Nudging Beyond the Comfort Zone: Efficient Strategy-Guided Exploration for RLVR
Pith reviewed 2026-05-20 19:14 UTC · model grok-4.3
The pith
Conditioning rollouts on lightweight strategy contexts enables efficient diverse exploration in RLVR without oracle supervision or brute-force scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
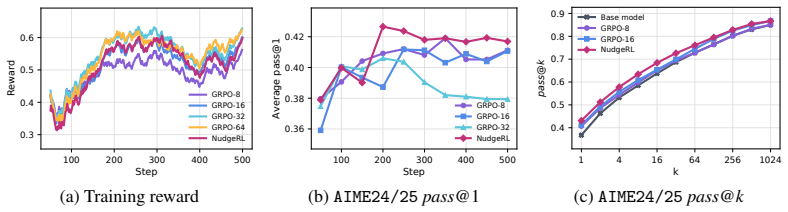
NudgeRL introduces Strategy Nudging, which conditions each rollout on lightweight, strategy-level contexts to induce diverse reasoning trajectories without relying on expensive oracle supervision. It pairs this with a unified objective that decomposes the reward signal into inter- and intra-context components and incorporates a distillation objective to transfer discovered behaviors back to the base policy. Empirically, the method outperforms standard GRPO with up to 8 times larger rollout budgets and outperforms an oracle-guided RL baseline on average across five challenging math benchmarks, showing that structured context-driven exploration can replace both brute-force scaling and methods,
What carries the argument
Strategy Nudging: conditioning each rollout on lightweight, strategy-level contexts to induce diverse reasoning trajectories without oracle supervision or expensive signals.
If this is right
- Decomposing rewards into inter- and intra-context components allows the policy to learn both from diversity across strategies and consistency within each.
- Distillation transfers newly discovered behaviors from nudged trajectories back into the base policy without permanent context dependence.
- Structured exploration scales better than increasing rollout count, delivering higher performance at lower compute for the same training budget.
- The method works without privileged oracle information, making it applicable where feasibility signals are unavailable.
- Context-driven diversity provides a practical substitute for brute-force sampling in RLVR settings.
Where Pith is reading between the lines
- The same lightweight-context idea could be tested in non-math domains such as code generation or scientific reasoning to check whether strategy nudging generalizes beyond the reported benchmarks.
- If the strategy contexts can be generated automatically rather than hand-specified, the framework would require even less human design.
- Combining NudgeRL with existing reward-shaping or curriculum methods might compound the exploration gains.
- The inter/intra-context decomposition suggests a general pattern for turning any diversity source into a usable training signal in policy optimization.
Load-bearing premise
Lightweight strategy-level contexts are sufficient to induce meaningfully diverse reasoning trajectories without oracle supervision or expensive additional signals.
What would settle it
A controlled run of NudgeRL with the strategy contexts removed or randomized that fails to show gains over plain GRPO at matched rollout budgets would falsify the claim that the nudging mechanism drives the efficiency improvement.
Figures





read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has emerged as a scalable paradigm for improving the reasoning capabilities of large language models. However, its effectiveness is fundamentally limited by exploration: the policy can only improve on trajectories it has already sampled. While increasing the number of rollouts alleviates this issue, such brute-force scaling is computationally expensive, and existing approaches that modify the optimization objective provide limited control over what is explored. In this work, we propose NudgeRL, a framework for structured and diversity-driven exploration in RLVR. Our approach introduces Strategy Nudging, which conditions each rollout on lightweight, strategy-level contexts to induce diverse reasoning trajectories without relying on expensive oracle supervision. To effectively learn from such structured exploration, we further propose a unified objective, which decomposes the reward signal into inter- and intra-context components and incorporates a distillation objective to transfer discovered behaviors back to the base policy. Empirically, NudgeRL outperforms standard GRPO with up to 8 times larger rollout budgets, while outperforming oracle-guided RL baseline on average across five challenging math benchmarks. These results demonstrate that structured, context-driven exploration can serve as an efficient and scalable alternative to both brute-force rollout scaling and feasibility-oriented methods based on privileged information. Our code is available at https://github.com/tally0818/NudgeRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes NudgeRL, a framework for structured and diversity-driven exploration in reinforcement learning with verifiable rewards (RLVR) applied to large language models. It introduces Strategy Nudging, which conditions each rollout on lightweight strategy-level contexts to induce diverse reasoning trajectories without expensive oracle supervision. A unified objective is proposed that decomposes the reward signal into inter- and intra-context components and incorporates a distillation term to transfer discovered behaviors back to the base policy. Empirically, the work claims that NudgeRL outperforms standard GRPO even when the latter uses up to 8 times larger rollout budgets, while also outperforming an oracle-guided RL baseline on average across five challenging math benchmarks.
