Beyond Semantics: Modeling Factual and Affective Perceptual Experiences from Vision-Language Data
Pith reviewed 2026-06-28 11:17 UTC · model grok-4.3
The pith
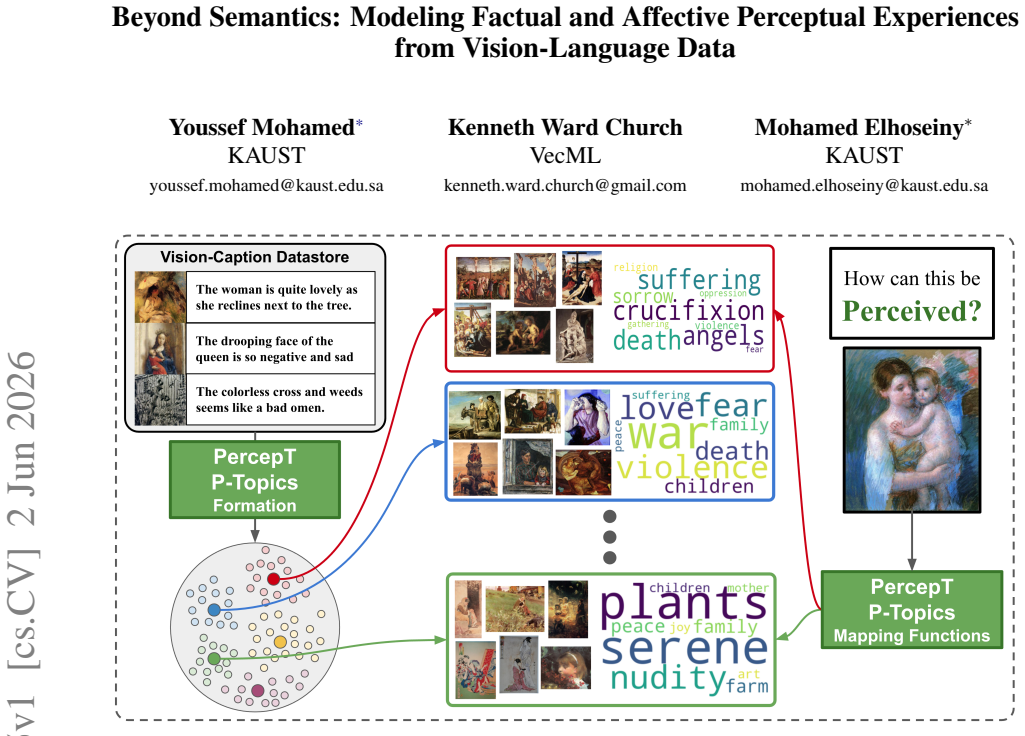
PercepT discovers visual-textual clusters that combine factual content with affective perception experiences and maps new images to those clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
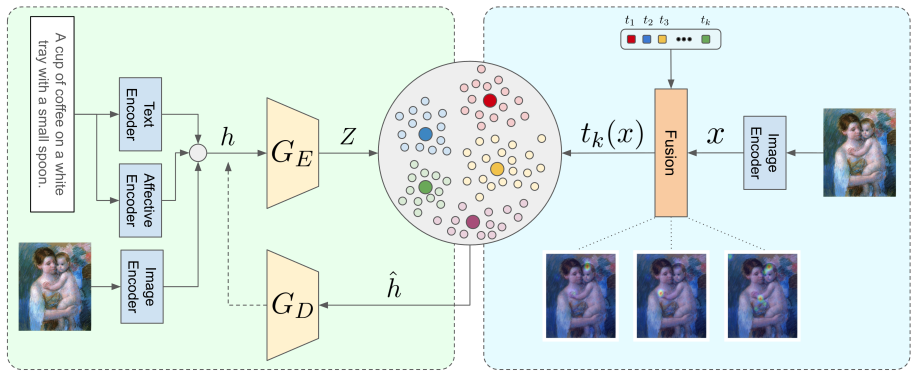
PercepT discovers P-Topics as visual-textual clusters through an unsupervised objective in its formation stage that dynamically selects the number of clusters, then learns P-Topic mapping functions via attention pooling in the mapping stage to associate images with their corresponding clusters.
