics, or search methodology are stated; this directly affects the weakest assumption identified in the review and requires a dedicated subsection to make the representativeness claim verifiable.
Authors: We agree that the absence of an explicit literature-selection methodology weakens the verifiability of the 'unified account' and 'critically assesses' claims. In the revised manuscript we will insert a new subsection (placed immediately after the current §1.1) titled 'Literature Selection and Scope'. This subsection will detail: (i) search strategy (keywords, databases, and venues queried, including arXiv categories cs.AI/cs.LG, top conferences 2018–2024, and citation thresholds), (ii) inclusion/exclusion criteria (peer-reviewed or high-impact preprints focused on AI-driven mathematical reasoning, with explicit cut-offs for coverage of each axis), and (iii) quantitative coverage metrics (number of papers per axis and benchmark category). The GitHub repository will also be updated with the same selection log. These additions directly satisfy the request while preserving the existing narrative. revision: yes
Circularity Check
No significant circularity
full rationale
This is a literature survey paper with no derivations, equations, fitted parameters, predictions, or theoretical claims. The central contribution is an organizational taxonomy across four axes plus benchmark cataloging and failure-mode discussion; none of these reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The paper is self-contained as a review and draws on external literature without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
E. A. Feigenbaum, J. Feldman,et al.,Computers and thought. New York: McGraw-Hill, 1963
1963
-
[2]
Natural language input for a computer problem solving system,
D. G. Bobrow, “Natural language input for a computer problem solving system,” 1964
1964
-
[3]
Neu- ropsychological performance, iq, personality, and grades in a longi- tudinal grade-school male sample,
J. Peterson, R. Pihl, D. Higgins, J. S ´eguin, and R. Tremblay, “Neu- ropsychological performance, iq, personality, and grades in a longi- tudinal grade-school male sample,”Individual Differences Research, vol. 1, pp. 159–172, 2003
2003
-
[4]
A broad look at the literature on math word problem-solving interventions for third graders,
S. Kingsdorf and J. Krawec, “A broad look at the literature on math word problem-solving interventions for third graders,”Cogent Education, vol. 3, no. 1, p. 1135770, 2016
2016
-
[5]
Inter-GPS: Interpretable geometry problem solving with formal language and symbolic reasoning,
P. Lu, R. Gong, S. Jiang, L. Qiu, S. Huang, X. Liang, and S.-C. Zhu, “Inter-GPS: Interpretable geometry problem solving with formal language and symbolic reasoning,”arXiv preprint arXiv:2105.04165, 2021
arXiv 2021
-
[6]
The Lean 4 theorem prover and program- ming language,
L. de Moura and S. Ullrich, “The Lean 4 theorem prover and program- ming language,”CADE, 2021
2021
-
[7]
Mathematical discoveries from program search with large language models,
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. Ruiz, J. S. Ellenberg, P. Wang, O. Fawzi,et al., “Mathematical discoveries from program search with large language models,”Nature, vol. 625, pp. 468–475, 2024
2024
-
[8]
AlphaEvolve: A cod- ing agent for scientific and algorithmic discovery,
A. Novikov, N. V ˜u, M. Eisenberger, E. Dupont, P.-S. Huang, A. Z. Wagner, S. Shirobokov, B. Kozlovskii,et al., “AlphaEvolve: A cod- ing agent for scientific and algorithmic discovery,”arXiv preprint arXiv:2506.13131, 2025
