LLM Features Can Hurt GNNs: Concatenation Interference on Homophilous Graph Benchmarks
Pith reviewed 2026-06-27 02:08 UTC · model grok-4.3
The pith
Concatenating LLM node features directly to graph models can degrade accuracy on homophilous benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
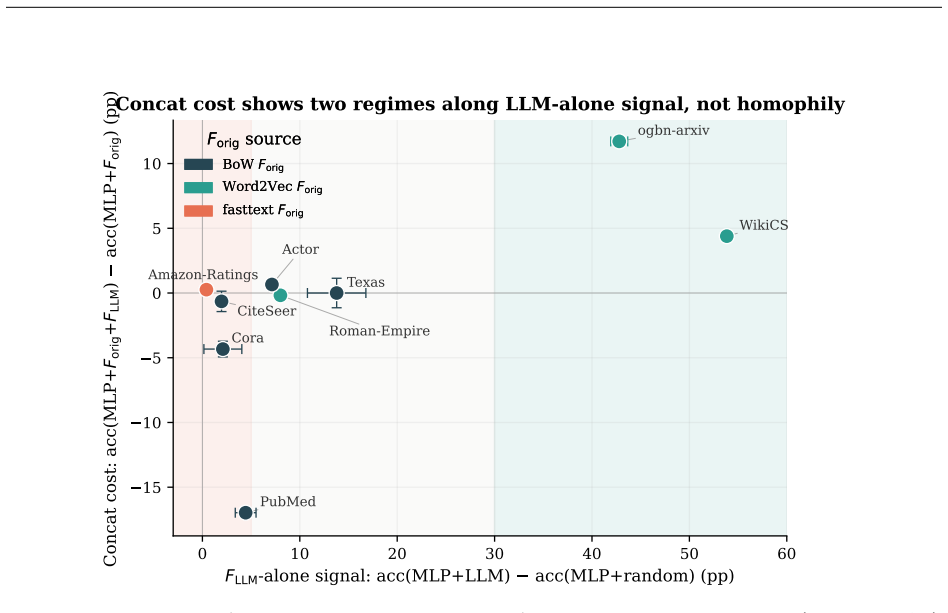
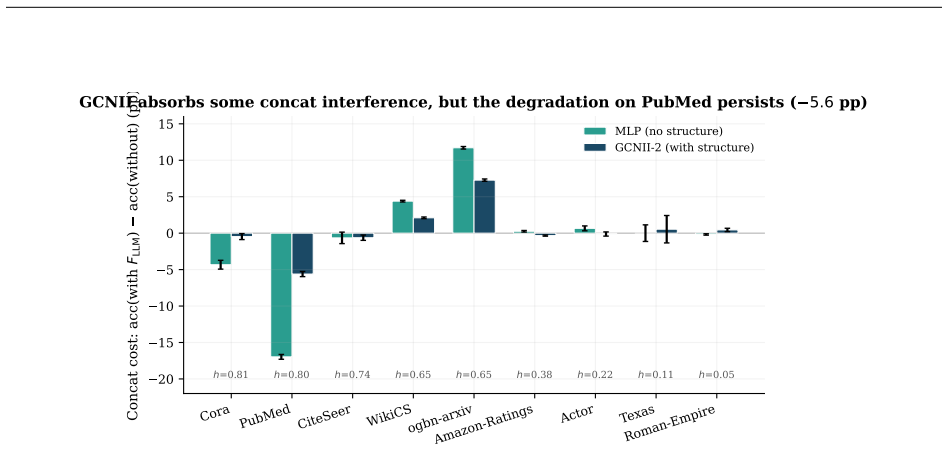
On the Planetoid public split with bag-of-words features, concatenating SBERT-encoded GPT-4o-mini TAPE features to an MLP reduces PubMed test accuracy by 17.0 percentage points and Cora by 4.3 points. The degradation is smaller with GCN backbones or random splits and reverses on WikiCS and ogbn-arxiv. Delta_sig correlates with the concatenation cost across nine datasets.
What carries the argument
Delta_sig, a measure of LLM-alone discriminability that is used to predict whether concatenation will produce non-positive accuracy change.
If this is right
- Concatenation interference is strongest in the low-Delta_sig, small-n regime.
