Reference-Based Prosody and Rhythm Evaluation for Spoken Dialogue Systems
Pith reviewed 2026-07-01 06:04 UTC · model grok-4.3
The pith
Matched reference regimes from dyadic conversations allow percentile-based evaluation of prosody and rhythm in speech-to-speech outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
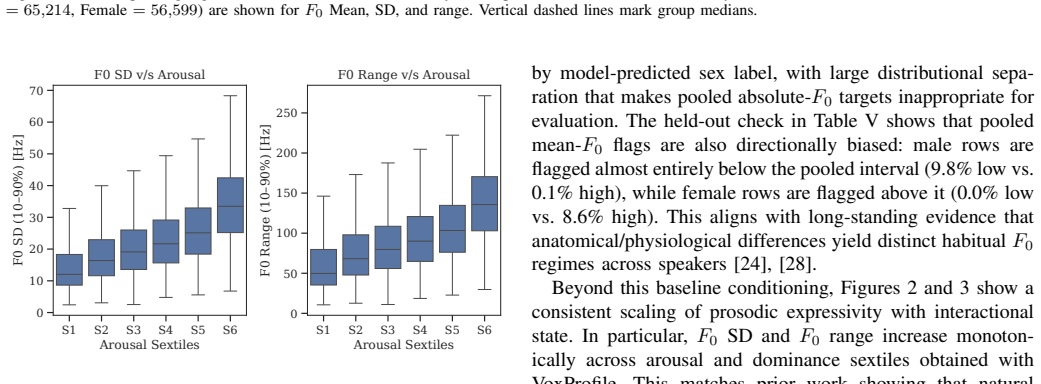
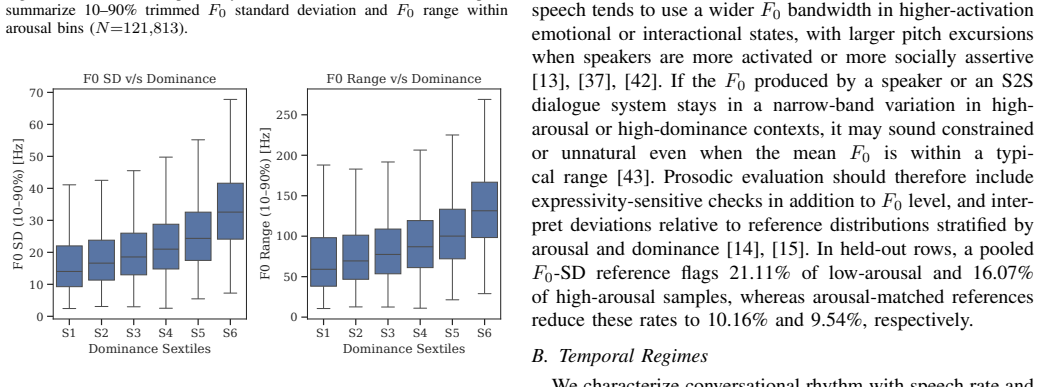
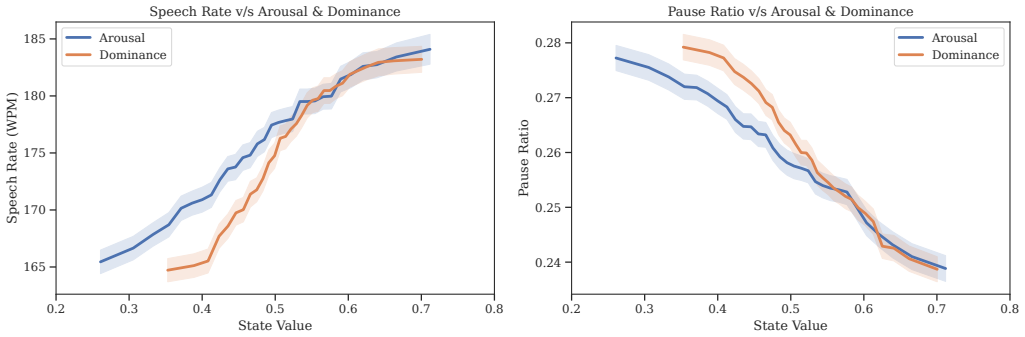
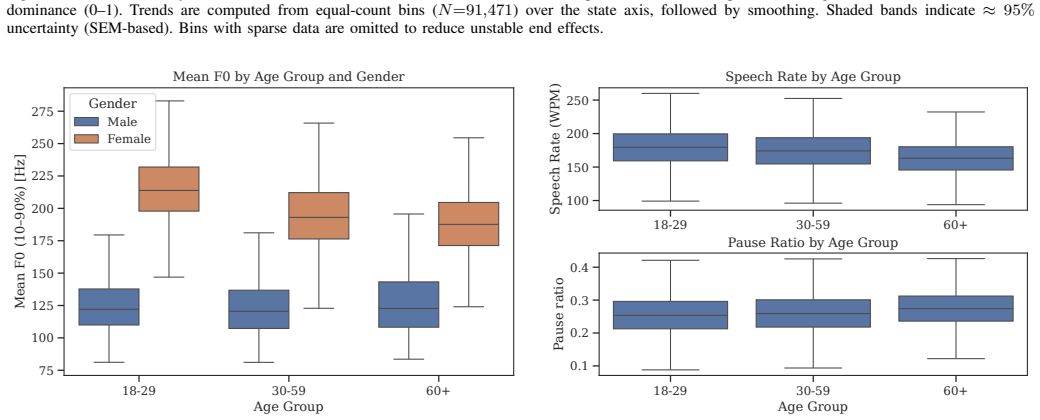
The paper constructs matched reference regimes for F0 mean, F0 expressivity, speech rate, articulation rate, pause ratio, and mean pause duration from the Seamless Interaction dataset by conditioning on speaker traits and interaction state. It defines a percentile-based protocol that extracts the same metrics from an S2S output waveform and compares them to the closest matched human reference stratum, reporting percentile deviations or out-of-regime flags between the 5th and 95th percentiles.
What carries the argument
Matched reference regimes conditioned on speaker traits and interaction state, used in a percentile-based comparison protocol to flag deviations in prosody and rhythm metrics.
If this is right
- Matched references produce flag rates near the nominal 10% on held-out human data, unlike pooled references.
- Deviation directions become interpretable because they are relative to the appropriate stratum.
- Pooled references over-flag state-conditioned F0 expressivity and rhythm.
- The method provides behavioral plausibility checks that complement perceptual evaluations.
Where Pith is reading between the lines
- Similar matching could be applied to other languages or datasets if sufficient dyadic conversation data exists.
- Integration with automatic speaker trait prediction might allow real-time regime selection for evaluation.
- Combining this with user studies could validate whether lower flag rates correlate with higher perceived naturalness.
Load-bearing premise
That matching reference regimes on speaker traits and interaction state from the Seamless Interaction dataset produces strata appropriate for evaluating behavioral plausibility of any S2S output waveform.
What would settle it