What carries the argument
PercepT, a two-stage architecture whose formation stage produces unsupervised visual-textual clusters and whose mapping stage applies attention pooling to assign images to those clusters.
If this is right
- Images can be grouped and retrieved according to combined factual and affective criteria rather than semantics alone.
- The number of perception topics can adjust automatically to the richness of any given vision-language collection.
- Mapping functions learned via attention pooling allow new images to be placed into existing perception experiences without retraining the clusters.
- Human judgments confirm that the clusters reflect semantically coherent perception experiences rather than artifacts of the training objective.
Where Pith is reading between the lines
- The same two-stage structure could be applied to datasets that include explicit cultural or emotional annotations to test cross-dataset stability of the discovered clusters.
- If the clusters truly separate affective dimensions, downstream tasks such as caption generation conditioned on a chosen P-Topic might produce more varied emotional tone.
- The dynamic cluster selection mechanism suggests a way to compare perceptual richness across different image domains without fixing the number of topics in advance.
Load-bearing premise
The unsupervised clusters formed from visual-textual pairs correspond to distinct factual-plus-affective perception experiences instead of purely semantic or visual groupings.
What would settle it
A controlled human study in which raters judge whether images assigned to the same discovered cluster share the same factual-affective perception experience; performance no better than random assignment would falsify the claim.
Figures



read the original abstract
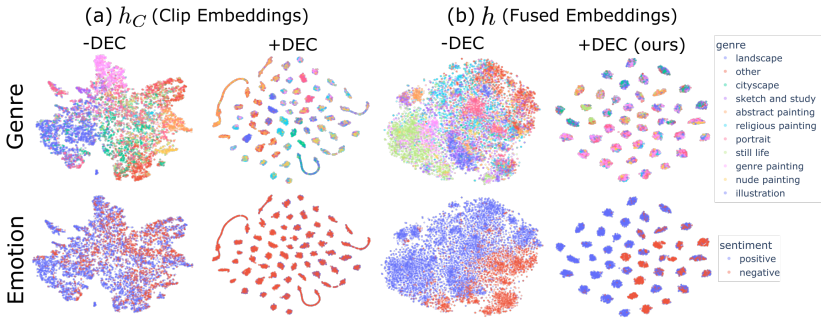
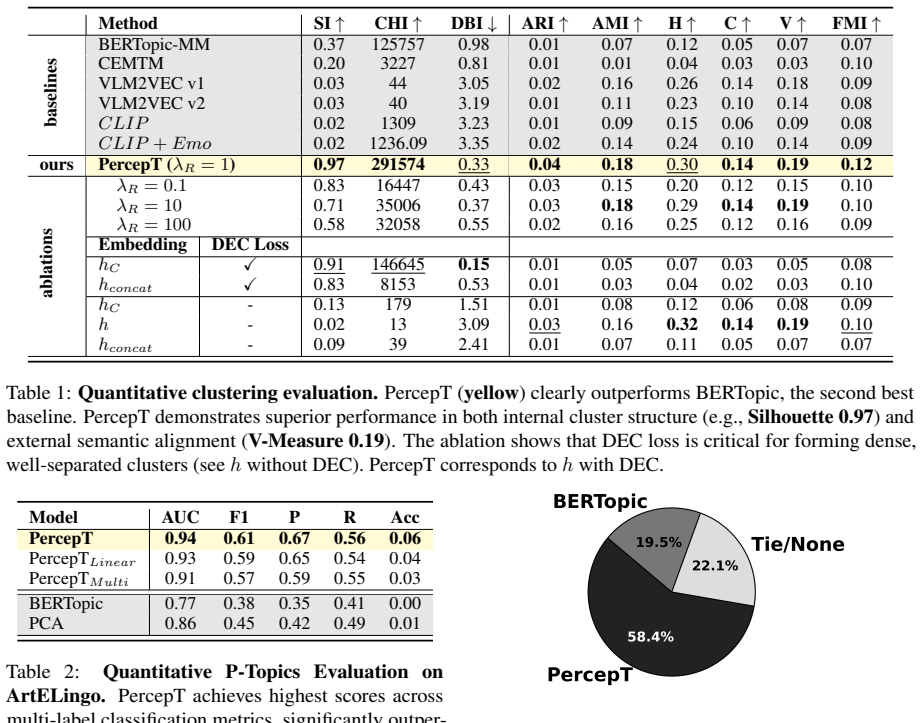
We present P-Topics (Perception Topics) modeling, a novel problem for understanding how images are perceived affectively and across cultures. The goal is to (1) discover and model the different perception experiences in a dataset of images and captions, where each experience is defined by an objective factual and a subjective affective aspect, and (2) associate images to their relevant perception experiences. We introduce **PercepT** (**Percep**tion topic **T**ransformer), a two-stage architecture that tackles P-Topics modeling. In the formation stage, percepT discovers *P-Topics* as visual-textual clusters using an unsupervised training objective, and dynamically selects the number of clusters to match the perceptual richness of the dataset. In the mapping stage, it learns *P-Topic mapping functions* via attention pooling to associate images to their respective clusters. On ArtELingo, PercepT achieves a silhouette score of **0.97** compared to **0.37** from the closest baseline reflecting better perceptual clusters. PercepT also achieves an AUC score of **0.94** compared to **0.77** showing better mapping to perceptual clusters. Human evaluation confirms that PercepT captures semantically meaningful perception experiences and significantly outperforms existing methods. Our implementation will be made