OSS: Open Suturing Skills Vision-Based Assessment Challenge 2024-2025
Pith reviewed 2026-05-22 07:55 UTC · model grok-4.3
The pith
General-purpose spatiotemporal video models achieve the strongest performance in assessing open suturing skills from video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
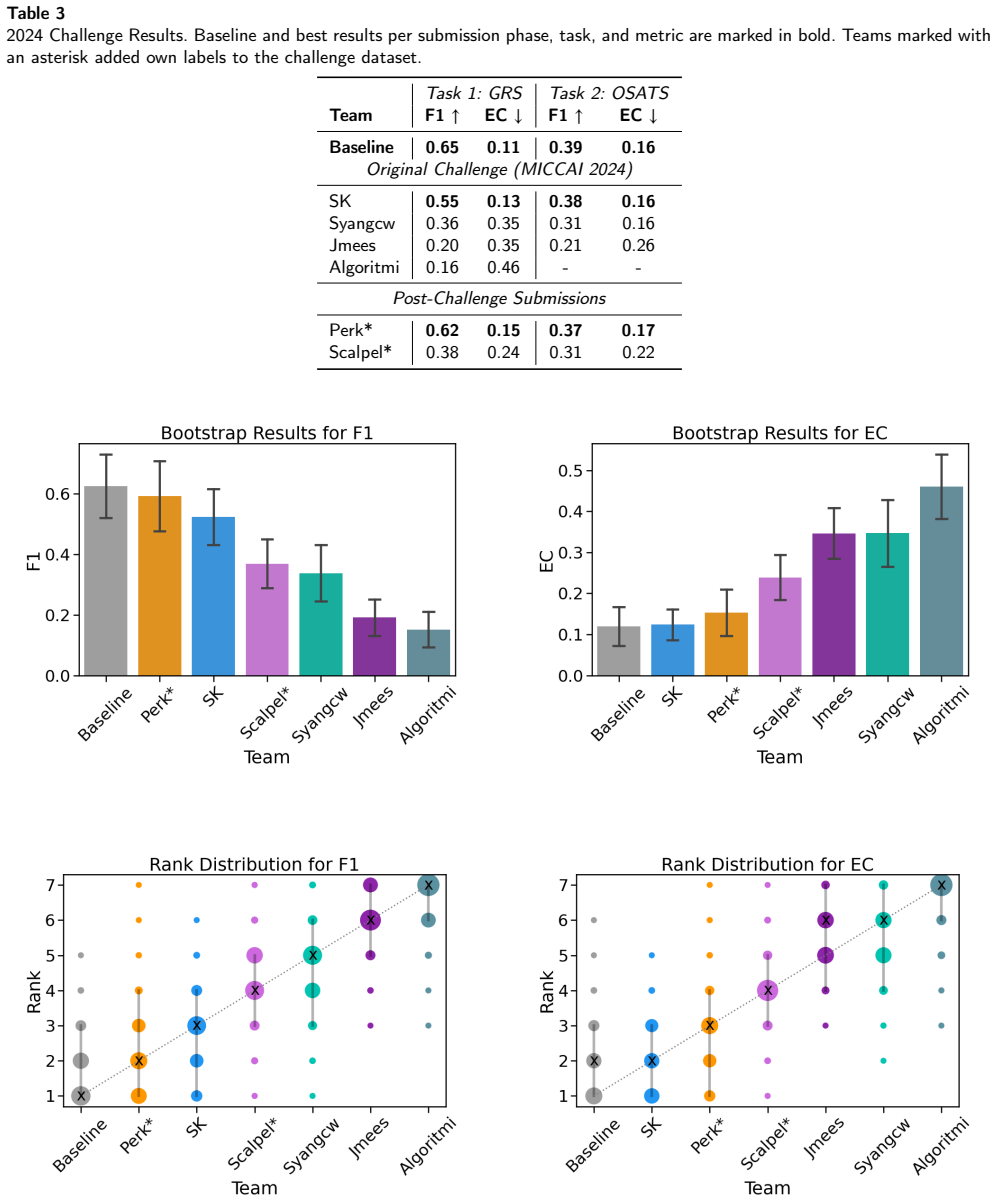
The central claim is that general-purpose spatiotemporal video models consistently achieved the strongest performance across the challenge tasks of four-class skill level classification and eight-category OSATS prediction, although conceptually diverse approaches reached competitive levels when well-executed; predicting fine-grained OSATS scores remains challenging but improves with more training data, while keypoint tracking is hindered by frequent occlusions and out-of-frame instances.
What carries the argument
General-purpose spatiotemporal video models operating on dry-lab suturing videos supplemented by instrument trajectories.
If this is right
- Skill level can be classified into four categories with high reliability using video models alone.
- Fine-grained prediction of the eight OSATS categories benefits substantially from larger amounts of training data.
- Keypoint tracking of hands and tools is currently limited by occlusions and out-of-frame motion, restricting motion-based skill analysis.
- Conceptually different methods can reach competitive accuracy when implemented and tuned effectively.
