HealthAgentBench: A Unified Benchmark Suite of Realistic Agentic Healthcare Environments for Challenging Frontier AI Agents
Pith reviewed 2026-07-01 06:05 UTC · model grok-4.3
The pith
A benchmark of 54 healthcare tasks shows frontier AI agents reach only 42 percent success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
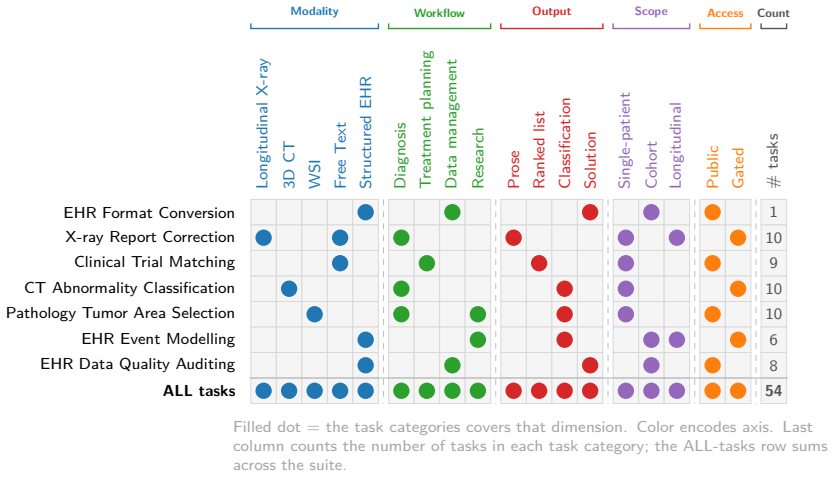
HealthAgentBench supplies 54 agentic tasks across seven categories, each placed in its own environment. When frontier agents receive only minimal instructions and raw healthcare data, they must explore the environment and execute multi-step solutions that replicate end-to-end clinical workflows. Aggregate success rates remain low; the strongest and most cost-effective agent attains approximately 42 percent. The benchmark further shows that agents can generate research modeling pipelines from EHR data yet struggle markedly with medical imaging and with tasks that demand both large search spaces and compositional reasoning.
What carries the argument
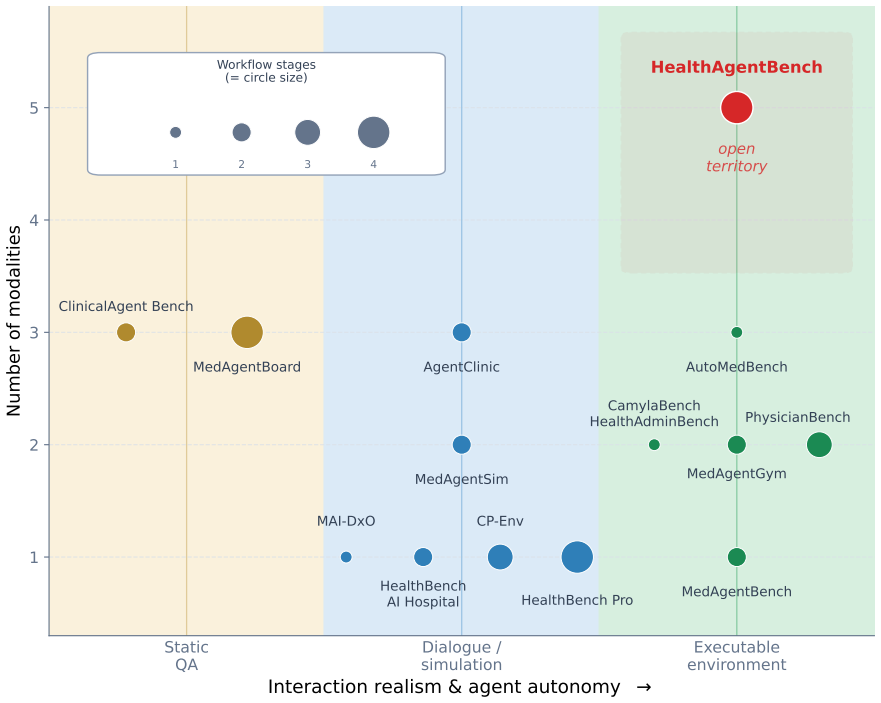
HealthAgentBench, a suite of 54 tasks in seven categories each with its own environment, that requires agents to complete realistic clinical workflows from minimal instructions and raw data.