public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces P-Topics modeling as a new problem for discovering perception experiences (each defined by an objective factual aspect and a subjective affective aspect) from vision-language image-caption data, along with associating images to those experiences. It presents PercepT, a two-stage transformer: an unsupervised formation stage that discovers P-Topics as visual-textual clusters with dynamic cluster count selection, and a mapping stage that uses attention pooling to associate images to clusters. On the ArtELingo dataset, PercepT reports a silhouette score of 0.97 (vs. 0.37 for the closest baseline) and AUC of 0.94 (vs. 0.77), with human evaluation confirming semantically meaningful experiences; the implementation will be released publicly.
Significance. If the unsupervised clusters can be shown to isolate factual-plus-affective perceptual experiences (including cross-cultural affective dimensions) rather than standard semantic or visual similarity, the framework would offer a concrete advance in moving vision-language models beyond purely semantic representations toward modeling subjective perception. The public code release would support reproducibility and follow-up work.
major comments (2)
- [Abstract / Formation stage] Abstract / Formation stage: The central claim that P-Topics capture 'objective factual and a subjective affective aspect' (and go 'beyond semantics') rests on the unsupervised clustering objective producing clusters aligned with this definition. However, the only human evaluation described confirms 'semantically meaningful' experiences; no ablation (e.g., comparison against CLIP-only semantic clustering) or affective annotation of clusters is reported to isolate the affective component or rule out that clusters reflect visual/textual similarity instead.
- [Abstract] Abstract: The headline performance numbers (silhouette 0.97, AUC 0.94) are presented without any description of baseline implementations, data splits, statistical testing, or the precise computation of the silhouette and AUC metrics. This prevents verification that the metrics are independent of training choices or cluster-selection decisions and directly support the superiority claim.
minor comments (1)
- [Abstract] The abstract states that human evaluation 'significantly outperforms existing methods' but provides no quantitative details (e.g., inter-annotator agreement, exact rating scales, or statistical tests) on the human study.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of our evaluation methodology. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Formation stage] Abstract / Formation stage: The central claim that P-Topics capture 'objective factual and a subjective affective aspect' (and go 'beyond semantics') rests on the unsupervised clustering objective producing clusters aligned with this definition. However, the only human evaluation described confirms 'semantically meaningful' experiences; no ablation (e.g., comparison against CLIP-only semantic clustering) or affective annotation of clusters is reported to isolate the affective component or rule out that clusters reflect visual/textual similarity instead.
