DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization
Pith reviewed 2026-06-28 23:14 UTC · model grok-4.3
The pith
DRIFT achieves multi-turn RL performance by sampling fixed-policy trajectories and applying return-based importance weights in supervised fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
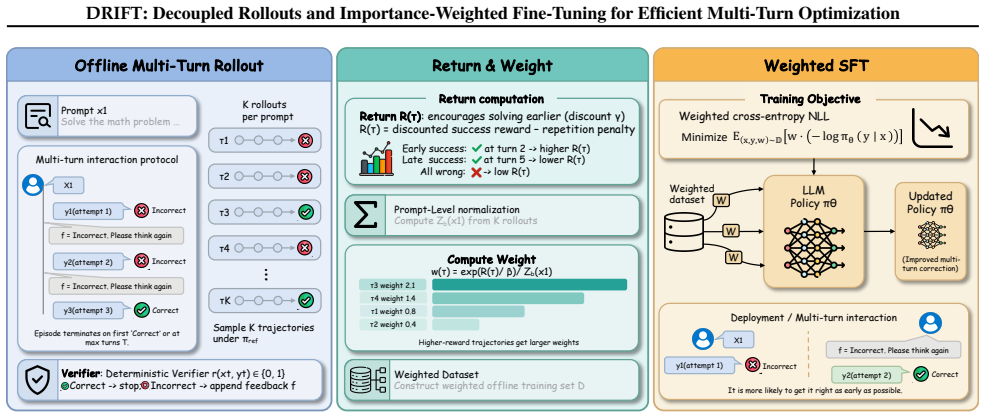
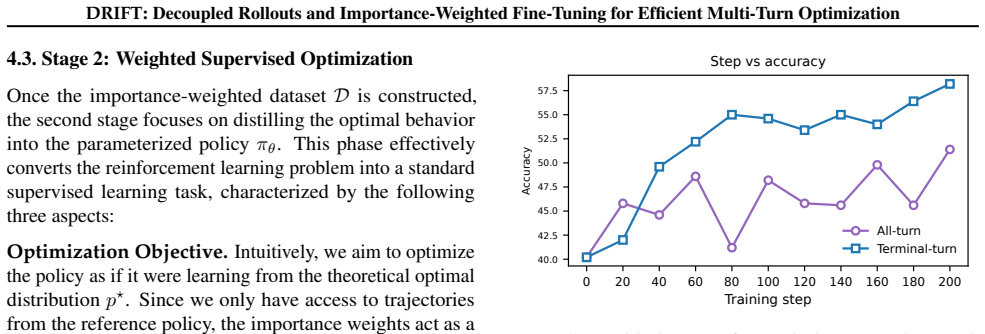
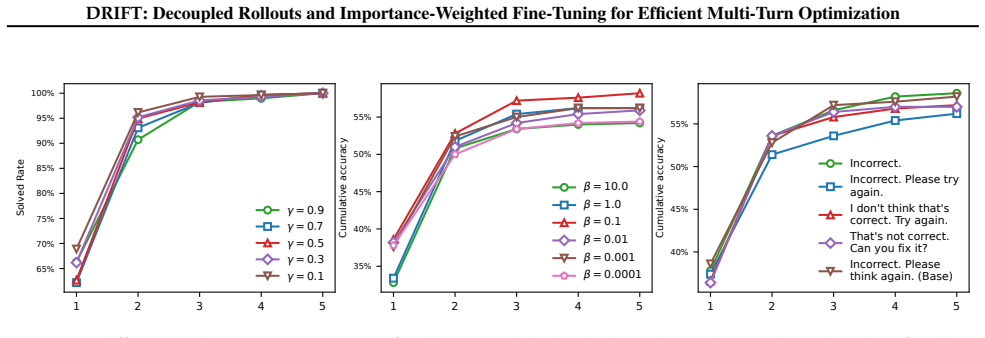
DRIFT operationalizes the equivalence between the KL-regularized RL objective and importance-weighted supervised learning by sampling offline interaction trajectories from a fixed reference policy, deriving return-based importance weights, and optimizing the policy via weighted SFT on the resulting dataset. Empirically this matches or exceeds the performance of multi-turn reinforcement learning baselines while maintaining the training efficiency and simplicity of standard supervised fine-tuning.