If this is right
- Agents already show capability at automatically building research modeling pipelines from EHR data.
- Medical imaging tasks remain especially difficult, particularly for certain model families.
- Any task that pairs a large search space with compositional reasoning requirements stays hard for every current agent.
- A single aggregate success-rate metric can now be used to track progress across the entire patient-journey workflow.
Where Pith is reading between the lines
- Developers may need to improve long-horizon planning and multimodal integration before agents can handle full clinical sequences reliably.
- The benchmark could be extended to additional medical specialties or real-time sensor streams to test generalization.
- Persistent low success rates suggest that premature deployment of agents in live clinical settings would carry measurable risk.
- Category-level breakdowns could guide targeted training or tool-use improvements rather than uniform scaling.
Load-bearing premise
The 54 tasks accurately replicate end-to-end clinical workflows when agents receive minimal instructions and raw healthcare data inside the described complex environments.
What would settle it
An agent achieving a success rate well above 42 percent on the full suite while using only the stated minimal-instruction protocol would falsify the reported level of difficulty.
Figures









read the original abstract
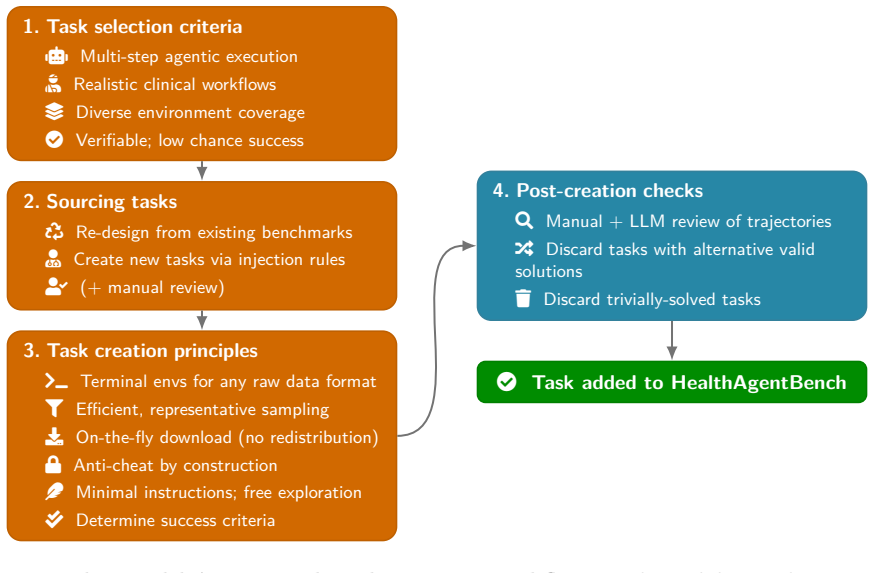
As AI agents become increasingly capable of complex, long-horizon reasoning, rigorous and holistic evaluation is essential for measuring progress toward real-world healthcare applications. We introduce HealthAgentBench, a suite of 54 agentic healthcare tasks across 7 categories each with its unique environment. The benchmark suite spans diverse workflows throughout the patient journey and a broad range of modalities. Each task is designed to replicate an end-to-end clinical workflow: given minimal instructions, an agent must explore raw healthcare data, operate within a complex environment, and execute multi-step solutions that go beyond naive prompting. A final task success rate is reported to provide a single, interpretable metric for HealthAgentBench overall performance for each agent. Evaluating frontier agents on HealthAgentBench, we find that overall task success rate remains low, underscoring the difficulty of the suite. The strongest and the most cost effective agent, Codex GPT-5.5, achieves only approximately 42% success rate. Beyond aggregate performance, HealthAgentBench reveals nuanced strengths and weaknesses across task categories. Frontier agents show promise in automatically developing research modeling pipelines over EHR data, but medical imaging remains especially challenging, particularly for Claude Code models, while Codex GPT-5.5 shows emerging capability. Tasks that combine large search spaces with compositional reasoning requirements remain difficult for all current agents. Together, these results suggest that HealthAgentBench provides a challenging and realistic benchmark with substantial room for future progress. We release our benchmark at https://github.com/microsoft/HealthAgentBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HealthAgentBench, a suite of 54 agentic healthcare tasks across 7 categories, each with unique environments. The benchmark aims to evaluate frontier AI agents on realistic end-to-end clinical workflows using minimal instructions and raw data. Evaluation shows low overall success rates, with the strongest agent Codex GPT-5.5 achieving approximately 42% success, and highlights category-specific challenges such as in medical imaging.