Authors: The ArtELingo dataset captions explicitly encode both factual descriptions and affective, cross-cultural perceptions, and our formation stage clusters on joint vision-language embeddings derived from these pairs. This design aims to go beyond pure semantics by leveraging affective language in the textual component. We agree that an explicit ablation against CLIP-only clustering would better isolate the contribution of affective signals, and we will add this comparison (along with cluster-level affective analysis where possible) in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: The headline performance numbers (silhouette 0.97, AUC 0.94) are presented without any description of baseline implementations, data splits, statistical testing, or the precise computation of the silhouette and AUC metrics. This prevents verification that the metrics are independent of training choices or cluster-selection decisions and directly support the superiority claim.
Authors: We agree that the experimental details require expansion for full reproducibility and verification. The revised manuscript will include a dedicated experimental setup subsection describing baseline implementations, data splits, any statistical significance testing, and the exact formulas and procedures used to compute silhouette scores and AUC (including their relation to dynamic cluster selection). revision: yes
Circularity Check
No significant circularity; evaluation metrics are standard and independent of any derivation chain
full rationale
The paper describes a two-stage unsupervised clustering plus mapping architecture with no equations or derivations shown. Performance is reported via standard external metrics (silhouette score, AUC) on held-out data. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations are present in the provided text. The central claim rests on empirical separation of clusters rather than any mathematical identity or construction that collapses the result to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
FirstName Alpher , title =
-
[2]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[3]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[4]
FirstName Alpher and FirstName Gamow , title =
-
[5]
Computer Vision -- ECCV 2022 , year =
2022
-
[6]
Oesterling and Suraj Srinivas and F
Usha Bhalla and Alexander X. Oesterling and Suraj Srinivas and F. Calmon and Himabindu Lakkaraju , booktitle =. ArXiv , title =
-
[7]
R. Trans. Mach. Learn. Res. , year =
-
[8]
and Della Pietra, Vincent J
Brown, Peter F. and Della Pietra, Vincent J. and deSouza, Peter V. and Lai, Jenifer C. and Mercer, Robert L. , journal =. Class-Based. 1992 , url =
1992
-
[9]
2020 , volume =
Dimitar Angelov , journal =. 2020 , volume =
2020
-
[10]
URL:https: //aclanthology.org/2020.emnlp-main.135,doi:10.18653/v1/2020.emnlp-main.135
Tired of Topic Models? Clusters of Pretrained Word Embeddings Make for Fast and Good Topics too! , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , month = nov, year =. doi:10.18653/v1/2020.emnlp-main.135 , pages =
-
[11]
Grootendorst , journal =
Maarten R. Grootendorst , journal =. 2022 , volume =
2022
-
[12]
Proceedings of the ACM Web Conference 2022 , pages =
Topic discovery via latent space clustering of pretrained language model representations , author =. Proceedings of the ACM Web Conference 2022 , pages =
2022
-
[13]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren and Shilong Liu and Ailing Zeng and Jing Lin and Kunchang Li and He Cao and Jiayu Chen and Xinyu Huang and Yukang Chen and Feng Yan and Zhaoyang Zeng and Hao Zhang and Feng Li and Jie Yang and Hongyang Li and Qing Jiang and Lei Zhang , year =. Grounded. 2401.14159 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Language in a Bottle: Language Model Guided Concept Bottlenecks for Interpretable Image Classification , year =
Yue Yang and Artemis Panagopoulou and Shenghao Zhou and Daniel Jin and Chris Callison-Burch and Mark Yatskar , booktitle =. Language in a Bottle: Language Model Guided Concept Bottlenecks for Interpretable Image Classification , year =. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
2023
-
[15]
AAAI Workshop on Meta-Learning and MetaDL Challenge , pages =
Semi-supervised few-shot learning with prototypical random walks , author =. AAAI Workshop on Meta-Learning and MetaDL Challenge , pages =. 2021 , organization =
2021
-
[16]
Mohamed, Youssef and Li, Runjia and Ahmad, Ibrahim Said and Haydarov, Kilichbek and Torr, Philip and Church, Kenneth and Elhoseiny, Mohamed , editor =. No Culture Left Behind:. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , journal =. 2024 , address =. doi:10.18653/v1/2024.emnlp-main.1165 , pages =