Evaluating a set of S2S outputs known to have unnatural prosody and checking if the matched reference method flags them at rates significantly above 10% while pooled does not align with human judgments of plausibility.
Figures

read the original abstract
Speech-to-speech (S2S) AI agents are advancing rapidly, yet evaluation lacks interpretable speech-native measures for conversational prosody and rhythm. Because $F_0$, speaking rate, articulation rate, and pausing shift with model-predicted speaker traits and interaction state, pooled human statistics can be poorly calibrated for evaluating a particular output. Using 4000+ hours of dyadic English conversation from the Seamless Interaction dataset, we construct matched reference regimes for $F_0$ mean, $F_0$ expressivity, speech rate, articulation rate, pause ratio, and mean pause duration. We then define a percentile-based evaluation protocol: extract the same metrics from an S2S output waveform, compare them to the closest matched human reference stratum, and report percentile deviations or 5th-95th percentile out-of-regime flags. On held-out human rows, pooled references over-flag state-conditioned $F_0$ expressivity and rhythm, while matched references return flag rates closer to the nominal 10% and make deviation direction interpretable. These outputs serve as behavioral plausibility checks that complement, rather than replace, perceptual and user-centered evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reference-based evaluation method for prosody and rhythm in speech-to-speech (S2S) dialogue systems. It leverages over 4000 hours of dyadic English conversation from the Seamless Interaction dataset to build matched reference regimes conditioned on speaker traits and interaction state for six metrics: F0 mean, F0 expressivity, speech rate, articulation rate, pause ratio, and mean pause duration. The protocol extracts these metrics from an S2S output waveform, compares them to the closest matched human reference stratum, and flags deviations outside the 5th-95th percentiles or reports percentile positions. Validation on held-out human data demonstrates that matched references yield flag rates near the target 10% and interpretable directions, whereas pooled references over-flag state-conditioned features.