Significance. If the tasks accurately represent clinical workflows, this benchmark would be significant for identifying limitations in current AI agents for healthcare applications, particularly in multi-step reasoning and handling diverse modalities. The open-source release enhances its utility for the community.
major comments (1)
- [Abstract] Abstract: The central claim that the 54 tasks replicate end-to-end clinical workflows (and thus that ~42% success demonstrates benchmark difficulty) is load-bearing, yet the abstract provides no details on task construction, the definition of the 7 categories, how raw healthcare data is presented in the environments, or validation of realism against actual clinical practices. This absence prevents verification of the weakest assumption identified in the review.
minor comments (1)
- [Abstract] Abstract: The phrasing 'Codex GPT-5.5' is unclear (Codex is an older model family and GPT-5.5 does not exist); clarify the exact model identifier and whether it is a hypothetical or specific variant used in the experiments.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of the abstract in supporting the benchmark's core claims. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the 54 tasks replicate end-to-end clinical workflows (and thus that ~42% success demonstrates benchmark difficulty) is load-bearing, yet the abstract provides no details on task construction, the definition of the 7 categories, how raw healthcare data is presented in the environments, or validation of realism against actual clinical practices. This absence prevents verification of the weakest assumption identified in the review.
Authors: We agree that the abstract, constrained by length, does not elaborate on these elements. The full manuscript provides the requested details on task construction (including sourcing from de-identified clinical scenarios), definitions of the seven categories spanning the patient journey, the format in which raw data (EHR, imaging, labs) is exposed to agents, and validation steps involving domain experts to confirm alignment with real workflows. To address the concern directly, we will revise the abstract to incorporate a concise sentence on category definitions and the validation process for realism. This change will make the load-bearing claim more verifiable at a glance while preserving the abstract's brevity. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a benchmark suite of 54 tasks across 7 categories, each defined by explicit environment construction, raw data inputs, and multi-step workflow requirements. Task success is measured by direct execution outcomes against these independently specified criteria. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the derivation of the central claim (low agent performance demonstrates benchmark difficulty). The reported ~42% success rate for the top agent follows directly from applying the stated metric to the described tasks without reduction to prior fitted values or author-specific uniqueness theorems. The construction is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The designed tasks replicate realistic end-to-end clinical workflows using raw data and minimal instructions
Reference graph
Works this paper leans on
-
[1]
Self-evolving multi-agent simulations for realistic clinical interactions, 2025
Mohammad Almansoori, Komal Kumar, and Hisham Cholakkal. Self-evolving multi-agent simulations for realistic clinical interactions, 2025. URLhttps://arxiv.org/abs/2503.22678
-
[2]
Claude code documentation, 2025
Anthropic. Claude code documentation, 2025. URLhttps://code.claude.com/docs
2025
-
[3]
Claude opus system card, 2026
Anthropic. Claude opus system card, 2026. URLhttps://www.anthropic.com/claude/opus
2026
-
[4]
Claude sonnet system card, 2026
Anthropic. Claude sonnet system card, 2026. URLhttps://www.anthropic.com/claude/ sonnet
2026
-