Significance. If the central claims hold after addressing the empirical and methodological details, this work offers a meaningful advance in efficient exploration for RLVR, providing a scalable alternative to brute-force rollout scaling and to methods that rely on privileged oracle information. The public release of code supports reproducibility and positions the contribution as a practical step toward controlled diversity in LLM reasoning optimization.
major comments (2)
- [Abstract and §4] Abstract and §4 (Empirical Evaluation): The central performance claims—outperformance of GRPO with 8× rollout budgets and superiority to the oracle-guided baseline—are presented without reported statistical significance tests, exact benchmark splits, number of independent runs, variance measures, or ablation controls on the inter-/intra-context decomposition and distillation terms. These omissions are load-bearing because the soundness of the efficiency and superiority arguments rests directly on the reliability of the reported gains.
- [§3] §3 (Strategy Nudging and Unified Objective): The description of how lightweight strategy-level contexts are generated and selected must explicitly demonstrate that the process does not draw on model capabilities equivalent to those exploited by the oracle-guided baseline. Without this clarification the comparison to the oracle baseline risks circularity, directly affecting the claim that the gains arise from the proposed nudging mechanism rather than hidden privileged signals.
minor comments (2)
- [§2.2] §2.2: Define the precise mathematical form of the inter-context and intra-context reward terms at first use to avoid ambiguity when they appear in the unified objective.
- [Figure 2] Figure 2: Add explicit labels for the context encoder, reward decomposition, and distillation loss components so that the diagram can be followed without reference to the main text.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Empirical Evaluation): The central performance claims—outperformance of GRPO with 8× rollout budgets and superiority to the oracle-guided baseline—are presented without reported statistical significance tests, exact benchmark splits, number of independent runs, variance measures, or ablation controls on the inter-/intra-context decomposition and distillation terms. These omissions are load-bearing because the soundness of the efficiency and superiority arguments rests directly on the reliability of the reported gains.
Authors: We agree that the current empirical presentation would be strengthened by greater statistical detail and explicit ablations. In the revised manuscript we will report the number of independent runs conducted for each experiment, include variance measures (standard deviations across runs), specify the exact benchmark splits employed, and add statistical significance testing (e.g., paired t-tests) for the reported performance differences. We will also insert a dedicated ablation subsection that isolates the contributions of the inter-context reward term, the intra-context reward term, and the distillation objective. These additions directly address the load-bearing nature of the claims and will be placed in an expanded §4. revision: yes
-
Referee: [§3] §3 (Strategy Nudging and Unified Objective): The description of how lightweight strategy-level contexts are generated and selected must explicitly demonstrate that the process does not draw on model capabilities equivalent to those exploited by the oracle-guided baseline. Without this clarification the comparison to the oracle baseline risks circularity, directly affecting the claim that the gains arise from the proposed nudging mechanism rather than hidden privileged signals.
Authors: We appreciate the referee’s emphasis on avoiding any appearance of circularity. The revised §3 will contain an expanded subsection that explicitly describes the context-generation procedure: lightweight strategy contexts are produced by prompting the base policy itself with concise meta-instructions that elicit high-level reasoning directives (for example, “explore an algebraic approach” or “consider a proof by contradiction”). No ground-truth solutions, verified trajectories, or oracle-level supervision are provided at any stage. We will contrast this process with the oracle-guided baseline, which supplies direct access to expert solution paths, and will include illustrative prompts and pseudocode to make the distinction unambiguous. This clarification will confirm that performance gains derive from the structured nudging and unified objective rather than hidden privileged information. revision: yes
Circularity Check
New conditioning and objective components supply independent exploration without reduction to fitted inputs
full rationale
The derivation introduces Strategy Nudging via lightweight strategy-level contexts and a unified objective decomposing rewards into inter-/intra-context terms plus distillation. These are presented as novel additions rather than quantities defined by or fitted to the target performance metrics. Comparisons to GRPO (with scaled rollouts) and an oracle-guided baseline supply external grounding. No load-bearing step reduces a claimed prediction or uniqueness result to a self-citation, fitted parameter, or definitional tautology; the central claims retain independent content from the proposed mechanisms.