Pith/arXiv arXiv 2025
-
[9]
Autoformalization with large language models,
Y . Wu, A. Q. Jiang, W. Li, M. Rabe, C. Staats, M. Jamnik, and C. Szegedy, “Autoformalization with large language models,”NeurIPS, vol. 35, pp. 32353–32368, 2022
2022
-
[10]
Draft, sketch, and prove: Guiding formal theorem provers with informal proofs,
A. Q. Jiang, S. Welleck, J. P. Zhou, W. Li, J. Liu, M. Jamnik, T. Lacroix, Y . Wu, and G. Lample, “Draft, sketch, and prove: Guiding formal theorem provers with informal proofs,”ICLR, 2023
2023
-
[11]
Erd\h{o}s’ minimum overlap problem,
E. P. White, “Erd\h{o}s’ minimum overlap problem,”arXiv preprint arXiv:2201.05704, 2022
arXiv 2022
-
[12]
Are nlp models really able to solve simple math word problems?,
A. Patel, S. Bhattamishra, and N. Goyal, “Are nlp models really able to solve simple math word problems?,”arXiv preprint arXiv:2103.07191, 2021
Pith/arXiv arXiv 2021
-
[13]
GSM-Symbolic: Understanding the limitations of mathematical reasoning in large language models,
I. Mirzadeh, K. Alizadeh, H. Shahrokhi, O. Tuzel, S. Bengio, and M. Farajtabar, “GSM-Symbolic: Understanding the limitations of mathematical reasoning in large language models,”arXiv preprint arXiv:2410.05229, 2024
Pith/arXiv arXiv 2024
-
[14]
LeanDojo: Theorem prov- ing with retrieval-augmented language models,
K. Yang, A. M. Swope, A. Gu, R. Chalamala, P. Song, S. Yu, S. Godil, R. Prenger, and A. Anandkumar, “LeanDojo: Theorem prov- ing with retrieval-augmented language models,” inNeurIPS Datasets and Benchmarks Track, 2023
2023
-
[15]
A review of methods for automatic understanding of natural language mathematical problems,
A. Mukherjee and U. Garain, “A review of methods for automatic understanding of natural language mathematical problems,”Artificial Intelligence Review, vol. 29, no. 2, pp. 93–122, 2008
2008
-
[16]
Solving arithmetic mathematical word problems: A review and recent advancements,
S. Mandal and S. K. Naskar, “Solving arithmetic mathematical word problems: A review and recent advancements,” inInformation Tech- nology and Applied Mathematics(P. Chandra, D. Giri, F. Li, S. Kar, and D. K. Jana, eds.), (Singapore), pp. 95–114, Springer Singapore, 2019
2019
-
[17]
The gap of semantic parsing: A survey on automatic math word problem solvers,
D. Zhang, L. Wang, L. Zhang, B. T. Dai, and H. T. Shen, “The gap of semantic parsing: A survey on automatic math word problem solvers,” 2018
2018
-
[18]
S. S. Sundaram, S. Gurajada, M. Fisichella, S. S. Abraham,et al., “Why are nlp models fumbling at elementary math? a survey of deep learning based word problem solvers,”arXiv preprint arXiv:2205.15683, 2022
arXiv 2022
-
[19]
A survey of deep learning for mathematical reasoning,
P. Lu, L. Qiu, W. Yu, S. Welleck, and K.-W. Chang, “A survey of deep learning for mathematical reasoning,”ACL, 2023
2023
-
[20]
Large lan- guage models for mathematical reasoning: Progresses and challenges,
J. Ahn, R. Verma, R. Lou, D. Liu, R. Zhang, and W. Yin, “Large lan- guage models for mathematical reasoning: Progresses and challenges,” inEACL Student Research Workshop, 2024
2024
-
[21]
Learning to reason with LLMs,
OpenAI, “Learning to reason with LLMs,” tech. rep., OpenAI, 2024. https://openai.com/index/learning-to-reason-with-llms/
2024
-
[22]
Mathematical language models: A survey,
W. Liu, H. Hu, J. Zhou, Y . Ding, J. Li, J. Zeng, M. He, Q. Chen, B. Jiang, A. Zhou, and L. He, “Mathematical language models: A survey,”ACM Computing Surveys, vol. 58, no. 6, 2025
2025
-
[23]
A survey on large language models for mathematical reasoning,
