OSWorld-Human: Benchmarking the Efficiency of Computer-Use Agents
Pith reviewed 2026-05-22 01:18 UTC · model grok-4.3
The pith
Computer-use agents take 2.7 to 4.3 times more steps than humans to complete the same tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
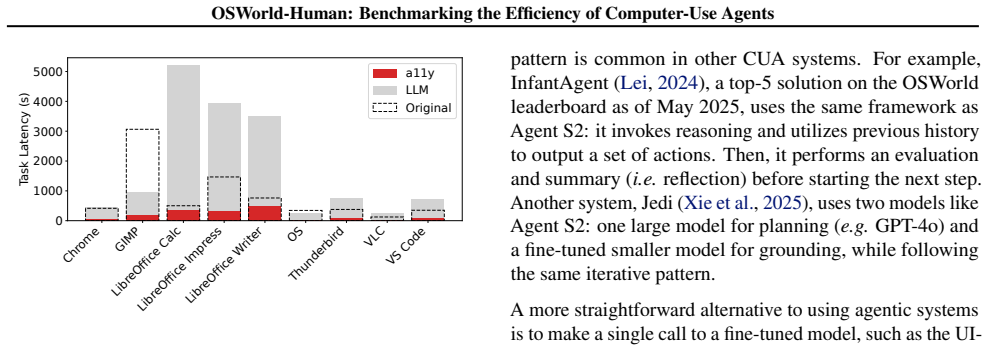
State-of-the-art computer-use agents on OSWorld incur 2.7-4.3 times as many steps as the human-annotated trajectories in OSWorld-Human, with large-model planning, reflection, and judging calls accounting for the bulk of latency and later steps taking up to three times longer than early ones.
What carries the argument
OSWorld-Human, the manually annotated dataset that supplies one human-determined trajectory per task as the reference for necessary steps.
If this is right
- Cutting unnecessary steps would reduce end-to-end latency even if model call times stay constant.
- The observed increase in time per step with task length points to compounding costs from reflection and error handling.
- Accuracy-only benchmarks miss the dominant practical barrier to usable agents.
- Human trajectories provide a concrete target for training or search methods that aim at minimal action sequences.
Where Pith is reading between the lines
- Agents could incorporate explicit state tracking to avoid repeating actions already taken.
- The same human-trajectory approach could be applied to web or mobile agent benchmarks to measure step efficiency there.
- Training on the human paths might produce agents whose step counts start closer to the baseline.
- If later steps really cost more, early termination or checkpointing mechanisms would yield outsized gains.
Load-bearing premise
The human trajectories chosen for OSWorld-Human are close to the fewest steps actually needed to finish each task.
What would settle it
An agent that finishes most OSWorld tasks in a step count within 30 percent of the human annotations would undermine the reported efficiency gap.
Figures




read the original abstract
Generative AI is being leveraged to solve a variety of computer-use tasks involving desktop applications. State-of-the-art systems have focused solely on improving accuracy on leading benchmarks. However, these systems are practically unusable due to extremely high end-to-end latency (e.g., tens of minutes) for tasks that typically take humans just a few minutes to complete. To understand the cause behind this and to guide future developments of computer agents, we conduct the first study on the temporal performance of computer-use agents on OSWorld, the flagship benchmark in computer-use AI. We find that large model calls for planning, reflection, and judging account for most of the overall latency, and as an agent uses more steps to complete a task, each successive step can take 3x longer than steps at the beginning of a task. We then construct OSWorld Human, a manually annotated version of the original OSWorld dataset that contains a human-determined trajectory for each task. We evaluate 16 agents on their efficiency using OSWorld Human and found that even the best agents take 2.7-4.3x more steps than necessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OSWorld-Human, a manually annotated version of the OSWorld benchmark containing a human-determined trajectory for each task. It analyzes latency sources in computer-use agents (primarily large model calls for planning, reflection, and judging) and reports that per-step latency grows up to 3x as tasks progress. Evaluating 16 agents against the human trajectories, the central claim is that even the best agents require 2.7-4.3x more steps than necessary.