[5]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, et al. Healthbench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025. URLhttps://doi.org/10.48550/arXiv.2505.08775
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.08775 2025
-
[6]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. HealthBench: Evaluating Large Language Models Towards Improved Human Health, 2025. URL https://doi.org/10.48550/arXiv.2505. 08775
-
[7]
HealthAdminBench: Evaluating Computer-Use Agents on Healthcare Administration Tasks
Suhana Bedi, Ryan Welch, Ethan Steinberg, Michael Wornow, Taeil Matthew Kim, Haroun Ahmed, Peter Sterling, Bravim Purohit, Qurat Akram, Angelic Acosta, et al. Healthadmin- bench: Evaluating computer-use agents on healthcare administration tasks.arXiv preprint arXiv:2604.09937, 2026. URLhttps://doi.org/10.48550/arXiv.2604.09937
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.09937 2026
-
[8]
Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator, 2024
Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xi, Fei Huang, and Jingren Zhou. Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator, 2024. URLhttps://arxiv.org/abs/2402.09742
-
[9]
Camyla: Scaling Autonomous Research in Medical Image Segmentation
Yifan Gao, Haoyue Li, Feng Yuan, Xin Gao, Weiran Huang, and Xiaosong Wang. Camyla: Scaling autonomous research in medical image segmentation, 2026. URLhttps://arxiv.org/ abs/2604.10696
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Github copilot cli, 2025
GitHub. Github copilot cli, 2025. URLhttps://github.com/features/copilot/cli
2025
-
[11]
Ibrahim Ethem Hamamci, Sezgin Er, Chenyu Wang, Furkan Almas, Ayse Gulnihan Simsek, Sev- val Nil Esirgun, Irem Dogan, Omer Faruk Durugol, Benjamin Hou, Suprosanna Shit, Weicheng Dai, Murong Xu, Hadrien Reynaud, Muhammed Furkan Dasdelen, Bastian Wittmann, Tamaz Amiranashvili, Enis Simsar, Mehmet Simsar, Emine Bensu Erdemir, Abdullah Alanbay, Anjany Sekuboyi...
-
[12]
Harbor: Aframeworkforevaluatingandoptimizingagentsandmodels in container environments, January 2026
HarborFrameworkTeam. Harbor: Aframeworkforevaluatingandoptimizingagentsandmodels in container environments, January 2026. URL https://github.com/laude-institute/ harbor. 16
2026
-
[13]
Rebecca Soskin Hicks, Mikhail Trofimov, Dominick Lim, Rahul K. Arora, Foivos Tsimpourlas, Preston Bowman, Michael Sharman, Chi Tong, Kavin Karthik, Arnav Dugar, Akshay Ja- gadeesh, Khaled Saab, Johannes Heidecke, Ashley Alexander, Nate Gross, and Karan Singhal. Healthbench professional: Evaluating large language models on real clinician chats, 2026. URL h...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Black, Gloria Geng, Danny Park, James Zou, Andrew Y
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y. Ng, and Jonathan H. Chen. MedAgentBench: A Virtual EHR Environment to Benchmark Medical LLM Agents.NEJM AI, 2, 2025. URLhttps://doi.org/10.1056/AIdbp2500144
-
[15]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021. URLhttps://doi.org/10.3390/ app11146421
2021
-
[16]
MIMIC-IV Clinical Database Demo.PhysioNet, January 2023
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Steven Horng, Leo Anthony Celi, and Roger Mark. MIMIC-IV Clinical Database Demo.PhysioNet, January 2023. doi: 10.13026/dp1f-ex47. URLhttps://doi.org/10.13026/dp1f-ex47. Version 2.2
-
[17]
MIMIC-CXR-JPG - chest radiographs with structured labels.PhysioNet, March 2024
Alistair Johnson, Matthew Lungren, Yifan Peng, Zhiyong Lu, Roger Mark, Seth Berkowitz, and Steven Horng. MIMIC-CXR-JPG - chest radiographs with structured labels.PhysioNet, March 2024. doi: 10.13026/jsn5-t979. URLhttps://doi.org/10.13026/jsn5-t979. Version 2.1.0
-
[18]
MIMIC-CXR Database.PhysioNet, July 2024
Alistair Johnson, Tom Pollard, Roger Mark, Seth Berkowitz, and Steven Horng. MIMIC-CXR Database.PhysioNet, July 2024. doi: 10.13026/4jqj-jw95. URL https://doi.org/10.13026/ 4jqj-jw95. Version 2.1.0
-
[19]
