ACE: Self-Evolving LLM Coding Framework via Adversarial Unit Test Generation and Preference Optimization
Pith reviewed 2026-05-22 10:11 UTC · model grok-4.3
The pith
A single LLM improves its own code generation by creating adversarial tests that expose failures, using only execution outcomes for supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ACE shows that a solver-adversary loop inside a single LLM can drive self-evolution in code generation: the model produces both candidate solutions and adversarial tests that are optimized, through execution-derived preferences and Kahneman-Tversky Optimization, to maximize the discovery of failure modes, allowing robust programs to be reinforced without any external correctness labels.
What carries the argument
Solver-adversary architecture in which the same LLM generates candidate code and then produces adversarial unit tests optimized to induce execution failures, with supervision drawn solely from pass/fail outcomes.
If this is right
- Code-generation training loops can run indefinitely using only program execution as the source of preference signals.
- Out-of-distribution coding performance improves more than in-distribution performance, indicating the method strengthens generalization.
- Inference cost remains competitive or lower while accuracy rises, because the same model handles both generation and test creation.
- The approach removes dependence on large annotated solution datasets or separate verifier models.
Where Pith is reading between the lines
- The same execution-only preference loop could be tested on other domains that have cheap simulators, such as simple game agents or symbolic math.
- If the adversary component continues to scale with model size, the framework might reduce the need for human-written test suites in future training pipelines.
- A natural next measurement would be to track how the diversity of discovered failure modes changes across training iterations.
Load-bearing premise
Adversarial unit tests produced by the LLM itself will keep exposing genuine remaining failures rather than mostly confirming that the current code is already correct.
What would settle it
Measure whether the generated adversarial tests still produce high failure rates on successively stronger versions of the model, or whether their failure rate drops to near zero while pass@1 on held-out benchmarks stays flat.
Figures




read the original abstract
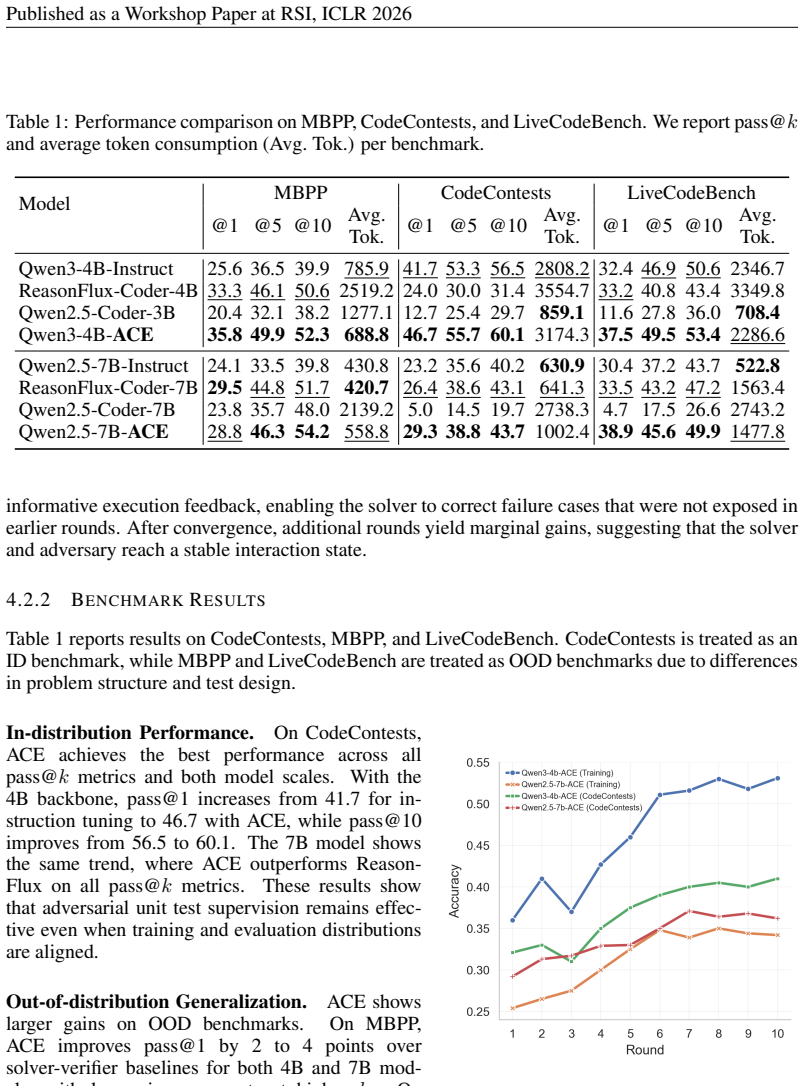
Large Language Models (LLMs) excel at code generation but remain heavily reliant on large-scale annotated solutions and verification-based supervision, which constrains scalability and hinders sustained self-improvement. Recent solver--verifier frameworks exploit program execution as an automatic supervision signal, but their effectiveness degrades as solvers become moderately strong: verifier-generated tests increasingly confirm semantic correctness rather than exposing the remaining failure modes. We propose \textbf{ACE}, a self-evolving code generation framework based on a solver--adversary architecture that prioritizes active failure discovery through execution-centric supervision. A single LLM alternates between generating candidate programs and producing adversarial unit test inputs optimized to induce execution-level failures, such as runtime errors, exceptions, or non-termination. Supervision is derived solely from execution outcomes: robust programs are selected for supervised fine-tuning, while adversarial tests are optimized via Kahneman--Tversky Optimization using execution-derived preferences. Notably, the entire training loop requires no ground-truth code or external reward models. Experiments on CodeContests, MBPP, and LiveCodeBench demonstrate that ACE consistently outperforms strong solver--verifier baselines, achieving 3--7\% absolute gains in pass@1, with larger improvements on out-of-distribution benchmarks, while maintaining competitive or improved inference efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ACE, a