Where Pith is reading between the lines
- The results point toward hybrid systems that combine video features with trajectory data to strengthen future assessment tools.
- Expanding the dataset to include varied camera angles or real surgical footage could address current tracking failures.
- These benchmarks suggest that video-based assessment pipelines might be integrated into simulator platforms to give trainees immediate feedback.
Load-bearing premise
Dry-lab videos captured by a static GoPro camera and paired with instrument trajectories serve as a representative proxy for real clinical open surgery skill that generalizes beyond the training task.
What would settle it
Models trained only on this dry-lab dataset would show a large drop in accuracy when tested on videos recorded during actual open operations in the operating room.
Figures












read the original abstract
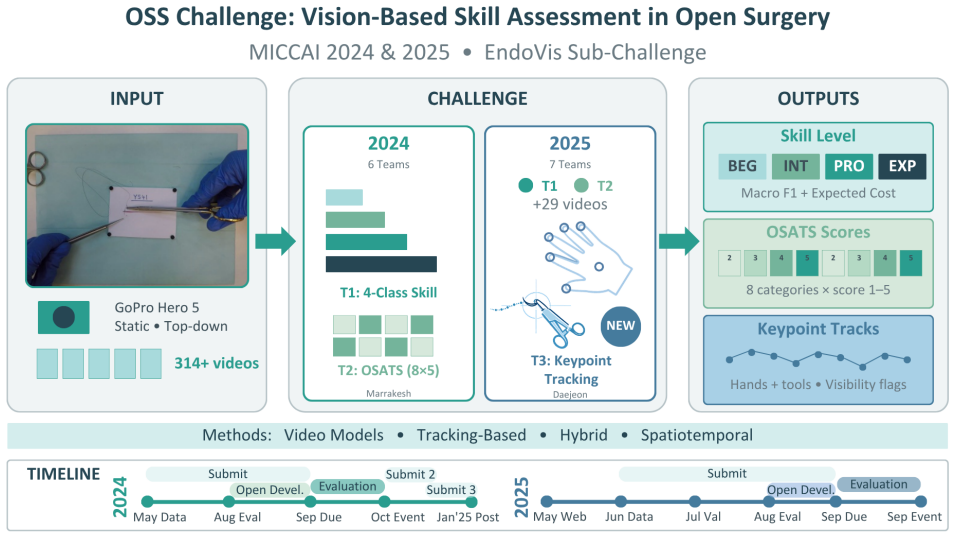
Achieving high levels of surgical skill through effective training is essential for optimal patient outcomes. Automated, data-driven skill assessment holds significant potential to improve surgical training. While machine learning-based methods are increasingly popular for assessing skills in minimally invasive surgery, their application to open surgery remains limited. We present the results of a dedicated MICCAI challenge designed to benchmark and advance vision-based skill assessment in open surgery. The challenge dataset comprises videos of an open suturing training task recorded with a static GoPro camera in a dry-lab setting, with instrument trajectories available in addition to the primary video modality. The OSS Challenge was hosted over two consecutive years, comprising two and three independent tasks, respectively: (1) classifying skill level into four classes, (2) predicting the full Objective Structured Assessment of Technical Skills across eight categories, and (3) tracking hands and surgical tools. Participants submitted diverse solutions including deep learning-based video models, tracking-driven methods, and hybrid approaches. General-purpose spatiotemporal video models consistently achieved the strongest performance, though conceptually diverse approaches reached competitive levels when well-executed. Predicting fine-grained OSATS scores remains challenging but benefits substantially from increased training data. Keypoint tracking proves difficult given frequent occlusions and out-of-frame instances, limiting current applicability for motion-based skill analysis. This work benchmarks innovative and diverse solutions for surgical skill assessment, highlighting both the promise and current limitations of video-based evaluation in open surgery and identifying critical directions for advancing automated skill assessment toward clinical impact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from the OSS Challenge 2024-2025, a MICCAI competition for vision-based surgical skill assessment in open suturing. The dataset consists of dry-lab videos recorded with a static GoPro camera, augmented by instrument trajectories. Two years of the challenge covered three tasks: four-class skill level classification, prediction of full OSATS scores across eight categories, and hand/tool keypoint tracking. Diverse participant submissions included spatiotemporal video models, tracking-driven methods, and hybrids. The central observation is that general-purpose spatiotemporal video models achieved the strongest aggregate performance, although well-executed conceptually diverse approaches remained competitive; fine-grained OSATS prediction improves with more data while tracking is limited by occlusions.
Significance. If the leaderboard outcomes hold, the work supplies a useful public benchmark for an under-studied domain (open-surgery skill assessment) that has lagged behind laparoscopic applications. By releasing a fixed dataset with multiple modalities and tasks, the challenge enables direct comparison of methods and surfaces concrete limitations (occlusions, data hunger for OSATS) that future research can target. The finding that off-the-shelf spatiotemporal models already lead provides a clear, actionable starting point for the community.
major comments (2)
- [Abstract / Evaluation protocol] Abstract and evaluation-protocol section: the claim that spatiotemporal models 'consistently achieved the strongest performance' rests on aggregate rankings, yet the manuscript does not report per-task statistical significance tests or confidence intervals on the performance gaps; without these, it is difficult to judge whether the observed differences are robust or could be explained by variance in participant submissions.