What carries the argument
Decoupled rollouts from a fixed reference policy with return-based importance weights fed into weighted supervised fine-tuning, which approximates the multi-turn value function offline.
If this is right
- DRIFT matches or exceeds the performance of multi-turn reinforcement learning baselines.
- DRIFT maintains the training efficiency and simplicity of standard supervised fine-tuning.
- DRIFT mitigates distribution shift and behavioral collapse that arise in plain offline SFT for multi-turn settings.
- The method supports optimization from lightweight iterative feedback without requiring repeated full-trajectory regeneration during updates.
Where Pith is reading between the lines
- The same offline weighting pattern could lower costs in other sequential decision domains where online sampling is expensive.
- Fixed-reference sampling may still require periodic updates if the environment distribution drifts significantly over time.
- Combining DRIFT weights with limited online corrections could serve as a hybrid that tests the necessity of full decoupling.
Load-bearing premise
Trajectories sampled from a fixed reference policy plus return-based importance weights are sufficient to approximate the multi-turn value function and avoid behavioral collapse without any online correction.
What would settle it
If DRIFT underperforms online multi-turn RL baselines or exhibits behavioral collapse when tested on tasks with long interaction horizons and strong environmental feedback, the central claim would be falsified.
Figures

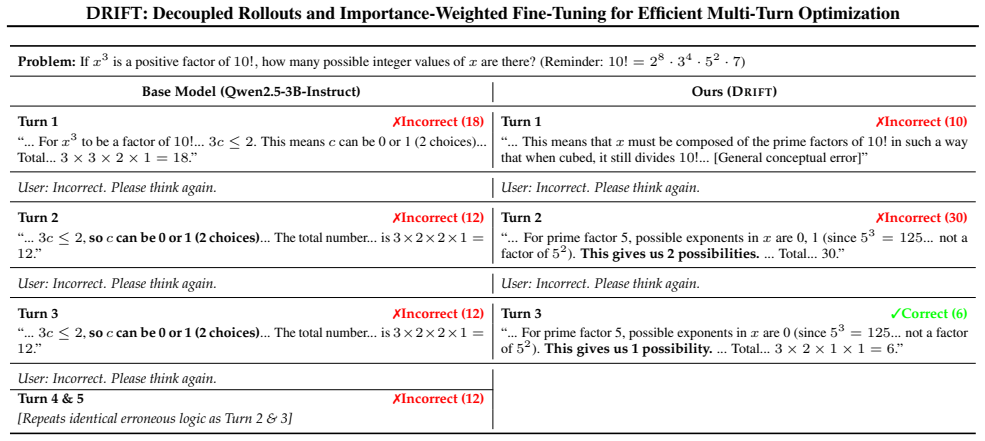
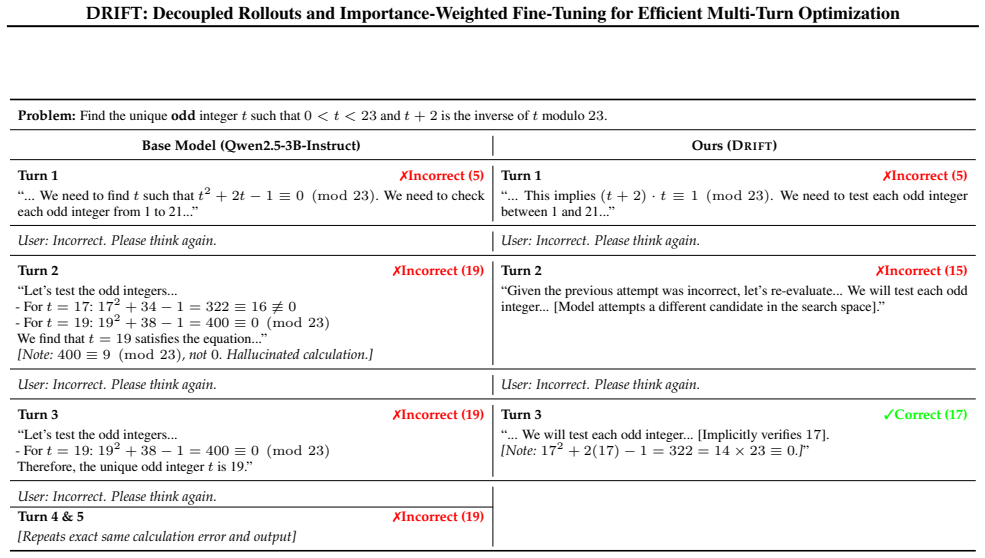
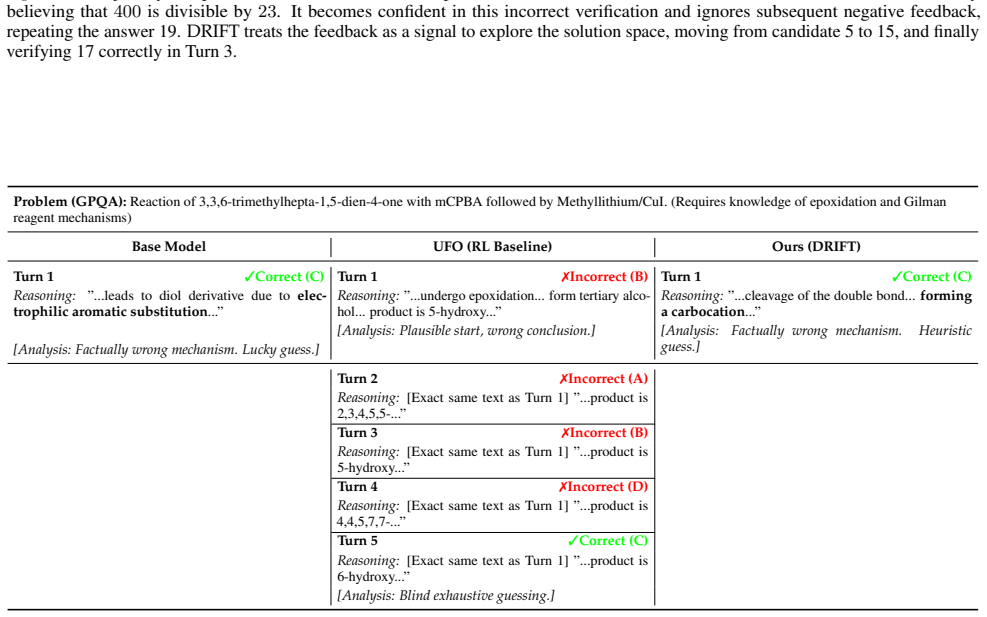
read the original abstract
