Co-occurring associated retained concepts in Diffusion Unlearning
Pith reviewed 2026-06-26 00:49 UTC · model grok-4.3
The pith
ReCARE erases only target concepts in diffusion models by constructing and using a CARE-set of benign co-occurring tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReCARE automatically constructs the CARE-set, a curated vocabulary of benign co-occurring tokens extracted from target images, and leverages this vocabulary during training for stable unlearning that safeguards CARE while erasing only the target concept.
What carries the argument
The CARE-set, a vocabulary of benign co-occurring tokens extracted from target images, used to guide training so that only the target concept is removed.
Load-bearing premise
The automatically constructed CARE-set from target images reliably identifies only benign co-occurring concepts that should be preserved without introducing new biases or missing critical associations.
What would settle it
Running ReCARE on a new target concept such as violence and measuring whether the CARE score on held-out co-occurring tokens drops below the scores achieved by existing unlearning baselines.
Figures







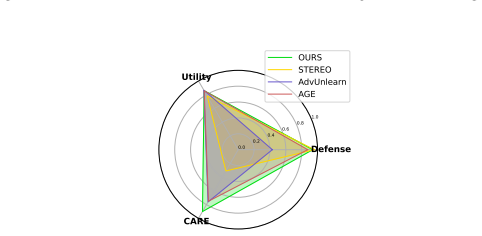



read the original abstract
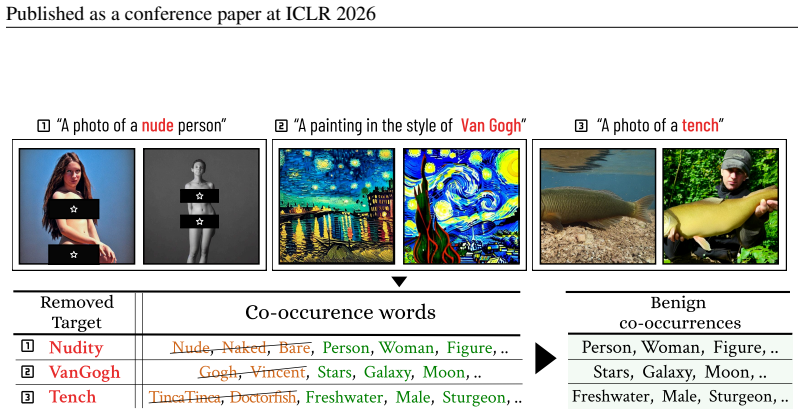
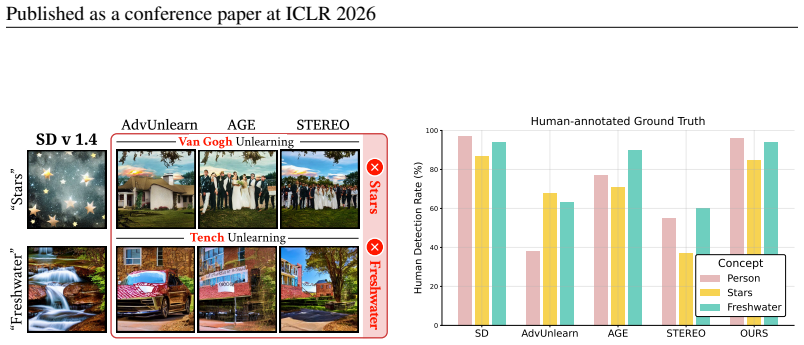
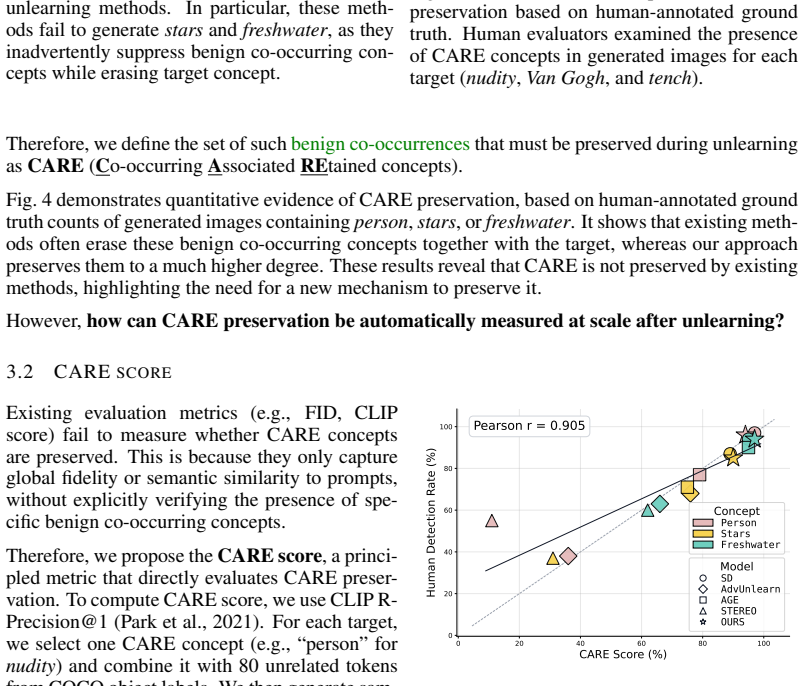
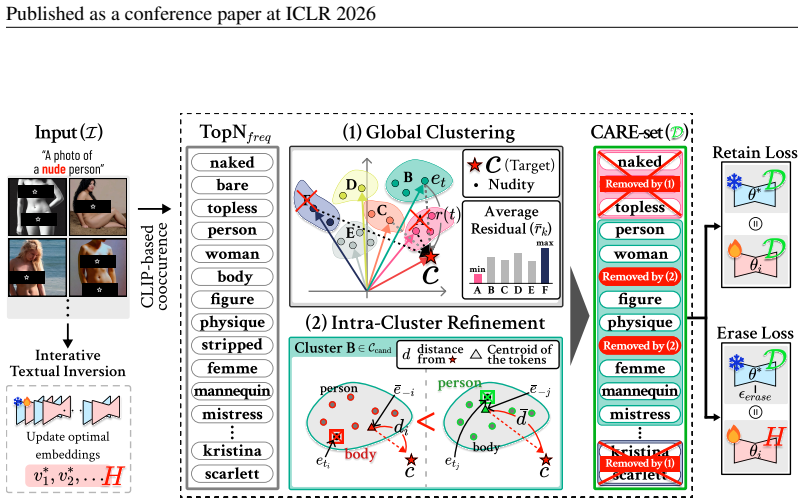
Unlearning has emerged as a key technique to mitigate harmful content generation in diffusion models. However, existing methods often remove not only the target concept, but also benign co-occurring concepts. As illustrated in Fig.1, unlearning nudity can unintentionally suppress the concept of person, preventing a model from generating images with person. We define these undesirably suppressed co-occurring concepts that must be preserved CARE (Co-occurring Associated REtained concepts). Then, we introduce the CARE score, a general metric that directly quantifies their preservation across unlearning tasks. With this foundation, we propose ReCARE (Robust