Long Live the Librarian! A Persistent Search Sub-Agent for Energy-Efficient Multi-Agent Software Engineering Systems
Pith reviewed 2026-06-29 09:56 UTC · model grok-4.3
The pith
The Librarian persistent search sub-agent reduces GPU energy consumption by up to 25% in multi-agent software engineering systems without hurting task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
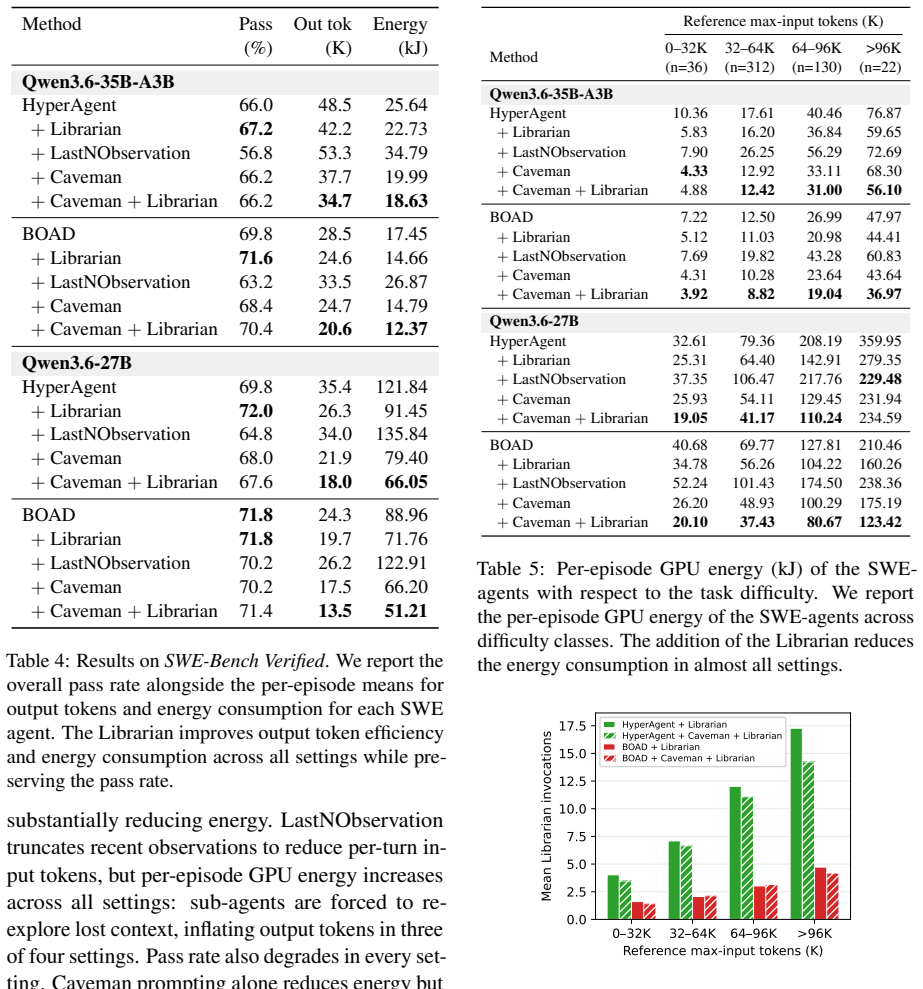
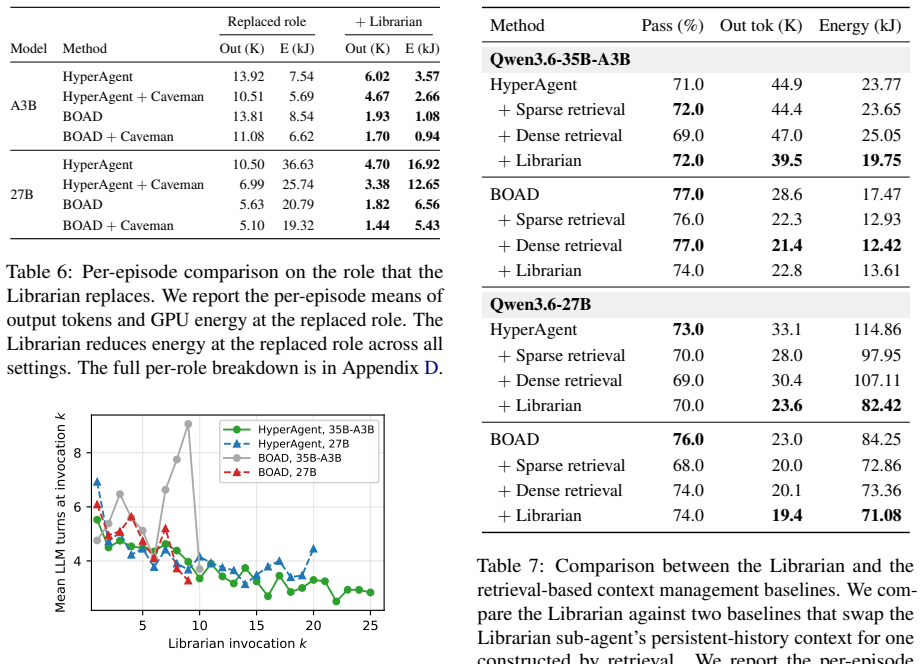
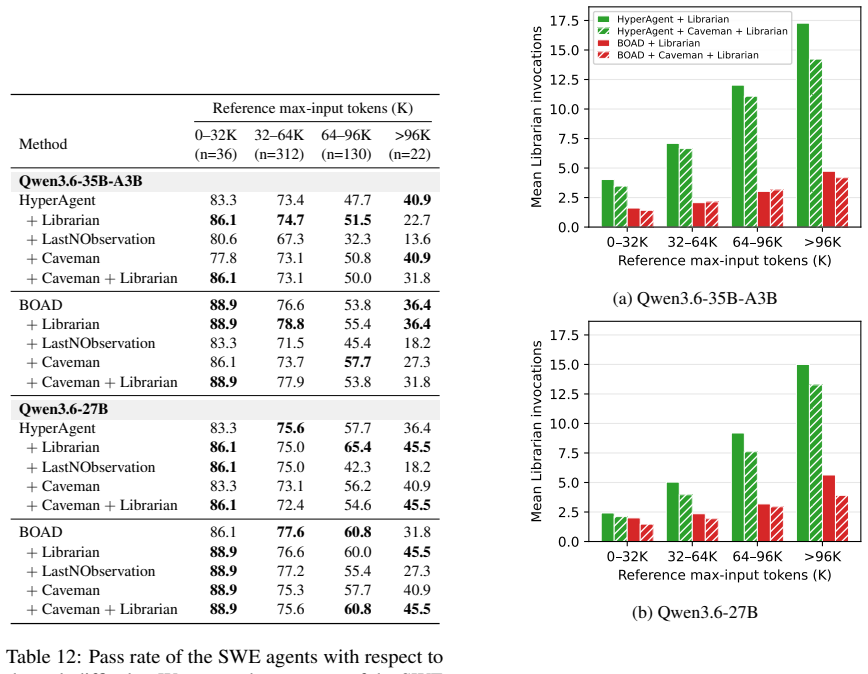
The central discovery is that redundant repository explorations across agents in multi-agent SWE systems generate unnecessary output tokens, which dominate energy use. By introducing Librarian, a persistent sub-agent that tracks search history and suppresses redundant actions, returning short references to file regions, the systems achieve up to 25% lower per-episode GPU energy use without loss in performance on SWE-Bench Verified.
What carries the argument
Librarian, a persistent search sub-agent that tracks repository-search history across agents and returns short references to file regions instead of full excerpts to suppress redundant exploration.
