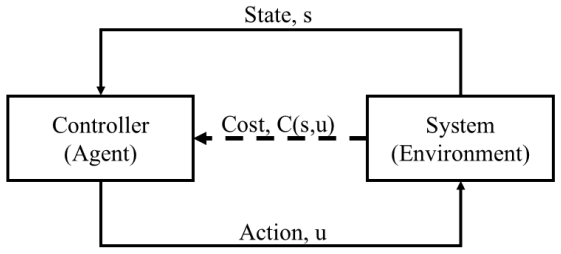
Reinforcement Learning-based Control via Y-wise Affine Neural Networks (YANNs)
Pith reviewed 2026-05-21 22:45 UTC · model grok-4.3
The pith
YANNs initialize RL actor-critic from exact linear MPC solutions and extend them to nonlinear control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
YANNs can exactly represent any piecewise-affine function defined on polytopic subdomains; therefore the explicit multi-parametric solution of a linear OCP and its associated state-action value function can be encoded directly into the actor and critic. Extra layers injected into the YANN architecture allow the networks to represent nonlinear maps that are then trained by direct interaction with the true plant, so the policy and value functions begin as the exact linear OCP solution and evolve into the solution of the nonlinear OCP.
What carries the argument
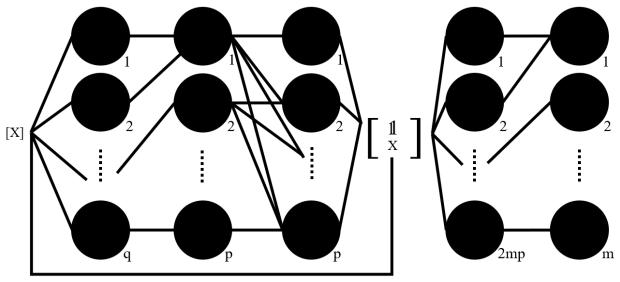
Y-wise Affine Neural Networks (YANNs), which exactly represent known piecewise affine functions of arbitrary input and output dimensions on any number of polytopic subdomains.
If this is right
- The YANN actor begins as the exact optimal policy of the linear OCP and the critic as the exact value function for that OCP.
- Continuous policy improvement guarantees that the final RL policy is at least as good as the linear solution.
- Safety constraints are respected more reliably than with standard deep RL because the initial policy already satisfies them.
- The same YANN architecture can be applied to any system for which an explicit multi-parametric linear MPC solution can be pre-computed.
Where Pith is reading between the lines
- The method may reduce the number of unsafe episodes during early training in safety-critical RL tasks.
- Similar initialization strategies could be tested on other explicit control representations such as hybrid MPC or switched linear systems.
- Stability or robustness certificates might be carried over from the linear solution into the early stages of nonlinear training.
Load-bearing premise
The explicit multi-parametric solutions obtained from an approximated linear model supply an initial policy and value function that are close enough to the true nonlinear system for online training to succeed.
What would settle it
Running YANN-RL and DDPG on the chemical-reactive system and finding that YANN-RL either violates the safety constraints or achieves lower cumulative reward than DDPG would falsify the performance claim.