Alistair E. W. Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J. Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, Li-wei H. Lehman, Leo A. Celi, and Roger G. Mark. MIMIC-IV, a freely accessible electronic health record dataset. Scientific Data, 10(1):1, 2023. doi: 10.1038/s41597-022-01899-x
-
[20]
ReflecTool: Towards Reflection- Aware Tool-Augmented Clinical Agents
Yusheng Liao, Shuyang Jiang, Yanfeng Wang, and Yu Wang. ReflecTool: Towards Reflection- Aware Tool-Augmented Clinical Agents. InProceedings of Annual Meeting of the Associa- tion for Computational Linguistics (ACL), 2025. URLhttps://doi.org/10.18653/v1/2025. acl-long.663
-
[21]
Automedbench: Towards medical autoresearch with agentic ai models, 2026
Junqi Liu, Selena Song, Yuhan Wang, Jiawei Mao, Hardy Chen, Xiaoke Huang, Tianhao Qi, Pengfei Guo, Yucheng Tang, Yufan He, Can Zhao, Andriy Myronenko, Dong Yang, Daguang Xu, and Yuyin Zhou. Automedbench: Towards medical autoresearch with agentic ai models, 2026
2026
-
[22]
PhysicianBench: Evaluating LLM Agents in Real-World EHR Environments
Ruoqi Liu, Imran Q. Mohiuddin, Austin J. Schoeffler, Kavita Renduchintala, Ashwin Nayak, Prasantha L. Vemu, Shivam C. Vedak, Kameron C. Black, John L. Havlik, Isaac Ogunmola, Stephen P. Ma, Roopa Dhatt, and Jonathan H. Chen. Physicianbench: Evaluating llm agents in real-world ehr environments, 2026. URLhttps://arxiv.org/abs/2605.02240
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
MIMIC-IV MEDS: An ETL pipeline to extract MIMIC-IV data into the MEDS format.https://github.com/Medical-Event-Data-Standard/MIMIC_ IV_MEDS, May 2025
Matthew McDermott and Justin Xu. MIMIC-IV MEDS: An ETL pipeline to extract MIMIC-IV data into the MEDS format.https://github.com/Medical-Event-Data-Standard/MIMIC_ IV_MEDS, May 2025. Software, MIT license. 17
2025
-
[24]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for General AI Assistants, 2023. URLhttps://doi.org/10. 48550/arXiv.2311.12983
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Sequential diagnosis with language models, 2025
Harsha Nori, Mayank Daswani, Christopher Kelly, Scott Lundberg, Marco Tulio Ribeiro, Marc Wilson, Xiaoxuan Liu, Viknesh Sounderajah, Jonathan Carlson, Matthew P Lungren, Bay Gross, Peter Hames, Mustafa Suleyman, Dominic King, and Eric Horvitz. Sequential diagnosis with language models, 2025. URLhttps://arxiv.org/abs/2506.22405
-
[27]
Openai codex cli, 2025
OpenAI. Openai codex cli, 2025. URLhttps://github.com/openai/codex
2025
-
[28]
Gpt-5.3 codex, 2026
OpenAI. Gpt-5.3 codex, 2026. URL https://openai.com/index/ introducing-gpt-5-3-codex/
2026
-
[29]
Gpt-5.4, 2026
OpenAI. Gpt-5.4, 2026. URLhttps://openai.com/index/gpt-5-4
2026
-
[30]
Introducing gpt-5.5, 2026
OpenAI. Introducing gpt-5.5, 2026. URL https://openai.com/index/ introducing-gpt-5-5
2026
-
[31]
Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments,
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments,
-
[32]
URLhttps://arxiv.org/abs/2405.07960
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Overview of trec 2021
Ian Soboroff. Overview of trec 2021. InTREC, 2021
2021
-
[34]
Michael Wornow, Rahul Thapa, Ethan Steinberg, Jason A. Fries, and Nigam H. Shah. EHRSHOT: An EHR Benchmark for Few-Shot Evaluation of Foundation Models, 2023. URL https://doi.org/10.48550/arXiv.2307.02028
-
[35]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments, 2024. URL https://doi.org/10.48550...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.07972 2024
-
[36]
Medagentgym: A scalable agentic training environment for code-centric reasoning in biomedical data science
Ran Xu, Yuchen Zhuang, Yishan Zhong, Yue Yu, Zifeng Wang, Xiangru Tang, Hang Wu, May Dongmei Wang, Peifeng Ruan, Donghan Yang, Tao Wang, Guanghua Xiao, Xin Liu, Carl Yang, Yang Xie, and Wenqi Shi. Medagentgym: A scalable agentic training environment for code-centric reasoning in biomedical data science. InThe Fourteenth International Conference on Learnin...
