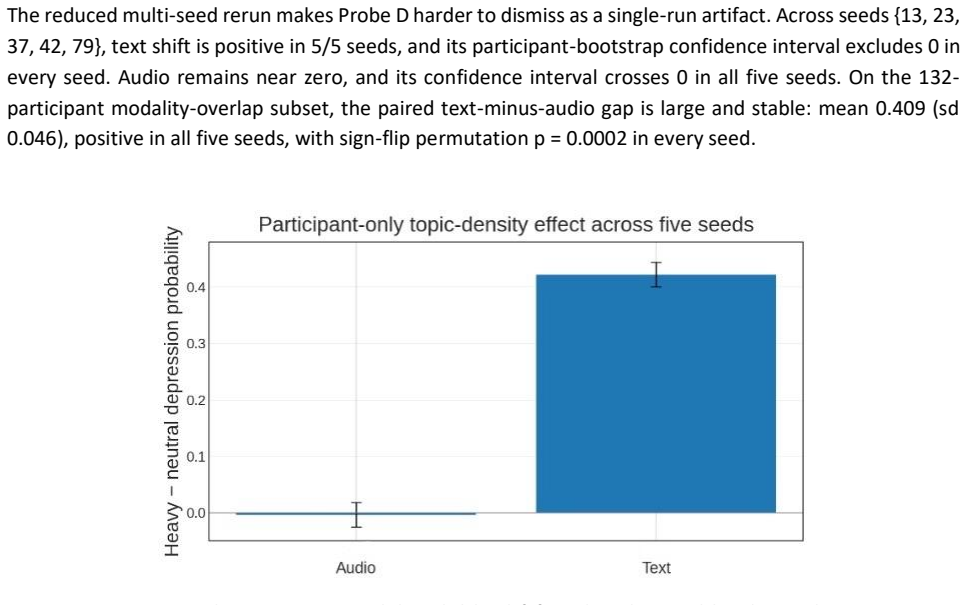
A Multi-Probe Audit of Clinical-Interview Depression Detection Benchmarks
Pith reviewed 2026-06-30 21:17 UTC · model grok-4.3
The pith
Cross-validation and official test rankings disagree on top models for depression detection from interviews
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under subject-disjoint leave-one-subject-out cross-validation on E-DAIC, a hybrid model reaches macro-F1 of 0.723. Sweeping 96 configurations shows development CV and official test rankings align moderately, with the best CV model ranking 20th on test, the test winner 41st on CV, zero top-3 overlap, and the winner ranking first in only 32.3% of subject bootstraps. Strong in-domain baselines on CMDC and ANDROIDS transfer poorly zero-shot. On symptom-dense slices, text scores rise while audio scores stay flat.
What carries the argument
The four-probe audit consisting of strict subject-disjoint cross-validation, model configuration sweeps for ranking stability, external corpus validation, and symptom-density partitioned stress testing.
If this is right
- Strict CV provides a conservative reference without relying on privileged holdout.
- Official test rankings are unreliable due to low alignment with CV.
- Zero-shot transfer to other datasets is weak despite high in-domain performance.
- Text models show greater improvement on symptom-dense slices compared to audio.
Where Pith is reading between the lines
- If rankings are this unstable, reported state-of-the-art results may reflect split-specific artifacts more than true capability.
- Audio features might provide more consistent signals across varying levels of expressed symptoms.
- Future benchmarks could benefit from ensemble evaluation or multiple holdouts to assess ranking robustness.
- The differential behavior of text and audio suggests hybrid systems or modality-specific evaluation strategies.
Load-bearing premise
The SRDS-based annotator correctly identifies symptom-dense versus symptom-light interview slices without systematic bias affecting text versus audio model comparisons.
What would settle it
Re-annotating the interview slices with a different method or human experts and re-running the stress-test to check if the text-audio gap persists.