Figures



read the original abstract
This work presents a novel reinforcement learning (RL) algorithm based on Y-wise Affine Neural Networks (YANNs). YANNs provide an interpretable neural network which can exactly represent known piecewise affine functions of arbitrary input and output dimensions defined on any amount of polytopic subdomains. One representative application of YANNs is to reformulate explicit solutions of multi-parametric linear model predictive control. Built on this, we propose the use of YANNs to initialize RL actor and critic networks, which enables the resulting YANN-RL control algorithm to start with the confidence of linear optimal control. The YANN-actor is initialized by representing the multi-parametric control solutions obtained via offline computation using an approximated linear system model. The YANN-critic represents the explicit form of the state-action value function for the linear system and the reward function as the objective in an optimal control problem (OCP). Additional network layers are injected to extend YANNs for nonlinear expressions, which can be trained online by directly interacting with the true complex nonlinear system. In this way, both the policy and state-value functions exactly represent a linear OCP initially and are able to eventually learn the solution of a general nonlinear OCP. Continuous policy improvement is also implemented to provide heuristic confidence that the linear OCP solution serves as an effective lower bound to the performance of RL policy. The YANN-RL algorithm is demonstrated on a clipped pendulum and a safety-critical chemical-reactive system. Our results show that YANN-RL significantly outperforms the modern RL algorithm using deep deterministic policy gradient, especially when considering safety constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Y-wise Affine Neural Networks (YANNs) capable of exactly representing piecewise affine functions on arbitrary polytopic subdomains. It initializes RL actor and critic networks from explicit multi-parametric solutions of an approximated linear MPC problem, injects additional layers to extend to nonlinear dynamics, and trains online on the true nonlinear plant while using continuous policy improvement for heuristic lower-bound confidence. Demonstrations on a clipped pendulum and safety-critical chemical reactor claim significant outperformance over DDPG, particularly under safety constraints.
Significance. If the empirical results hold, the work offers a principled way to initialize RL policies from linear optimal control solutions, potentially improving safety and interpretability in nonlinear control tasks. The exact PWA representation property of YANNs is a clear technical strength for bridging explicit MPC and data-driven methods.
major comments (2)
- [Abstract and Numerical Examples] Abstract and demonstration sections: the central claim that YANN-RL 'significantly outperforms' DDPG (especially under safety constraints) rests on unverified demonstration; no quantitative metrics, reward curves, success rates, error bars, or tables comparing performance are referenced, making it impossible to assess the magnitude or statistical reliability of the reported gains.
- [Method (initialization and training)] Method sections on initialization and online training: the headline performance advantage depends on the multi-parametric linear solutions serving as an effective initial actor/critic for the true nonlinear system, yet no ablation study, sensitivity analysis to linear approximation quality, or isolation of the initialization contribution versus the YANN architecture and training procedure is provided. This is load-bearing for the claim that the linear OCP solution acts as a reliable lower bound.
minor comments (1)
- The manuscript would benefit from explicit pseudocode or a diagram clarifying the transition from the exact linear YANN representation to the trained nonlinear extension.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the YANN representation property and its potential to bridge explicit MPC with RL. We address each major comment below and will incorporate revisions to strengthen the empirical support and methodological analysis.
read point-by-point responses
-
Referee: [Abstract and Numerical Examples] Abstract and demonstration sections: the central claim that YANN-RL 'significantly outperforms' DDPG (especially under safety constraints) rests on unverified demonstration; no quantitative metrics, reward curves, success rates, error bars, or tables comparing performance are referenced, making it impossible to assess the magnitude or statistical reliability of the reported gains.
Authors: We agree that the abstract would benefit from explicit quantitative references to support the performance claims. In the revised manuscript, we will update the abstract to include key metrics such as average cumulative rewards, safety constraint violation rates, and success rates drawn from the numerical examples on the clipped pendulum and chemical reactor. We will also add a summary comparison table in the demonstration section that includes error bars, standard deviations across multiple runs, and references to the reward curves and success rate plots already present in the figures. This will make the magnitude and reliability of the gains directly verifiable. revision: yes
-
Referee: [Method (initialization and training)] Method sections on initialization and online training: the headline performance advantage depends on the multi-parametric linear solutions serving as an effective initial actor/critic for the true nonlinear system, yet no ablation study, sensitivity analysis to linear approximation quality, or isolation of the initialization contribution versus the YANN architecture and training procedure is provided. This is load-bearing for the claim that the linear OCP solution acts as a reliable lower bound.