self-evolving LLM coding framework using a single model that alternates between generating candidate code solutions and adversarial unit test inputs designed to trigger runtime errors, exceptions, or non-termination. Execution outcomes alone provide supervision: successful programs undergo supervised fine-tuning while preference optimization via Kahneman-Tversky Optimization (KTO) is applied to execution-derived signals. No ground-truth code or external reward models are used. Experiments on CodeContests, MBPP, and LiveCodeBench report 3-7% absolute pass@1 gains over solver-verifier baselines, with larger improvements on out-of-distribution sets and maintained inference efficiency.
Significance. If the central claims hold after verification, ACE would offer a scalable path to self-improvement in code generation by turning execution feedback into an active adversarial loop, addressing the degradation of verifier signals as solvers strengthen. This could reduce dependence on annotated data and external verifiers, with potential implications for autonomous coding agents.
major comments (2)
- [Abstract, §4] Abstract and §4 (Experiments): The central performance claim of consistent 3-7% pass@1 gains (with larger OOD improvements) is presented without reported statistical significance tests, exact hyperparameter choices for the KTO loop, or controls for post-hoc selection of adversarial tests; this information is load-bearing for assessing whether the gains exceed noise or baseline variance.
- [§3] §3 (Method): The assumption that the same LLM acting as adversary will continue to generate tests exposing new failure modes (rather than confirming correctness) as the solver improves via iterative SFT+KTO is not supported by any analysis or ablation; if this assumption fails, execution outcomes supply only weak or self-confirming preference signals, directly undermining the no-ground-truth self-evolution premise.
minor comments (2)
- [§3] Notation for the adversary generation objective and the precise KTO preference construction from execution outcomes (pass/fail, timeout, exception) should be formalized with equations for reproducibility.
- [§4] Figure or table reporting per-benchmark pass@1 with and without the adversarial component would clarify the contribution of the solver-adversary loop.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and outline specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The central performance claim of consistent 3-7% pass@1 gains (with larger OOD improvements) is presented without reported statistical significance tests, exact hyperparameter choices for the KTO loop, or controls for post-hoc selection of adversarial tests; this information is load-bearing for assessing whether the gains exceed noise or baseline variance.
Authors: We agree that statistical significance testing, precise hyperparameter reporting, and explicit controls are essential for validating the reported gains. In the revised manuscript we will add bootstrap confidence intervals and paired t-tests (across 5 random seeds) for all pass@1 improvements in §4 and the appendix. We will also list the complete KTO hyperparameter set (learning rate, β, number of preference pairs per iteration, and early-stopping criterion) used in all experiments. Finally, we will clarify the fixed, non-post-hoc procedure for adversarial test selection (top-k by execution failure rate, with a deterministic tie-breaker) to rule out selection bias. These changes will be incorporated in the next version. revision: yes
-
Referee: [§3] §3 (Method): The assumption that the same LLM acting as adversary will continue to generate tests exposing new failure modes (rather than confirming correctness) as the solver improves via iterative SFT+KTO is not supported by any analysis or ablation; if this assumption fails, execution outcomes supply only weak or self-confirming preference signals, directly undermining the no-ground-truth self-evolution premise.