Significance. This work addresses a gap in interpretable, speech-native evaluation metrics for conversational prosody that account for contextual variation, which is important as S2S systems advance. The use of a large, independent external dataset for references and the percentile-based, falsifiable flagging mechanism are strengths. If the matched strata prove suitable for S2S outputs, the method could complement perceptual evaluations with behavioral plausibility checks. The current validation, however, is confined to human data.
major comments (1)
- Abstract: The reported experiments validate the calibration of matched vs. pooled references exclusively on held-out human rows from the Seamless Interaction dataset. This does not test whether the same strata are appropriate for evaluating S2S-generated waveforms, which may exhibit different conditional statistics, synthesis artifacts, or context sensitivity not captured by the conditioning variables (speaker traits and interaction state). This assumption is load-bearing for the paper's intended application.
minor comments (2)
- Abstract: Details on the exact matching procedure, how strata are defined, and the construction rules for reference regimes are not provided, limiting assessment of reproducibility.
- Abstract: The nominal 10% flag rate is mentioned but the rationale for the 5th-95th percentile thresholds is not explained.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The single major comment correctly identifies a key limitation in the scope of our validation experiments. We agree that this assumption is load-bearing and will revise the manuscript accordingly to make the limitation explicit while preserving the contribution of the matched-reference protocol.
read point-by-point responses
-
Referee: [—] Abstract: The reported experiments validate the calibration of matched vs. pooled references exclusively on held-out human rows from the Seamless Interaction dataset. This does not test whether the same strata are appropriate for evaluating S2S-generated waveforms, which may exhibit different conditional statistics, synthesis artifacts, or context sensitivity not captured by the conditioning variables (speaker traits and interaction state). This assumption is load-bearing for the paper's intended application.
Authors: We agree with this assessment. The held-out human validation shows that the strata are well-calibrated for natural speech (flag rates near the nominal 10% and interpretable directions), but it does not directly confirm suitability for S2S waveforms that may contain synthesis artifacts or unmodeled context sensitivity. In the revision we will (1) update the abstract to state that validation is performed on held-out human data, (2) add an explicit limitations paragraph in the discussion section acknowledging that the method assumes the chosen conditioning variables capture the relevant variation for the target S2S outputs, and (3) note that direct validation on S2S-generated speech remains future work once suitable system outputs become available. These changes will be made without altering the core technical contribution. revision: yes
Circularity Check
No significant circularity; derivation uses external dataset
full rationale
The paper builds matched reference regimes directly from the independent Seamless Interaction human conversation dataset and defines a percentile protocol on those strata. The reported flag rates near the nominal 10% on held-out rows from the same dataset follow from the percentile construction and data partitioning but do not constitute a fitted parameter renamed as a prediction of the S2S evaluation result itself. No self-citations, uniqueness theorems, or ansatzes appear in the provided text, and the central method does not reduce to its own inputs by construction. The applicability to S2S waveforms is an external assumption rather than an internal circular step.
Axiom & Free-Parameter Ledger
free parameters (1)
- strata construction rules
axioms (1)
- domain assumption The acoustic metrics (F0, rates, pauses) adequately capture prosody and rhythm variation relevant to plausibility
Reference graph
Works this paper leans on
-
[1]
Anticipation in turn- taking: mechanisms and information sources,
C. Riest, A. B. Jorschick, and J. P. de Ruiter, “Anticipation in turn- taking: mechanisms and information sources,”Frontiers in Psychology, vol. 6, Feb. 2015
2015
-
[2]
Turn-taking in Human Communication – Origins and Implications for Language Processing,
S. C. Levinson, “Turn-taking in Human Communication – Origins and Implications for Language Processing,”Trends in Cognitive Sciences, vol. 20, no. 1, pp. 6–14, Jan. 2016. [Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/S1364661315002764
2016
-
[3]
H. Koiso, Y . Horiuchi, S. Tutiya, A. Ichikawa, and Y . Den, “An Analysis of Turn-Taking and Backchannels Based on Prosodic and Syntactic Features in Japanese Map Task Dialogs,”Language and Speech, vol. 41, no. 3-4, pp. 295–321, Jul. 1998. [Online]. Available: https://doi.org/10.1177/002383099804100404
-
[4]
Combining conversational speech with read speech to improve prosody in Text-to-Speech synthesis,
J. O’Mahony, C. Lai, and S. King, “Combining conversational speech with read speech to improve prosody in Text-to-Speech synthesis,” in Interspeech 2022. ISCA, Sep. 2022, pp. 3388–3392
2022
-
[5]
Comparison of prosodic properties between read and spontaneous speech material,
P. Howell and K. Kadi-Hanifi, “Comparison of prosodic properties between read and spontaneous speech material,”Speech communication, vol. 10, no. 2, pp. 163–169, 1991
1991
-
[6]
Does reading clearly produce the same acoustic- phonetic modifications as spontaneous speech in a clear speaking style?