Figures
read the original abstract
This paper audits benchmark evaluation in clinical-interview depression detection through four complementary probes across DAIC/E-DAIC, CMDC, ANDROIDS, MODMA, and PDCH. First, we re-evaluate E-DAIC under strict subject-disjoint leave-one-subject-out cross-validation. A lightweight hybrid text-plus-LLM-score model reaches macro-F1 = 0.723 - the highest reported under this protocol, to our knowledge - providing a conservative out-of-fold reference point that does not depend on the privileged official holdout. Second, we test whether the E-DAIC official split supports fine-grained leaderboard rankings by sweeping 96 model configurations across modality bundles, pooling strategies, and learners. Development-side cross-validation and official-test rankings align only moderately: the best cross-validation configuration ranks twentieth on the official test, the official-test winner ranks forty-first by cross-validation, top-3 overlap is zero, and the apparent winner is rank-1 in only 32.3% of subject bootstraps. Third, we externally validate strong public CMDC and ANDROIDS baselines that achieve near-ceiling in-domain performance. Zero-shot transfer to external corpora is substantially weaker. Finally, we stress-test E-DAIC text and audio models using paired symptom-dense versus symptom-light interview slices defined by an SRDS-based annotator. Text scores rise sharply on symptom-dense slices, whereas audio scores remain nearly flat; the text-minus-audio gap is positive across all five seeds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper audits clinical-interview depression detection benchmarks across DAIC/E-DAIC, CMDC, ANDROIDS, MODMA, and PDCH via four probes: re-evaluation of E-DAIC under subject-disjoint LOSO CV yielding macro-F1=0.723; a sweep of 96 model configurations showing moderate misalignment between dev CV and official test rankings (best CV config ranks 20th on test, official-test winner ranks 41st on CV, zero top-3 overlap, 32.3% bootstrap rank-1 stability); external validation with strong in-domain but weak zero-shot transfer performance; and a stress-test on symptom-dense vs. symptom-light slices (defined by SRDS annotator) where text models improve but audio models remain flat.
Significance. If the reported misalignment between CV and test rankings is shown to exceed sampling variability, the work would indicate that official E-DAIC splits may not reliably support fine-grained leaderboard comparisons, with implications for benchmark design in clinical NLP. The multi-dataset external validation and bootstrap stability analysis are constructive elements that strengthen the audit's empirical grounding.
major comments (1)
- [96-configuration sweep (second probe)] In the section describing the sweep of 96 model configurations: the central claim that dev CV and official-test rankings align only moderately (best CV at rank 20 on test, test winner at rank 41 on CV, zero top-3 overlap) is presented without per-configuration macro-F1 values, standard errors, or a null distribution of rank instability under random subject-disjoint splits of comparable size; this leaves open whether the observed shifts exceed what finite test-set variance would produce, as noted by the limited number of test subjects.
minor comments (2)
- [Abstract and methods] The abstract and methods description provide specific performance numbers but omit details on exact model implementations, hyperparameter choices, data exclusion criteria, and the statistical tests used for the bootstrap analysis.
- [Stress-test section (fourth probe)] The stress-test section would benefit from explicit description of how the SRDS-based annotator was applied to define symptom-dense versus symptom-light slices, including any inter-annotator agreement metrics if available.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the 96-configuration sweep. The concern about whether observed rank shifts exceed finite-sample variance is well-taken, and we address it directly below.
read point-by-point responses
-
Referee: In the section describing the sweep of 96 model configurations: the central claim that dev CV and official-test rankings align only moderately (best CV at rank 20 on test, test winner at rank 41 on CV, zero top-3 overlap) is presented without per-configuration macro-F1 values, standard errors, or a null distribution of rank instability under random subject-disjoint splits of comparable size; this leaves open whether the observed shifts exceed what finite test-set variance would produce, as noted by the limited number of test subjects.
Authors: The manuscript already reports a subject-bootstrap analysis showing the apparent winner is rank-1 in only 32.3% of resamples, which directly quantifies rank instability. However, we agree that a formal null distribution under random subject-disjoint splits of the test set would strengthen the claim that the misalignment exceeds sampling variability. In revision we will add (i) the full table of 96 per-configuration macro-F1 scores with standard errors (in an appendix) and (ii) a comparison of observed rank shifts against the distribution obtained from 1000 random subject-disjoint partitions of the test subjects. This will allow readers to evaluate whether the reported misalignment is statistically distinguishable from test-set variance alone. revision: yes
Circularity Check
No significant circularity; empirical audit on public data with standard protocols
full rationale
The paper conducts an empirical audit using subject-disjoint cross-validation, model sweeps, external transfer tests, and symptom-slice stress tests on public datasets (DAIC/E-DAIC, CMDC, etc.). All reported quantities—macro-F1 scores, rank alignments, bootstrap stabilities, and modality gaps—are direct measurements from these protocols. No equations, fitted parameters, or self-citations are invoked to derive the central observations by construction; the misalignment findings and transfer results stand as independent empirical outcomes without reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Subject-disjoint leave-one-subject-out cross-validation is the appropriate protocol for obtaining conservative out-of-fold performance estimates on E-DAIC.
