StepAudio 2.5 Technical Report
Pith reviewed 2026-05-25 02:50 UTC · model grok-4.3
The pith
A single audio-language model matches specialized systems at speech recognition, synthesis, and realtime dialogue.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
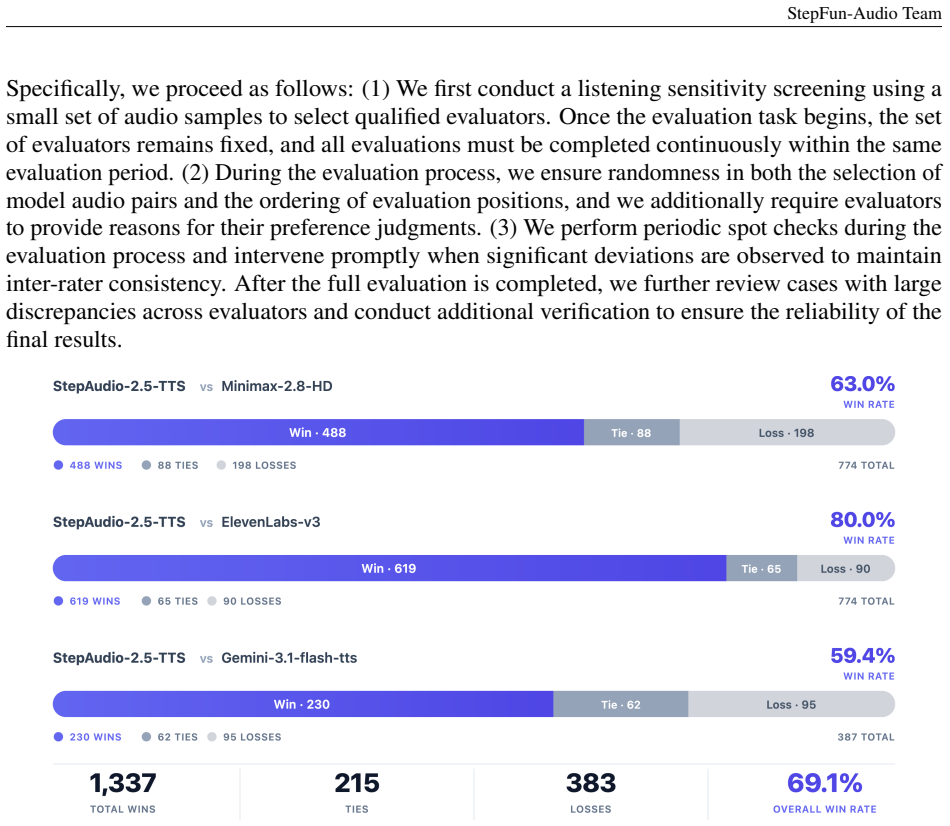
StepAudio 2.5 shows that a shared audio-language backbone can internalize the distinct deployment objectives of speech understanding, generation, and live interaction by advancing post-training to task-tailored RLHF together with specialized decoding, thereby matching or exceeding the performance of systems built separately for ASR, TTS, and realtime dialogue.
What carries the argument
Task-tailored Reinforcement Learning from Human Feedback applied after text and audio share a multimodal representational space, used to set distinct optimization targets and decoding constraints for each operational mode.
If this is right
- ASR mode improves transcription efficiency through verifiable multi-token decoding.
- TTS mode produces controllable and expressive output via preference-based RLHF and context-rich supervision.
- Realtime mode delivers low-latency, persona-consistent dialogue through generative reward modeling inside the RLHF framework.
- The single backbone achieves state-of-the-art numbers across all three tasks on standard benchmarks.
Where Pith is reading between the lines
- If the premise holds, developers could maintain one model instead of three separate pipelines for audio tasks.
- The same operational-regime approach might allow additional audio capabilities to be added without redesigning the core architecture.
- Consistent persona across understanding and generation modes could simplify building reliable conversational agents.
Load-bearing premise
Once text and audio share a multimodal representational space, task specialization reduces to choices in data construction, optimization targets, and decoding constraints.
What would settle it
Head-to-head evaluation on a standard benchmark in which StepAudio 2.5 fails to match or exceed the best specialized system in at least one of ASR, TTS, or realtime interaction.