V . Hazan and R. Baker, “Does reading clearly produce the same acoustic- phonetic modifications as spontaneous speech in a clear speaking style?” inProc. DiSS 2010, 2010, pp. 7–10
2010
-
[7]
Speech Rates in British English,
S. Tauroza and D. Allison, “Speech Rates in British English,” Applied Linguistics, vol. 11, no. 1, pp. 90–105, Mar
-
[8]
Available: https://academic.oup.com/applij/article- lookup/doi/10.1093/applin/11.1.90
[Online]. Available: https://academic.oup.com/applij/article- lookup/doi/10.1093/applin/11.1.90
-
[9]
Automatic User-Adaptive Speaking Rate Selection,
N. Ward and S. Nakagawa, “Automatic User-Adaptive Speaking Rate Selection,”International Journal of Speech Technology, vol. 7, no. 4, pp. 259–268, Oct. 2004. [Online]. Available: https://link.springer.com/10.1023/B:IJST.0000037070.31146.f9
-
[10]
User speech rates and preferences for system speech rates,
S. Dowding, C. Gutwin, and A. Cockburn, “User speech rates and preferences for system speech rates,”International Journal of Human- Computer Studies, vol. 184, p. 103222, Apr. 2024. [Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/S1071581924000065
2024
-
[11]
Speaking, fast or slow: how conversational agents’ rate of speech influences user experience,
Y . Xie, J. Qu, Y . Zhang, R. Zhou, and A. H. S. Chan, “Speaking, fast or slow: how conversational agents’ rate of speech influences user experience,”Universal Access in the Information Society, vol. 23, no. 4, pp. 1947–1956, Nov. 2024. [Online]. Available: https://link.springer.com/10.1007/s10209-023-01000-2
-
[12]
Dialog as interper- sonal synergy,
R. Fusaroli, J. Raczaszek-Leonardi, and K. Tylen, “Dialog as interper- sonal synergy,”New Ideas in Psychology, vol. 32, pp. 147–157, Jan. 2014
2014
-
[13]
Conversational Speech Behaviors Are Context Dependent,
C. J. Wynn, T. S. Barrett, and S. A. Borrie, “Conversational Speech Behaviors Are Context Dependent,”Journal of Speech, Language, and Hearing Research, vol. 67, no. 5, pp. 1360–1369, May 2024
2024
-
[14]
The role of intonation in emotional expressions,
T. Bänziger and K. R. Scherer, “The role of intonation in emotional expressions,”Speech Communication, vol. 46, no. 3, pp. 252–267, Jul. 2005
2005
-
[15]
Emotional speech processing: Disentangling the effects of prosody and semantic cues,
M. D. Pell, A. Jaywant, L. Monetta, and S. A. Kotz, “Emotional speech processing: Disentangling the effects of prosody and semantic cues,”Cognition & Emotion, vol. 25, no. 5, pp. 834–853, Aug. 2011. [Online]. Available: http://www.tandfonline.com/doi/abs/10.1080/02699931.2010.516915
-
[16]
Speech melody as articulatorily implemented communicative functions,
Y . Xu, “Speech melody as articulatorily implemented communicative functions,”Speech Communication, vol. 46, no. 3-4, pp. 220–251, Jul. 2005. [Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/S0167639305000889
2005
-
[17]
Acoustic correlates of linguistic stress and accent in Dutch and American English,
A. Sluijter and V . Van Heuven, “Acoustic correlates of linguistic stress and accent in Dutch and American English,” inProceeding of Fourth International Conference on Spoken Language Processing. ICSLP ’96, vol. 2. Philadelphia, PA, USA: IEEE, 1996, pp. 630–633. [Online]. Available: http://ieeexplore.ieee.org/document/607440/
1996
-
[18]
Spectral balance as an acoustic correlate of linguistic stress,
A. M. C. Sluijter and V . J. Van Heuven, “Spectral balance as an acoustic correlate of linguistic stress,”The Journal of the Acoustical Society of America, vol. 100, no. 4, pp. 2471–2485, Oct. 1996. [Online]. Available: https://pubs.aip.org/jasa/article/100/4/2471/580350/Spectral- balance-as-an-acoustic-correlate-of
1996
-
[19]
Speech analysis and mental processes,