Large language models are increasingly deployed in multi-turn interactive settings where users or environments can iteratively provide lightweight feedback. Unfortunately, optimizing such behavior presents a sharp dilemma in practice: online reinforcement learning is able to effectively address multi-turn dynamics but is prohibitively expensive due to the cost of generating full correction trajectories at every update, whereas offline supervised fine-tuning (SFT) is efficient but suffers from distribution shift and behavioral collapse. To this end, we novelly propose DRIFT (Decoupled Rollouts and Importance-Weighted Fine-Tuning), a framework that operationalizes the theoretical insight that the KL-regularized RL objective is equivalent to importance-weighted supervised learning. DRIFT decouples rollout from optimization by sampling offline interaction trajectories from a fixed reference policy, deriving return-based importance weights, and optimizing the policy via weighted SFT on the resulting dataset. Empirically, we demonstrate that DRIFT matches or exceeds the performance of multi-turn reinforcement learning baselines while maintaining the training efficiency and simplicity of standard supervised fine-tuning. Code is available at https://github.com/2020-qqtcg/DRIFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
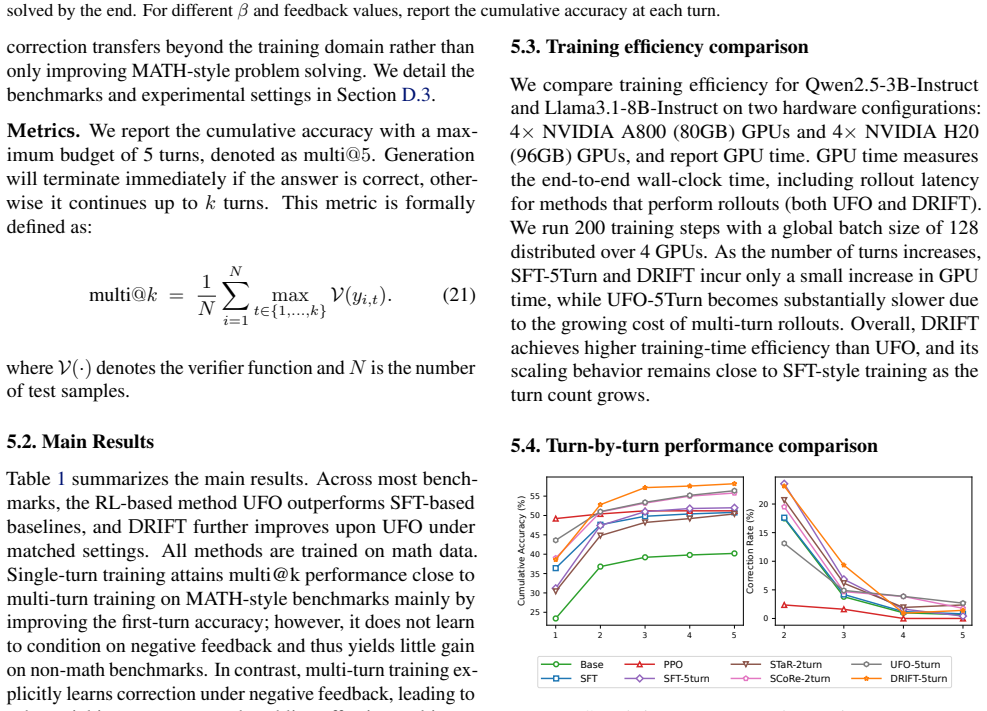
Summary. The manuscript proposes DRIFT, a framework that decouples rollout generation from optimization for multi-turn LLM fine-tuning. It samples full trajectories offline from a fixed reference policy, derives return-based importance weights, and performs weighted supervised fine-tuning on the resulting static dataset. The central claim is that this approach matches or exceeds the performance of online multi-turn RL baselines while retaining the training efficiency and simplicity of standard SFT.
Significance. If the empirical results and underlying assumptions hold, DRIFT would offer a practical bridge between the effectiveness of KL-regularized multi-turn RL and the computational simplicity of offline SFT, potentially enabling broader adoption of interactive optimization techniques without repeated online trajectory generation.
major comments (2)
- [Abstract] Abstract: The claim of empirical parity with multi-turn RL baselines is asserted without any reported experiment details, variance estimates, effective sample size, or analysis of importance-weight variance, leaving the central empirical result unverifiable from the provided text.
- [Theoretical Framework / Experiments] Theoretical and empirical sections: The method relies on the standard equivalence between KL-regularized RL and importance-weighted learning, but provides no analysis or metrics on reference-policy coverage of multi-turn state-action distributions, weight variance, or effective sample size. These quantities are load-bearing for the claim that fixed-reference trajectories plus return-based weights suffice to approximate the value function without online correction or behavioral collapse.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the presentation of empirical results and supporting analyses. We will revise the manuscript accordingly to improve verifiability while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of empirical parity with multi-turn RL baselines is asserted without any reported experiment details, variance estimates, effective sample size, or analysis of importance-weight variance, leaving the central empirical result unverifiable from the provided text.