- domain assumption The SRDS-based annotator provides an unbiased partition of interview slices into symptom-dense and symptom-light categories.
Reference graph
Works this paper leans on
-
[1]
Depressive disorder (depression),
World Health Organization, "Depressive disorder (depression)," WHO Fact Sheet, Aug. 29, 2025. [Online]. Available: https://www.who.int/news-room/fact-sheets/detail/depression. Accessed: May 4, 2026
2025
-
[2]
J. Rong, X. Wang, P. Cheng, D. Li, and D. Zhao, “Global, regional and national burden of depressive disorders and attributable risk factors, from 1990 to 2021: results from the 2021 Global Burden of Disease study,” The British Journal of Psychiatry, vol. 227, no. 4, pp. 688–697, 2025, doi: 10.1192/bjp.2024.266
-
[3]
Digital health tools for the passive monitoring of depression: a systematic review of methods,
V. De Angel et al., “Digital health tools for the passive monitoring of depression: a systematic review of methods,” npj Digital Medicine, vol. 5, art. 3, 2022, doi: 10.1038/s41746-021-00548-8
-
[4]
H. Lee, S.-G. Kang, and S. Lee, “The role of digital biomarkers in physiological signal-based depression assessment: systematic review and meta-analysis,” Journal of Medical Internet Research, vol. 28, e76432, 2026, doi: 10.2196/76432
-
[5]
The Distress Analysis Interview Corpus of human and computer interviews,
J. Gratch et al., "The Distress Analysis Interview Corpus of human and computer interviews," in Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC 2014), pp. 3123-3128, 2014
2014
-
[6]
F. Ringeval et al., "AVEC 2019 Workshop and Challenge: State-of-Mind, Detecting Depression with AI, and Cross-Cultural Affect Recognition," in Proceedings of the 9th International on Audio/Visual Emotion Challenge and Workshop (AVEC '19), 2019, doi: 10.1145/3347320.3357688
-
[7]
Z. Jiang, S. Seyedi, E. Griner, A. Abbasi, A. B. Rad, H. Kwon, R. O. Cotes, and G. D. Clifford, "Multimodal Mental Health Digital Biomarker Analysis From Remote Interviews Using Facial, Vocal, Linguistic, and Cardiovascular Patterns," IEEE Journal of Biomedical and Health Informatics, vol. 28, no. 3, pp. 1680- 1691, Mar. 2024, doi: 10.1109/JBHI.2024.3352075
-
[8]
Language-based detection of depression with machine learning: systematic review and meta-analysis,
H. Fisher et al., "Language-based detection of depression with machine learning: systematic review and meta-analysis," npj Digital Medicine, vol. 9, art. 273, 2026, doi: 10.1038/s41746-026-02448-1
-
[9]
L. Liu et al., "Diagnostic accuracy of deep learning using speech samples in depression: a systematic review and meta-analysis," Journal of the American Medical Informatics Association, vol. 31, no. 10, pp. 2394-2404, 2024, doi: 10.1093/jamia/ocae189
-
[10]
On over-fitting in model selection and subsequent selection bias in performance evaluation,
G. C. Cawley and N. L. C. Talbot, "On over-fitting in model selection and subsequent selection bias in performance evaluation," Journal of Machine Learning Research, vol. 11, pp. 2079-2107, 2010
2079
-
[11]
Selection bias in gene extraction on the basis of microarray gene- expression data,
C. Ambroise and G. J. McLachlan, "Selection bias in gene extraction on the basis of microarray gene- expression data," Proceedings of the National Academy of Sciences, vol. 99, no. 10, pp. 6562-6566, 2002
2002
-
[12]
Bias in error estimation when using cross-validation for model selection,
V. S. Varma and R. Simon, "Bias in error estimation when using cross-validation for model selection," BMC Bioinformatics, vol. 7, art. 91, 2006
2006