Figures




read the original abstract
Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across ASR, TTS, and realtime spoken interaction. It operates on the premise that a shared multimodal representational space allows task specialization via operational regimes (data construction, optimization targets, and decoding constraints), with RLHF as the primary post-training mechanism: verifiable multi-token decoding for ASR, preference-based RLHF for TTS, and generative reward modeling for realtime.
Significance. If the SOTA claims are substantiated with detailed, reproducible benchmarks including error bars, dataset specifications, and direct comparisons to specialized baselines, the work would be significant for showing that a single backbone can internalize distinct deployment objectives through RLHF-centric alignment rather than separate architectures.
major comments (1)
- [Abstract] Abstract: the central claim that StepAudio 2.5 'achieves state-of-the-art results across ASR, TTS, and Realtime' is presented without any quantitative metrics (e.g., WER, MOS, latency figures), error bars, dataset details, or comparison tables. This directly undermines verification of the performance claim that is load-bearing for the entire contribution.
minor comments (1)
- [Abstract] Abstract, paragraph 3: the phrase 'standard benchmarks' is used without naming the specific datasets or metrics, reducing clarity on how the SOTA comparisons were performed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the single major comment below and will revise accordingly to strengthen verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that StepAudio 2.5 'achieves state-of-the-art results across ASR, TTS, and Realtime' is presented without any quantitative metrics (e.g., WER, MOS, latency figures), error bars, dataset details, or comparison tables. This directly undermines verification of the performance claim that is load-bearing for the entire contribution.
Authors: We agree that the abstract would benefit from explicit quantitative support to allow immediate assessment of the SOTA claims. The full manuscript contains detailed benchmark tables, dataset specifications, and direct comparisons in the experimental sections, but the abstract relies on a summary statement. In the revised version we will update the abstract to include representative metrics (e.g., WER on LibriSpeech, MOS on standard TTS test sets, and end-to-end latency for realtime), along with brief references to baselines and error bars where reported. This change improves transparency without altering the technical narrative or results. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper states its central premise explicitly as an operating assumption ('we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes') and then describes the application of RLHF and specialized decoding to produce three modes. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce the claimed results to the inputs by construction. The SOTA claims rest on benchmark outcomes rather than any definitional equivalence or load-bearing self-reference. This is the normal case of a self-contained empirical report.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Once text and audio share a multimodal representational space, task specialization reduces to data construction, optimization targets, and decoding constraints.
Reference graph
Works this paper leans on
-
[1]
Connectionist temporal classification
Alex Graves. Connectionist temporal classification. InSupervised sequence labelling with recurrent neural networks, pages 61–93. Springer, 2012
work page 2012
-
[2]
Sequence Transduction with Recurrent Neural Networks
Alex Graves. Sequence transduction with recurrent neural networks.arXiv preprint arXiv:1211.3711, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[3]
William Chan, Navdeep Jaitly, Quoc V Le, and Oriol Vinyals. Listen, attend and spell.arXiv preprint arXiv:1508.01211, 2015. 16 StepFun-Audio Team
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. pages 28492–28518, 2023
work page 2023
-
[5]
VIBEVOICE-ASR technical report.arXiv preprint arXiv:2601.18184, 2026
Zhiliang Peng, Jianwei Yu, Yaoyao Chang, Zilong Wang, Li Dong, Yingbo Hao, et al. VIBEVOICE-ASR technical report.arXiv preprint arXiv:2601.18184, 2026
-
[6]
Fun-ASR technical report.arXiv preprint arXiv:2509.12508, 2025