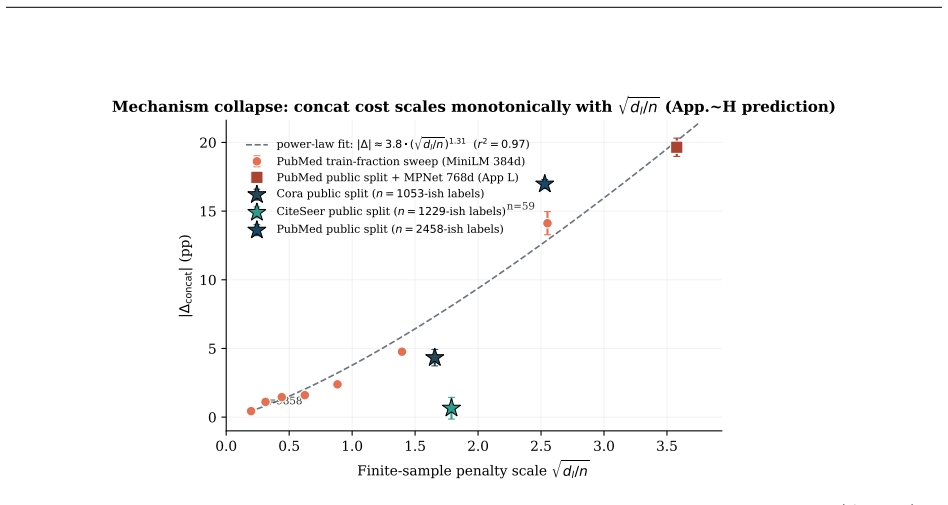
- The effect follows a power law relating drop magnitude to the square root of LLM feature dimension over sample size.
- Dimension-controlled ablations show the drop lies between PCA reduction and Gaussian noise addition.
- Delta_sig classifies seven of nine datasets correctly for non-positive concat cost using a threshold around 13.8 pp.
Where Pith is reading between the lines
- Practitioners should check LLM feature discriminability before concatenating rather than assuming benefit.
- Future work could test whether the same interference appears when concatenating to more advanced GNN architectures.
- Delta_sig might generalize to other feature types beyond LLMs on graph tasks.
Load-bearing premise
The accuracy drops are caused by interference from the concatenation step itself rather than by differences in training dynamics or unmeasured feature properties.
What would settle it
Re-running the PubMed MLP experiment with the same LLM features but identical optimization and seed settings that eliminates the 17 pp gap.
Figures




read the original abstract
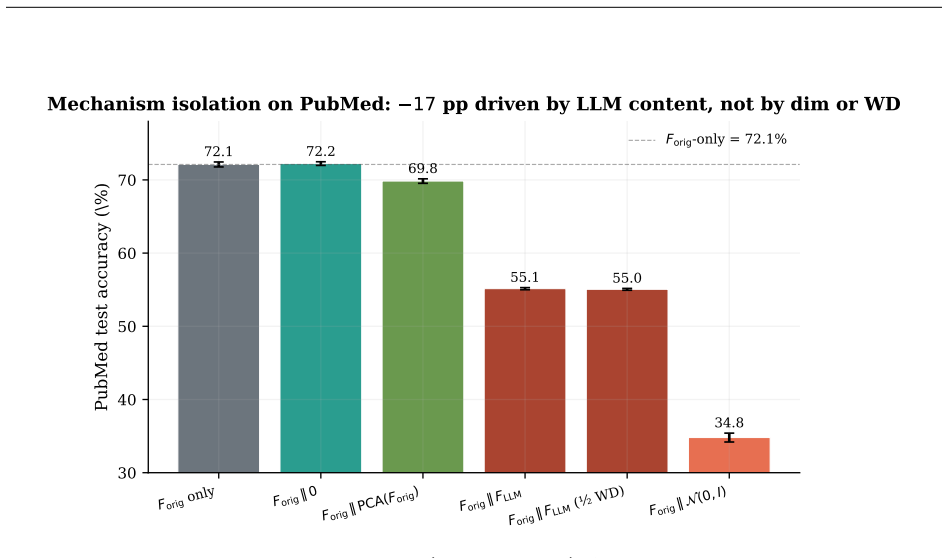
Adding LLM-generated node features to graph neural networks (GNNs) is widely reported to improve accuracy on standard benchmarks. We document a contrasting observation: when LLM features are introduced through pure input concatenation (rather than joint training, distillation, or prompt-conditioning), they can systematically degrade accuracy on the same homophilous benchmarks where end-to-end LLM pipelines succeed. With an MLP backbone on the Planetoid public split and bag-of-words original features, concatenating SBERT-encoded GPT-4o-mini TAPE features reduces PubMed test accuracy by -17.0 +/- 0.3 pp and Cora by -4.3 +/- 0.6 pp (CiteSeer -0.6 +/- 0.8 pp, within seed noise). The drop attenuates as we relax each condition (GCN / GCNII / GAT backbones, random splits, smaller encoders) and reverses on medium-homophily WikiCS (+4.4 pp) and ogbn-arxiv (+11.7 pp). To predict when concatenation helps versus hurts, we report a simple measure of LLM-alone discriminability, Delta_sig. Across 9 datasets Delta_sig correlates with the concatenation cost more strongly than homophily at point estimate (r^2 = 0.38 vs. 0.06; N=9, bootstrap CIs overlap). The bootstrap-best change-point is tau = 13.8 pp, and the rule "Delta_sig <= tau predicts non-positive concat cost" classifies 7/9 datasets correctly; since 60% of bootstrap samples place tau in [5, 30] pp, we treat Delta_sig as an interpretive lens rather than a precision filter. A dimension-controlled ablation on PubMed places the LLM-feature drop between same-source PCA (-2.3 pp) and same-dim Gaussian noise (-37.3 pp), ruling out dimensionality and weight-decay artifacts. Nine PubMed configurations fit a power law |Delta_concat| proportional to (sqrt(d_l/n))^1.31 with r^2 = 0.97; the low-Delta_sig, small-n corner is exactly where the headline -17 pp PubMed deficit appears.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that introducing LLM-generated node features (SBERT-encoded GPT-4o-mini TAPE) via pure input concatenation to bag-of-words features systematically degrades accuracy on homophilous Planetoid benchmarks when using an MLP backbone on the public split (PubMed: -17.0 +/- 0.3 pp; Cora: -4.3 +/- 0.6 pp), with the effect attenuating or reversing under relaxed conditions (GCN/GCNII/GAT backbones, random splits, other datasets). It introduces Delta_sig (LLM-alone discriminability) as an interpretive measure that correlates more strongly with concatenation cost than homophily (r^2=0.38 vs 0.06), supported by a bootstrap change-point at tau=13.8 pp, a dimension-controlled ablation on PubMed, and a power-law fit |Delta_concat| ~ (sqrt(d_l/n))^1.31 (r^2=0.97) across nine PubMed configurations.