-
[13]
No unbiased estimator of the variance of k-fold cross-validation,
Y. Bengio and Y. Grandvalet, "No unbiased estimator of the variance of k-fold cross-validation," Journal of Machine Learning Research, vol. 5, pp. 1089-1105, 2004
2004
-
[14]
Cross-validation pitfalls when selecting and assessing regression and classification models,
D. Krstajic et al., "Cross-validation pitfalls when selecting and assessing regression and classification models," Journal of Cheminformatics, vol. 6, art. 10, 2014
2014
-
[15]
Cross-validation failure: Small sample sizes lead to large error bars,
G. Varoquaux, "Cross-validation failure: Small sample sizes lead to large error bars," NeuroImage, vol. 180, pp. 68-77, 2018
2018
-
[16]
I. Danylenko and O. Unold, "Common Pitfalls and Recommendations for Use of Machine Learning in Depression Severity Estimation: DAIC-WOZ Study," Applied Sciences, vol. 16, no. 1, art. 422, 2026, doi: 10.3390/app16010422
-
[17]
Assessing speaker independence on a speech-based depression level estimation system,
P. López-Otero, L. Docío-Fernández, and C. García-Mateo, "Assessing speaker independence on a speech-based depression level estimation system," Pattern Recognition Letters, vol. 68, pp. 343-350, 2015, doi: 10.1016/j.patrec.2015.05.017
-
[18]
The need to approximate the use-case in clinical machine learning,
S. Saeb, L. Lonini, A. Jayaraman, D. C. Mohr, and K. P. Kording, "The need to approximate the use-case in clinical machine learning," GigaScience, vol. 6, no. 5, pp. 1-9, 2017, doi: 10.1093/gigascience/gix019
-
[19]
H.-C. Yeh, L. Sun, A. Mahapatra, S. S. Chandra, E. Mower Provost, and B. Sisman, "Who is Speaking or Who is Depressed? A Controlled Study of Speaker Leakage in Speech-Based Depression Detection," arXiv preprint arXiv:2604.14354, 2026, doi: 10.48550/arXiv.2604.14354
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.14354 2026
-
[20]
B. Zou et al., "Semi-Structural Interview-Based Chinese Multimodal Depression Corpus Towards Automatic Preliminary Screening of Depressive Disorders," IEEE Transactions on Affective Computing, vol. 14, no. 4, pp. 2823-2838, 2023, doi: 10.1109/TAFFC.2022.3181210
-
[21]
The Androids Corpus: A New Publicly Available Benchmark for Speech Based Depression Detection,
F. Tao, A. Esposito, and A. Vinciarelli, "The Androids Corpus: A New Publicly Available Benchmark for Speech Based Depression Detection," in Proceedings of Interspeech 2023, pp. 4149-4153, 2023, doi: 10.21437/Interspeech.2023-894
-
[22]
S. Xia, "Subject-level depression detection from Chinese clinical interview texts requires dataset- specific aggregation," Research Square preprint, 2026, doi: 10.21203/rs.3.rs-9258754/v1
-
[23]
K. Daly and O. Olukoya, "Depression detection in read and spontaneous speech: a multimodal approach for lesser-resourced languages," Biomedical Signal Processing and Control, vol. 108, art. 107959, 2025, doi: 10.1016/j.bspc.2025.107959
-
[24]
Speech-Based Depression Assessment: A Comprehensive Survey,
S. S. Leal, S. Ntalampiras, and R. Sassi, "Speech-Based Depression Assessment: A Comprehensive Survey," IEEE Transactions on Affective Computing, vol. 16, no. 3, pp. 1318-1333, Jul.-Sep. 2025, doi: 10.1109/TAFFC.2024.3521327
-
[25]
A systematic review on automated clinical depression diagnosis,
K. Mao, Y. Wu, and J. Chen, "A systematic review on automated clinical depression diagnosis," npj Mental Health Research, vol. 2, art. 20, 2023, doi: 10.1038/s44184-023-00040-z
-
[26]