2026
-
[37]
A clinically accessible small multimodal radiology model and evaluation metric for chest x-ray findings.Nature Communications, 16(1):3108, 2025
Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Yanbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Yujia Xie, Mahmoud Khademi, Ziyi Yang, et al. A clinically accessible small multimodal radiology model and evaluation metric for chest x-ray findings.Nature Communications, 16(1):3108, 2025. 18
2025
-
[38]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A Realistic Web Environment for Building Autonomous Agents, 2024. URLhttps://doi.org/ 10.48550/arXiv.2307.13854
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.13854 2024
-
[39]
Yakun Zhu, Zhongzhen Huang, Qianhan Feng, Linjie Mu, Yannian Gu, Shaoting Zhang, Qi Dou, and Xiaofan Zhang. CP-Env: Evaluating Large Language Models on Clinical Pathways in a Controllable Hospital Environment, 2025. URLhttps://doi.org/10.48550/arXiv.2512. 10206
-
[40]
Yinghao Zhu, Ziyi He, Haoran Hu, Xiaochen Zheng, Xichen Zhang, Zixiang Wang, Junyi Gao, Liantao Ma, and Lequan Yu. MedAgentBoard: Benchmarking Multi-Agent Collaboration with Conventional Methods for Diverse Medical Tasks, 2025. URLhttps://doi.org/10.48550/ arXiv.2505.12371. 19 A Benchmark Comparison Table 1 gives the full per-benchmark comparison from whi...
-
[41]
must be able to come to our hospital
and single-study patients with no prior (cases 06, 08). Each case’s draft FINDINGS is then synthesized at bootstrap by applying one or more documented swap principles (lateralization, severity, comparison-word flip, no-prior/no-change, count, location, negation) to the gold, introducing at least one clinically-significant error the agent must correct. Sco...
-
[42]
Scripted triage.It writes a chain of inline Python passes over all301XMLs—parsing each trial’s title, conditions, age/sex limits, and criteria; applying hard demographic filters (age 65, male); scoring relevance against cardiology keyword groups (VT/arrhythmia, ICD/SCD, syncope, CAD/MI, cath/PCI, HF, HTN, HLD); andsplittingthe surviving relevant subset in...
-
[43]
clinical trial eligibility adjudicator
Parallel adjudication.It spawns five backgroundgeneral-purpose subagents, one per batch, each prompted as a “clinical trial eligibility adjudicator” with a structured patient pro- file. Crucially, that profile spells out what the patientdoes nothave— “no atrial fibril- lation...does NOT currently have an ICD or pacemaker (only a loop recorder)...NOT nonis...
-
[44]
Loaded 29M events with pyarrow (∼8s) and built per-patient sorted timelines; extracted features for each (patient, prediction-time) pair
Merge and re-verify.It collects each subagent’s verdicts, then re-reads the full eligibility text of the surviving and borderline trials itself (e.g. pulling DAVID II’s criteria in full) to resolve edge cases, before writingeligible_trials.txt in descending confidence with a documented patient summary and validating that every NCT ID resolves to a real tr...