F. Goldman-Eisler, “Speech analysis and mental processes,”Language and speech, vol. 1, no. 1, pp. 59–75, 1958
1958
-
[20]
Automatic estimation of speaking rate in multilingual spontaneous speech,
F. Pellegrino, J. Farinas, and J. L. Rouas, “Automatic estimation of speaking rate in multilingual spontaneous speech,” inSpeech Prosody
-
[21]
2004, pp
ISCA, Mar. 2004, pp. 517–520
2004
-
[22]
Across-Language Perspective on Speech Information Rate,
F. Pellegrino, C. Coupe, and E. Marsico, “Across-Language Perspective on Speech Information Rate,”Language, vol. 87, no. 3, pp. 539–558, Sep. 2011. [Online]. Available: https://muse.jhu.edu/article/449938
2011
-
[23]
Estimating speaking rate in spontaneous discourse,
Y . Jiao, V . Berisha, M. Tu, T. Huston, and J. Liss, “Estimating speaking rate in spontaneous discourse,” in2015 49th Asilomar Conference on Signals, Systems and Computers. Pacific Grove, CA, USA: IEEE, Nov. 2015, pp. 1189–1192. [Online]. Available: http://ieeexplore.ieee.org/document/7421328/
-
[24]
Combining multiple estimators of speaking rate,
N. Morgan and E. Fosler-Lussier, “Combining multiple estimators of speaking rate,” inProceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP ’98 (Cat. No.98CH36181), vol. 2. Seattle, W A, USA: IEEE, 1998, pp. 729–
1998
-
[25]
Available: http://ieeexplore.ieee.org/document/675368/
[Online]. Available: http://ieeexplore.ieee.org/document/675368/
-
[26]
Language Model and Speaking Rate Adaptation for Spontaneous Presentation Speech Recog- nition,
H. Nanjo and T. Kawahara, “Language Model and Speaking Rate Adaptation for Spontaneous Presentation Speech Recog- nition,”IEEE Transactions on Speech and Audio Processing, vol. 12, no. 4, pp. 391–400, Jul. 2004. [Online]. Available: http://ieeexplore.ieee.org/document/1306512/
-
[27]
Acoustic effects of variation in vocal effort by men, women, and children,
H. Traunmüller and A. Eriksson, “Acoustic effects of variation in vocal effort by men, women, and children,”The Journal of the Acoustical Society of America, vol. 107, no. 6, pp. 3438–3451, Jun. 2000. [Online]. Available: https://pubs.aip.org/jasa/article/107/6/3438/554986/Acoustic- effects-of-variation-in-vocal-effort-by
2000
-
[28]
Seamless interaction: Dyadic audiovisual motion modeling and large-scale dataset,
V . Agrawal, A. Akinyemi, K. Alvero, M. Behrooz, J. Buffalini, F. M. Carlucci, J. Chen, J. Chen, Z. Chen, S. Cheng, P. Chowdary, J. Chuang, A. D’Avirro, J. Daly, N. Dong, M. Duppenthaler, C. Gao, J. Girard, M. Gleize, S. Gomez, H. Gong, S. Govindarajan, B. Han, S. He, D. Hernandez, Y . Hristov, R. Huang, H. Inaguma, S. Jain, R. Janardhan, Q. Jia, C. Klaib...
2025
-
[29]
Introducing parselmouth: A python interface to praat,
Y . Jadoul, B. Thompson, and B. De Boer, “Introducing parselmouth: A python interface to praat,”Journal of Phonetics, vol. 71, pp. 1–15, 2018
2018
-
[30]
Standardization of pitch-range settings in voice acoustic analysis,
A. P. V ogel, P. Maruff, P. J. Snyder, and J. C. Mundt, “Standardization of pitch-range settings in voice acoustic analysis,”Behavior research methods, vol. 41, no. 2, pp. 318–324, 2009
2009
-
[31]
Toward standards in acoustic analysis of voice,
I. R. Titze, “Toward standards in acoustic analysis of voice,”Journal of Voice, vol. 8, no. 1, pp. 1–7, Mar. 1994. [Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/S0892199705803133
1994
-
[32]
Culturax: A cleaned, enormous, and multilingual dataset for large language models in 167 languages,
T. Nguyen, C. Van Nguyen, V . D. Lai, H. Man, N. T. Ngo, F. Dernon- court, R. A. Rossi, and T. H. Nguyen, “Culturax: A cleaned, enormous, and multilingual dataset for large language models in 167 languages,” inProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, ...