P.-Y . Wang, T.-S. Liu, C. Wang, Z. Li, Y . Wang, S. Yan, C. Jia, X.-H. Liu, X. Chen, J. Xu, and Y . Yu, “A survey on large language models for mathematical reasoning,”ACM Computing Surveys, vol. 58, no. 8, 2026
2026
-
[24]
A survey of mathematical reasoning in the era of multimodal large language model: Benchmark, method & challenges,
Y . Yan, J. Su, J. He, F. Fu, X. Zheng, Y . Lyu, K. Wang, S. Wang, Q. Wen, and X. Hu, “A survey of mathematical reasoning in the era of multimodal large language model: Benchmark, method & challenges,” inFindings of the Association for Computational Linguistics: ACL 2025, pp. 11798–11827, 2025
2025
-
[25]
Large language model based multi-agents: A survey of progress and challenges,
T. Guo, X. Chen, Y . Wang, R. Chang, S. Pei, N. V . Chawla, O. Wiest, and X. Zhang, “Large language model based multi-agents: A survey of progress and challenges,”arXiv preprint arXiv:2402.01680, 2024
Pith/arXiv arXiv 2024
-
[26]
Formal mathematical reasoning: A new frontier in AI,
K. Yang, G. Poesia, J. He, W. Li, K. Lauter, S. Chaudhuri, and D. Song, “Formal mathematical reasoning: A new frontier in AI,”arXiv preprint arXiv:2412.16075, 2024
arXiv 2024
-
[27]
A survey on deep learning for theorem proving,
Z. Li, J. Sun, L. Murphy, Q. Su, Z. Li, X. Zhang, K. Yang, and X. Si, “A survey on deep learning for theorem proving,”Conference on Language Modeling (COLM), 2024
2024
-
[28]
AI will become mathematicians’ co-pilot
T. Tao, “AI will become mathematicians’ co-pilot.” Scientific American Interview, 2024
2024
-
[29]
AI is ready for primetime in math and theoretical physics
T. Tao, “AI is ready for primetime in math and theoretical physics.” IPAM talk, reported by OpenAI Academy, 2026
2026
-
[30]
Mathematical methods and human thought in the age of AI,
T. Klowden and T. Tao, “Mathematical methods and human thought in the age of AI,”arXiv preprint, 2026. To appear in Blackwell Companion to the Philosophy of Mathematics
2026
-
[31]
Guidelines for performing systematic literature reviews in software engineering,
B. Kitchenham and S. Charters, “Guidelines for performing systematic literature reviews in software engineering,” Tech. Rep. EBSE-2007-01, Keele University and Durham University, 2007
2007
-
[32]
PAL: Program-aided language models,
L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y . Yang, J. Callan, and G. Neubig, “PAL: Program-aided language models,” inICML, 2023
2023
-
[33]
Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks,
W. Chen, X. Ma, X. Wang, and W. W. Cohen, “Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks,”TMLR, 2023
2023
-
[34]
ToRA: A tool-integrated reasoning agent for mathematical problem solving,
Z. Gou, Z. Shao, Y . Gong, Y . Shen, Y . Yang, M. Huang, N. Duan, and W. Chen, “ToRA: A tool-integrated reasoning agent for mathematical problem solving,” inICLR, 2024
2024
-
[35]
GeoQA: A geometric question answering benchmark towards multi- modal numerical reasoning,
J. Chen, J. Tang, J. Qin, X. Liang, L. Liu, E. P. Xing, and L. Lin, “GeoQA: A geometric question answering benchmark towards multi- modal numerical reasoning,”arXiv preprint arXiv:2105.14517, 2021
arXiv 2021
-
[36]
G-LLaV A: Solving geometric problem with multi-modal large language model,
J. Gao, R. Pi, J. Zhang, J. Ye, W. Zhong, Y . Wang, L. Hong, J. Han, H. Xu, Z. Li, and L. Kong, “G-LLaV A: Solving geometric problem with multi-modal large language model,”arXiv preprint arXiv:2312.11370, 2023
arXiv 2023
-
[37]
DeepSeek-Prover: Advancing theorem proving in LLMs through large-scale synthetic data,