Authors: The abstract is space-constrained and therefore omits granular statistics. The full manuscript (Section 4 and Appendix) reports results over multiple random seeds with means and standard deviations, along with the experimental protocol. We will revise the abstract to briefly reference these details and will add a dedicated paragraph plus table summarizing importance-weight variance and effective sample size in the experiments section. revision: yes
-
Referee: [Theoretical Framework / Experiments] Theoretical and empirical sections: The method relies on the standard equivalence between KL-regularized RL and importance-weighted learning, but provides no analysis or metrics on reference-policy coverage of multi-turn state-action distributions, weight variance, or effective sample size. These quantities are load-bearing for the claim that fixed-reference trajectories plus return-based weights suffice to approximate the value function without online correction or behavioral collapse.
Authors: We agree that explicit metrics on coverage, weight variance, and effective sample size would strengthen the empirical grounding. The equivalence itself is standard (as cited), and the reference policy is the initial SFT model, which by construction covers the training distribution. In revision we will add quantitative analysis of these quantities, including effective sample size calculations and weight histograms, to the experiments section and a new appendix. revision: yes
Circularity Check
No circularity; derivation rests on standard external equivalence between KL-regularized RL and importance-weighted SFT
full rationale
The paper invokes the known equivalence of the KL-regularized RL objective to importance-weighted supervised learning as a theoretical foundation, then decouples rollout (fixed reference policy) from optimization (weighted SFT). This equivalence is not derived or reduced within the paper's own equations; it is treated as an established insight that the method operationalizes. No parameters are fitted to a subset and then renamed as predictions, no self-citation chains bear the central claim, and the empirical performance comparison is presented as validation rather than a definitional consequence. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption KL-regularized RL objective is equivalent to importance-weighted supervised learning
Reference graph
Works this paper leans on
-
[1]
Bai, C., Zhang, Y ., Qiu, S., Zhang, Q., Xu, K., and Li, X. On- line preference alignment for language models via count- based exploration.arXiv preprint arXiv:2501.12735,
-
[2]
Theoremqa: A theorem- driven question answering dataset.arXiv preprint arXiv:2305.12524,
Chen, W., Yin, M., Ku, M., Lu, P., Wan, Y ., Ma, X., Xu, J., Wang, X., and Xia, T. Theoremqa: A theorem- driven question answering dataset.arXiv preprint arXiv:2305.12524,
-
[3]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps: //arxiv.org/abs/2502.11026. Gao, Z., Zhan, W., Chang, J. D., Swamy, G., Brantley, K., Lee, J. D., and Sun, W. Regressing the relative future: Efficient policy optimization for multi-turn rlhf.arXiv preprint arXiv:2410.04612,
-
[5]
P., Leang, J
Gema, A. P., Leang, J. O. J., Hong, G., Devoto, A., Mancino, A. C. M., Saxena, R., He, X., Zhao, Y ., Du, X., Madani, M. R. G., et al. Are we done with mmlu? InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 5069–5096,
2025
-
[6]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Training Language Models to Self-Correct via Reinforcement Learning
Kumar, A., Zhuang, V ., Agarwal, R., Su, Y ., Co-Reyes, J. D., Singh, A., Baumli, K., Iqbal, S., Bishop, C., Roelofs, R., et al. Training language models to self-correct via reinforcement learning.arXiv preprint arXiv:2409.12917,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
LLMs Get Lost In Multi-Turn Conversation
Laban, P., Hayashi, H., Zhou, Y ., and Neville, J. Llms get lost in multi-turn conversation.arXiv preprint arXiv:2505.06120,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Levine, S. Reinforcement learning and control as proba- bilistic inference: Tutorial and review.arXiv preprint arXiv:1805.00909,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Li, L., Chen, Z., Chen, G., Zhang, Y ., Su, Y ., Xing, E., and Zhang, K. Confidence matters: Revisiting intrinsic self- correction capabilities of large language models.arXiv preprint arXiv:2402.12563,