2024
-
[33]
Minimum sample length for the estimation of long-term speaking rate,
P. Arantes, A. Eriksson, and V . G. Lima, “Minimum sample length for the estimation of long-term speaking rate,” inProc. 9th International Conference on Speech Prosody, vol. 2018, 2018, pp. 661–665
2018
-
[34]
A large-scale multilingual study of silent pause duration,
E. Campione, J. Véroniset al., “A large-scale multilingual study of silent pause duration,” inSpeech prosody, vol. 2002, 2002, pp. 199–202
2002
-
[35]
Measuring speaking rate: how do objective measurements correlate with audio-perceptual ratings?
J. Iwarsson, J. Naes, and R. Hollen, “Measuring speaking rate: how do objective measurements correlate with audio-perceptual ratings?” Logopedics Phoniatrics Vocology, vol. 48, no. 2, pp. 57–66, 2023
2023
-
[36]
The determinants of the rate of speech output and their mutual relations
F. Goldman-Eisler, “The determinants of the rate of speech output and their mutual relations.”Journal of Psychosomatic Research, 1956
1956
-
[37]
T. Feng, J. Lee, A. Xu, Y . Lee, T. Lertpetchpun, X. Shi, H. Wang, T. Thebaud, L. Moro-Velazquez, D. Byrdet al., “V ox-profile: A speech foundation model benchmark for characterizing diverse speaker and speech traits,”arXiv preprint arXiv:2505.14648, 2025
-
[38]
Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,
S. Team, “Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,” https://github.com/snakers4/silero-vad, 2024
2024
-
[39]
The significance of changes in the rate of articula- tion,
F. Goldman-Eisler, “The significance of changes in the rate of articula- tion,”Language and Speech, vol. 4, no. 3, pp. 171–174, 1961
1961
-
[40]
Acoustic profiles in vocal emotion expression
R. Banse and K. R. Scherer, “Acoustic profiles in vocal emotion expression.”Journal of personality and social psychology, vol. 70, no. 3, p. 614, 1996
1996
-
[41]
Dominance statistics: Ordinal analyses to answer ordinal questions
N. Cliff, “Dominance statistics: Ordinal analyses to answer ordinal questions.”Psychological bulletin, vol. 114, no. 3, p. 494, 1993
1993
-
[42]
The proof and measurement of association between two things
C. Spearman, “The proof and measurement of association between two things.”American Journal of Psychology, 1961
1961
-
[43]
Use of ranks in one-criterion variance analysis,
W. H. Kruskal and W. A. Wallis, “Use of ranks in one-criterion variance analysis,”Journal of the American statistical Association, vol. 47, no. 260, pp. 583–621, 1952
1952
-
[44]
The need to report effect size estimates revisited. an overview of some recommended measures of effect size,
M. Tomczak and E. Tomczak, “The need to report effect size estimates revisited. an overview of some recommended measures of effect size,” Trends in Sport Sciences, 2014
2014
-
[45]
Acoustic-prosodic and articulatory characteristics of the mandarin speech conveying dominance or submissiveness,
P. Geng, W. Gu, K. Johnson, and D. Erickson, “Acoustic-prosodic and articulatory characteristics of the mandarin speech conveying dominance or submissiveness,” inProc. 10th International Conference on Speech Prosody, 2020, pp. 424–428
2020
-
[46]
Multiple prosodic meanings are conveyed through separate pitch ranges: Evidence from perception of focus and surprise in mandarin chinese,
X. Liu, Y . Xu, W. Zhang, and X. Tian, “Multiple prosodic meanings are conveyed through separate pitch ranges: Evidence from perception of focus and surprise in mandarin chinese,”Cognitive, Affective, & Behavioral Neuroscience, vol. 21, no. 6, pp. 1164–1175, 2021
2021
-
[47]
Authenticity of academic lecture passages in high-stakes tests: A temporal fluency perspective,
H. Nishizawa, “Authenticity of academic lecture passages in high-stakes tests: A temporal fluency perspective,”Language Testing, vol. 41, no. 4, pp. 792–816, 2024
2024
-
[48]
Individual traits of speaking style and speech rhythm in a spoken discourse,
N. Campbell, “Individual traits of speaking style and speech rhythm in a spoken discourse,” inVerbal and Nonverbal Features of Human-Human and Human-Machine Interaction: COST Action 2102 International Con- ference, Patras, Greece, October 29-31, 2007. Revised Papers. Springer, 2008, pp. 107–120
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.