H. Xin, D. Guo, Z. Shao, Z. Ren, Q. Zhu, B. Liu, C. Ruan, W. Li, and X. Liang, “DeepSeek-Prover: Advancing theorem proving in LLMs through large-scale synthetic data,”arXiv preprint arXiv:2405.14333, 2024
arXiv 2024
-
[38]
Understanding and solving arithmetic word problems: A computer simulation,
C. R. Fletcher, “Understanding and solving arithmetic word problems: A computer simulation,”Behavior Research Methods, Instruments, & Computers, vol. 17, no. 5, pp. 565–571, 1985
1985
-
[39]
Learning to solve arithmetic word problems with verb categorization,
M. J. Hosseini, H. Hajishirzi, O. Etzioni, and N. Kushman, “Learning to solve arithmetic word problems with verb categorization,” inEMNLP, 2014
2014
-
[40]
Learning to automatically solve algebra word problems,
N. Kushman, Y . Artzi, L. Zettlemoyer, and R. Barzilay, “Learning to automatically solve algebra word problems,” inProceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 271–281, 2014
2014
-
[41]
Deep neural solver for math word problems,
Y . Wang, X. Liu, and S. Shi, “Deep neural solver for math word problems,” inEMNLP, pp. 845–854, 2017
2017
-
[42]
A goal-driven tree-structured neural model for math word problems,
Z. Xie and S. Sun, “A goal-driven tree-structured neural model for math word problems,” inIJCAI, pp. 5299–5305, 2019
2019
-
[43]
Graph-to-tree learning for solving math word problems,
J. Zhang, L. Wang, R. K.-W. Lee, Y . Bin, Y . Wang, J. Shao, and E.- P. Lim, “Graph-to-tree learning for solving math word problems,” in ACL, 2020
2020
-
[44]
Generate & rank: A multi-task framework for math word problems,
J. Shen, Y . Yin, L. Li, L. Shang, X. Jiang, M. Zhang, and Q. Liu, “Generate & rank: A multi-task framework for math word problems,” arXiv preprint arXiv:2109.03034, 2021
arXiv 2021
-
[45]
MWP-BERT: A strong baseline for math word problems,
Z. Liang, J. Zhang, J. Shao, and X. Zhang, “MWP-BERT: A strong baseline for math word problems,”arXiv preprint arXiv:2107.13435, 2021
arXiv 2021
-
[46]
Learning to reason deductively: Math word problem solving as complex relation extraction,
Z. Jie, J. Li, and W. Lu, “Learning to reason deductively: Math word problem solving as complex relation extraction,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 5944–5955, 2022
2022
-
[47]
Solving quantitative reasoning problems with language models,
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V . Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo,et al., “Solving quantitative reasoning problems with language models,” NeurIPS, vol. 35, pp. 3843–3857, 2022
2022
-
[48]
DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu,et al., “DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[49]
Qwen2.5-math technical report: Toward mathematical expert model via self-improvement,
A. Yang, B. Zhang, B. Hui, B. Gao, B. Yu, C. Li, D. Liu, J. Tu, J. Zhou, J. Lin,et al., “Qwen2.5-math technical report: Toward mathematical expert model via self-improvement,”arXiv preprint arXiv:2409.12122, 2024
Pith/arXiv arXiv 2024
-
[50]
STaR: Bootstrapping reasoning with reasoning,
E. Zelikman, Y . Wu, J. Mu, and N. D. Goodman, “STaR: Bootstrapping reasoning with reasoning,”NeurIPS, vol. 35, pp. 15476–15488, 2022
2022
-
[51]
rStar-Math: Small LLMs can mas- ter math reasoning with self-evolved deep thinking,
X. Guan, L. Li, Y . Chen, Z. Shao, Z. Ren, B. Liu, D. Dai, J. Shao, J. Song, Y . Wu, and Q. Zhu, “rStar-Math: Small LLMs can mas- ter math reasoning with self-evolved deep thinking,”arXiv preprint arXiv:2404.07846, 2025
arXiv 2025
-
[52]
LIMO: Less is more for reasoning,