-
[17]
EMNLP , year =
Ashish Thapliyal and Jordi Pont-Tuset and Xi Chen and Radu Soricut , title =. EMNLP , year =
-
[18]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author =. arXiv preprint arXiv:1907.11692 , volume =
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[19]
DINOv2: Learning Robust Visual Features without Supervision
Dinov2: Learning robust visual features without supervision , author =. arXiv preprint arXiv:2304.07193 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
No Language Left Behind: Scaling Human-Centered Machine Translation
No language left behind: Scaling human-centered machine translation , author =. arXiv preprint arXiv:2207.04672 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
, author =
Visualizing data using t-SNE. , author =. Journal of machine learning research , volume =
-
[22]
science , volume =
Dynamic programming , author =. science , volume =. 1966 , publisher =
1966
-
[23]
Journal of machine Learning research , volume =
Latent dirichlet allocation , author =. Journal of machine Learning research , volume =
-
[24]
arXiv preprint arXiv:2211.10780 , year =
Artelingo: A million emotion annotations of wikiart with emphasis on diversity over language and culture , author =. arXiv preprint arXiv:2211.10780 , year =
-
[25]
IEEE transactions on pattern analysis and machine intelligence , volume=
Write a classifier: Predicting visual classifiers from unstructured text , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2016 , publisher=
2016
-
[26]
Proceedings of the IEEE international conference on computer vision , pages=
Write a classifier: Zero-shot learning using purely textual descriptions , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
It is okay to not be okay: Overcoming emotional bias in affective image captioning by contrastive data collection , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[28]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
X 2-vlm: All-in-one pre-trained model for vision-language tasks , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
-
[29]
International Conference on Machine Learning , pages =
mplug-2: A modularized multi-modal foundation model across text, image and video , author =. International Conference on Machine Learning , pages =. 2023 , organization =
2023
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Florence-2: Advancing a unified representation for a variety of vision tasks , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[31]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Kosmos-2: Grounding multimodal large language models to the world , author =. arXiv preprint arXiv:2306.14824 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author =. arXiv preprint arXiv:2409.12191 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Minigpt-v2: large language model as a unified interface for vision-language multi-task learning , author =. arXiv preprint arXiv:2310.09478 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Journal of cross-cultural gerontology , volume =
Perceptions of aging in two cultures: Korean and American views on old age , author =. Journal of cross-cultural gerontology , volume =. 2006 , publisher =
2006
-
[35]
Journal of applied gerontology , volume =
Stereotypes and perceptions of the elderly by the youth in Nigeria: Implications for social policy , author =. Journal of applied gerontology , volume =. 2005 , publisher =
2005
-
[36]
nearest neighbor
When is “nearest neighbor” meaningful? , author =. International conference on database theory , pages =. 1999 , organization =
1999
-
[37]
Proceedings of the 25th international conference on Machine learning , pages =
Extracting and composing robust features with denoising autoencoders , author =. Proceedings of the 25th international conference on Machine learning , pages =. 2008 , organization =
2008
-
[38]
International conference on machine learning , pages =
Unsupervised deep embedding for clustering analysis , author =. International conference on machine learning , pages =. 2016 , organization =
2016
-
[39]
Journal of machine learning research , volume =
Visualizing data using t-SNE , author =. Journal of machine learning research , volume =
-
[40]
International conference on machine learning , pages =
Learning transferable visual models from natural language supervision , author =. International conference on machine learning , pages =. 2021 , organization =
2021
-
[41]
2025 , howpublished =