Axiom & Free-Parameter Ledger
free parameters (1)
- strategy context design
axioms (1)
- domain assumption Conditioning on strategy contexts induces diverse reasoning trajectories
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Strategy Nudging appends lightweight, heuristic text prompts (e.g., specific strategies for math problems or reasoning keywords) to the input... inter-intra group advantage... distillation-augmented objective
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorem unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NUDGERL outperforms standard GRPO with up to 8 times larger rollout budgets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Matharena: Evaluating llms on uncontaminated math competitions, February 2025
Mislav Balunovi ´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi ´c, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions, February 2025. URL https://matharena.ai/
work page 2025
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Jia Deng, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, and Ji-Rong Wen. Decomposing the entropy-performance exchange: The missing keys to unlocking effective reinforcement learning. arXiv preprint arXiv:2508.02260, 2025
-
[4]
Measuring mathematical problem solving with the math dataset.NeurIPS, 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.NeurIPS, 2021
work page 2021
-
[5]
Jian Hu, Mingjie Liu, Ximing Lu, Fang Wu, Zaid Harchaoui, Shizhe Diao, Yejin Choi, Pavlo Molchanov, Jun Yang, Jan Kautz, et al. Brorl: Scaling reinforcement learning via broadened exploration.arXiv preprint arXiv:2510.01180, 2025
-
[6]
Math-verify: A toolkit for verifying mathematical reasoning
HuggingFace. Math-verify: A toolkit for verifying mathematical reasoning. https://github. com/huggingface/Math-Verify, 2024. Accessed 2026-05-06
work page 2024
-
[7]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Self-hinting language models enhance reinforcement learning.arXiv preprint arXiv:2602.03143, 2026
Baohao Liao, Hanze Dong, Xinxing Xu, Christof Monz, and Jiang Bian. Self-hinting language models enhance reinforcement learning.arXiv preprint arXiv:2602.03143, 2026
-
[9]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models. arXiv preprint arXiv:2505.24864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv, 2503.20783, 2025. URLhttps://doi.org/10.48550/arXiv.2503.20783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.20783 2025
-
[12]
American mathematics competitions
Mathematical Association of America. American mathematics competitions. https://www. maa.org/math-competitions, 2023
work page 2023
-
[13]
Aime: American invitational mathematics examination
Mathematical Association of America. Aime: American invitational mathematics examination. https://www.maa.org/math-competitions, 2025
work page 2025
-
[14]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott 10 Geng, S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
OpenAI. Gpt-4o mini. https://openai.com/ko-KR/index/ gpt-4o-mini-advancing-cost-efficient-intelligence/ , 2024. Accessed: 2026-05- 04
work page 2024
-
[16]
Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, and Aviral Kumar. Pope: Learning to reason on hard problems via privileged on-policy exploration.arXiv preprint arXiv:2601.18779, 2026
-
[17]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv, 2402.03300, 2024. URL https://doi.org/10.48550/arXiv. 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[19]
arXiv preprint arXiv:2602.02482 , year=
Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback.arXiv preprint arXiv:2602.02482, 2026
-
[20]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
TRL: Transformers Rein- forcement Learning, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Rein- forcement Learning, 2020. URLhttps://github.com/huggingface/trl
work page 2020
-
[23]
The invisible leash: Why rlvr may or may not escape its origin.arXiv preprint arXiv:2507.14843, 2025
Fang Wu, Weihao Xuan, Ximing Lu, Zaïd Harchaoui, and Yejin Choi. The invisible leash: Why RLVR may not escape its origin.arXiv, 2507.14843, 2025. URL https://doi.org/10. 48550/arXiv.2507.14843
-
[24]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
URLhttps://doi.org/10.48550/arXiv.2503.14476
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476
-
[26]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv, 2504.13837, 2025. URL https://doi.org/10.48550/arXiv.2504. 13837
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504 2025
-
[27]
Xiaoyun Zhang, Xiaojian Yuan, Di Huang, Wang You, Chen Hu, Jingqing Ruan, Kejiang Chen, and Xing Hu. Rediscovering entropy regularization: Adaptive coefficient unlocks its potential for llm reinforcement learning.arXiv preprint arXiv:2510.10959, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Xuechen Zhang, Zijian Huang, Yingcong Li, Chenshun Ni, Jiasi Chen, and Samet Oymak. Bread: Branched rollouts from expert anchors bridge sft & rl for reasoning.arXiv preprint arXiv:2506.17211, 2025. 11 A Related Work A.1 Reinforcement Learning with Verifiable Rewards Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a scalable paradigm f...
-
[29]
[Hint 2] ... {num_hints}. [Hint {num_hints}] Make sure each hint is a distinct mathematical concept or theorem.""" Strategy Nudging prompt.Given a problem and an optional hint, we construct prompts that encourage the model to follow a specific reasoning strategy. The model is instructed to explicitly separate its reasoning process and final answer using p...
-
[30]
Without loss of generality, assumex > y, sox−y= 7 √ 2— (4) — ### Step 3: Use equations (1), (2), (3), (4) From (1):x 2 +y 2 = 196 From (4):x=y+ 7 √ 2 Plug into (1): (y+ 7 √ 2)2 +y 2 = 196 y2 + 14 √ 2y+ 98 +y 2 = 196 2y2 + 14 √ 2y+ 98 = 196 2y2 + 14 √ 2y= 98 y2 + 7 √ 2y= 49 This is a quadratic iny. Let’s solve it. Complete the square: y2 + 7 √ 2y= 49 y2 + ...
-
[31]
= (13,3 √ 3) and: L= r 196− c 2 2 , c 2 ! Since: c 2 = 8 √ 3 and: c 2 2 = (8 √ 3)2 = 192 So: √ 196−192 = √ 4 = 2 Thus: L= (2,8 √ 3) 25 NudgeRL Solution (Cont.) Therefore: -K= (13,3 √ 3)-L= (2,8 √ 3) Now we want the area of quadrilateralBKLC Points: -B= (26,0)-K= (13,3 √ 3)-L= (2,8 √ 3)-C= (0,16 √ 3) QuadrilateralBKLC— in order: B→K→L→C→B We can compute it...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.