Keyu An, Yanni Chen, Zhigao Chen, Chong Deng, Zhihao Du, Changfeng Gao, et al. Fun-ASR technical report.arXiv preprint arXiv:2509.12508, 2025
-
[7]
Ye Bai, Jingping Chen, Jitong Chen, Wei Chen, Zhuo Chen, Chuang Ding, Linhao Dong, Qianqian Dong, Yujiao Du, Kepan Gao, et al. Seed-asr: Understanding diverse speech and contexts with llm-based speech recognition.arXiv preprint arXiv:2407.04675, 2024
-
[8]
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, et al. Qwen3- ASR technical report.arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, et al. StepAudio 2 technical report.arXiv preprint arXiv:2507.16632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-Omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Boosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation
Che Liu, Lichao Ma, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Xuerui Yang, and Fei Tian. Boosting omni-modal language models: Staged post-training with visually debiased evaluation, 2026. URLhttps://arxiv.org/abs/2605.12034
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Salmonn: Towards generic hearing abilities for large language models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models. In International Conference on Learning Representations, volume 2024, pages 16607–16629, 2024
work page 2024
-
[13]
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. Audiolm: a language modeling approach to audio generation.IEEE/ACM transactions on audio, speech, and language processing, 31:2523–2533, 2023
work page 2023
-
[14]
Recent advances in speech language models: A survey
Wenqian Cui, Dianzhi Yu, Xiaoqi Jiao, Ziqiao Meng, Guangyan Zhang, Qichao Wang, Steven Y Guo, and Irwin King. Recent advances in speech language models: A survey. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13943–13970, 2025
work page 2025
-
[15]
Heeseung Kim, Soonshin Seo, Kyeongseok Jeong, Ohsung Kwon, Soyoon Kim, Jungwhan Kim, Jaehong Lee, Eunwoo Song, Myungwoo Oh, Jung-Woo Ha, et al. Paralinguistics-aware speech-empowered large language models for natural conversation.Advances in Neural Information Processing Systems, 37:131072–131103, 2024
work page 2024
-
[16]
Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen LLM
Xiong Wang, Yangze Li, Chaoyou Fu, Yike Zhang, Yunhang Shen, Lei Xie, Ke Li, Xing Sun, and Long MA. Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen LLM. InF orty-second International Conference on Machine Learning, 2025. URL 17 StepFun-Audio Team https://openreview.net/forum?id=s1EImzs5Id
work page 2025
-
[17]
Yuxin Li, Xiangyu Zhang, Yifei Li, Zhiwei Guo, Haoyang Zhang, Eng Siong Chng, and Cuntai Guan. Depflow: Disentangled speech generation to mitigate semantic bias in depression detection.arXiv preprint arXiv:2601.00303, 2026
-
[18]
A new approach to extract fetal electrocardiogram using affine combination of adaptive filters
Yu Xuan, Xiangyu Zhang, Shuyue Stella Li, Zihan Shen, Xin Xie, Leibny Paola Garcia, and Roberto Togneri. A new approach to extract fetal electrocardiogram using affine combination of adaptive filters. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[19]
Yayue Deng, Guoqiang Hu, Haiyang Sun, Xiangyu Zhang, Haoyang Zhang, Fei Tian, Xuerui Yang, Gang Yu, and Eng Siong Chng. Multi-bench: A multi-turn interactive benchmark for assessing emotional intelligence ability of spoken dialogue models.arXiv preprint arXiv:2511.00850, 2025
-
[20]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Mind-Paced Speaking: A Dual-Brain Approach to Real-Time Reasoning in Spoken Language Models
Donghang Wu, Haoyang Zhang, Jun Chen, Hexin Liu, Eng Siong Chng, Fei Tian, Xuerui Yang, Xiangyu Zhang, Daxin Jiang, Gang Yu, et al. Mind-paced speaking: A dual-brain approach to real-time reasoning in spoken language models.arXiv preprint arXiv:2510.09592, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Donghang Wu, Haoyang Zhang, Chen Chen, Tianyu Zhang, Fei Tian, Xuerui Yang, Gang Yu, Hexin Liu, Nana Hou, Yuchen Hu, et al. Chronological thinking in full-duplex spoken dialogue language models.arXiv preprint arXiv:2510.05150, 2025
-
[24]
Duplexsla: A full-duplex spoken language model with synchronized speech, language, and action, 2026
Haoyang Zhang, Jun Chen, Donghang Wu, Yuxin Li, Yuxin Zhang, Xiangyu Tony Zhang, Che Liu, Qingjian Lin, Yizhou Peng, Hexin Liu, Eng Siong Chng, Chao Yan, Boyong Wu, Yechang Huang, Xuerui Yang, and Fei Tian. Duplexsla: A full-duplex spoken language model with synchronized speech, language, and action, 2026. URL https://arxiv.org/abs/2605. 20755