- [Dataset and evaluation protocol] Dataset and split description: full details on the train/validation/test partitioning ratios, number of videos per skill class, and exact definitions of the OSATS and tracking metrics (including handling of out-of-frame or occluded keypoints) are referenced only at high level; these omissions affect reproducibility of the reported rankings and the claim that increased training data substantially benefits OSATS prediction.
minor comments (3)
- [Abstract] Abstract: the sentence 'Predicting fine-grained OSATS scores remains challenging but benefits substantially from increased training data' would be stronger if it cited the specific data-volume ablation or participant results that support the 'substantially' qualifier.
- [Results] The manuscript should include a short table summarizing the number of participating teams, submissions per task, and top-three scores with metric names to give readers an immediate quantitative overview.
- [Discussion] Consider adding a brief discussion of how the static GoPro viewpoint and dry-lab setting may affect generalization to real operating-room conditions, even if only to reiterate the limitations already flagged.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and positive recommendation. We address the two major comments point-by-point below. Both points identify areas where additional detail will improve the manuscript, and we have incorporated the requested information in the revision.
read point-by-point responses
-
Referee: [Abstract / Evaluation protocol] Abstract and evaluation-protocol section: the claim that spatiotemporal models 'consistently achieved the strongest performance' rests on aggregate rankings, yet the manuscript does not report per-task statistical significance tests or confidence intervals on the performance gaps; without these, it is difficult to judge whether the observed differences are robust or could be explained by variance in participant submissions.
Authors: We agree that statistical support strengthens the claim. The reported rankings reflect performance on a fixed, held-out test set across all submissions. In the revised manuscript we will add per-task bootstrap confidence intervals (1000 resamples) for the top three methods and non-parametric paired tests (Wilcoxon signed-rank) between the leading spatiotemporal models and the next-best approaches. These additions will quantify whether the observed gaps are statistically distinguishable from submission variance. revision: yes
-
Referee: [Dataset and evaluation protocol] Dataset and split description: full details on the train/validation/test partitioning ratios, number of videos per skill class, and exact definitions of the OSATS and tracking metrics (including handling of out-of-frame or occluded keypoints) are referenced only at high level; these omissions affect reproducibility of the reported rankings and the claim that increased training data substantially benefits OSATS prediction.
Authors: We accept this criticism. The revised Dataset section will explicitly state the train/validation/test ratios (approximately 55/15/30 across both challenge years), the exact number of videos per skill class, and the precise metric formulations. For OSATS we will detail the 1–5 Likert scale per category and the averaging procedure; for tracking we will specify that occluded or out-of-frame keypoints are excluded from the error computation via the provided visibility flags. These clarifications will also make transparent the data-scaling experiments that support the OSATS improvement claim. revision: yes
Circularity Check
No significant circularity in challenge report
full rationale
The manuscript is a MICCAI challenge summary that reports empirical outcomes from independent participant submissions evaluated on a fixed, publicly released dry-lab dataset. Central observations (e.g., strongest performance by general-purpose spatiotemporal video models on skill classification and OSATS tasks) are direct leaderboard results rather than outputs of any internal derivation, fitted parameter, or self-referential equation. No load-bearing steps reduce to the paper's own inputs by construction; the text contains no equations, no self-citation chains invoked as uniqueness theorems, and no renaming of known results as novel derivations. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption OSATS categories provide a valid and reliable measure of technical surgical skill.