Emotion Detection with ModernBERT , author =. 2025 , howpublished =
2025
-
[42]
2025 , eprint =
Multilingual Machine Translation with Open Large Language Models at Practical Scale: An Empirical Study , author =. 2025 , eprint =
2025
-
[43]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Affection: Learning affective explanations for real-world visual data , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[44]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Probabilistic principal component analysis , author =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 1999 , publisher =
1999
-
[45]
Annals of eugenics , volume =
The use of multiple measurements in taxonomic problems , author =. Annals of eugenics , volume =. 1936 , publisher =
1936
-
[46]
Journal of computational and applied mathematics , volume =
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis , author =. Journal of computational and applied mathematics , volume =. 1987 , publisher =
1987
-
[47]
IEEE transactions on pattern analysis and machine intelligence , number =
A cluster separation measure , author =. IEEE transactions on pattern analysis and machine intelligence , number =. 2009 , publisher =
2009
-
[48]
Communications in Statistics-theory and Methods , volume =
A dendrite method for cluster analysis , author =. Communications in Statistics-theory and Methods , volume =. 1974 , publisher =
1974
-
[49]
Journal of the American Statistical association , volume =
Objective criteria for the evaluation of clustering methods , author =. Journal of the American Statistical association , volume =. 1971 , publisher =
1971
-
[50]
Journal of Machine Learning Research , year =
Nguyen Xuan Vinh and Julien Epps and James Bailey , title =. Journal of Machine Learning Research , year =
-
[51]
Proceedings of the 2007 joint conference on empirical methods in natural language processing and computational natural language learning (EMNLP-CoNLL) , pages =
V-measure: A conditional entropy-based external cluster evaluation measure , author =. Proceedings of the 2007 joint conference on empirical methods in natural language processing and computational natural language learning (EMNLP-CoNLL) , pages =
2007
-
[52]
1988 , publisher =
Algorithms for clustering data , author =. 1988 , publisher =
1988
-
[53]
SIAM review , volume =
Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions , author =. SIAM review , volume =. 2011 , publisher =
2011
-
[54]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[55]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
CEMTM: Contextual Embedding-based Multimodal Topic Modeling , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
2025
-
[56]
Proceedings of the 29th International Conference on Computational Linguistics , pages =
Multilingual and multimodal topic modelling with pretrained embeddings , author =. Proceedings of the 29th International Conference on Computational Linguistics , pages =
-
[57]
GPTopic: Dynamic and interactive topic representations.arXiv preprint arXiv:2403.03628,
Gptopic: Dynamic and interactive topic representations , author =. arXiv preprint arXiv:2403.03628 , year =
-
[58]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages =
TopicGPT: A prompt-based topic modeling framework , author =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages =
2024
-
[59]
Proceedings of the International AAAI Conference on Web and Social Media , volume =
More than memes: A multimodal topic modeling approach to conspiracy theories on telegram , author =. Proceedings of the International AAAI Conference on Web and Social Media , volume =
-
[60]
Advances in neural information processing systems , volume =
Visual instruction tuning , author =. Advances in neural information processing systems , volume =
-
[61]
VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks
Vlm2vec: Training vision-language models for massive multimodal embedding tasks , author =. arXiv preprint arXiv:2410.05160 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Benchmarking Vision Language Models for Cultural Understanding
Nayak, Shravan and Jain, Kanishk and Awal, Rabiul and Reddy, Siva and Steenkiste, Sjoerd Van and Hendricks, Lisa Anne and Stanczak, Karolina and Agrawal, Aishwarya. Benchmarking Vision Language Models for Cultural Understanding. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.329
-
[63]
arXiv preprint arXiv:2407.00263 , year=
From Local Concepts to Universals: Evaluating the Multicultural Understanding of Vision-Language Models , author=. arXiv preprint arXiv:2407.00263 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.