Authors: We acknowledge that isolating the initialization contribution is important for substantiating the lower-bound claim. In the revised manuscript, we will add an ablation study comparing YANN-RL performance with the proposed linear multi-parametric initialization against random initialization and standard neural network warm-starts. We will also include a sensitivity analysis that varies the accuracy of the linear system approximation used to compute the explicit MPC solution and reports the resulting impact on final policy performance and safety metrics. These additions will directly address the load-bearing role of the initialization. revision: yes
Circularity Check
No circularity: linear mp-MPC initialization and online nonlinear training are independent of final performance metric
full rationale
The derivation begins with offline computation of explicit multi-parametric solutions for an approximated linear system, represented exactly by YANNs as piecewise-affine functions. These initialize the actor and critic, after which nonlinear layers are added and trained online via interaction with the true nonlinear plant. The final performance comparison to DDPG is obtained through simulation on the clipped pendulum and chemical reactor, not by algebraic reduction to the linear initialization or any fitted parameter. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the chain; the linear solution functions as an external warm-start rather than a constructed outcome of the RL procedure itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption YANNs can exactly represent known piecewise affine functions of arbitrary input and output dimensions defined on any amount of polytopic subdomains
invented entities (1)
-
YANNs
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
YANNs ... exactly represent known piecewise affine functions ... reformulate explicit solutions of multi-parametric linear model predictive control
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
YANN-actor ... initialized by representing the multi-parametric control solutions ... Additional network layers ... to extend YANNs for nonlinear expressions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Reinforcement Learning-based Control via Y-wise Affine Neural Networks: Comparative Case Studies for Chemical Processes
YANN-RL is tested on three PC-Gym chemical process case studies, showing reduced training time and near-NMPC performance compared to PPO, SAC, DDPG, and TD3.
Reference graph
Works this paper leans on
- [1]
-
[2]
J. Shin, T. A. Badgwell, K.-H. Liu, J. H. Lee, Reinforcement Learn- ing – Overview of recent progress and implications for process control, Computers & Chemical Engineering 127 (2019) 282–294
work page 2019
-
[3]
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, D. Hassabis, Human-level control through deep reinforcement learning, Nature 518 (7540) (2015) 529–533
work page 2015
-
[4]
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. Lilli- crap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, D. Hassabis, Mastering the game of Go without human knowledge, Nature 550 (7676) (2017) 354–359
work page 2017
-
[5]
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanc- tot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, D. Hassabis, Mas- tering the game of Go with deep neural networks and tree search, Nature 529 (758...
work page 2016
-
[6]
E. Kaufmann, L. Bauersfeld, A. Loquercio, M. M¨ uller, V. Koltun, D. Scaramuzza, Champion-level drone racing using deep reinforcement learning, Nature 620 (7976) (2023) 982–987
work page 2023
-
[7]
J. Wang, J. Zhao, A virtual entity of the digital twin based on deep re- inforcement learning model for dynamic scheduling process, in: F. Ma- nenti, G. V. Reklaitis (Eds.), Computer Aided Chemical Engineering, Vol. 53 of 34 European Symposium on Computer Aided Process Engi- neering / 15 International Symposium on Process Systems Engineering, Elsevier, 20...