Reference graph
Works this paper leans on
-
[1]
Ahmed, K., Miskovic, D., Darzi, A., Athanasiou, T., Hanna, G.B.,
-
[2]
The American Journal of Surgery 202, 469– 480.e6
Observational tools for assessment of procedural skills: a systematic review. The American Journal of Surgery 202, 469– 480.e6. doi:10.1016/J.AMJSURG.2010.10.020. :Preprint submitted to Elsevier Page 28 of 31
-
[3]
Keep your eye on the best: Contrastive regression transformer for skill assessmentinroboticsurgery
Anastasiou, D., Jin, Y., Stoyanov, D., Mazomenos, E., 2023. Keep your eye on the best: Contrastive regression transformer for skill assessmentinroboticsurgery. IEEERoboticsandAutomationLetters 8, 1755–1762. doi:10.1109/LRA.2023.3242466
-
[4]
Benmansour, M., Malti, A., Jannin, P., 2023. Deep neural network architecture for automated soft surgical skills evaluation using ob- jective structured assessment of technical skills criteria. Interna- tionalJournalofComputerAssistedRadiologyandSurgery18,929–
work page 2023
-
[5]
URL:https://doi.org/10.1007/s11548-022-02827-5, doi:10. 1007/s11548-022-02827-5
-
[6]
Is space-time attention all you need for video understanding?, in: Meila, M., Zhang, T
Bertasius, G., Wang, H., Torresani, L., 2021. Is space-time attention all you need for video understanding?, in: Meila, M., Zhang, T. (Eds.), Proceedings of the 38th International Conference on Machine Learning, PMLR. pp. 813–824. URL:https://proceedings.mlr. press/v139/bertasius21a.html
work page 2021
-
[7]
Surgical skill and complication rates after bariatric surgery
Birkmeyer, J.D., Finks, J.F., O’Reilly, A., Oerline, M., et al., 2013. Surgical skill and complication rates after bariatric surgery. New England Journal of Medicine 369, 1434–1442. URL:https:// www.nejm.org/doi/10.1056/NEJMsa1300625,doi:10.1056/NEJMSA1300625/ SUPPL_FILE/NEJMSA1300625_DISCLOSURES.PDF
-
[8]
Byvshev,P.,Mettes,P.,Xiao,Y.,2022.Are3dconvolutionalnetworks inherently biased towards appearance? Computer Vision and Im- age Understanding 220, 103437. URL:https://www.sciencedirect. com/science/article/pii/S1077314222000534,doi:https://doi.org/10. 1016/j.cviu.2022.103437
-
[9]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
Carreira, J., Zisserman, A., Com, Z., Deepmind, 2017. Quo vadis, actionrecognition?anewmodelandthekineticsdataset. Proceedings -30thIEEEConferenceonComputerVisionandPatternRecognition, CVPR 2017 2017-January, 4724–4733. URL:https://arxiv.org/ abs/1705.07750v3, doi:10.1109/CVPR.2017.502
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr.2017.502 2017
-
[10]
Chen, T., Guestrin, C., 2016. Xgboost: A scalable tree boosting system, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Associa- tion for Computing Machinery, New York, NY, USA. pp. 785–
work page 2016
-
[11]
URL:https://doi.org/10.1145/2939672.2939785, doi:10.1145/ 2939672.2939785
-
[12]
Cspnext:Anewefficienttokenhybridbackbone
Chen, X., Yang, C., Mo, J., Sun, Y., Karmouni, H., Jiang, Y., Zheng, Z.,2024. Cspnext:Anewefficienttokenhybridbackbone. Eng.Appl. Artif. Intell. 132. URL:https://doi.org/10.1016/j.engappai.2024. 107886, doi:10.1016/j.engappai.2024.107886
-
[13]
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R., 2022. Masked-attention mask transformer for universal image segmenta- tion,in:2022IEEE/CVFConferenceonComputerVisionandPattern Recognition (CVPR), pp. 1280–1289. doi:10.1109/CVPR52688.2022. 00135
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Cherti,M.,Beaumont,R.,Wightman,R.,Wortsman,M.,Ilharco,G., Gordon, C., Schuhmann, C., Schmidt, L., Jitsev, J., 2023. Repro- duciblescalinglawsforcontrastivelanguage-imagelearning,in:2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2818–2829. doi:10.1109/CVPR52729.2023.00276
-
[15]
In: Moschitti, A., Pang, B., Daelemans, W
Cho,K.,vanMerriënboer,B.,Gulcehre,C.,Bahdanau,D.,Bougares, F., Schwenk, H., Bengio, Y., 2014. Learning phrase representations using RNN encoder–decoder for statistical machine translation, in: Moschitti, A., Pang, B., Daelemans, W. (Eds.), Proceedings of the 2014 Conference on Empirical Methods in Natural Language Pro- cessing(EMNLP),AssociationforComputa...
-
[16]
Czempiel, T., Paschali, M., Keicher, M., Simson, W., Feussner, H., Kim, S.T., Navab, N., 2020. Tecno: Surgical phase recognition with multi-stage temporal convolutional networks, in: Martel, A.L., Abolmaesumi, P., Stoyanov, D., Mateus, D., Zuluaga, M.A., Zhou, S.K., Racoceanu, D., Joskowicz, L. (Eds.), Medical Image Comput- ing and Computer Assisted Inter...
