Real-Time Execution with Autoregressive Policies
Pith reviewed 2026-06-27 06:38 UTC · model grok-4.3
The pith
Autoregressive policies achieve real-time execution by shortening tokenization horizons and applying constrained decoding to enforce latency bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
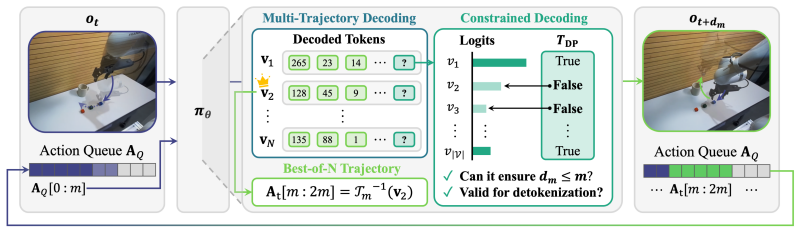
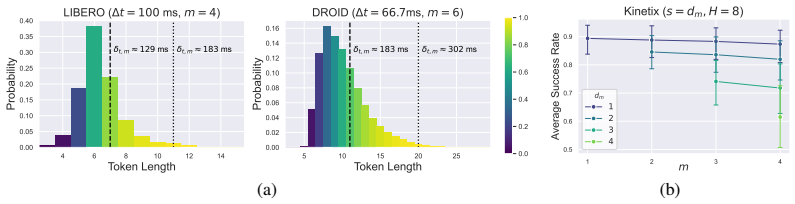
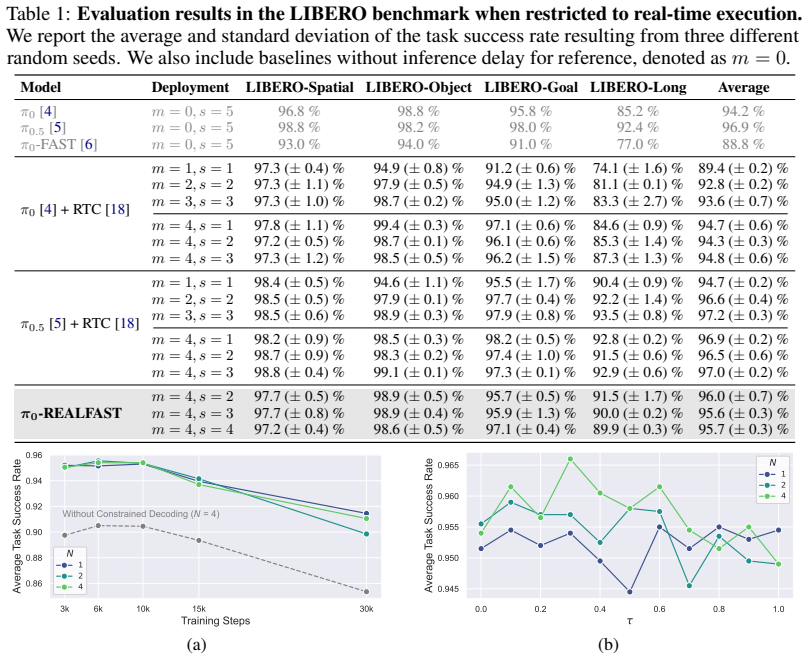
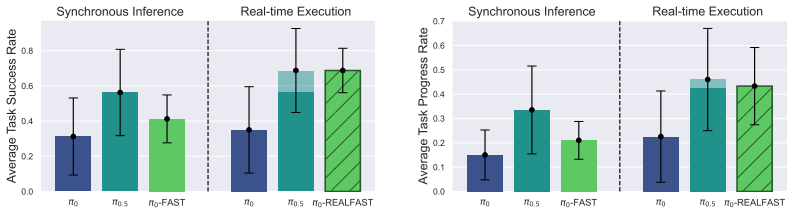
We demonstrate that autoregressive policies can achieve real-time execution by adjusting the tokenization horizon and applying constrained decoding, thereby guaranteeing strict latency bounds that enable multi-trajectory decoding to maximize performance. Across simulated and real-world environments, the autoregressive policy consistently outperforms its equivalent-level flow-matching policy counterpart while achieving significantly improved task completion speeds from synchronous inference. Coupled with the inherent advantages of autoregressive policies, such as faster convergence and better generalizability in instruction-following, these results confirm that autoregressive policies can rem
What carries the argument
Tokenization horizon adjustment combined with constrained decoding, which together enforce strict latency bounds and thereby permit multi-trajectory decoding.