If this is right
- Multi-agent SWE systems can maintain performance while lowering energy demands through shared search tracking.
- Reducing output token volume directly translates to lower energy consumption given the 30-1000x higher cost of output tokens.
- Existing MAS frameworks can integrate such a sub-agent without major redesign.
- Task performance remains unchanged when redundant paths are avoided.
Where Pith is reading between the lines
- Similar persistent trackers could apply to other multi-agent tasks beyond software engineering where agents overlap in information gathering.
- If the energy asymmetry holds across models, this method might scale to larger systems with more agents.
- Future systems might design agents to minimize output length by default using such references.
Load-bearing premise
The main energy cost comes from redundant output tokens in overlapping searches, and a lightweight tracker can remove most redundancy without missing important paths or adding significant new costs.
What would settle it
Running the same multi-agent SWE system on SWE-Bench tasks with and without the Librarian sub-agent and measuring both energy use and task success rate; if energy does not drop or success falls, the claim is falsified.
Figures

read the original abstract
Multi-agent systems (MAS) have substantially advanced autonomous software engineering (SWE), but their growing inference energy demands raise sustainability concerns. In this paper, we demonstrate that this cost is concentrated in an overlooked source: redundant output tokens generated across agents. Two empirical findings ground this claim. First, our per-token energy attribution for MAS reveals a sharp asymmetry: an output token consumes 30 to 1,000 times more energy than an input or cached token. Second, MAS inflate per-episode output because agents repeatedly re-explore overlapping repository regions. To address this inefficiency, we propose Librarian, a persistent search sub-agent that tracks repository-search history and suppresses redundant exploration actions across agents. By returning short references to file regions instead of full file excerpts, Librarian further reduces output-token volume. On SWE-Bench Verified, Librarian reduces per-episode GPU energy consumption of existing multi-agent SWE systems by up to 25% while preserving task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that energy costs in multi-agent SWE systems are dominated by redundant output tokens arising from overlapping repository searches, supported by two empirical findings: a 30-1000x energy asymmetry between output tokens and input/cached tokens, and inflation of output volume due to repeated exploration. It introduces Librarian, a persistent search sub-agent that tracks repository-search history across agents and returns short file-region references instead of full excerpts. On SWE-Bench Verified, this yields up to 25% reduction in per-episode GPU energy consumption while preserving task performance.
Significance. If the empirical results and underlying assumptions hold after detailed validation, the work identifies a concrete, measurable inefficiency in current MAS designs for code tasks and offers a lightweight architectural fix. This could inform more sustainable multi-agent frameworks, particularly as inference energy becomes a deployment constraint. The use of a standard benchmark (SWE-Bench Verified) and focus on per-episode GPU metrics provide a reproducible starting point for follow-up studies.
major comments (2)
- [Abstract] Abstract: the two empirical findings and the 25% reduction are stated without any reference to methodology, baselines, error bars, statistical tests, or data-exclusion criteria; these details are load-bearing for assessing whether the energy attribution and performance preservation are robust.
- [Proposed Method / Experiments] Librarian description and evaluation: the claim that the persistent tracker plus short-reference mechanism removes most redundant output volume without new overhead or missed exploration paths is untested in the provided text; if the tracker either adds measurable latency/energy or prunes a path an agent would have needed, both the net saving and the 'preserving task performance' result collapse.
minor comments (1)
- [Abstract] Abstract: the energy-asymmetry range is written '30 to 1,000'; standardize formatting for consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below. The first comment correctly identifies that the abstract would benefit from additional methodological pointers; we have revised it accordingly. The second comment raises a valid concern about explicit validation of overhead and coverage; we clarify the existing empirical support while adding targeted ablations in revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the two empirical findings and the 25% reduction are stated without any reference to methodology, baselines, error bars, statistical tests, or data-exclusion criteria; these details are load-bearing for assessing whether the energy attribution and performance preservation are robust.