Significance. If the central measurements hold, the work supplies concrete evidence that simple concatenation of LLM features can harm rather than help on standard homophilous benchmarks, contrasting with gains reported for joint training or distillation pipelines. Strengths include the direct accuracy measurements, the dimension-controlled PCA/noise ablation that rules out dimensionality and weight-decay artifacts, the high-r^2 power-law relation on multiple PubMed configurations, and the transparent bootstrap analysis of the Delta_sig change-point. These elements provide a falsifiable lens for when concatenation is likely to be neutral or detrimental.
major comments (1)
- [Experimental protocol and ablation sections] The central claim attributes the observed accuracy drops directly to 'pure input concatenation' interference. The reported protocol uses identical training hyperparameters for the bag-of-words baseline and the concatenated model. While the dimension-controlled ablation (placing the LLM drop between PCA at -2.3 pp and Gaussian noise at -37.3 pp) rules out dimensionality and weight-decay artifacts, no evidence is provided that the higher-dimensional concatenated inputs reach an equivalent optimum (e.g., via separate hyperparameter search, learning-curve comparison, or adjusted LR/epochs). This leaves open the possibility that part of the -17 pp PubMed drop arises from under-optimization rather than feature interference per se, which is load-bearing for the attribution in the title and abstract.
minor comments (2)
- [Section introducing Delta_sig] The definition and computation of Delta_sig (computed from LLM features alone before GNN training) should be stated with an explicit equation or pseudocode in the main text to make the correlation analysis fully reproducible without reference to the appendix.
- [Power-law analysis paragraph] The power-law fit is reported with r^2=0.97 on nine PubMed configurations; adding the fitted exponent with its uncertainty and the exact list of configurations (e.g., as a table row) would strengthen the claim that the low-Delta_sig, small-n corner explains the headline deficit.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The recognition of the paper's direct measurements, ablations, and analyses is appreciated. We address the single major comment below.
read point-by-point responses
-
Referee: [Experimental protocol and ablation sections] The central claim attributes the observed accuracy drops directly to 'pure input concatenation' interference. The reported protocol uses identical training hyperparameters for the bag-of-words baseline and the concatenated model. While the dimension-controlled ablation (placing the LLM drop between PCA at -2.3 pp and Gaussian noise at -37.3 pp) rules out dimensionality and weight-decay artifacts, no evidence is provided that the higher-dimensional concatenated inputs reach an equivalent optimum (e.g., via separate hyperparameter search, learning-curve comparison, or adjusted LR/epochs). This leaves open the possibility that part of the -17 pp PubMed drop arises from under-optimization rather than feature interference per se, which is load-bearing for the attribution in the title and abstract.