work page 2024
-
[8]
C. D. Hubbs, C. Li, N. V. Sahinidis, I. E. Grossmann, J. M. Wassick, A deep reinforcement learning approach for chemical production schedul- ing, Computers & Chemical Engineering 141 (2020) 106982
work page 2020
-
[9]
A. Braniff, F. You, Y. Tian, Enhanced Reinforcement Learning-driven Process Design via Quantum Machine Learning, in: The 35th European Symposium on Computer Aided Process Engineering, Ghent, Belgium, 2025, pp. 1403–1408
work page 2025
-
[10]
S. Reynoso-Donzelli, L. A. Ricardez-Sandoval, An integrated reinforce- ment learning framework for simultaneous generation, design, and con- trol of chemical process flowsheets, Computers & Chemical Engineering 194 (2025) 108988
work page 2025
-
[11]
P. Petsagkourakis, I. O. Sandoval, E. Bradford, D. Zhang, E. A. del Rio-Chanona, Reinforcement learning for batch bioprocess optimization, Computers & Chemical Engineering 133 (2020) 106649
work page 2020
-
[12]
S. Spielberg, A. Tulsyan, N. P. Lawrence, P. D. Loewen, R. Bhushan Gopaluni, Toward self-driving processes: A deep rein- forcement learning approach to control, AIChE Journal 65 (10) (2019) e16689
work page 2019
-
[13]
R. d. R. Faria, B. D. O. Capron, M. B. de Souza Jr., A. R. Secchi, One-Layer Real-Time Optimization Using Reinforcement Learning: A Review with Guidelines, Processes 11 (1) (2023) 123
work page 2023
- [14]
- [15]
-
[16]
Y. Wang, X. Zhu, Z. Wu, A tutorial review of policy iteration methods in reinforcement learning for nonlinear optimal control, Digital Chemical Engineering 15 (2025) 100231
work page 2025
-
[17]
A. Braniff, S. S. Akundi, Y. Liu, B. Dantas, S. S. Niknezhad, F. Khan, E. N. Pistikopoulos, Y. Tian, Real-time process safety and systems 30 decision-making toward safe and smart chemical manufacturing, Dig- ital Chemical Engineering 15 (2025) 100227
work page 2025
-
[18]
R. Nian, J. Liu, B. Huang, A review On reinforcement learning: In- troduction and applications in industrial process control, Computers & Chemical Engineering 139 (2020) 106886
work page 2020
-
[19]
R. d. R. Faria, B. D. O. Capron, A. R. Secchi, M. B. de Souza, Where Reinforcement Learning Meets Process Control: Review and Guidelines, Processes 10 (11) (2022) 2311
work page 2022
-
[20]
H. Yoo, H. E. Byun, D. Han, J. H. Lee, Reinforcement learning for batch process control: Review and perspectives, Annual Reviews in Control 52 (2021) 108–119
work page 2021
-
[21]
H. Hassanpour, X. Wang, B. Corbett, P. Mhaskar, A practically imple- mentable reinforcement learning-based process controller design, AIChE Journal 70 (1) (2024) e18245
work page 2024
-
[22]
H. Hassanpour, P. Mhaskar, B. Corbett, A practically implementable reinforcement learning control approach by leveraging offset-free model predictive control, Computers & Chemical Engineering 181 (2024) 108511
work page 2024
-
[23]
H. Hassanpour, B. Corbett, P. Mhaskar, A practical reinforcement learn- ing control design for nonlinear systems with input and output con- straints, Computers & Chemical Engineering 201 (2025) 109248
work page 2025
-
[24]
Y. Kim, T. H. Oh, Model-based safe reinforcement learning for non- linear systems under uncertainty with constraints tightening approach, Computers & Chemical Engineering 183 (2024) 108601
work page 2024
-
[25]
Y. Kim, J. W. Kim, Safe model-based reinforcement learning for non- linear optimal control with state and input constraints, AIChE Journal 68 (5) (2022) e17601
work page 2022
-
[26]
Y. Kim, J. M. Lee, Model-based reinforcement learning for nonlinear optimal control with practical asymptotic stability guarantees, AIChE Journal 66 (10) (2020) e16544. 31
work page 2020
-
[27]
F. Berkenkamp, M. Turchetta, A. Schoellig, A. Krause, Safe Model- based Reinforcement Learning with Stability Guarantees, in: Advances in Neural Information Processing Systems, Vol. 30, Curran Associates, Inc., 2017