work page 2020
-
[17]
Low-fidelity bench models for basic surgical skills trainingduringundergraduatemedicaleducation
Denadai, R., Saad-Hossne, R., Todelo, A.P., Kirylko, L., Souto, L.R.M., 2014. Low-fidelity bench models for basic surgical skills trainingduringundergraduatemedicaleducation. RevistadoColégio Brasileiro de Cirurgiões 41, 137–145
work page 2014
-
[18]
An Introduction to the Bootstrap
Efron, B., Tibshirani, R.J., 1994. An Introduction to the Bootstrap. 1st ed., Chapman and Hall/CRC. URL:https://doi.org/10.1201/ 9780429246593, doi:10.1201/9780429246593
-
[19]
The impact of simulation-based training in medical education: A review
Elendu, C., Amaechi, D.C., Okatta, A.U., Amaechi, E.C., Elendu, T.C., Ezeh, C.P., Elendu, I.D., 2024. The impact of simulation-based training in medical education: A review. Medicine 103, e38813. doi:10.1097/MD.0000000000038813
-
[20]
Two-framemotionestimationbasedonpolyno- mial expansion, in: Bigun, J., Gustavsson, T
Farnebäck,G.,2003. Two-framemotionestimationbasedonpolyno- mial expansion, in: Bigun, J., Gustavsson, T. (Eds.), Image Analysis, Springer Berlin Heidelberg, Berlin, Heidelberg. pp. 363–370
work page 2003
-
[21]
Fathabadi, F.R., Grantner, J.L., Shebrain, S.A., Abdel-Qader, I.,
-
[22]
Surgical skill assessment system using fuzzy logic in a multi- class detection of laparoscopic box-trainer instruments. Conference Proceedings - IEEE International Conference on Systems, Man and Cybernetics , 1248–1253doi:10.1109/SMC52423.2021.9658766
-
[23]
X3d: Expanding architectures for efficient video recognition doi:10.48550/arXiv.2004.04730
Feichtenhofer, C., 2020. X3d: Expanding architectures for efficient video recognition doi:10.48550/arXiv.2004.04730
-
[24]
A benchmark for video-based laparoscopic skill analysis and assessment
Funke, I., Bodenstedt, S., von Bechtolsheim, F., Oehme, F., Mar- uschke, M., Herrlich, S., Weitz, J., Distler, M., Mees, S.T., Spei- del, S., 2026. A benchmark for video-based laparoscopic skill analysis and assessment. URL:https://arxiv.org/abs/2602.09927, arXiv:2602.09927
-
[25]
Funke,I.,Bodenstedt,S.,Oehme,F.,vonBechtolsheim,F.,Weitz,J., Speidel, S., 2019a. Using 3d convolutional neural networks to learn spatiotemporal features for automatic surgical gesture recognition in video,in:Shen,D.,Liu,T.,Peters,T.M.,Staib,L.H.,Essert,C.,Zhou, S., Yap, P.T., Khan, A. (Eds.), Medical Image Computing and Com- puter Assisted Intervention – ...
work page 2019
-
[26]
Video-based surgical skill assessment using 3d convolutional neural networks
Funke, I., Mees, S.T., Weitz, J., Speidel, S., 2019b. Video-based surgical skill assessment using 3d convolutional neural networks. International Journal of Computer Assisted Radiology and Surgery 14, 1217–1225. URL:https://link.springer.com/article/10.1007/ s11548-019-01995-1, doi:10.1007/S11548-019-01995-1/FIGURES/4
-
[27]
Goh, A.C., Goldfarb, D.W., Sander, J.C., Miles, B.J., Dunkin, B.J.,
-
[28]
URL:https://www.auajournals.org/doi/ 10.1016/j.juro.2011.09.032, doi:10.1016/J.JURO.2011.09.032
Global evaluative assessment of robotic skills: Validation of a clinicalassessmenttooltomeasureroboticsurgicalskills.TheJournal of Urology 187, 247–252. URL:https://www.auajournals.org/doi/ 10.1016/j.juro.2011.09.032, doi:10.1016/J.JURO.2011.09.032
-
[29]
Video- based fully automatic assessment of open surgery suturing skills
Goldbraikh,A.,D’Angelo,A.L.,Pugh,C.M.,Laufer,S.,2022. Video- based fully automatic assessment of open surgery suturing skills. International Journal of Computer Assisted Radiology and Surgery 17, 437–448. URL:https://link.springer.com/article/10.1007/ s11548-022-02559-6, doi:10.1007/S11548-022-02559-6/FIGURES/5
-
[30]
Automated skills assessment in open surgery: A scoping review
Hamza, H., Shabir, D., Aboumarzouk, O., Al-Ansari, A., Shaban, K., Navkar, N.V., 2025. Automated skills assessment in open surgery: A scoping review. Engineering Applications of Artifi- cial Intelligence 153, 110893. URL:https://www.sciencedirect. com/science/article/pii/S0952197625008930,doi:https://doi.org/10. 1016/j.engappai.2025.110893
- [31]
-
[32]
URL:https://api.semanticscholar.org/CorpusID:264031695
-
[33]
Deep residual learning for image recognition,
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep residual learning for image recognition. Proceedings of the IEEE Computer Soci- ety Conference on Computer Vision and Pattern Recognition 2016- December, 770–778. doi:10.1109/CVPR.2016.90
-
[34]
Aixsuture: vision-based assessment of open suturing skills
Hoffmann,H.,Funke,I.,Peters,P.,Venkatesh,D.K.,Egger,J.,Rivoir, D., Röhrig, R., Hölzle, F., Bodenstedt, S., Willemer, M.C., Speidel, S., Puladi, B., 2024. Aixsuture: vision-based assessment of open suturing skills. International Journal of Computer Assisted Radiol- ogy and Surgery 19, 1045–1052. URL:https://doi.org/10.1007/ s11548-024-03093-3, doi:10.1007/...