Authors: We agree that the abstract should reference the core methodology to support the stated findings. In the revised version we have added one sentence directing readers to the per-token energy measurement protocol (Section 3.1), the SWE-Bench Verified setup with the listed baselines, and the performance metrics reported in Section 4. Full statistical details, error bars, and exclusion criteria remain in the main text and appendix as they exceed typical abstract length limits; we believe this balances conciseness with transparency. revision: yes
-
Referee: [Proposed Method / Experiments] Librarian description and evaluation: the claim that the persistent tracker plus short-reference mechanism removes most redundant output volume without new overhead or missed exploration paths is untested in the provided text; if the tracker either adds measurable latency/energy or prunes a path an agent would have needed, both the net saving and the 'preserving task performance' result collapse.
Authors: The evaluation on SWE-Bench Verified already provides net evidence: Librarian yields up to 25% lower per-episode GPU energy while task success rates remain statistically indistinguishable from the baselines. This outcome implies that any tracker overhead is dominated by the token savings and that no critical exploration paths were lost. Nevertheless, to directly address the concern we have added an ablation (new Table 5) that isolates Librarian's incremental latency and energy cost, together with a coverage analysis comparing repository regions visited with and without the persistent tracker. These additions confirm the net benefit without introducing new overhead that would negate the reported savings. revision: partial
Circularity Check
No derivation chain present; results are empirical measurements
full rationale
The paper reports two empirical observations (output-token energy asymmetry and redundant repository searches in MAS) followed by a system proposal (Librarian) and a benchmark result (25% energy reduction on SWE-Bench Verified). No equations, fitted parameters, or mathematical derivations are described in the provided text. The central claim is therefore a direct empirical outcome rather than a derivation that could reduce to its own inputs by construction. No self-citation load-bearing steps or ansatz smuggling are visible. This is the normal non-circular case for an engineering measurement paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Output tokens dominate energy cost in MAS inference (30-1000x input/cached tokens)
- domain assumption Agents repeatedly re-explore overlapping repository regions
invented entities (1)
-
Librarian persistent search sub-agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 1658–1677, Bangkok, Thailand
LongLLMLingua: Accelerating and enhanc- ing LLMs in long context scenarios via prompt com- pression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 1658–1677, Bangkok, Thailand. Association for Computational Linguistics. Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, K...
2024
-
[2]
Codexembed: A generalist embedding model family for multiligual and multi-task code retrieval,
Compressing context to enhance inference ef- ficiency of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natu- ral Language Processing, pages 6342–6353, Singa- pore. Association for Computational Linguistics. Ye Liu, Rui Meng, Shafiq Jot, Silvio Savarese, Caim- ing Xiong, Yingbo Zhou, and Semih Yavuz. 2024. Codexembed: ...
-
[3]
Association for Computing Machinery
Power hungry processing: Watts driving the cost of ai deployment? InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’24, page 85–99, New York, NY , USA. Association for Computing Machinery. Jacob Morrison, Clara Na, Jared Fernandez, Tim Dettmers, Emma Strubell, and Jesse Dodge. 2025. Holistically evaluating the ...
2024
-
[4]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. Preprint, arXiv:2310.08560. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S Bern- stein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th an- nual acm symposium on user interface software and technology, pages 1–22. Pr...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
,→ ,→ ,→
Is``result``PROSE only (no``def ...``/``class ...``/ line-numbered code blocks)? If I caught myself pasting code into``result``, move it to ``view_commands``instead. ,→ ,→ ,→
-
[6]
,→ ,→ ,→ ,→
Are the line ranges in``view_commands``PRECISE (verified against my actual``view``/``cat -n`` output)? Vague ranges like``[200, 300]``make the main agent see the wrong region -- re-ground from output. ,→ ,→ ,→ ,→
-
[7]
fragments
For multi-fragment``view_commands``: are the regions REALLY scattered (different files OR non-adjacent regions), or am I really showing one long block split into "fragments"? If the latter, collapse to a single``[path, start, end]`` covering the union range. ,→ ,→ ,→ ,→ ,→
-
[8]
this is a fix for issue #N
Did my``result``slip into analysis / interpretation territory? Phrases to scrub before submitting:,→ - "this is a fix for issue #N" / "this was added to handle X" (historical inference -- not your job) ,→ ,→ - "the bug is here because ..." / "the issue arises when ..." (diagnosis -- not your job),→ - "the fix should ..." / "you should change this to ..." ...