-
[12]
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Li, Y ., Shen, X., Yao, X., Ding, X., Miao, Y ., Krishnan, R., and Padman, R. Beyond single-turn: A survey on multi-turn interactions with large language models.arXiv preprint arXiv:2504.04717,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A simple” try again” can elicit multi-turn llm reasoning.arXiv preprint arXiv:2507.14295,
Liu, L., Wang, Z., Li, L., Xu, C., Lu, Y ., Liu, H., Sil, A., and Li, M. A simple” try again” can elicit multi-turn llm reasoning.arXiv preprint arXiv:2507.14295,
-
[14]
Self-Refine: Iterative Refinement with Self-Feedback
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y ., et al. Self-refine: Iterative refinement with self- feedback, 2023.URL https://arxiv. org/abs/2303.17651,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Nair, A., Gupta, A., Dalal, M., and Levine, S. Awac: Accel- erating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[16]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Peng, X. B., Kumar, A., Zhang, G., and Levine, S. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[17]
Qin, C. and Springenberg, J. T. Supervised fine tuning on curated data is reinforcement learning (and can be improved).arXiv preprint arXiv:2507.12856,
-
[18]
URL https: //arxiv.org/abs/2412.15115. Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimiza- tion: Your language model is secretly a reward model. Advances in neural information processing systems, 36: 53728–53741,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y ., Dirani, J., Michael, J., and Bowman, S. R. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
D., Agarwal, R., Anand, A., Patil, P., Garcia, X., Liu, P
Singh, A., Co-Reyes, J. D., Agarwal, R., Anand, A., Patil, P., Garcia, X., Liu, P. J., Harrison, J., Lee, J., Xu, K., et al. Beyond human data: Scaling self-training for problem-solving with language models.arXiv preprint arXiv:2312.06585,
-
[23]
Generating sequences by learning to self-correct.arXiv preprint arXiv:2211.00053,
Welleck, S., Lu, X., West, P., Brahman, F., Shen, T., Khashabi, D., and Choi, Y . Generating sequences by learning to self-correct.arXiv preprint arXiv:2211.00053,
-
[24]
Wen, X., Liu, Z., Zheng, S., Ye, S., Wu, Z., Wang, Y ., Xu, Z., Liang, X., Li, J., Miao, Z., et al. Reinforcement learn- ing with verifiable rewards implicitly incentivizes correct reasoning in base llms.arXiv preprint arXiv:2506.14245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Llm alignment through successive policy re-weighting (spr)
Zhang, X., Zeng, S., Li, J., Lin, K., and Hong, M. Llm alignment through successive policy re-weighting (spr). InNeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability,
2024
-
[26]
Group Sequence Policy Optimization
Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y ., Men, R., Yang, A., Zhou, J., and Lin, J. Group sequence policy optimization, 2025a. URL https://arxiv.org/abs/2507.18071. Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y ., Men, R., Yang, A., et al. Group sequence policy optimization.arXiv preprint arX...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Complementary analyses study when RLVR with answer-only rewards can still promote correct reasoning and what normalization or supervision improves stability (Wen et al., 2025)
and importance-weighted SFT (Qin & Springenberg, 2025), and successive policy reweighting schemes that target RL objectives with SFT-like compute (Zhang et al., 2024). Complementary analyses study when RLVR with answer-only rewards can still promote correct reasoning and what normalization or supervision improves stability (Wen et al., 2025). Although onl...
2025
-
[28]
as the primary math benchmark with competition-style problems that require multi-step derivations. We also report MATH500 (Hendrycks et al., 2021), a 500-problem evaluation 20 DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization Table 3.Additional model results on Qwen2.5-7B-Instruct after training on MetaMat...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.