SemChunk-C: Semantic Segmentation for C Code
Pith reviewed 2026-06-30 22:34 UTC · model grok-4.3
The pith
SemChunk-C lightweight models match larger LLMs at identifying semantic chunks in C code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SemChunk-C is a family of lightweight language models with 17M to 150M parameters that identify chunk boundaries in C-related code and assign functional categories, achieving high boundary accuracy and semantic coherence on various datasets while matching or outperforming chunkers based on much larger code-oriented LLMs.
What carries the argument
An LLM-based classifier trained to detect flexible chunk boundaries and assign functional attributes such as data structures or interface blocks.
If this is right
- The models handle challenging real-world constructs including nested definitions and macros across .c, .cpp, .h, and .cs files.
- Downstream tasks such as retrieval show improved performance on curated benchmarks when using the produced chunks.
- Small parameter counts allow efficient semantic segmentation without the compute cost of larger models.
- The approach remains robust on irregular structural patterns typical of production C-family codebases.
Where Pith is reading between the lines
- If the category labels prove stable, they could support type-aware indexing that lets retrieval systems fetch code by functional role rather than text similarity alone.
- The flexible-boundary method may reduce the need for language-specific parsers when moving the technique to other procedural languages.
- Lightweight deployment could enable on-device or low-resource code analysis pipelines that currently depend on remote large-model calls.
Load-bearing premise
An LLM-based classifier can reliably identify flexible chunk boundaries and assign meaningful functional categories without post-hoc tuning or dataset-specific adjustments.
What would settle it
Evaluation on a fresh collection of C files containing complex nested macros and irregular structures where boundary accuracy falls below that of larger LLM chunkers.
Figures

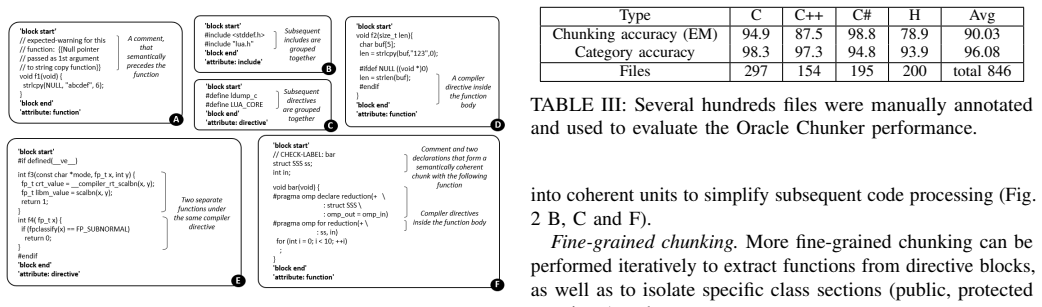
read the original abstract
Semantic segmentation of code written in a C-family language remains a challenging problem, due to the language's complex syntax, macro expansion, and irregular structural patterns. Existing chunking methods, such as fixed-sized windows, heuristic splitting, and syntax-based tools, often fail to capture meaningful functional units, limiting the efficacy of retrieval and other downstream LLM driven tasks. In this paper, we address the problem of chunking in C-related languages. First, we define a set of code chunk categories. Second, we train an LLM-based classifier to a) identify chunk boundaries, and b) assign each chunk a descriptive functional attribute (a category), which can be useful for downstream tasks. By leveraging the LLM's ability to capture semantic context within the code, we assume flexible chunk boundaries, allowing to adapt to the specific structure and context of each instance. Third, we introduce SemChunk-C, a family of lightweight language models for semantic chunking of C-related files (.c, .cpp, .h, .cs, etc.). These models are based on the first four Ettin encoders [1] with 17M, 32M, 68M, and 150M parameters. Despite their relatively small size, they are capable of identifying cohesive code units, such as data structures, interface blocks, and other components. Furthermore, we demonstrate the robustness of our approach on real-world code, including challenging constructs such as nested definitions and macros. We test our approach on various datasets, and show that it achieves high boundary accuracy and semantic coherence, matching or outperforming chunkers that are based on much larger code-oriented LLMs. We also validate the improved performance of the downstream tasks on a few curated benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SemChunk-C, a family of small encoder-based models (17M–150M parameters, derived from the first four Ettin encoders) for semantic segmentation of C-family code (.c, .cpp, .h, .cs, etc.). It defines a set of functional chunk categories, trains an LLM classifier to detect flexible boundaries and assign categories, distills the capability into the lightweight models, and claims these models achieve high boundary accuracy and semantic coherence while matching or outperforming chunkers based on much larger code-oriented LLMs across various datasets and downstream tasks.