-
[35]
Rtmpose: Real-time multi-person pose estimation based on mmpose,
Jiang, T., Lu, P., Zhang, L., Ma, N., Han, R., Lyu, C., Li, Y., Chen, K., 2023. Rtmpose: Real-time multi-person pose estimation based on mmpose. ArXiv abs/2303.07399. URL:https://api. semanticscholar.org/CorpusID:257504954. :Preprint submitted to Elsevier Page 29 of 31
-
[36]
Ke,G.,Meng,Q.,Finley,T.,Wang,T.,Chen,W.,Ma,W.,Ye,Q.,Liu, T.Y., 2017. Lightgbm: a highly efficient gradient boosting decision tree, in: Proceedings of the 31st International Conference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, NY, USA. p. 3149–3157
work page 2017
-
[37]
A vision transformer for decoding surgeon activity from surgical videos
Kiyasseh, D., Ma, R., Haque, T.F., Miles, B.J., Wagner, C., Donoho, D.A., Anandkumar, A., Hung, A.J., 2023. A vision transformer for decoding surgeon activity from surgical videos. Nature Biomedical Engineering 7, 780–796. URL:https://www.nature.com/articles/ s41551-023-01010-8, doi:10.1038/s41551-023-01010-8
-
[38]
Machine learn- ing for technical skill assessment in surgery: a systematic re- view
Lam, K., Chen, J., Wang, Z., Iqbal, F.M., Darzi, A., Lo, B., Purkayastha, S., Kinross, J.M., 2022. Machine learn- ing for technical skill assessment in surgery: a systematic re- view. URL:https://www.nature.com/articles/s41746-022-00566-0. pdf, doi:10.1038/s41746-022-00566-0
-
[39]
Automation of surgical skill assessment using a three-stage machine learning algorithm
Lavanchy,J.L.,Zindel,J.,Kirtac,K.,Twick,I.,Hosgor,E.,Candinas, D., Beldi, G., 2021. Automation of surgical skill assessment using a three-stage machine learning algorithm. Scientific Reports 11, 1–9. URL:https://www.nature.com/articles/s41598-021-84295-6, doi:10. 1038/s41598-021-84295-6
work page 2021
-
[40]
Automatic assessment of per- formanceintheflstrainerusingcomputervision
Lazar, A., Sroka, G., Laufer, S., 2023. Automatic assessment of per- formanceintheflstrainerusingcomputervision. SurgicalEndoscopy 37, 6476–6482. URL:https://doi.org/10.1007/s00464-023-10132-8, doi:10.1007/s00464-023-10132-8
-
[41]
Automated methods of technical skill as- sessment in surgery: A systematic review
Levin, M., McKechnie, T., Khalid, S., Grantcharov, T.P., Gold- enberg, M., 2019. Automated methods of technical skill as- sessment in surgery: A systematic review. Journal of Surgi- cal Education 76, 1629–1639. URL:https://www.sciencedirect. com/science/article/pii/S1931720419301643,doi:https://doi.org/10. 1016/j.jsurg.2019.06.011
work page 2019
-
[42]
Hrnext: High-resolution context network for crowd pose estimation
Li, Q., Zhang, Z., Zhang, F., Xiao, F., 2023. Hrnext: High-resolution context network for crowd pose estimation. IEEE Transactions on Multimedia 25, 1521–1528. doi:10.1109/TMM.2023.3248144
-
[43]
Mvitv2: Improved multiscale vision transformers for classification and detection
Li, Y., Wu, C., Fan, H., Mangalam, K., Xiong, B., Malik, J., Feicht- enhofer, C., 2021. Mvitv2: Improved multiscale vision transformers for classification and detection. 2022 IEEE/CVF Conference on ComputerVisionandPatternRecognition(CVPR),4794–4804URL: https://api.semanticscholar.org/CorpusID:244799268
work page 2021
-
[44]
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.,
-
[45]
A convnet for the 2020s, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11976–11986
-
[46]
Hota:Ahigherordermetricforevaluatingmulti- object tracking
Luiten, J., Osep, A., Dendorfer, P., Torr, P., Geiger, A., Leal-Taixé, L.,Leibe,B.,2020. Hota:Ahigherordermetricforevaluatingmulti- object tracking. International Journal of Computer Vision , 1–31
work page 2020
-
[47]
Rtmdet: An empirical study of designing real-time object detectors.arXiv preprint arXiv:2212.07784,
Lyu, C., Zhang, W., Huang, H., Zhou, Y., Wang, Y., Liu, Y., Zhang, S., Chen, K., 2022. Rtmdet: An empirical study of designing real- time object detectors. ArXiv abs/2212.07784. URL:https://api. semanticscholar.org/CorpusID:254685870
-
[48]
Maier-Hein, L., Eisenmann, M., Reinke, A., Onogur, S., Stankovic, M., Scholz, P., Arbel, T., Bogunovic, H., Bradley, A.P., Carass, A., Feldmann, C., Frangi, A.F., Full, P.M., van Ginneken, B., Hanbury, A., Honauer, K., Kozubek, M., Landman, B.A., März, K., Maier, O., Maier-Hein, K., Menze, B.H., Müller, H., Neher, P.F., Niessen, W., Rajpoot, N., Sharp, G....