work page 2017
- [28]
-
[29]
M. A. Chowdhury, S. S. S. Al-Wahaibi, Q. Lu, Entropy-maximizing TD3-based reinforcement learning for adaptive PID control of dynamical systems, Computers & Chemical Engineering 178 (2023) 108393
work page 2023
- [30]
- [31]
-
[32]
N. P. Lawrence, M. G. Forbes, P. D. Loewen, D. G. McClement, J. U. Backstr¨ om, R. B. Gopaluni, Deep reinforcement learning with shallow controllers: An experimental application to PID tuning, Control Engi- neering Practice 121 (2022) 105046
work page 2022
-
[33]
S. Gros, M. Zanon, Data-Driven Economic NMPC Using Reinforcement Learning, IEEE Transactions on Automatic Control 65 (2) (2020) 636– 648
work page 2020
-
[34]
K. Alhazmi, F. Albalawi, S. M. Sarathy, A reinforcement learning-based economic model predictive control framework for autonomous operation of chemical reactors, Chemical Engineering Journal 428 (2022) 130993
work page 2022
-
[35]
AC4MPC: Actor-critic reinforcement learning for nonlinear model predictive control,
R. Reiter, A. Ghezzi, K. Baumg¨ artner, J. Hoffmann, R. D. McAllister, M. Diehl, AC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control (Jun. 2024). arXiv:2406.03995. 32
-
[36]
E. Hedrick, K. Hedrick, D. Bhattacharyya, S. E. Zitney, B. Omell, Rein- forcement learning for online adaptation of model predictive controllers: Application to a selective catalytic reduction unit, Computers & Chem- ical Engineering 160 (2022) 107727
work page 2022
-
[37]
J. W. Kim, B. J. Park, T. H. Oh, J. M. Lee, Model-based reinforcement learning and predictive control for two-stage optimal control of fed-batch bioreactor, Computers & Chemical Engineering 154 (2021) 107465
work page 2021
- [38]
-
[39]
Y. Chow, O. Nachum, E. Duenez-Guzman, M. Ghavamzadeh, A Lyapunov-based Approach to Safe Reinforcement Learning, in: Ad- vances in Neural Information Processing Systems, Vol. 31, Curran As- sociates, Inc., 2018
work page 2018
-
[40]
X. Zhu, Y. Wang, Z. Wu, Reinforcement learning for optimal control of stochastic nonlinear systems, AIChE Journal 71 (7) (2025) e18840
work page 2025
-
[41]
Y. Wang, Z. Wu, Control Lyapunov-barrier function-based safe rein- forcement learning for nonlinear optimal control, AIChE Journal 70 (3) (2024) e18306
work page 2024
- [42]
-
[43]
B. Thananjeyan, A. Balakrishna, S. Nair, M. Luo, K. Srinivasan, M. Hwang, J. E. Gonzalez, J. Ibarz, C. Finn, K. Goldberg, Recovery RL: Safe Reinforcement Learning With Learned Recovery Zones, IEEE Robotics and Automation Letters 6 (3) (2021) 4915–4922
work page 2021
- [44]
-
[45]
Y. Wang, M. Xiao, Z. Wu, Safe Transfer-Reinforcement-Learning-Based Optimal Control of Nonlinear Systems, IEEE Transactions on Cyber- netics 54 (12) (2024) 7272–7284. 33
work page 2024
-
[46]
S. Bo, B. T. Agyeman, X. Yin, J. Liu, Control invariant set enhanced safe reinforcement learning: Improved sampling efficiency, guaranteed stability and robustness, Computers & Chemical Engineering 179 (2023) 108413
work page 2023
-
[47]
M. Mowbray, P. Petsagkourakis, E. A. del Rio-Chanona, D. Zhang, Safe chance constrained reinforcement learning for batch process con- trol, Computers & Chemical Engineering 157 (2022) 107630
work page 2022
- [48]
-
[49]
A. Braniff, Y. Tian, YANNs: Y-wise Affine Neural Networks for Exact and Efficient Representations of Piecewise Linear Functions (May 2025). arXiv:2505.07054
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
E. N. Pistikopoulos, N. A. Diangelakis, R. Oberdieck, Multi-Parametric Optimization and Control, John Wiley & Sons, Ltd, 2020
work page 2020
- [51]
-
[52]
S. L. Brunton, J. N. Kutz, Reinforcement Learning, Cambridge Univer- sity Press, 2022, p. 419–448
work page 2022
