Support-Constrained RL Enables Real-World Policy Improvement without Real-World Experience
Pith reviewed 2026-06-29 01:54 UTC · model grok-4.3
The pith
Support-constrained RL in simulation improves real-world robot policies without further real-world experience.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
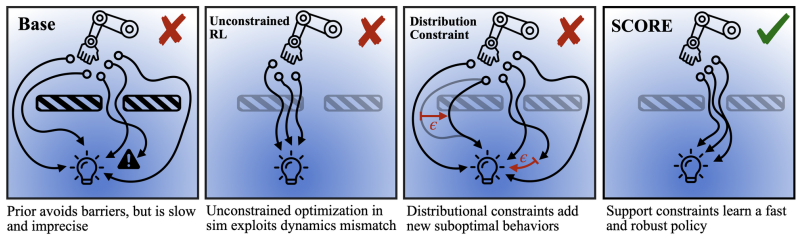
By constraining reinforcement learning in simulation to the support of a generative policy pretrained on real data, implemented through flow steering, the optimized policies transfer to hardware and deliver higher success rates plus faster task completion across eight real-world dexterous manipulation tasks, all without real-world RL or changes to the base policy.
What carries the argument
The support constraint via flow steering, which restricts actions during simulated RL to the distribution of the real-data generative policy.
If this is right
- Policy improvement after initial real data collection can occur entirely in simulation.
- The process works with sparse rewards and requires no distillation step.
- The base policy stays unchanged while a separate improved policy is learned.
- Simulation becomes usable for safe real-to-sim-to-real transfer on manipulation tasks when actions are limited to the real policy support.
Where Pith is reading between the lines
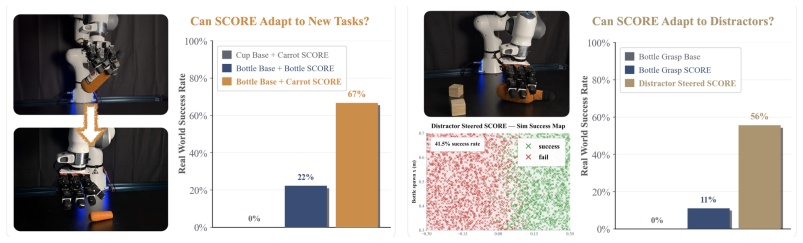
- The same support constraint might apply to other robot skills where simulation gaps cause problems, such as assembly or locomotion.
- The method could lower the total real-world data needed across repeated policy refinements.
- Combining the constraint with different base policy training approaches might show how broadly the gains hold.
Load-bearing premise
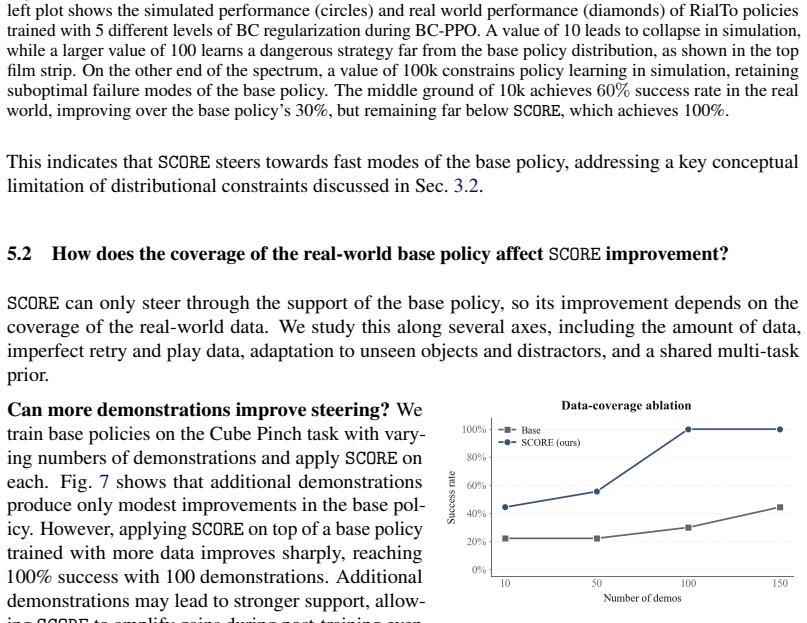
That actions kept inside the real policy support will avoid exploiting simulation inaccuracies enough to block transfer while still allowing useful policy gains.
What would settle it
Running unconstrained RL in simulation on the same tasks and finding that its policies achieve comparable or higher real-world success rates than the constrained SCORE versions would show the support constraint is not required.