Authors: We acknowledge the validity of this observation. The manuscript employs the same set of training hyperparameters for the bag-of-words baseline and the LLM-concatenated model to ensure a controlled comparison. While this protocol does not include a dedicated hyperparameter optimization for the concatenated inputs, the dimension-controlled ablation demonstrates that the observed drop cannot be attributed solely to increased input dimensionality, as PCA reduction yields only -2.3 pp while LLM concatenation yields -17.0 pp. Furthermore, the Gaussian noise control at matched dimension produces a much larger drop (-37.3 pp), indicating that the LLM features introduce a specific interference effect beyond optimization challenges from dimensionality. The power-law relationship fitted across nine PubMed configurations with r^2 = 0.97 provides additional evidence for a systematic phenomenon tied to feature discriminability (Delta_sig). Nevertheless, to strengthen the claim and rule out under-optimization, we will conduct a separate hyperparameter search for the concatenated model on PubMed and include learning curve analyses in the revised manuscript. revision: yes
Circularity Check
No significant circularity; claims are direct empirical measurements
full rationale
The paper reports direct measurements of test accuracy drops on Planetoid splits when concatenating LLM features to MLP/GNN backbones. Delta_sig is computed solely from LLM features prior to any GNN training, and the reported r^2 correlations, bootstrap change-point tau, and power-law exponent are descriptive fits to the observed accuracy deltas across the 9 datasets and 9 PubMed configurations. These fits are not used to derive the headline drops or to claim first-principles predictions; the central attribution to concatenation interference rests on the measured deltas themselves (with dimension-controlled ablations). No self-citations, uniqueness theorems, or ansatzes appear in the provided text to support the claims. The derivation chain is therefore self-contained observational reporting rather than reduction to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- tau =
13.8 pp
- power-law exponent =
1.31
axioms (1)
- standard math Standard assumptions on random initialization, fixed public splits, and early-stopping behavior in GNN training
invented entities (1)
-
Delta_sig
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chen, M., Wei, Z., Huang, Z., Ding, B., and Li, Y. (2020). Simple and deep graph convolutional networks. In ICML
2020
-
[2]
Chen, R. et al. (2024). LLaGA: Large Language and Graph Assistant. In ICML
2024
- [3]
-
[4]
Li, Y., Wang, P., Zhu, X., Chen, A., Jiang, H., Cai, D., Chan, W. K., and Li, J. (2024). GLBench: A Comprehensive Benchmark for Graph with Large Language Models. In NeurIPS Datasets and Benchmarks Track. arXiv:2407.07457
-
[5]
Wu, X., Shen, Y., Ge, F., Shan, C., Jiao, Y., Sun, X., and Cheng, H. (2025). When Do LLMs Help With Node Classification? A Comprehensive Analysis. In ICML
2025
- [6]
- [7]
-
[8]
Luan, S. et al. (2024). The heterophily paradox: when homophily fails and when it succeeds
2024
-
[9]
Ma, Y. et al. (2022). Is homophily a necessity for graph neural networks? In ICLR
2022
-
[10]
Tang, J. et al. (2024). GraphGPT: Graph instruction tuning for large language models
2024
-
[11]
Wang, R. et al. (2025). TANS: Topology-aware neighbor summarization for LLM-on-graph. NAACL
2025
-
[12]
Ying, R. et al. (2019). GNNExplainer: Generating explanations for graph neural networks. NeurIPS
2019
-
[13]
Yuan, H. et al. (2021). On explainability of graph neural networks via subgraph explorations. ICML
2021
-
[14]
Zhao, J. et al. (2023). Learning on large-scale text-attributed graphs via variational inference. In ICLR (GLEM)
2023
-
[15]
Zhu, J. et al. (2020). Beyond homophily in graph neural networks: Current limitations and effective designs. NeurIPS
2020
-
[16]
Shchur, O., Mumme, M., Bojchevski, A., and Günnemann, S. (2018). Pitfalls of graph neural network evaluation. Relational Representation Learning Workshop, NeurIPS
2018
-