Significance. If the human trajectories represent efficient paths, the work usefully shifts focus from accuracy to practical efficiency and latency in computer-use agents, with the latency growth observation and OSWorld-Human dataset as concrete contributions that could guide future agent design. The empirical measurement against external annotations avoids circularity in the reported ratios.
major comments (2)
- [Abstract and OSWorld Human construction] Abstract and OSWorld-Human construction: the headline claim that agents take '2.7-4.3x more steps than necessary' treats the manually annotated trajectories as the minimal reference. The manuscript supplies no annotation protocol, instructions for step minimization, inter-annotator agreement statistics, or verification that shorter feasible sequences were considered or ruled out. This assumption is load-bearing for every quantitative efficiency comparison.
- [Evaluation section] Evaluation section: the reported step multipliers are given as point estimates without per-task variance, statistical significance tests, or sensitivity analysis to alternative human trajectories. This weakens the robustness of the cross-agent efficiency ranking.
minor comments (1)
- [Abstract] The abstract states agents take 'tens of minutes' while humans take 'a few minutes'; adding concrete average or median end-to-end times for both would make the latency contrast more precise.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract, OSWorld-Human construction, and evaluation section. These points highlight areas where additional detail and statistical support will strengthen the manuscript. We address each comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract and OSWorld Human construction] Abstract and OSWorld-Human construction: the headline claim that agents take '2.7-4.3x more steps than necessary' treats the manually annotated trajectories as the minimal reference. The manuscript supplies no annotation protocol, instructions for step minimization, inter-annotator agreement statistics, or verification that shorter feasible sequences were considered or ruled out. This assumption is load-bearing for every quantitative efficiency comparison.
Authors: We agree that the manuscript would benefit from explicit documentation of the annotation process to support the efficiency comparisons. In the revised version, we will insert a dedicated subsection under OSWorld-Human construction that describes the annotation protocol: annotators (experienced computer users) were instructed to complete each task using the fewest actions possible while ensuring reliable task success, avoiding redundant clicks or navigation. We will clarify in the abstract and main text that the human trajectories represent efficient human performance rather than provably minimal sequences, and we will adjust phrasing from 'more steps than necessary' to 'more steps than human trajectories' where appropriate. Inter-annotator agreement was assessed on a 20% subset of tasks by a second reviewer; we will report Cohen's kappa and agreement rates. We will also document the verification step in which annotators reviewed their trajectories for obvious shorter alternatives before finalizing. revision: yes
-
Referee: [Evaluation section] Evaluation section: the reported step multipliers are given as point estimates without per-task variance, statistical significance tests, or sensitivity analysis to alternative human trajectories. This weakens the robustness of the cross-agent efficiency ranking.
Authors: We concur that reporting only aggregate point estimates limits interpretability. In the revision, we will augment the evaluation section with per-task standard deviations and 95% confidence intervals for the step multipliers. We will add statistical comparisons (e.g., paired Wilcoxon tests) between the top-performing agents and the human baselines to establish significance of the reported 2.7-4.3x range. For sensitivity to alternative trajectories, we will include a new paragraph discussing this limitation and provide a qualitative sensitivity check on five representative tasks by enumerating plausible alternative human paths and showing that the efficiency gap remains directionally consistent. revision: partial
Circularity Check
No significant circularity; empirical comparison to external human annotations is self-contained.
full rationale
The paper constructs OSWorld-Human via manual annotation of human trajectories for each task and directly measures agent step counts against these trajectories, reporting that best agents require 2.7-4.3x more steps. No equations, fitted parameters, or self-citations are present that reduce this multiplier to prior results or inputs by construction. The result is an external empirical observation rather than a derived claim that collapses into its own definitions or annotations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators produce near-optimal trajectories for each OSWorld task
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We then construct OSWorld-Human, a manually annotated version of the original OSWorld dataset that contains a human-determined trajectory for each task. We evaluate 16 agents on their efficiency using OSWorld-Human and found that even the best agents take 2.7-4.3x more steps than necessary.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
OS-SPEAR: A Toolkit for the Safety, Performance,Efficiency, and Robustness Analysis of OS Agents
OS-SPEAR is a new evaluation toolkit that tests 22 OS agents and identifies trade-offs between efficiency and safety or robustness.