erasure for CARE), a framework that explicitly safeguards CARE while erasing only the target concept. ReCARE automatically constructs the CARE-set, a curated vocabulary of benign co-occurring tokens extracted from target images, and leverages this vocabulary during training for stable unlearning. Extensive experiments across various target concepts (Nudity, Van Gogh style, and Tench object) demonstrate that ReCARE achieves overall state-of-the-art performance in balancing robust concept erasure, overall utility, and CARE preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines CARE (Co-occurring Associated REtained concepts) as benign co-occurring concepts that unlearning methods should preserve rather than suppress. It introduces the CARE score as a metric to quantify preservation of these concepts and proposes ReCARE, a framework that automatically constructs a CARE-set vocabulary of benign co-occurring tokens from target images and uses it during training to erase only the target concept. Experiments on three targets (Nudity, Van Gogh style, Tench object) claim state-of-the-art performance balancing robust concept erasure, overall utility, and CARE preservation.
Significance. If the CARE-set construction proves reliable and the experimental comparisons are rigorous, the work would usefully highlight and mitigate an under-addressed side-effect of diffusion unlearning. The CARE score offers a concrete, general-purpose evaluation tool that could be adopted by other methods. The automatic extraction approach is novel but its validity is central to all downstream claims.
major comments (2)
- [Abstract / Method] Abstract and Method (CARE-set construction): The central SOTA claim rests on the automatically extracted CARE-set containing only concepts that should be retained. No validation (human labeling of associations, sensitivity analysis on extraction rules, or completeness checks) is described, making both the CARE score and reported superiority unreliable if the set includes concepts that ought to be erased or omits critical ones.