-
[45]
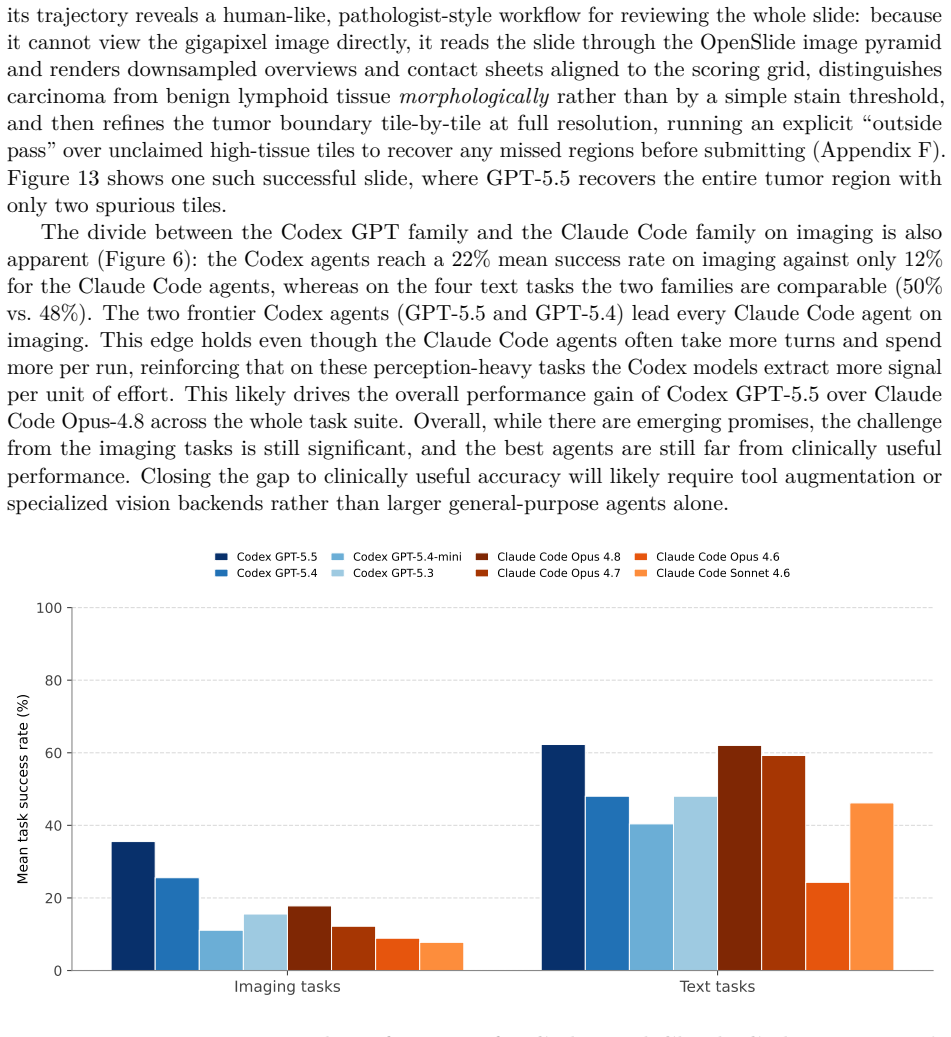
generate downsampled views aligned to the 4096-pixel grid so the tumor tile calls can be made against the required coordinates
It reads the slide through the OpenSlide pyramid and renders views at several levels aligned to the scoring grid—a low-power (level-6) overview with the tile grid labelled, plus level-4and 46 level-2contact sheets per region—stating it will “generate downsampled views aligned to the 4096-pixel grid so the tumor tile calls can be made against the required ...
-
[46]
tumor versus lymphoid tissue has to be decided morphologically,
It distinguishes tumor from confounders by histology rather than by a color threshold: “tumor versus lymphoid tissue has to be decided morphologically,” identifying “the large left mass is carcinoma, while the upper trabeculated/dark areas are largely lymphoid or non-tumor,” and computing per-tile tissue/stain fractions only to avoid over-calling low-tiss...
-
[47]
transition row...where carcinoma along the lower edge
It then refines the boundary tile-by-tile—inspecting the ambiguous “transition row...where carcinoma along the lower edge” mixes into lymphoid tissue at full level-2resolution—and runs an “outside pass” over high-tissue tiles it had not yet claimed to catch any overlooked carcinoma, overlaying the final selection on the overview before writing the tile co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.