-
AgentAtlas: Beyond Outcome Leaderboards for LLM Agents
AgentAtlas defines a six-state control taxonomy and nine-category failure taxonomy, then shows that removing explicit label menus from prompts drops trajectory accuracy 14-40 points to a 0.54-0.62 floor across eight models.
-
SkillDroid: Compile Once, Reuse Forever
SkillDroid compiles LLM-guided GUI trajectories into parameterized skill templates and replays them via a matching cascade, reaching 85.3% success rate with 49% fewer LLM calls and improving from 87% to 91% over 150 r...
-
WebFactory: Automated Compression of Foundational Language Intelligence into Grounded Web Agents
WebFactory is a fully automated RL pipeline that compresses LLM-encoded internet knowledge into grounded web agents, achieving performance comparable to human-annotated training but using synthetic data from only 10 websites.
-
Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges
A survey that taxonomizes threats to agentic AI, reviews benchmarks and evaluation methods, discusses technical and governance defenses, and identifies open challenges.
Reference graph
Works this paper leans on
-
[1]
Agashe, S., Wong, K., Tu, V ., Yang, J., Li, A., and Wang, X. E. Agent s2: A compositional generalist-specialist framework for computer use agents. arXiv preprint arXiv:2504.00906,
work page internal anchor Pith review arXiv
- [2]
-
[3]
Set-of-mark prompting unleashes extraordinary capabilities of gpt-4v
Li, M., Huang, Y ., Zhang, Y ., et al. Set-of-mark prompting unleashes extraordinary capabilities of gpt-4v. arXiv preprint arXiv:2310.10601,
-
[4]
Aguvis: A unified pure vision-based framework for autonomous gui agents
Performance of SOTA CUAs on OSWorld-Human with Single-Action and Grouped-Action Trajectories Observation Baseline (Max Steps) Original (%) Single WES+ (%) Grouped WES + (%) WES − Screenshot (SS) UI-TARS-1.5 (100) 42.5 23.7 14.3 -0.22 Agent S2 w/ Gemini 2.5 (50) 41.4 28.2 17.4 -0.26 InfantAgent (50) 35.3 13.3 8.2 -0.22 Agent S2 w/ Claude 3.7 (50) 34.5 20.0...
- [5]
-
[6]
URL https:// openai.com/index/computer-using-agent. Accessed: 2024-05-16. OpenAI. Gpt-4.1. https://openai.com/index/ gpt-4-1/,
work page 2024
-
[7]
Large language model released April 14, 2025, featuring major improvements in coding, in- struction following, and long-context comprehension. OpenAI. Computer-using agent
work page 2025
-
[8]
OpenAI et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Qin, Y ., Ye, Y ., Fang, J., Wang, H., Liang, S., Tian, S., Zhang, J., Li, J., Li, Y ., Huang, S., et al. Ui-tars: Pioneer- ing automated gui interaction with native agents. arXiv preprint arXiv:2501.12326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper. pdf. VideoLAN. VLC Media Player. https://www. videolan.org/vlc/,
work page 2017
-
[11]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y
URL https://arxiv.org/abs/2505.13227. Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y . ReAct: Synergizing reasoning and acting in language models. In International Confer- ence on Learning Representations (ICLR) ,
-
[13]
ReAct: Synergizing Reasoning and Acting in Language Models
URL https://arxiv.org/abs/2210.03629. Zheng, L., Yin, L., Xie, Z., Huang, J., Sun, C., Yu, C. H., Cao, S., Kozyrakis, C., Stoica, I., Gonzalez, J. E., Barrett, C., and Sheng, Y . Efficiently programming large language models using sglang,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.