Significance. If the performance claims hold with proper empirical support, the work would offer a practical contribution to code retrieval and LLM-driven tasks by supplying deployable, low-parameter models that capture semantic units more effectively than fixed-window or heuristic baselines. The explicit use of functional categories is a constructive element that could aid structured downstream applications.
major comments (3)
- [Abstract] Abstract: the central claim that SemChunk-C models 'achieve high boundary accuracy and semantic coherence, matching or outperforming chunkers that are based on much larger code-oriented LLMs' is stated without any accompanying numerical results, metrics, datasets, error bars, or baseline comparisons, rendering the headline performance assertion unevaluable.
- [LLM classifier description] Section describing the LLM-based classifier: no details are supplied on label generation quality (e.g., validation against human annotations, inter-annotator agreement, or prompting/tuning procedures); because the distilled models' reported accuracies depend directly on the fidelity of these labels, the absence of this information prevents assessment of whether the comparisons to larger-LLM baselines are valid.
- [Experimental evaluation] Experimental evaluation (implied in the abstract's reference to 'various datasets' and 'curated benchmarks'): the manuscript provides no information on training procedures, hyperparameters, dataset statistics, or statistical tests for either the classifier or the SemChunk-C models, which is load-bearing for the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional empirical details are needed to support the claims. We address each point below and will revise the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SemChunk-C models 'achieve high boundary accuracy and semantic coherence, matching or outperforming chunkers that are based on much larger code-oriented LLMs' is stated without any accompanying numerical results, metrics, datasets, error bars, or baseline comparisons, rendering the headline performance assertion unevaluable.
Authors: We agree that the abstract would be strengthened by including concrete metrics. In the revised version we will add key numerical results (e.g., boundary F1 scores, semantic coherence metrics), the primary datasets, and direct comparisons to the larger-LLM baselines so that the performance claim can be evaluated directly from the abstract. revision: yes
-
Referee: [LLM classifier description] Section describing the LLM-based classifier: no details are supplied on label generation quality (e.g., validation against human annotations, inter-annotator agreement, or prompting/tuning procedures); because the distilled models' reported accuracies depend directly on the fidelity of these labels, the absence of this information prevents assessment of whether the comparisons to larger-LLM baselines are valid.
Authors: We acknowledge that details on label quality are essential for assessing the validity of the distillation. We will expand the LLM-classifier section to describe the prompting and tuning procedures used, any human validation performed, and inter-annotator agreement statistics where available. If human validation was limited, we will explicitly note this and discuss its implications for the reported results. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation (implied in the abstract's reference to 'various datasets' and 'curated benchmarks'): the manuscript provides no information on training procedures, hyperparameters, dataset statistics, or statistical tests for either the classifier or the SemChunk-C models, which is load-bearing for the outperformance claim.
Authors: We agree that the experimental section requires substantially more detail to support the outperformance claims. In the revision we will add full descriptions of training procedures and hyperparameters for both the LLM classifier and the SemChunk-C models, dataset statistics (sizes, splits, sources), and any statistical tests used to compare against baselines. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's chain consists of defining chunk categories, training an LLM-based classifier for boundaries and labels, distilling into Ettin-based encoders, and evaluating boundary accuracy on datasets against larger LLM baselines. No quoted step reduces a claimed prediction or result to its own fitted inputs by construction, nor does any load-bearing premise collapse to a self-citation whose validity is internal to the paper. The central performance claims rest on external dataset testing rather than tautological re-use of the same quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ettin: Analyzing encoders vs decoders using the same architecture and data.International Conference on Learning Representations (ICLR), 2025