work page 2026
-
[25]
Xiangyu Zhang, Qiquan Zhang, Hexin Liu, Tianyi Xiao, Xinyuan Qian, Beena Ahmed, Eliathamby Ambikairajah, Haizhou Li, and Julien Epps. Mamba in speech: Towards an alternative to self-attention.IEEE Transactions on Audio, Speech and Language Processing, 2025
work page 2025
-
[26]
Hexin Liu, Haoyang Zhang, Qiquan Zhang, Xiangyu Zhang, Dongyuan Shi, Eng Siong Chng, and Haizhou Li. Code-switching speech recognition under the lens: Model-and data-centric perspectives.IEEE Transactions on Audio, Speech and Language Processing, 2026
work page 2026
-
[27]
Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848, 2025
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Yuxin Li, Daijiao Liu, Yayue Deng, Donghang Wu, Jun Chen, Liang Zhao, et al. Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848, 2025. 18 StepFun-Audio Team
-
[28]
Step-Audio-R1.5 Technical Report
Yuxin Zhang, Xiangyu Tony Zhang, Daijiao Liu, Fei Tian, Yayue Deng, Jun Chen, Qingjian Lin, Haoyang Zhang, Yuxin Li, Jinglan Gong, et al. Step-audio-r1.5 technical report.arXiv preprint arXiv:2604.25719, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Park, William Chan, Yu Zhang, et al
Daniel S. Park, William Chan, Yu Zhang, et al. SpecAugment: A simple data augmentation method for automatic speech recognition. InInterspeech 2019, pages 2613–2617, 2019
work page 2019
-
[30]
J. G. Fiscus. A post-processing system to yield reduced word error rates: Recognizer output voting error reduction (ROVER). In1997 IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings, pages 347–354, 1997
work page 1997
-
[31]
AIShell-1: An open-source mandarin speech corpus and a speech recognition baseline
Hui Bu, Jiatong Du, Xingyu Na, Bengu Wu, and Hao Zheng. AIShell-1: An open-source mandarin speech corpus and a speech recognition baseline. In20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment, pages 1–5, 2017
work page 2017
-
[32]
AISHELL-2: Transforming Mandarin ASR Research Into Industrial Scale
Jiatong Du, Xingyu Na, Xuechen Liu, and Hui Bu. AISHELL-2: Transforming mandarin ASR research into industrial scale. InarXiv preprint arXiv:1808.10583, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
WenetSpeech: A 10000+ hours multi-domain mandarin corpus for speech recognition
Binbin Zhang, Hang Lv, Pengcheng Guo, Qijie Shao, Chao Yang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenchen Zeng, et al. WenetSpeech: A 10000+ hours multi-domain mandarin corpus for speech recognition. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 6182–6186, 2022
work page 2022
-
[34]
Alexis Conneau, Min Ma, Simran Khanuja, et al. FLEURS: Few-shot learning evaluation of universal representations of speech.arXiv preprint arXiv:2205.12446, 2022
-
[35]
LibriSpeech: An ASR corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. LibriSpeech: An ASR corpus based on public domain audio books. In2015 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 5206–5210, 2015
work page 2015
-
[36]
Common voice: A massively-multilingual speech corpus
Rosana Ardila, Megan Branson, Kelly Davis, et al. Common voice: A massively-multilingual speech corpus. InProceedings of the Twelfth Language Resources and Evaluation Conference, pages 4218–4222, 2020
work page 2020
-
[37]
V oxpopuli-cleaned-aa: Cleaned ground truth transcripts for voxpopuli english test set, 2026
Artificial Analysis. V oxpopuli-cleaned-aa: Cleaned ground truth transcripts for voxpopuli english test set, 2026. URLhttps://artificialanalysis.ai/articles/aa-wer-v2
work page 2026
-
[38]
Earnings22-cleaned-aa: Cleaned ground truth transcripts for earnings22 english test set, 2026
Artificial Analysis. Earnings22-cleaned-aa: Cleaned ground truth transcripts for earnings22 english test set, 2026. URLhttps://artificialanalysis.ai/articles/aa-wer-v2
work page 2026
-
[39]
Step-audio-editx technical report, 2025
Chao Yan, Boyong Wu, Peng Yang, Pengfei Tan, Guoqiang Hu, Yuxin Zhang, Xiangyu, Zhang, Fei Tian, Xuerui Yang, Xiangyu Zhang, Daxin Jiang, and Gang Yu. Step-audio-editx technical report, 2025. URLhttps://arxiv.org/abs/2511.03601
-
[40]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 19
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.