-
[49]
Why rankings of biomedical image analysis competitions should be interpreted with care. Nature Communications 9, 5217. URL:https://www.nature.com/articles/s41467-018-07619-7, doi:10. 1038/s41467-018-07619-7. publisher: Nature Publishing Group
-
[50]
Metrics reloaded: Pitfalls and recommendationsfor imageanalysisvalidationURL:https://arxiv
Maier-Hein, L., Reinke, A., Godau, P., Tizabi, M.D., Büttner, F., Christodoulou, E., Glocker, B., Isensee, F., Kleesiek, J., Kozubek, M., Reyes, M., Riegler, M.A., Wiesenfarth, M., Kavur, E., Sudre, C.H., Baumgartner, M., Eisenmann, M., Heckmann-Nötzel, D., Räd- sch, A.T., Acion, L., Antonelli, M., Arbel, T., Bakas, S., Benis, A., Blaschko, M., Cardoso, M...
-
[51]
Bias:Transparentreportingofbiomedicalimageanalysis challenges
Maier-Hein, L., Reinke, A., Kozubek, M., Martel, A.L., Arbel, T., Eisenmann, M., Hanbury, A., Jannin, P., Müller, H., Onogur, S., Saez-Rodriguez,J.,vanGinneken,B.,Kopp-Schneider,A.,Landman, B.A.,2020. Bias:Transparentreportingofbiomedicalimageanalysis challenges. Medical Image Analysis 66, 101796. URL:https: //www.sciencedirect.com/science/article/pii/S13...
-
[52]
Objective structured assessment of technicalskill(osats)forsurgicalresidents
Martin, J., Regehr, G., Reznick, R., Macrae, H., Murnaghan, J., Hutchison, C., Brown, M., 1997. Objective structured assessment of technicalskill(osats)forsurgicalresidents. Britishjournalofsurgery 84, 273–278
work page 1997
-
[53]
Forming inferences about some intraclass correlation coefficients
Mcgraw, K., Wong, S., 1996. Forming inferences about some intraclass correlation coefficients. Psychological Methods 1, 30–46. doi:10.1037/1082-989X.1.1.30
-
[54]
Oğul, B.B., Gilgien, M., Özdemir, S., 2022. Ranking surgical skills using an attention-enhanced siamese network with piecewise aggre- gated kinematic data. International Journal of Computer Assisted Radiology and Surgery 17, 1039–1048. URL:https://doi.org/10. 1007/s11548-022-02581-8, doi:10.1007/s11548-022-02581-8
-
[55]
Papo, R., Gershov, S., Friedman, T., Or, I., Bolotin, G., Laufer, S.,
- [56]
-
[57]
Pedrett, R., Mascagni, P., Beldi, G., Padoy, N., Lavanchy, J.L.,
-
[58]
Technical skill assessment in minimally invasive surgery using artificial intelligence: a systematic review. Surgical Endoscopy URL:https://link.springer.com/10.1007/s00464-023-10335-z, doi:10.1007/S00464-023-10335-Z
-
[59]
Peruzzo, E., Sangineto, E., Liu, Y., Nadai, M.D., Bi, W., Lepri, B., Sebe, N., 2024. Spatial entropy as an inductive bias for vision transformers.MachineLearning113,6945–6975.URL:https://doi. org/10.1007/s10994-024-06570-7, doi:10.1007/s10994-024-06570-7
-
[60]
Peters, P., Lemos, M., Bönsch, A., Ooms, M., Ulbrich, M., Rashad, A., Krause, F., Lipprandt, M., Kuhlen, T.W., Röhrig, R., Hölzle, F., Puladi, B., 2023a. Dataset from: Effect of head-mounted displays on students’ acquisition of surgical suturing techniques compared to an e-learning and tutor-led course: A randomized controlled trial URL: https://zenodo.or...
-
[61]
Peters, P., Lemos, M., Bönsch, A., Ooms, M., Ulbrich, M., Rashad, A., Krause, F., Lipprandt, M., Kuhlen, T.W., Röhrig, R., Hölzle, F., Puladi, B., med med dent Behrus Puladi, 2023b. Effect of head-mounted displays on students’ acquisition of surgical suturing techniques compared to an e-learning and tutor-led course: A ran- domized controlled trial. Inter...
