Manga109-v2026: Revisiting Manga109 Annotations for Modern Manga Understanding
Pith reviewed 2026-05-21 04:33 UTC · model grok-4.3
The pith
Revising Manga109 annotations fixes errors to align with modern OCR and multimodal systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
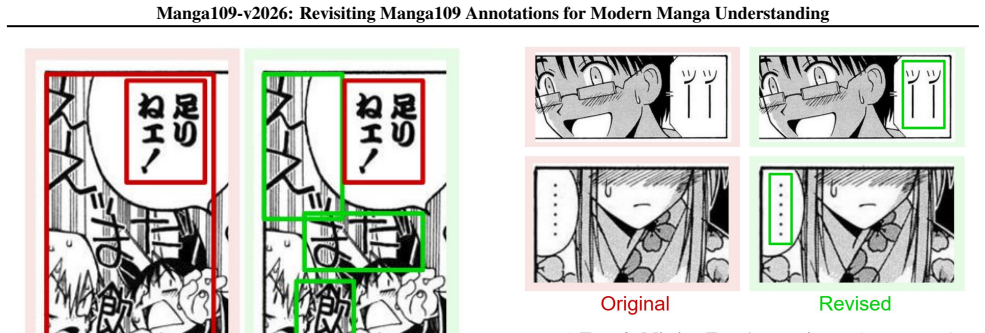
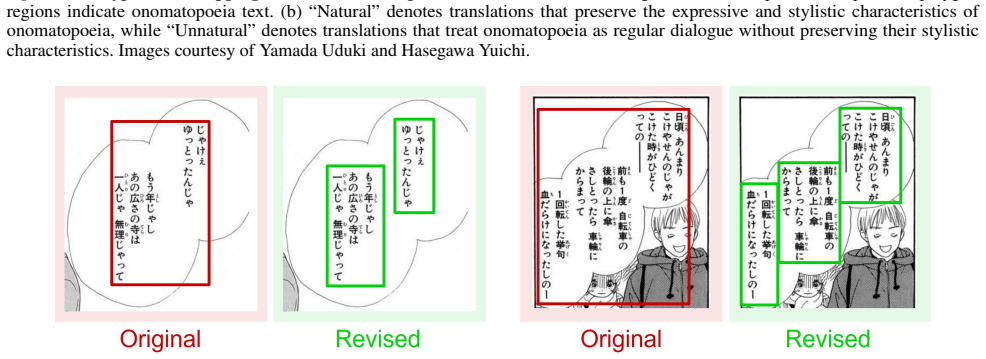
The authors claim that by detecting and correcting transcription errors, missing text regions, overlapping dialogue with onomatopoeia, and under-segmented speech balloons in approximately 29,000 annotations, the new Manga109-v2026 version better supports modern OCR and multimodal manga understanding systems while preserving the expressive structures typical of manga.
What carries the argument
OCR-based issue detection combined with manual revision of dialogue annotations
If this is right
- Modern OCR systems can achieve higher precision on manga text when using the revised annotations.
- Multimodal models will more accurately interpret the interplay between text and visuals in manga panels.
- Evaluation of manga translation and understanding algorithms becomes more reliable with fewer annotation flaws.
- The dataset continues to reflect the characteristic visual and textual expressions found in manga.
Where Pith is reading between the lines
- Similar revision processes could be applied to other datasets in the field of comic book analysis.
- This update may enable new applications in automated manga localization and cultural adaptation tools.
- Researchers might explore how these annotation improvements affect the training of large language models on visual narratives.
Load-bearing premise
The process of using OCR to find problems and then manually fixing them catches every issue in the five categories without adding new mistakes or biases to the dataset.
What would settle it
Comparing the performance of an OCR model trained on the original Manga109 versus the revised version on a test set of manga images; lack of improvement would challenge the value of the revisions.
Figures



read the original abstract
Manga is a culturally distinctive multimodal medium and one of the most influential forms of Japanese popular culture. As AI systems increasingly target manga understanding, OCR, and translation, Manga109 has become a foundational dataset for manga-related AI research. However, the current Manga109 dataset contains transcription errors and coarse annotations, which do not align well with modern OCR and multimodal manga understanding tasks. In this work, we revisit the dialogue text annotations of Manga109 and identify five categories of annotation issues, including transcription errors, missing text regions, overlapping dialogue and onomatopoeia, and under-segmented speech balloons. To address these issues, we combine OCR-based issue detection and manual revision to construct Manga109-v2026, revising approximately 29,000 dialogue annotations. Our revisions better align Manga109 with modern OCR and multimodal manga understanding systems while preserving expressive structures characteristic of manga.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the creation of Manga109-v2026 by revising approximately 29,000 dialogue annotations in the original Manga109 dataset. It identifies five categories of annotation issues (transcription errors, missing text regions, overlapping dialogue and onomatopoeia, under-segmented speech balloons, etc.) and uses OCR-based detection followed by manual revision to address them, with the goal of better aligning the dataset with modern OCR and multimodal manga understanding systems while preserving manga's expressive features.
Significance. If the revisions demonstrably improve alignment without introducing new biases, the updated dataset would be a useful resource for manga OCR and multimodal research, building on Manga109's established role as a benchmark. The hybrid OCR-plus-manual curation method is a reasonable practical approach for large-scale fixes.
major comments (3)
- [Abstract] Abstract: the central claim that revisions 'better align Manga109 with modern OCR and multimodal manga understanding systems' is unsupported, as no before/after metrics, OCR accuracy deltas, detection F1 scores, or end-to-end task results are reported to show measurable improvement.