- [Abstract] Abstract: The state-of-the-art claim on three concepts provides no details on baselines, exact metrics, statistical significance testing, or potential post-hoc selection of results, preventing verification of the balancing performance.
minor comments (1)
- [Introduction / Fig. 1] Fig. 1 is referenced but its caption and the surrounding text could more explicitly link the illustrated failure mode to the quantitative CARE score.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the presentation of the CARE-set construction and the abstract claims.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and Method (CARE-set construction): The central SOTA claim rests on the automatically extracted CARE-set containing only concepts that should be retained. No validation (human labeling of associations, sensitivity analysis on extraction rules, or completeness checks) is described, making both the CARE score and reported superiority unreliable if the set includes concepts that ought to be erased or omits critical ones.
Authors: We agree that explicit validation of the CARE-set is important for reliability. The current manuscript describes the automatic extraction as selecting tokens that co-occur with the target concept in the input images (Section 3.2), with the assumption that these are benign co-occurring concepts to be retained. However, no human validation, sensitivity analysis on extraction thresholds, or completeness checks are reported. In the revision we will add (i) a detailed description of the extraction rules and hyperparameters, (ii) sensitivity analysis varying vocabulary size and co-occurrence thresholds, and (iii) a small-scale human study confirming that extracted tokens are indeed benign and should be preserved for the three evaluated targets. revision: yes
-
Referee: [Abstract] Abstract: The state-of-the-art claim on three concepts provides no details on baselines, exact metrics, statistical significance testing, or potential post-hoc selection of results, preventing verification of the balancing performance.
Authors: The abstract is intentionally concise; the full experimental section (Section 4) reports the baselines (ESD, UCE, FMN, etc.), exact metrics (erasure success rate, FID on MS-COCO, CARE score), and results across the three targets. Statistical significance is assessed via multiple random seeds and reported with standard deviations, but these details are not summarized in the abstract. We will revise the abstract to include the key quantitative improvements and a brief statement on the evaluation protocol, while retaining the overall length constraint. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines CARE concepts and the CARE score as new constructs, builds the CARE-set automatically as an explicit component of the ReCARE method, and supports its SOTA claim via empirical experiments across multiple target concepts (Nudity, Van Gogh, Tench) that compare erasure, utility, and preservation metrics. No equation, prediction, or central result reduces by construction to a fitted parameter or self-referential input; the performance assertions rest on external comparisons using the introduced metric rather than tautological re-labeling of inputs. The assumption that the extracted CARE-set contains only benign concepts is a correctness/validity concern, not a circularity reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Unlearning-Aware Minimization , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[3]
Neural computation , volume=
A fast learning algorithm for deep belief nets , author=. Neural computation , volume=. 2006 , publisher=
2006
-
[4]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[5]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Erasing concepts from diffusion models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[6]
European Conference on Computer Vision , pages=
Reliable and efficient concept erasure of text-to-image diffusion models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[7]
Advances in neural information processing systems , volume=
Defensive unlearning with adversarial training for robust concept erasure in diffusion models , author=. Advances in neural information processing systems , volume=
-
[8]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Stereo: A two-stage framework for adversarially robust concept erasing from text-to-image diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[9]
arXiv preprint arXiv:2501.18950 , year=
Fantastic targets for concept erasure in diffusion models and where to find them , author=. arXiv preprint arXiv:2501.18950 , year=
-
[10]
2021 IEEE symposium on security and privacy (SP) , pages=
Machine unlearning , author=. 2021 IEEE symposium on security and privacy (SP) , pages=. 2021 , organization=
2021
-
[11]
Advances in neural information processing systems , volume=
Making ai forget you: Data deletion in machine learning , author=. Advances in neural information processing systems , volume=
-
[12]
arXiv preprint arXiv:2210.04610 , year=
Red-teaming the stable diffusion safety filter , author=. arXiv preprint arXiv:2210.04610 , year=
-
[13]
arXiv preprint arXiv:2502.08011 , year=
Training-free safe denoisers for safe use of diffusion models , author=. arXiv preprint arXiv:2502.08011 , year=
-
[14]
arXiv preprint arXiv:2410.12761 , year=
Safree: Training-free and adaptive guard for safe text-to-image and video generation , author=. arXiv preprint arXiv:2410.12761 , year=
-
[15]
Proceedings of the Fifteenth ACM Conference on Data and Application Security and Privacy , pages=
Espresso: Robust concept filtering in text-to-image models , author=. Proceedings of the Fifteenth ACM Conference on Data and Application Security and Privacy , pages=
-
[16]
Advances in neural information processing systems , volume=