If this is right
- The autoregressive policy outperforms equivalent-level flow-matching policies across simulated and real-world tasks.
- Task completion speeds increase significantly relative to synchronous inference.
- Strict latency bounds become available, enabling multi-trajectory decoding to improve action selection.
- Real-time execution remains compatible with the faster convergence and stronger instruction-following properties of autoregressive policies.
Where Pith is reading between the lines
- The same horizon and decoding adjustments could be tested on autoregressive policies for non-robotics sequence tasks that also require bounded response times.
- Larger autoregressive models might now be deployed in latency-sensitive settings without additional hardware changes.
- Hybrid training that mixes autoregressive and flow-matching objectives could be explored to combine their respective strengths under real-time constraints.
Load-bearing premise
Shortening the tokenization horizon and applying constrained decoding preserves policy performance and instruction-following ability without introducing new failure modes.
What would settle it
A direct comparison in which the horizon-adjusted autoregressive policy shows lower task success rates than the flow-matching policy when both are run under identical real-time latency constraints.
Figures

read the original abstract
Real-time execution, enabled by asynchronous inference that ensures both smooth action trajectories and fast reactivity, is critical for realistic deployments of large-scale Vision-Language-Action models. However, recent work on real-time execution primarily focuses on variants of diffusion policies, even though it is more critical for autoregressive policies given their slower rollout speed in synchronous inference. In contrast, we demonstrate that autoregressive policies can achieve real-time execution by adjusting the tokenization horizon and applying constrained decoding, thereby guaranteeing strict latency bounds that enable multi-trajectory decoding to maximize performance. Across simulated and real-world environments, we find that the autoregressive policy consistently outperforms its equivalent-level flow-matching policy counterpart while achieving significantly improved task completion speeds from synchronous inference. Coupled with the inherent advantages of autoregressive policies, such as faster convergence and better generalizability in instruction-following, these results confirm that autoregressive policies can remain a competitive policy type supporting real-time execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that autoregressive policies for Vision-Language-Action models can achieve real-time execution by adjusting the tokenization horizon and applying constrained decoding to guarantee strict latency bounds. This enables multi-trajectory decoding and yields consistent outperformance over equivalent-level flow-matching policies across simulated and real-world environments, along with significantly improved task completion speeds relative to synchronous inference. The work emphasizes the inherent advantages of autoregressive policies such as faster convergence and better instruction-following generalizability.
Significance. If the empirical claims are substantiated with quantitative evidence, the result would be significant for establishing autoregressive policies as viable for real-time robotic control, leveraging their training and generalization strengths over diffusion-based alternatives.
major comments (2)
- [Abstract] Abstract: the claims that the autoregressive policy 'consistently outperforms' its flow-matching counterpart and achieves 'significantly improved task completion speeds' are presented without any quantitative metrics, success rates, latency measurements, statistical tests, or baseline details, preventing assessment of whether the data support the central claim.
- [Methods/Results] The central claim requires that horizon adjustment plus constrained decoding simultaneously enforce latency bounds while leaving the policy distribution and instruction-following behavior essentially unchanged; however, no before/after comparison, ablation, or failure-mode analysis is supplied to substantiate that the modifications do not degrade performance or introduce new issues.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the specific simulated and real-world environments and the precise flow-matching baseline used for comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of our empirical results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims that the autoregressive policy 'consistently outperforms' its flow-matching counterpart and achieves 'significantly improved task completion speeds' are presented without any quantitative metrics, success rates, latency measurements, statistical tests, or baseline details, preventing assessment of whether the data support the central claim.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised manuscript we will incorporate key metrics (success rates, latency bounds, task completion times, and statistical comparisons) drawn from the experimental sections to substantiate the performance claims. revision: yes
-
Referee: [Methods/Results] The central claim requires that horizon adjustment plus constrained decoding simultaneously enforce latency bounds while leaving the policy distribution and instruction-following behavior essentially unchanged; however, no before/after comparison, ablation, or failure-mode analysis is supplied to substantiate that the modifications do not degrade performance or introduce new issues.