L. Gomez-Zaragoza, J. Marin-Morales, M. Alcaniz, and M. Soleymani, "Speech and Text Foundation Models for Depression Detection: Cross-Task and Cross-Language Evaluation," in Proceedings of Interspeech 2025, pp. 5253-5257, 2025, doi: 10.21437/Interspeech.2025-1035
-
[27]
Detecting depression using vocal, facial and semantic communication cues,
J. R. Williamson, E. Godoy, M. Cha, A. Schwarzentruber, P. Khorrami, Y. Gwon, H.-T. Kung, C. Dagli, and T. F. Quatieri, “Detecting depression using vocal, facial and semantic communication cues,” in Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge (AVEC ’16), 2016, pp. 11–18, doi: 10.1145/2988257.2988263
-
[28]
Detecting depression with word-level multimodal fusion,
M. Rohanian, J. Hough, and M. Purver, “Detecting depression with word-level multimodal fusion,” in Proceedings of Interspeech 2019, 2019, pp. 1443–1447, doi: 10.21437/Interspeech.2019-2283
-
[29]
Multi-level attention network using text, audio and video for depression prediction,
A. Ray, S. Kumar, R. Reddy, P. Mukherjee, and R. Garg, “Multi-level attention network using text, audio and video for depression prediction,” in Proceedings of the 9th International on Audio/Visual Emotion Challenge and Workshop (AVEC ’19), 2019, pp. 81–88, doi: 10.1145/3347320.3357697
-
[30]
Multi-level attention network using text, audio and video for depression prediction,
M. R. Makiuchi, T. Warnita, K. Uto, and K. Shinoda, “Multimodal fusion of BERT-CNN and gated CNN representations for depression detection,” in Proceedings of the 9th International on Audio/Visual Emotion Challenge and Workshop (AVEC ’19), 2019, pp. 55–63, doi: 10.1145/3347320.3357694
-
[31]
M. Sadeghi, R. Richer, B. Egger, L. Schindler-Gmelch, L. H. Rupp, F. Rahimi, M. Berking, and B. M. Eskofier, “Harnessing multimodal approaches for depression detection using large language models and facial expressions,” npj Mental Health Research, vol. 3, art. 66, 2024, doi: 10.1038/s44184-024- 00112-8
-
[32]
When Consistency Becomes Bias: Interviewer Effects in Semi-Structured Clinical Interviews,
H. Watawana et al., "When Consistency Becomes Bias: Interviewer Effects in Semi-Structured Clinical Interviews," arXiv preprint arXiv:2603.24651, 2026
-
[33]
S. Burdisso et al., "DAIC-WOZ: On the Validity of Using the Therapist's prompts in Automatic Depression Detection from Clinical Interviews," in Proceedings of the 6th Clinical Natural Language Processing Workshop, Mexico City, Mexico, Jun. 2024, pp. 82-90, doi: 10.18653/v1/2024.clinicalnlp- 1.8
-
[34]
T. Ishikawa, "T+L and L-only code for Beyond Headline Scores: A Multi-Probe Audit of Clinical- Interview Depression Detection Benchmarks," Zenodo, Version v2, Apr. 27, 2026, doi: 10.5281/zenodo.19813142. Concept DOI: 10.5281/zenodo.19813141
-
[35]
MODMA dataset: a Multi-modal Open Dataset for Mental-disorder Analysis,
H. Cai, Y. Gao, S. Sun, N. Li, F. Tian, H. Xiao, J. Li, Z. Yang, X. Li, Q. Zhao, Z. Liu, Z. Yao, M. Yang, H. Peng, J. Zhu, X. Zhang, X. Hu, and B. Hu, "MODMA dataset: a Multi-modal Open Dataset for Mental-disorder Analysis," arXiv preprint arXiv:2002.09283, 2020
-
[36]
A multi-modal open dataset for mental-disorder analysis,
H. Cai, Z. Yuan, Y. Gao, et al., "A multi-modal open dataset for mental-disorder analysis," Scientific Data, vol. 9, art. 178, 2022, doi: 10.1038/s41597-022-01211-x
-
[37]
A Multimodal Depression Consultation Dataset of Speech and Text with HAMD-17 Assessments,
P. Cao et al., "A Multimodal Depression Consultation Dataset of Speech and Text with HAMD-17 Assessments," Scientific Data, vol. 12, art. 1577, 2025, doi: 10.1038/s41597-025-05817-9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.