Figures



















read the original abstract
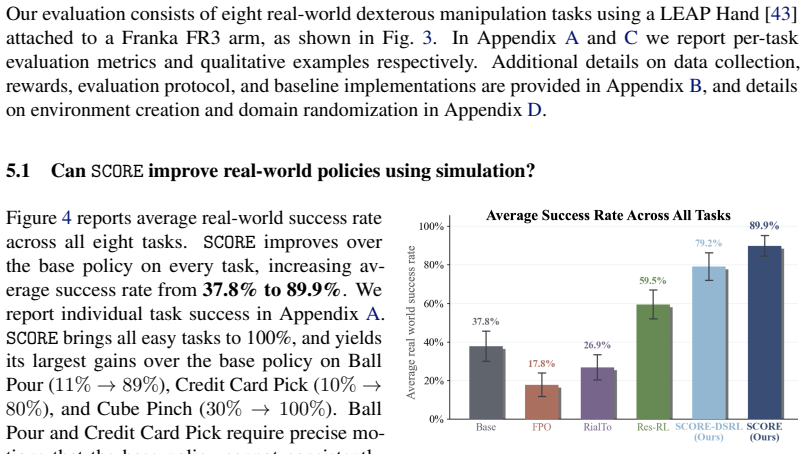
Robots trained on real world data tend to be imprecise, slow, and brittle to perturbations. Improving these policies with reinforcement learning (RL) is an appealing alternative, but this process often requires expensive training in the real world. Performing policy improvement in simulation instead provides a far cheaper alternative, but unconstrained RL in simulation can exploit contact and dynamics mismatches, resulting in unsafe behaviors that do not transfer to hardware. Common forms of regularization can furthermore limit improvement by overconstraining to an imperfect behavior prior. In this work, we propose Support-Constrained Off-Domain REinforcement (SCORE), a real-to-sim-to-real framework that constrains RL in simulation to the support of a generative policy pretrained on real data. We instantiate this constraint through flow steering, restricting SCORE to actions the base policy can already produce, which ensures transferable behaviors while maximizing policy improvement. Improving a policy with SCORE requires minimal effort: it learns from sparse rewards, avoids distillation, and leaves the base policy untouched. Across eight real-world dexterous multi-fingered robotic manipulation tasks, SCORE improves average success rate from 37.8% to 89.9%, compared to 59.5% for the best baseline, and reaches success in 36.8% fewer steps than the base policy. Ultimately, through extensive experiments and ablations, we show that simulation can substantially improve real-world manipulation policies when policy optimization is appropriately constrained, introducing a new paradigm for real-to-sim-to-real policy improvement. Videos and code are available at https://weirdlabuw.github.io/score/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Support-Constrained Off-Domain REinforcement (SCORE), a real-to-sim-to-real framework that performs RL in simulation while constraining actions via flow steering to the support of a generative policy pretrained on real data. This is claimed to enable substantial policy improvement on real hardware without real-world RL experience, without distillation, and without altering the base policy. The central empirical result is that across eight real-world dexterous multi-fingered manipulation tasks, SCORE raises average success rate from 37.8% (base policy) to 89.9%, outperforming the best baseline at 59.5%, while also reaching success in 36.8% fewer steps; the work states that extensive experiments and ablations support the approach.
Significance. If the reported results and ablations hold, the work is significant for robotics because it offers a concrete, low-effort method to leverage simulation for real policy improvement while mitigating sim-reality exploitation. The provision of code and videos is a positive factor for reproducibility and verification of the claimed gains.
minor comments (2)
- [Abstract] Abstract: the quantitative claims (e.g., 89.9% success, 36.8% fewer steps) would be strengthened by a brief indication of trial counts, error bars, or statistical testing even at the abstract level.
- The manuscript states that the base policy is left untouched and only sparse rewards are used; a minor clarification on how the final deployed policy is obtained (e.g., whether it is the improved sim policy or a combination) would aid clarity.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the work, recognition of its potential significance for robotics, and recommendation for minor revision. We are pleased that the reproducibility elements (code and videos) were noted favorably.