-
[10]
,→ ,→ ,→
Use the code_navigator subagent to map the relevant codebase structure, focusing on files and functions identified in the analysis to understand dependencies and data flow. ,→ ,→ ,→
-
[11]
,→ ,→ ,→ 16
Synthesize the structured analysis and code mapping to implement the fix, ensuring the solution addresses the root cause while adhering to the established success conditions. ,→ ,→ ,→ 16
-
[12]
Create a minimal test case or validation script to verify the fix against the reproduction criteria defined in the initial analysis. ,→ ,→
-
[14]
Use the submit tool to submit the changes to the repository.,→ BOAD + Librarian.Steps 1, 3, 5, and 6 are byte-identical to the baseline. Step 2 is rewritten to phrase every search as a natural-language lookup question to the Librarian, and step 4 is rewritten to call the Librarian for additional location lookups after test failures. Prompt for BOAD orches...
-
[15]
,→ ,→ ,→
Use the issue_analyzer subagent to decompose the problem description into structured requirements, identify affected components, and define explicit success criteria to guide the investigation. ,→ ,→ ,→
-
[16]
Where lives <symbol / behaviour>?
Use the librarian subagent to map the relevant code areas: phrase each request as a natural-language lookup question ("Where lives <symbol / behaviour>?", "Show me the body of <function>", "Locate the test that exercises <feature>"). The librarian is a single long-lived instance -- its conversation history accumulates across calls in this episode, so foll...
-
[17]
,→ ,→ ,→
Synthesize the structured analysis and code mapping to implement the fix, ensuring the solution addresses the root cause while adhering to the established success conditions. ,→ ,→ ,→
-
[18]
Write and execute targeted unit tests or integration checks to validate that the solution resolves the issue without introducing regressions. If any check fails, consult the librarian for ADDITIONAL location lookups (other call sites of a changed symbol, subclasses that override it, fixtures or sibling tests that exercise the failing path) -- phrase each ...
-
[19]
After you have solved the issue, delete any test files or temporary files you created.,→
-
[20]
Prompt for HyperAgent planner
Use the submit tool to submit the changes to the repository.,→ HyperAgent baseline.The planner’s five-step sequence with step 2 delegating to the Codebase Navigator. Prompt for HyperAgent planner
-
[22]
Delegate to the Codebase Navigator to localize where the change must happen.,→
-
[25]
HyperAgent + Librarian.Step 2 is rewritten to delegate to the Repo Librarian
Iterate as needed until the tests pass. HyperAgent + Librarian.Step 2 is rewritten to delegate to the Repo Librarian. The remaining four steps are byte-identical to the baseline. Prompt for HyperAgent planner with Li- brarian
-
[26]
Read the PR description and understand the issue
-
[27]
Delegate to the Repo Librarian to localize where the change must happen.,→
-
[28]
Delegate to the Codebase Editor to apply the minimal source change.,→
-
[29]
Delegate to the Executor to verify the fix (run the relevant tests / a reproduction script).,→
-
[30]
implement a solution for
Iterate as needed until the tests pass. C Experiment Details This appendix records the configuration held fixed across the experiments of §5—the vLLM serving, sampling, and scaffold settings (Appendix C.1) and the caveman prompting style directive (Ap- pendix C.2). C.1 Serving and scaffold configuration Table 9 lists the vLLM serving configuration, sam- p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.