Y . Ye, Z. Huang, Y . Xiao, E. Chern, S. Xia, and P. Liu, “LIMO: Less is more for reasoning,”arXiv preprint arXiv:2502.03387, 2025
Pith/arXiv arXiv 2025
-
[53]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,”NeurIPS, vol. 35, pp. 24824–24837, 2022
2022
-
[54]
Self-consistency improves chain of thought rea- soning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowd- hery, and D. Zhou, “Self-consistency improves chain of thought rea- soning in language models,” inICLR, 2023
2023
-
[55]
Q. Zhong, K. Wang, Z. Xu, J. Liu, L. Ding, B. Du, and D. Tao, “Achieving>97% on GSM8K: Deeply understanding the problems makes LLMs better solvers for math word problems,”arXiv preprint arXiv:2404.14963, 2024
arXiv 2024
-
[56]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,”NeurIPS, vol. 36, 2023
2023
-
[57]
Least-to-most prompting enables complex reasoning in large language models,
D. Zhou, N. Sch ¨arli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schu- urmans, C. Cui, O. Bousquet, Q. Le, and E. Chi, “Least-to-most prompting enables complex reasoning in large language models,” in ICLR, 2023
2023
-
[58]
Graph of thoughts: Solving elaborate problems with large language models,
M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P. Nyczyk, et al., “Graph of thoughts: Solving elaborate problems with large language models,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, pp. 17682–17690, 2024
2024
-
[59]
DeepSeek-R1: Incentivizing reason- ing capability in LLMs via reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi,et al., “DeepSeek-R1: Incentivizing reason- ing capability in LLMs via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[60]
Kimi k1.5: Scaling reinforcement learning with LLMs,
Kimi Team, “Kimi k1.5: Scaling reinforcement learning with LLMs,” arXiv preprint arXiv:2501.12599, 2025
Pith/arXiv arXiv 2025
-
[61]
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Cand `es, and T. Hashimoto, “s1: Simple test-time scaling,”arXiv preprint arXiv:2501.19393, 2025
Pith/arXiv arXiv 2025
-
[62]
Improv- ing factuality and reasoning in language models through multiagent debate,
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch, “Improv- ing factuality and reasoning in language models through multiagent debate,”arXiv preprint arXiv:2305.14325, 2023
Pith/arXiv arXiv 2023
-
[63]
ReConcile: Round-table conference improves reasoning via consensus among diverse LLMs,
J. C.-Y . Chen, S. Saha, and M. Bansal, “ReConcile: Round-table conference improves reasoning via consensus among diverse LLMs,” inACL, 2024
2024
-
[64]
MAgICoRe: Multi-agent, iterative, coarse-to-fine refinement for rea- soning,
J. C.-Y . Chen, A. Prasad, S. Saha, E. Stengel-Eskin, and M. Bansal, “MAgICoRe: Multi-agent, iterative, coarse-to-fine refinement for rea- soning,” inEMNLP, 2025
2025
-
[65]
Graph-of-agents: A graph-based framework for multi-agent LLM collaboration,
S. Yun, J. Peng, P. Li, W. Fan, J. Chen, J. Zou, G. Li, and T. Chen, “Graph-of-agents: A graph-based framework for multi-agent LLM collaboration,” inICLR, 2026
2026
-
[66]
AutoGPS: Automated geometry problem solving via multimodal formalization and deductive reasoning,
W. Zhaoet al., “AutoGPS: Automated geometry problem solving via multimodal formalization and deductive reasoning,”arXiv preprint arXiv:2505.23381, 2025
arXiv 2025
-
[67]
FGeo- HyperGNet: Geometric problem solving integrating FormalGeo sym- bolic system and hypergraph neural network,
X. Zhang, Y . Li, N. Zhu, C. Qin, Z. Zeng, and T. Leng, “FGeo- HyperGNet: Geometric problem solving integrating FormalGeo sym- bolic system and hypergraph neural network,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pp. 4733–4741, 2025