Laion-5b: An open large-scale dataset for training next generation image-text models , author=. Advances in neural information processing systems , volume=
-
[17]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Comclip: Training-free compositional image and text matching , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[18]
Journal of machine learning research , volume=
Visualizing data using t-SNE , author=. Journal of machine learning research , volume=
-
[19]
for now , author=
To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images... for now , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[20]
arXiv preprint arXiv:2301.00704 , year=
Muse: Text-to-image generation via masked generative transformers , author=. arXiv preprint arXiv:2301.00704 , year=
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
arXiv preprint arXiv:2110.01963 , year=
Multimodal datasets: misogyny, pornography, and malignant stereotypes , author=. arXiv preprint arXiv:2110.01963 , year=
-
[23]
Advances in neural information processing systems , volume=
Pick-a-pic: An open dataset of user preferences for text-to-image generation , author=. Advances in neural information processing systems , volume=
-
[24]
European Conference on Computer Vision , pages=
Is retain set all you need in machine unlearning? restoring performance of unlearned models with out-of-distribution images , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[25]
arXiv preprint arXiv:2502.15082 , year=
Upcore: Utility-preserving coreset selection for balanced unlearning , author=. arXiv preprint arXiv:2502.15082 , year=
-
[26]
arXiv preprint arXiv:2504.10185 , year=
Llm unlearning reveals a stronger-than-expected coreset effect in current benchmarks , author=. arXiv preprint arXiv:2504.10185 , year=
-
[27]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Unlearning concepts in diffusion model via concept domain correction and concept preserving gradient , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[28]
2015 IEEE symposium on security and privacy , pages=
Towards making systems forget with machine unlearning , author=. 2015 IEEE symposium on security and privacy , pages=. 2015 , organization=
2015
-
[29]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[30]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Unified concept editing in diffusion models , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mace: Mass concept erasure in diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Forget-me-not: Learning to forget in text-to-image diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[34]
arXiv preprint arXiv:2310.10012 , year=
Ring-a-bell! how reliable are concept removal methods for diffusion models? , author=. arXiv preprint arXiv:2310.10012 , year=
-
[35]
arXiv preprint arXiv:2308.01508 , year=
Circumventing concept erasure methods for text-to-image generative models , author=. arXiv preprint arXiv:2308.01508 , year=
-
[36]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Clipscore: A reference-free evaluation metric for image captioning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[37]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[38]
Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation , author=. arXiv preprint arXiv:2310.12508 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2401.05779 , year=
Erasediff: Erasing data influence in diffusion models , author=. arXiv preprint arXiv:2401.05779 , year=
-
[40]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
You only look once: Unified, real-time object detection , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
2019 , publisher=
Nudenet: Neural nets for nudity classification, detection and selective censoring , author=. 2019 , publisher=
2019
-
[43]
arXiv preprint arXiv:2006.03677 , year=
Visual transformers: Token-based image representation and processing for computer vision , author=. arXiv preprint arXiv:2006.03677 , year=
-
[44]
Large-scale Classification of Fine-Art Paintings: Learning The Right Metric on The Right Feature
Large-scale classification of fine-art paintings: Learning the right metric on the right feature , author=. arXiv preprint arXiv:1505.00855 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1) , year=
Benchmark for compositional text-to-image synthesis , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1) , year=
-
[46]
Advances in Neural Information Processing Systems , volume=
Selective amnesia: A continual learning approach to forgetting in deep generative models , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[48]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[49]
The Thirteenth International Conference on Learning Representations , year=
Learning LLM-as-a-judge for preference alignment , author=. The Thirteenth International Conference on Learning Representations , year=
-
[50]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Improving automatic vqa evaluation using large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[52]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
FiVE-Bench: A Fine-grained Video Editing Benchmark for Evaluating Emerging Diffusion and Rectified Flow Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[53]
Advances in Neural Information Processing Systems , volume=
FiVA: Fine-grained visual attribute dataset for text-to-image diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Meta-rewarding language models: Self-improving alignment with llm-as-a-meta-judge , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[55]
Not Every Time and Frequency Need to Be Forgotten in Diffusion Unlearning
Data Unlearning Beyond Uniform Forgetting via Diffusion Time and Frequency Selection , author=. arXiv preprint arXiv:2510.17917 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.