-
[53]
V. S. Devarakonda, W. Sun, X. Tang, Y. Tian, Recent Advances in Reinforcement Learning for Chemical Process Control, Processes 13 (6) (2025) 1791
work page 2025
-
[54]
Y. Tian, I. Pappas, B. Burnak, J. Katz, E. N. Pistikopoulos, Simulta- neous design & control of a reactive distillation system – A paramet- ric optimization & control approach, Chemical Engineering Science 230 (2021) 116232
work page 2021
-
[55]
D. Kenefake, E. N. Pistikopoulos, PPOPT – Multiparametric solver for explicit MPC, in: Computer Aided Chemical Engineering, Vol. 51, Elsevier, 2022, pp. 1273–1278
work page 2022
-
[56]
S. Bradtke, Reinforcement Learning Applied to Linear Quadratic Regu- lation, in: Advances in Neural Information Processing Systems, Vol. 5, Morgan-Kaufmann, 1992. 34
work page 1992
-
[57]
K. M. Patel, A practical Reinforcement Learning implementation ap- proach for continuous process control, Computers & Chemical Engi- neering 174 (2023) 108232
work page 2023
-
[58]
C. Panjapornpon, P. Chinchalongporn, S. Bardeeniz, R. Makkayatorn, W. Wongpunnawat, Reinforcement Learning Control with Deep Deter- ministic Policy Gradient Algorithm for Multivariable pH Process, Pro- cesses 10 (12) (2022) 2514
work page 2022
-
[59]
R. Siraskar, Reinforcement learning for control of valves, Machine Learn- ing with Applications 4 (2021) 100030
work page 2021
-
[60]
M. S. F. Bangi, J. S.-I. Kwon, Deep reinforcement learning control of hydraulic fracturing, Computers & Chemical Engineering 154 (2021) 107489
work page 2021
-
[61]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Sil- ver, D. Wierstra, Continuous control with deep reinforcement learning (Jul. 2019). arXiv:1509.02971
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [62]
-
[63]
Trust Region Policy Optimization
J. Schulman, S. Levine, P. Moritz, M. I. Jordan, P. Abbeel, Trust Region Policy Optimization (Apr. 2017). arXiv:1502.05477
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[64]
M. Pirotta, M. Restelli, A. Pecorino, D. Calandriello, Safe Policy Itera- tion, in: Proceedings of the 30th International Conference on Machine Learning, PMLR, 2013, pp. 307–315
work page 2013
-
[65]
B. Scherrer, M. Geist, Local Policy Search in a Convex Space and Con- servative Policy Iteration as Boosted Policy Search, in: T. Calders, F. Esposito, E. H¨ ullermeier, R. Meo (Eds.), Machine Learning and Knowledge Discovery in Databases, Springer, Berlin, Heidelberg, 2014, pp. 35–50
work page 2014
-
[66]
Safe Exploration in Continuous Action Spaces
G. Dalal, K. Dvijotham, M. Vecerik, T. Hester, C. Paduraru, Y. Tassa, Safe Exploration in Continuous Action Spaces (Jan. 2018). arXiv:1801.08757. 35
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[67]
Stochastic Variance-Reduced Policy Gradient
M. Papini, D. Binaghi, G. Canonaco, M. Pirotta, M. Restelli, Stochastic Variance-Reduced Policy Gradient (Jun. 2018). arXiv:1806.05618
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [68]
-
[69]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov, Proximal Policy Optimization Algorithms (Aug. 2017). arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[70]
G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, W. Zaremba, Openai gym, arXiv preprint arXiv:1606.01540 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[71]
A. Braniff, Y. Tian, A hierarchical multi-parametric programming ap- proach for dynamic risk-based model predictive quality control, Control Engineering Practice 152 (2024) 106062
work page 2024
-
[72]
M. Ali, X. Cai, F. I. Khan, E. N. Pistikopoulos, Y. Tian, Dynamic risk- based process design and operational optimization via multi-parametric programming, Digital Chemical Engineering 7 (2023) 100096. 36
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.