2025
-
[68]
Solving olympiad geometry without human demonstrations,
T. H. Trinh, Y . Wu, Q. V . Le, H. He, and T. Luong, “Solving olympiad geometry without human demonstrations,”Nature, vol. 625, pp. 476– 482, 2024
2024
-
[69]
Gold-medalist performance in solving olympiad geometry with AlphaGeometry2,
Y . Chervonyi, T. H. Trinh, M. Ol ˇs´ak, X. Yang, H. Nguyen, M. Mene- gali, J. Jung, V . Verma, Q. V . Le, and T. Luong, “Gold-medalist performance in solving olympiad geometry with AlphaGeometry2,” arXiv preprint arXiv:2502.03544, 2025
arXiv 2025
-
[70]
MathVista: Evaluating mathematical reasoning of foundation models in visual contexts,
P. Lu, H. Bansal, T. Xia, J. Liu, C. Li, H. Hajishirzi, H. Cheng, K.-W. Chang, M. Galley, and J. Gao, “MathVista: Evaluating mathematical reasoning of foundation models in visual contexts,” inICLR, 2024
2024
-
[71]
MathVerse: Does your multi-modal LLM truly see the diagrams in visual math problems?,
R. Zhang, D. Jiang, Y . Zhang, H. Lin, Z. Guo, P. Qiu, A. Zhou, P. Lu, K.-W. Chang, Y . Qiao, and H. Li, “MathVerse: Does your multi-modal LLM truly see the diagrams in visual math problems?,” inECCV, 2024
2024
-
[72]
Measuring multimodal mathematical reasoning with MATH-vision dataset,
K. Wang, J. Pan, W. Shi, Z. Lu, M. Zhan, and H. Li, “Measuring multimodal mathematical reasoning with MATH-vision dataset,” in NeurIPS Datasets and Benchmarks Track, 2024
2024
-
[73]
MA VIS: Mathematical visual instruction tuning,
R. Zhang, X. Wei, D. Jiang, Y . Zhang, Z. Guo, C. Tong, J. Liu, A. Zhou, B. Wei, S. Zhang,et al., “MA VIS: Mathematical visual instruction tuning,”arXiv preprint arXiv:2407.08739, 2024
arXiv 2024
-
[74]
MINT-CoT: Enabling interleaved visual tokens in mathematical chain- of-thought reasoning,
X. Chen, R. Zhang, D. Jiang, A. Zhou, S. Yan, W. Lin, and H. Li, “MINT-CoT: Enabling interleaved visual tokens in mathematical chain- of-thought reasoning,”arXiv preprint arXiv:2506.05331, 2025
arXiv 2025
-
[75]
Generative language modeling for automated theorem proving,
S. Polu and I. Sutskever, “Generative language modeling for automated theorem proving,”arXiv preprint arXiv:2009.03393, 2020
Pith/arXiv arXiv 2009
-
[76]
Lean Copilot: Large language models as copilots for theorem proving in Lean,
P. Song, K. Yang, and A. Anandkumar, “Lean Copilot: Large language models as copilots for theorem proving in Lean,”arXiv preprint arXiv:2404.12534, 2024
arXiv 2024
-
[77]
APOLLO: Automated LLM and Lean collaboration for proof repair via compiler feedback,
Z. Sunet al., “APOLLO: Automated LLM and Lean collaboration for proof repair via compiler feedback,”arXiv preprint arXiv:2505.05758, 2025
arXiv 2025
-
[78]
Baldur: Whole-proof generation and repair with large language models,
E. First, M. N. Rabe, T. Ringer, and Y . Brun, “Baldur: Whole-proof generation and repair with large language models,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, (New York, NY , USA), pp. 1229–1241, Association for Computing Machinery, 2023
2023
-
[79]
Z. Ren, Z. Shao, J. Song, H. Xin, H. Wang, W. Zhao, L. Zhang, Z. Fu, Q. Zhu, D. Yang,et al., “DeepSeek-Prover-V2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition,”arXiv preprint arXiv:2504.21801, 2025
Pith/arXiv arXiv 2025
-
[80]
Kimina-Prover Preview: Towards large for- mal reasoning models with reinforcement learning,
H. Wanget al., “Kimina-Prover Preview: Towards large for- mal reasoning models with reinforcement learning,”arXiv preprint arXiv:2504.11354, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.