Authors: We recognize that the continued effectiveness of the adversary is a central assumption and that the current manuscript lacks direct supporting analysis. We will add a new ablation subsection (or appendix) that tracks adversary strength over iterations by measuring (i) the fraction of generated tests that induce runtime errors or non-termination on the current solver and (ii) the diversity of failure modes (via error-type histograms). This will demonstrate that the adversary does not collapse to trivial or confirming tests. The analysis will be performed on the same training trajectories reported in the paper. revision: yes
Circularity Check
No circularity: execution provides independent external labels
full rationale
The described ACE loop derives supervision exclusively from program execution outcomes (runtime errors, exceptions, non-termination) rather than from model-generated signals or fitted parameters. Candidate programs are selected for SFT and preferences for KTO are labeled by whether execution succeeds or fails on the generated tests; these labels are produced by an external interpreter and do not reduce to the LLM's own outputs by construction. No equations, uniqueness theorems, or self-citations are invoked to force the result, and the empirical gains are measured against external benchmarks (CodeContests, MBPP, LiveCodeBench). The framework therefore remains self-contained against independent oracles.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Execution outcomes alone suffice as supervision for both program selection and adversarial test optimization in LLM fine-tuning.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A single LLM alternates between generating candidate programs and producing adversarial unit test inputs optimized to induce execution-level failures... Supervision is derived solely from execution outcomes
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
adversarial tests are optimized via Kahneman–Tversky Optimization using execution-derived preferences
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language 8 Published as a Workshop Paper at RSI, ICLR 2026 models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models.arXiv preprint arXiv:2401.01335,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
KTO: Model Alignment as Prospect Theoretic Optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Uagent: Adversarial co-evolution for targeted bug revelation in unit testing
Yulong Fu and Yingtong Zhang. Uagent: Adversarial co-evolution for targeted bug revelation in unit testing. InProceedings of the 2025 Workshop on Recent Advances in Resilient and Trustworthy MAchine learning-driveN systems, pp. 51–56,
work page 2025
-
[5]
Nam Huynh and Beiyu Lin. Large language models for code generation: A comprehensive survey of challenges, techniques, evaluation, and applications.arXiv preprint arXiv:2503.01245,
-
[6]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Yiyang Jin, Kunzhao Xu, Hang Li, Xueting Han, Yanmin Zhou, Cheng Li, and Jing Bai. Reveal: Self-evolving code agents via iterative generation-verification.arXiv preprint arXiv:2506.11442,
-
[8]
Atgen: Adversarial reinforcement learning for test case generation.arXiv preprint arXiv:2510.14635,
Qingyao Li, Xinyi Dai, Weiwen Liu, Xiangyang Li, Yasheng Wang, Ruiming Tang, Yong Yu, and Weinan Zhang. Atgen: Adversarial reinforcement learning for test case generation.arXiv preprint arXiv:2510.14635,
-
[9]
Zi Lin, Sheng Shen, Jingbo Shang, Jason Weston, and Yixin Nie. Learning to solve and verify: A self-play framework for code and test generation.arXiv preprint arXiv:2502.14948,
-
[10]
Zhihan Liu, Shenao Zhang, Yongfei Liu, Boyi Liu, Yingxiang Yang, and Zhaoran Wang. Dstc: Direct preference learning with only self-generated tests and code to improve code lms.arXiv preprint arXiv:2411.13611,
-
[11]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2404.14387 , year=
9 Published as a Workshop Paper at RSI, ICLR 2026 Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, and Jingren Zhou. A survey on self-evolution of large language models. arXiv preprint arXiv:2404.14387,
-
[13]
Co-evolving llm coder and unit tester via reinforcement learning.arXiv preprint arXiv:2506.03136,
Yinjie Wang, Ling Yang, Ye Tian, Ke Shen, and Mengdi Wang. Co-evolving llm coder and unit tester via reinforcement learning.arXiv preprint arXiv:2506.03136,
-
[14]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Self-rewarding correction for mathematical reasoning.arXiv preprint arXiv:2502.19613,
Wei Xiong, Hanning Zhang, Chenlu Ye, Lichang Chen, Nan Jiang, and Tong Zhang. Self-rewarding correction for mathematical reasoning.arXiv preprint arXiv:2502.19613,
-
[16]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Unless otherwise specified, all hyperparameters are fixed across experiments
A APPENDIX A.1 TRAININGDETAIL We adopt parameter-efficient fine-tuning for both solver and adversary optimization using LoRA. Unless otherwise specified, all hyperparameters are fixed across experiments. LoRA Setup.We apply LoRA to the backbone model with rankr= 64for all fine-tuning stages. We use separate LoRA adapters for the solver and adversary on to...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.