-
[62]
Icc4irr: A shinyapplicationtoestimateinterraterreliabilityusingintraclasscor- relation coefficients
Psychogyiopoulos, A., Koopman, L., Ten Hove, D., 2025. Icc4irr: A shinyapplicationtoestimateinterraterreliabilityusingintraclasscor- relation coefficients. URL:https://tasospsy.shinyapps.io/icc4irr_ app/
work page 2025
-
[63]
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C.Y., Girshick, R., Dollar, P., Feichtenhofer, C., 2025. SAM 2: Segment anything in images and videos, in: The Thirteenth International Conference on Learning Representations. URL:https://openrevie...
work page 2025
-
[64]
You Only Look Once: Unified, Real-Time Object Detection
Redmon, J., Divvala, S., Girshick, R., Farhadi, A., 2015. You only look once: Unified, real-time object detection URL:http://arxiv. :Preprint submitted to Elsevier Page 30 of 31 org/abs/1506.02640
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[65]
Rezaei, S., N. Brown, K., 2025. Generative reward machine for re- inforcementlearningforphysicalinternetdistributioncentre,in:Ma- chine Learning, Optimization, and Data Science: 10th International Conference, LOD 2024, Castiglione Della Pescaia, Italy, Septem- ber 22–25, 2024, Revised Selected Papers, Part I, Springer-Verlag, Berlin, Heidelberg. p. 317–33...
-
[66]
Benchmarking and error diagnosis in multi-instance pose estimation
Ronchi, M.R., Perona, P., 2017. Benchmarking and error diagnosis in multi-instance pose estimation. 2017 IEEE International Con- ference on Computer Vision (ICCV) , 369–378URL:https://api. semanticscholar.org/CorpusID:863539
work page 2017
-
[67]
ImageNet Large Scale Visual Recognition Challenge,
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei- Fei, L., 2015. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV) 115, 211–252. doi:10.1007/s11263-015-0816-y
-
[68]
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., Schramowski, P., Kundurthy, S., Crowson, K., Schmidt, L., Kacz- marczyk, R., Jitsev, J., 2022. Laion-5b: an open large-scale dataset for training next generation image-text models, in: Proceedings of the 36th International Confer...
work page 2022
-
[69]
Seymour, N.E., Gallagher, A.G., Roman, S.A., O’Brien, M.K., Bansal, V.K., Andersen, D.K., Satava, R.M., 2002. Virtual reality training improves operating room performance: results of a random- ized,double-blindedstudy. AnnalsofSurgery236,458–463. doi:10. 1097/00000658-200210000-00008
work page 2002
-
[70]
Intraclass correlations: uses in assessingraterreliability
Shrout, P.E., Fleiss, J.L., 1979. Intraclass correlations: uses in assessingraterreliability. Psychologicalbulletin862,420–8. doi:10. 1037//0033-2909.86.2.420
work page 1979
-
[71]
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.,
-
[72]
Rethinking the inception architecture for computer vision. 2016 IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR) , 2818–2826URL:https://api.semanticscholar.org/ CorpusID:206593880
work page 2016
-
[73]
Ten Hove, D., Jorgensen, T., van der Ark, A., 2024. Updated guide- lines on selecting an intraclass correlation coefficient for interrater reliability, with applications to incomplete observational designs. Psychological Methods 29, 967–979. doi:10.1037/met0000516
-
[74]
Convnext: A contemporary architecture for convolutional neural networks for imageclassification
Todi, A., Narula, N., Sharma, M., Gupta, U., 2023. Convnext: A contemporary architecture for convolutional neural networks for imageclassification. 20233rdInternationalConferenceonInnovative Sustainable Computational Technologies (CISCT) , 1–6URL:https: //api.semanticscholar.org/CorpusID:266486570
work page 2023
-
[75]
Tong, Z., Song, Y., Wang, J., Wang, L., 2022. Videomae: masked autoencodersaredata-efficientlearnersforself-supervisedvideopre- training, in: Proceedings of the 36th International Conference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, NY, USA
work page 2022
-
[76]
A closer look at spatiotemporal convolutions for action recognition, in: CVPR
Tran,D.,Wang,H.,Torresani,L.,Ray,J.,LeCun,Y.,Paluri,M.,2018. A closer look at spatiotemporal convolutions for action recognition, in: CVPR
work page 2018
-
[77]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I., 2017. Attention is all you need, in: Guyon, I., Luxburg, U.V., Bengio, S., Wal- lach, H., Fergus, R., Vishwanathan, S., Garnett, R. (Eds.), Ad- vancesinNeuralInformationProcessingSystems,CurranAssociates, Inc. URL:https://proceedings.neurips.cc/paper...
work page 2017
-
[78]
Wang,L.,Xiong,Y.,Wang,Z.,Qiao,Y.,Lin,D.,Tang,X.,VanGool, L., 2016. Temporal segment networks: Towards good practices for deepactionrecognition,in:Europeanconferenceoncomputervision, Springer. pp. 20–36
work page 2016
-
[79]
Yang, S., Luo, L., Wang, Q., Chen, H., 2024. Surgformer: Surgical TransformerwithHierarchicalTemporalAttentionforSurgicalPhase Recognition , in: proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024, Springer Nature Switzerland
work page 2024
-
[80]
Swin3d: A pretrained transformer backbone for 3d indoor scene understanding
Yang, Y.Q., Guo, Y.X., Xiong, J., Liu, Y., Pan, H., Wang, P.S., Tong, X., Guo, B., 2023. Swin3d: A pretrained transformer backbone for 3d indoor scene understanding. ArXiv abs/2304.06906. URL: https://api.semanticscholar.org/CorpusID:258170015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.