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical real-to-sim-to-real RL method (SCORE) that constrains simulation rollouts to the support of a real-data generative policy via flow steering. All load-bearing claims consist of reported success-rate deltas and step-count reductions measured on eight physical tasks; these rest on external experimental outcomes rather than any derivation, fitted parameter, or self-citation that reduces the result to its own inputs by construction. No equations, ansatzes, or uniqueness theorems appear in the provided text that would trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
E. Aljalbout, J. Xing, A. Romero, I. Akinola, C. R. Garrett, E. Heiden, A. Gupta, T. Hermans, Y . Narang, D. Fox, D. Scaramuzza, and F. Ramos. The reality gap in robotics: Challenges, solutions, and best practices, 2025. URLhttps://arxiv.org/abs/2510.20808
- [3]
-
[4]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models, 2020. URL https: //arxiv.org/abs/2006.11239
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion, 2024. URL https://arxiv.org/ abs/2303.04137
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [6]
-
[7]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
A. Z. Ren, J. Lidard, L. L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization, 2024. URL https://arxiv.org/ abs/2409.00588
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
D. McAllister, S. Ge, B. Yi, C. M. Kim, E. Weber, H. Choi, H. Feng, and A. Kanazawa. Flow matching policy gradients, 2025. URLhttps://arxiv.org/abs/2507.21053
-
[10]
S. Park, Q. Li, and S. Levine. Flow q-learning, 2025. URL https://arxiv.org/abs/2502. 02538
2025
-
[11]
Steering Your Diffusion Policy with Latent Space Reinforcement Learning
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning, 2025. URL https://arxiv.org/abs/2506.15799
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
M. M. Hong, J. Zhang, A. Nagabandi, and A. Gupta. Tmrl: Diffusion timestep-modulated pretraining enables exploration for efficient policy finetuning, 2026. URL https://arxiv. org/abs/2605.12236. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [14]
- [15]
- [16]
-
[17]
Kumar, Z
A. Kumar, Z. Fu, D. Pathak, and J. Malik. Rma: Rapid motor adaptation for legged robots,
-
[18]
URLhttps://arxiv.org/abs/2107.04034
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
- [20]
- [21]
-
[22]
Qin, Y .-H
Y . Qin, Y .-H. Wu, S. Liu, H. Jiang, R. Yang, Y . Fu, and X. Wang. Dexmv: Imitation learning for dexterous manipulation from human videos, 2022. URL https://arxiv.org/abs/2108. 05877
2022
- [23]
- [24]
-
[25]
Z. Xu, R. Gong, M. V . Minniti, A. S. Gundogdu, E. Rosen, K. Sivakumar, R. Yan, Z. Wang, D. Deng, P. Stone, X. Zhang, and K. Schmeckpeper. Expertgen: Scalable sim-to-real expert policy learning from imperfect behavior priors, 2026. URL https://arxiv.org/abs/2603. 15956
2026
-
[26]
B. Eysenbach, S. Asawa, S. Chaudhari, S. Levine, and R. Salakhutdinov. Off-dynamics reinforcement learning: Training for transfer with domain classifiers, 2021. URL https: //arxiv.org/abs/2006.13916
-
[27]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics, 40(4):1–20, July 2021. ISSN 1557-7368. doi:10.1145/3450626.3459670. URL http://dx.doi.org/10. 1145/3450626.3459670
- [28]
-
[29]
H. Niu, S. Sharma, Y . Qiu, M. Li, G. Zhou, J. HU, and X. Zhan. When to trust your simulator: Dynamics-aware hybrid offline-and-online reinforcement learning. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors,Advances in Neural Information Processing Systems, 2022. URLhttps://openreview.net/forum?id=zXE8iFOZKw. 12
2022
-
[30]
Y . Wu, G. Tucker, and O. Nachum. Behavior regularized offline reinforcement learning, 2019. URLhttps://arxiv.org/abs/1911.11361
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [31]
-
[32]
Singh, A
A. Singh, A. Kumar, Q. Vuong, Y . Chebotar, and S. Levine. Offline rl with realistic datasets: Heteroskedasticity and support constraints, 2022. URL https://arxiv.org/abs/2211. 01052
2022
- [33]
- [34]
-
[35]
Concrete Problems in AI Safety
D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané. Concrete problems in ai safety.arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [36]
-
[37]
J. Tan, T. Zhang, E. Coumans, A. Iscen, Y . Bai, D. Hafner, S. Bohez, and V . Vanhoucke. Sim-to-real: Learning agile locomotion for quadruped robots. InRobotics: Science and Systems, 2018
2018
-
[38]
Z. Wu, W. Lian, V . V . Unhelkar, M. Tomizuka, and S. Schaal. Learning dense rewards for contact-rich manipulation tasks. In2021 IEEE International Conference on Robotics and Automation (ICRA), 2021
2021
- [39]
- [40]
-
[41]
Generative Adversarial Imitation Learning
J. Ho and S. Ermon. Generative adversarial imitation learning, 2016. URL https://arxiv. org/abs/1606.03476
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[42]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [44]
-
[45]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Y . Lin, A. S. Wang, G. Sutanto, A. Rai, and F. Meier. Polymetis. https:// facebookresearch.github.io/fairo/polymetis/, 2021
2021
-
[47]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation, 2017. URLhttps://arxiv.org/abs/1612.00593
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
A. Jain, M. Zhang, K. Arora, W. Chen, M. Torne, M. Z. Irshad, S. Zakharov, Y . Wang, S. Levine, C. Finn, W.-C. Ma, D. Shah, A. Gupta, and K. Pertsch. Polaris: Scalable real-to-sim evaluations for generalist robot policies, 2025. URLhttps://arxiv.org/abs/2512.16881. 14 Appendix Table of Contents A Per-Task Performance 15 B Experiment Details 17 B.1 Hardwar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.