Authors: We acknowledge that explicit verification of distributional invariance is needed. The revised version will add before/after comparisons of policy outputs, ablations isolating the effect of horizon adjustment and constrained decoding on success rates and instruction adherence, and a brief failure-mode analysis to confirm that the latency guarantees are achieved without altering core behavior. revision: yes
Circularity Check
No significant circularity; empirical claims only
full rationale
The paper presents no equations, derivations, fitted parameters, or mathematical claims that could reduce to their own inputs. All load-bearing assertions rest on empirical comparisons across simulated and real-world environments, with the central modifications (tokenization horizon adjustment and constrained decoding) described as engineering choices whose effects are measured directly rather than derived from prior self-referential steps. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the results. This is a standard non-circular empirical robotics paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fu- sai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025
2025
-
[6]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Bjorck, F
NVIDIA, J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu,...
2025
-
[9]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
C. Cheang, S. Chen, Z. Cui, Y . Hu, L. Huang, T. Kong, H. Li, Y . Li, Y . Liu, X. Ma, et al. Gr-3 technical report.arXiv preprint arXiv:2507.15493, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [11]
-
[12]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, M.-Y . Liu, D. Xiang, G. Wetzstein, and T.-Y . Lin. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[13]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.016. 9
-
[15]
Y . Liu, J. Hamid, A. Xie, Y . Lee, M. Du, and C. Finn. Bidirectional decoding: Improving action chunking via guided test-time sampling. InInternational Conference on Learning Representations, volume 2025, pages 4594–4627, 2025
2025
-
[16]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [17]
-
[18]
Black, M
K. Black, M. Galliker, and S. Levine. Real-time execution of action chunking flow policies. Advances in Neural Information Processing Systems, 38:33383–33407, 2026
2026
- [19]
- [20]
-
[21]
Training-Time Action Conditioning for Efficient Real- Time Chunking,
K. Black, A. Z. Ren, M. Equi, and S. Levine. Training-time action conditioning for efficient real-time chunking.arXiv preprint arXiv:2512.05964, 2025
-
[22]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
- [23]
-
[24]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36: 44776–44791, 2023
2023
-
[25]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [27]
-
[28]
H. Zhou, W. Liao, X. Huang, Y . Tang, F. Otto, X. Jia, X. Jiang, S. Hilber, G. Li, Q. Wang, et al. Beast: Efficient tokenization of b-splines encoded action sequences for imitation learning. Advances in Neural Information Processing Systems, 38:172934–172959, 2026
2026
- [29]
-
[30]
E. W. Dijkstra. Cooperating sequential processes. In F. Genuys, editor,Programming Languages, pages 43–112. Academic Press, New York, 1968. 10
1968
-
[31]
Matthews, M
M. Matthews, M. Beukman, C. Lu, and J. Foerster. Kinetix: Investigating the training of general agents through open-ended physics-based control tasks. InInternational Conference on Learning Representations, volume 2025, pages 58515–58564, 2025
2025
- [32]
-
[33]
Hokamp and Q
C. Hokamp and Q. Liu. Lexically constrained decoding for sequence generation using grid beam search. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1535–1546, 2017
2017
-
[34]
Post and D
M. Post and D. Vilar. Fast lexically constrained decoding with dynamic beam allocation for neural machine translation. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1314–1324, 2018
2018
-
[35]
Deutsch, S
D. Deutsch, S. Upadhyay, and D. Roth. A general-purpose algorithm for constrained sequential inference. InProceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), pages 482–492, 2019
2019
- [36]
-
[37]
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean. Efficiently scaling transformer inference.Proceedings of machine learning and systems, 5:606–624, 2023
2023
-
[38]
PaliGemma: A versatile 3B VLM for transfer
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Driess, J
D. Driess, J. Springenberg, B. Ichter, L. Yu, A. Li-Bell, K. Pertsch, A. Ren, H. Walke, Q. Vuong, L. X. Shi, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better.Advances in Neural Information Processing Systems, 38:102867–102888, 2026
2026
-
[40]
Leviathan, M
Y . Leviathan, M. Kalman, and Y . Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023
2023
-
[41]
C. Wang, K. Cho, and J. Gu. Neural machine translation with byte-level subwords. In Proceedings of the AAAI conference on artificial intelligence, pages 9154–9160, 2020
2020
-
[42]
Sennrich, B
R. Sennrich, B. Haddow, and A. Birch. Neural machine translation of rare words with subword units. InProceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers), pages 1715–1725, 2016
2016
-
[43]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 11 A Implementation Details A.1 Constrained Decoding under FAST with Byte-level BPE Tokenization Throughout all experiments, we have implemented our approach using JAX based on theopenpi4 repository to adopt π0-FAST [6] as the base model for ourπ0-REA...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.