[17]
Duval, A., and Malliaros, F. D. (2021). GraphSVX: Shapley value explanations for graph neural networks. In ECML-PKDD
2021
-
[18]
Carlini, N., Tramer, F., Wallace, E., Jagielski, M., Herbert-Voss, A., Lee, K., Roberts, A., Brown, T., Song, D., Erlingsson, U., Oprea, A., and Raffel, C. (2021). Extracting training data from large language models. In30th USENIX Security Symposium, pp. 2633–2650
2021
-
[19]
A., García-Ferrero, I., Etxaniz, J., de Lacalle, O
Sainz, O., Campos, J. A., García-Ferrero, I., Etxaniz, J., de Lacalle, O. L., and Agirre, E. (2023). NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. InFindings of EMNLP
2023
- [20]
-
[21]
Huang, Y., Lin, J., Zhou, C., Yang, H., and Huang, L. (2022). Modality competition: What makes joint training of multi-modal network fail in deep learning? (Provably). InProc. ICML
2022
-
[22]
Peng, X., Wei, Y., Deng, A., Wang, D., and Hu, D. (2022). Balanced multimodal learning via on-the-fly gradient modulation. InProc. CVPR, pp. 8238–8247
2022
-
[23]
naive Bayes
Bickel, P. J. and Levina, E. (2004). Some theory for Fisher’s linear discriminant function, “naive Bayes”, and some alternatives when there are many more variables than observations.Bernoulli, 10(6):989–1010
2004
-
[24]
(2009).The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed
Hastie, T., Tibshirani, R., and Friedman, J. (2009).The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed. Springer. 11
2009
- [25]
-
[26]
Hewitt, J., and Manning, C. D. (2019). A Structural Probe for Finding Syntax in Word Representations. InNAACL-HLT, pp. 4129–4138
2019
-
[27]
Belinkov, Y., and Glass, J. (2019). Analysis Methods in Neural Language Processing: A Survey. Transactions of the Association for Computational Linguistics, 7:49–72
2019
-
[28]
Voita, E., and Titov, I. (2020). Information-Theoretic Probing with Minimum Description Length. In EMNLP, pp. 183–196
2020
-
[29]
Zheng, Y., Zhang, Z., Wang, Z., Li, X., Luan, S., Peng, X., and Chen, L. (2025). Disentangling and Re-evaluating The Effectiveness of Graph Structure Learning For GNNs. In NeurIPS Datasets and Benchmarks Track. OpenReview brvLHfbSQX
2025
-
[30]
When Structure Doesn't Help: LLMs Do Not Read Text-Attributed Graphs as Effectively as We Expected
Xu, H., You, Y., and Ma, T. (2025). When Structure Doesn’t Help: LLMs Do Not Read Text-Attributed Graphs as Effectively as We Expected. arXiv:2511.16767. 12 A LLM Feature Generation Details Text-attributed datasets.For Cora, CiteSeer, PubMed, WikiCS, and ogbn-arxiv we reuse the per-node TAPE explanations released by Wu et al.[5] (generated with GPT-4o-min...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
CATEGORY (or TYPE for Texas) / 3
TOPIC / 2. CATEGORY (or TYPE for Texas) / 3. CONTEXT / 4. KEYWORDS: 5 keywords. For Amazon-Ratings, the initial smoke-test agent wrote a deterministic template generator (scripts/gen_amazon.py) that inserts numerical feature values into one of sixteen product-domain topic templates indexed by(node_id,L 2). The full V3 validation in Appendix F shows this r...
2026
-
[32]
TOPIC: An 88-word isolated page with no hyperlinks, resembling a moderately detailed but disconnected personal write-up. 2. TYPE: student. 3. CONTEXT: A standalone participant whose content is visible but decoupled from the topology. 4. KEYWORDS: moderate bio, no links, disconnected, personal write-up, self-contained actor (fresh Sonnet, node index 346 in...
-
[33]
This is F2 in the main paper (Fig
Threshold behavior inMl (equivalently∆ sig).At fixed( n,d o,d l), sign of∆ concat flips withMl around a threshold depending onn. This is F2 in the main paper (Fig. 2)
-
[34]
∆sig predicts better at point estimate,
Monotone decay in1/√n.At fixed( Ml,d o,d l), the penalty term scales as1/√n, so|∆ concat|should decay monotonically with training-set sizen. This is validated empirically by the train-fraction curves in Appendix J. Both predictions are qualitative: we do not estimateC1,C 2 or∥Σ∥op from data. The role of this analysis is to place the empirical observations...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.