Orion Weller, Kathryn Ricci, Marc Marone, Antoine Chaffin, Dawn Lawrie, and Benjamin Van Durme. Ettin: Analyzing encoders vs decoders using the same architecture and data.International Conference on Learning Representations (ICLR), 2025
2025
-
[2]
Marti A. Hearst. TextTiling: Segmenting text into multi-paragraph subtopic passages.Computational Linguistics, 23(1):33–64, 1997
1997
-
[3]
Text Segmentation based on Semantic Word Embeddings
Alexander A. Alemi and Paul Ginsparg. Text segmentation based on semantic word embeddings.arXiv preprint arXiv:1503.05543, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
Text segmentation as a supervised learning task
Omri Koshorek, Adir Cohen, Noam Mor, Michael Rotman, and Jonathan Berant. Text segmentation as a supervised learning task. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 469–473, 2018
2018
-
[5]
Dense X retrieval: What retrieval unit should we use?arXiv preprint arXiv:2312.06648, 2023
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Dense X retrieval: What retrieval unit should we use?arXiv preprint arXiv:2312.06648, 2023
-
[6]
Scott Barnett, Stefanus Kurniawan, Srikanth Thudumu, Zach Brannelly, and Mohamed Abdelrazek. Seven failure points when engineering a retrieval augmented generation system.arXiv preprint arXiv:2401.05856, 2024
-
[7]
Semantic source code models using identifier embeddings.IEEE Access, 7:129364–129377, 2019
Vasiliki Efstathiou and Diomidis Spinellis. Semantic source code models using identifier embeddings.IEEE Access, 7:129364–129377, 2019
2019
-
[8]
GraphCodeBERT: Pre-training Code Representations with Data Flow
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. GraphCodeBERT: Pre-training code representation with data flow.arXiv preprint arXiv:2009.08366, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
Sheng Zhang, Yifan Ding, Shuquan Lian, Shun Song, and Hui Li. CodeRAG: Finding relevant and necessary knowledge for retrieval- augmented repository-level code completion.Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, 2025
2025
-
[10]
CodeWisp: AST guided retrieval augmented generation for code generation and completion
Hamza El Atrassi, Yasmina El Idrissi, and Yahya Benkaouz. CodeWisp: AST guided retrieval augmented generation for code generation and completion. In2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), 2025
2025
-
[11]
CAST: Enhancing code retrieval-augmented generation with structural chunking via abstract syntax tree.Findings of the Association for Computational Linguistics: EMNLP 2025, 2025
Yilin Zhang, Xinran Zhao, Zora Zhiruo Wang, Chenyang Yang, Jiayi Wei, and Tongshuang Wu. CAST: Enhancing code retrieval-augmented generation with structural chunking via abstract syntax tree.Findings of the Association for Computational Linguistics: EMNLP 2025, 2025
2025
-
[12]
CODE2JSON: Can a zero-shot llm extract code features for code RAG?International Conference on Learning Representations (ICLR), 2025
Aryan Singhal, Rajat Ghosh, Ria Mundra, Harshil Dadlani, and Debojyoti Dutta. CODE2JSON: Can a zero-shot llm extract code features for code RAG?International Conference on Learning Representations (ICLR), 2025
2025
-
[13]
RANGER: Repository-level agent for graph-enhanced retrieval.arXiv preprint arXiv:2509.25257, 2025
Pratik Shah, Rajat Ghosh, Aryan Singhal, and Debojyoti Dutta. RANGER: Repository-level agent for graph-enhanced retrieval.arXiv preprint arXiv:2509.25257, 2025
-
[14]
Sajal Halder, Muhammad Ejaz Ahmed, and Seyit Camtepe. FuncVul: An effective function level vulnerability detection model using LLM and code chunk.arXiv preprint arXiv:2506.19453, 2025
-
[15]
LongCodeZip: Compress long context for code language models
Yuling Shi, Yichun Qian, Hongyu Zhang, Beijun Shen, and Xiaodong Gu. LongCodeZip: Compress long context for code language models. arXiv preprint arXiv:2510.00446, 2025
-
[16]
Scott, Anand Patel, Jacob Zimmer, Colin Diggs, Michael Doyle, Scott Rosen, Nitin Naik, Justin F
Christopher Glasz, Emily Escamilla, Eric O. Scott, Anand Patel, Jacob Zimmer, Colin Diggs, Michael Doyle, Scott Rosen, Nitin Naik, Justin F. Brunelle, Samruddhi Thaker, Parthav Poudel, Arun Sridharan, Amit Madan, Doug Wendt, William Macke, and Thomas Schill. Can LLMs replace humans during code chunking?arXiv preprint arXiv:2506.19897, 2025. [17]https://hu...
-
[17]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Aidar Valeev, Roman Garaev, Vadim Lomshakov, Irina Piontkovskaya, Vladimir Ivanov, and Israel Adewuyi. Y ABLoCo: Yet another benchmark for long context code generation.arXiv preprint arXiv:2505.04406, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.