- [Methods] The manuscript provides no quantitative validation or error analysis of the five annotation-issue categories after revision (e.g., residual transcription error rates or introduced biases in onomatopoeia handling), which is required to substantiate the alignment claim.
- [Results] No results section, table, or figure presents downstream evaluation on any OCR model or multimodal manga understanding task, leaving open the possibility that changes are neutral or detrimental.
minor comments (1)
- [Methods] Clarify the exact criteria used for manual revision decisions to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting areas where the manuscript's claims and scope could be clarified. The work centers on documenting the annotation revision process and releasing Manga109-v2026 as a resource; we address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that revisions 'better align Manga109 with modern OCR and multimodal manga understanding systems' is unsupported, as no before/after metrics, OCR accuracy deltas, detection F1 scores, or end-to-end task results are reported to show measurable improvement.
Authors: We agree that the abstract phrasing overstates the contribution by implying demonstrated improvement. The revisions target concrete, previously documented annotation problems (transcription errors, missing regions, under-segmented balloons, and overlaps) that are known to degrade modern OCR pipelines. In the revised manuscript we will rephrase the abstract to state that the updates correct these specific issues, thereby making the dataset more compatible with current OCR and multimodal systems, without asserting quantitative gains. revision: yes
-
Referee: [Methods] The manuscript provides no quantitative validation or error analysis of the five annotation-issue categories after revision (e.g., residual transcription error rates or introduced biases in onomatopoeia handling), which is required to substantiate the alignment claim.
Authors: The methods section outlines the OCR-assisted detection followed by manual correction for each of the five issue categories. We accept that post-revision statistics would improve transparency. We will add a table and accompanying text reporting the number of annotations revised per category, the criteria used for manual verification, and any steps taken to avoid introducing new biases (for example, preserving original onomatopoeia styling where possible). revision: yes
-
Referee: [Results] No results section, table, or figure presents downstream evaluation on any OCR model or multimodal manga understanding task, leaving open the possibility that changes are neutral or detrimental.
Authors: The manuscript is structured as a dataset curation paper whose primary contribution is the identification of annotation issues and the release of the corrected annotations. We did not conduct downstream experiments because that would require choosing particular models and tasks outside the stated scope. In revision we will insert a short discussion section that explains, on qualitative grounds, why the targeted fixes (accurate transcription, proper balloon segmentation, separation of dialogue and onomatopoeia) are expected to benefit modern systems, while explicitly noting that empirical benchmarking remains future work. revision: partial
Circularity Check
No circularity: empirical dataset curation without derivations or fitted claims
full rationale
The paper describes an empirical process of identifying five categories of annotation problems in Manga109 (transcription errors, missing regions, overlaps, under-segmented balloons) via OCR-assisted detection and manual revision of ~29k annotations to produce Manga109-v2026. No mathematical derivations, equations, parameter fittings, predictions, or self-citation chains are present that could reduce any claim to its own inputs by construction. The central claim concerns improved alignment with modern OCR/multimodal systems, but this is presented as the outcome of the curation process itself rather than a derived or predicted quantity. The work is self-contained as data revision without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Text detection in manga by combining connected-component-based and region-based classifications , author=. ICIP , year=
-
[3]
Yusuke Matsui and Kota Ito and Yuji Aramaki and Azuma Fujimoto and Toru Ogawa and Toshihiko Yamasaki and Kiyoharu Aizawa , title=. MTAP , year=
-
[4]
Kiyoharu Aizawa and Azuma Fujimoto and Atsushi Otsubo and Toru Ogawa and Yusuke Matsui and Koki Tsubota and Hikaru Ikuta , title=. IEEE MultiMedia , year=
- [5]
-
[6]
COO: Comic Onomatopoeia Dataset for Recognizing Arbitrary or Truncated Texts , author=. ECCV , year=
-
[7]
Manga109Dialog: A Large-scale Dialogue Dataset for Comics Speaker Detection , author=. ICME , year=
-
[8]
MangaUB: A Manga Understanding Benchmark for Large Multimodal Models , year=
Ikuta, Hikaru and Wohler, Leslie and Aizawa, Kiyoharu , journal=. MangaUB: A Manga Understanding Benchmark for Large Multimodal Models , year=
-
[9]
CoMix: A Comprehensive Benchmark for Multi-Task Comic Understanding , author=. NeurIPS , year=
- [10]
-
[11]
Ragav Sachdeva and Gyungin Shin and Andrew Zisserman , title=. ACCV , year =
-
[12]
From Panels to Prose: Generating Literary Narratives from Comics , author=. ICCV , year=
-
[13]
Advancing Manga Analysis: Comprehensive Segmentation Annotations for the Manga109 Dataset , author=. CVPR , year=
-
[14]
Baek, Jeonghun and Egashira, Kazuki and Onohara, Shota and Miyai, Atsuyuki and Imajuku, Yuki and Ikuta, Hikaru and Aizawa, Kiyoharu , title =. EACL Findings , year =
-
[15]
Gemini 3 Flash: Frontier intelligence built for speed , author =. 2025 , howpublished =
work page 2025
-
[16]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
arXiv preprint arXiv:2409.09502 , year=
One missing piece in vision and language: A survey on comics understanding , author=. arXiv preprint arXiv:2409.09502 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.