CleanCodec: Efficient and Robust Speech Tokenization via Perceptually Guided Encoding
Pith reviewed 2026-06-28 05:18 UTC · model grok-4.3
The pith
CleanCodec reframes speech tokenization as a selective information bottleneck to discard noise and achieve 12.5 tokens per second with better quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CleanCodec is a denoising audio codec which learns to encode only perceptually important features and discard imperceptible information. At just 12.5 tokens per second, it achieves state-of-the-art tokenization efficiency and substantially outperforms existing codecs in speaker similarity and speech intelligibility. Evaluations on downstream text-to-speech and voice conversion tasks further demonstrate improved performance and up to 17x faster inference.
What carries the argument
The selective information bottleneck that forces the codec to discard imperceptible information such as background noise and recording artifacts.
If this is right
- Reconstructed speech exhibits higher speaker similarity and intelligibility at low token rates.
- Downstream text-to-speech and voice conversion models achieve better output quality.
- Inference speed in downstream pipelines increases by up to 17 times.
- Speech processing pipelines require fewer tokens overall while maintaining or improving task performance.
Where Pith is reading between the lines
- The same bottleneck principle could be tested on music or environmental audio where noise removal is also useful.
- Lower token rates might allow longer context windows in autoregressive models trained on the tokens.
- If the denoising step generalizes, similar selective encoding could reduce token counts in other modalities such as video.
Load-bearing premise
A learned denoising model can reliably keep only perceptually important speech content without losing linguistically or acoustically meaningful information.
What would settle it
An evaluation on noisy speech where CleanCodec produces lower intelligibility or speaker similarity scores than a non-denoising codec at the same token rate.
Figures
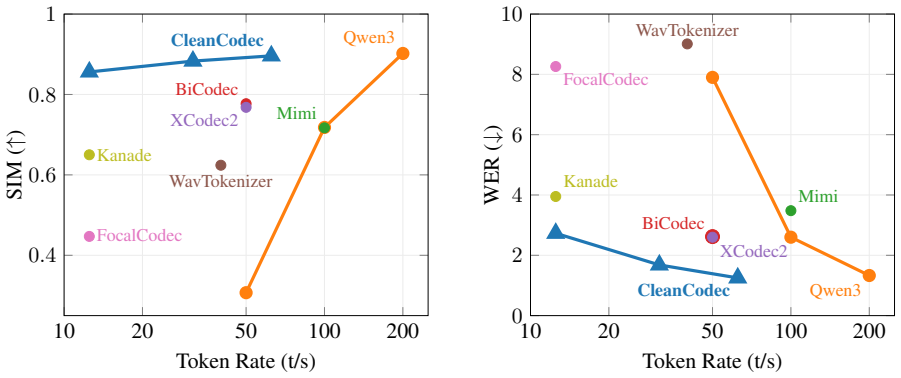
read the original abstract
Neural audio codecs are a key component of speech processing pipelines, compressing audio into discrete tokens for downstream modeling. However, existing codecs struggle to balance reconstruction quality with token efficiency, often encoding perceptually irrelevant information such as background noise and recording artifacts at the expense of linguistically and acoustically meaningful content. We reframe audio tokenization as a selective information bottleneck problem and propose CleanCodec, a denoising audio codec which learns to encode only perceptually important features and discard imperceptible information. At just 12.5 tokens per second, CleanCodec achieves state-of-the-art tokenization efficiency, substantially outperforming existing codecs in speaker similarity and speech intelligibility. Evaluations on downstream text-to-speech and voice conversion tasks further demonstrate improved performance and up to 17x faster inference, highlighting significant efficiency gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CleanCodec, a denoising neural audio codec that reframes audio tokenization as a selective information bottleneck problem. It learns to encode only perceptually important features while discarding imperceptible information such as background noise and artifacts. The central claim is that at 12.5 tokens per second, CleanCodec achieves state-of-the-art tokenization efficiency, substantially outperforming existing codecs on speaker similarity and speech intelligibility, with further gains on downstream text-to-speech and voice conversion tasks including up to 17x faster inference.
Significance. If the empirical claims hold under detailed scrutiny, the work could meaningfully advance efficient and robust speech tokenization for downstream modeling pipelines. The perceptual guidance via denoising offers a principled way to reduce token rates without sacrificing linguistic or speaker content, which would benefit scaling of audio generative models and real-time applications. Strengths include the focus on a concrete efficiency metric (12.5 tokens/sec) and explicit downstream task evaluations.
major comments (2)
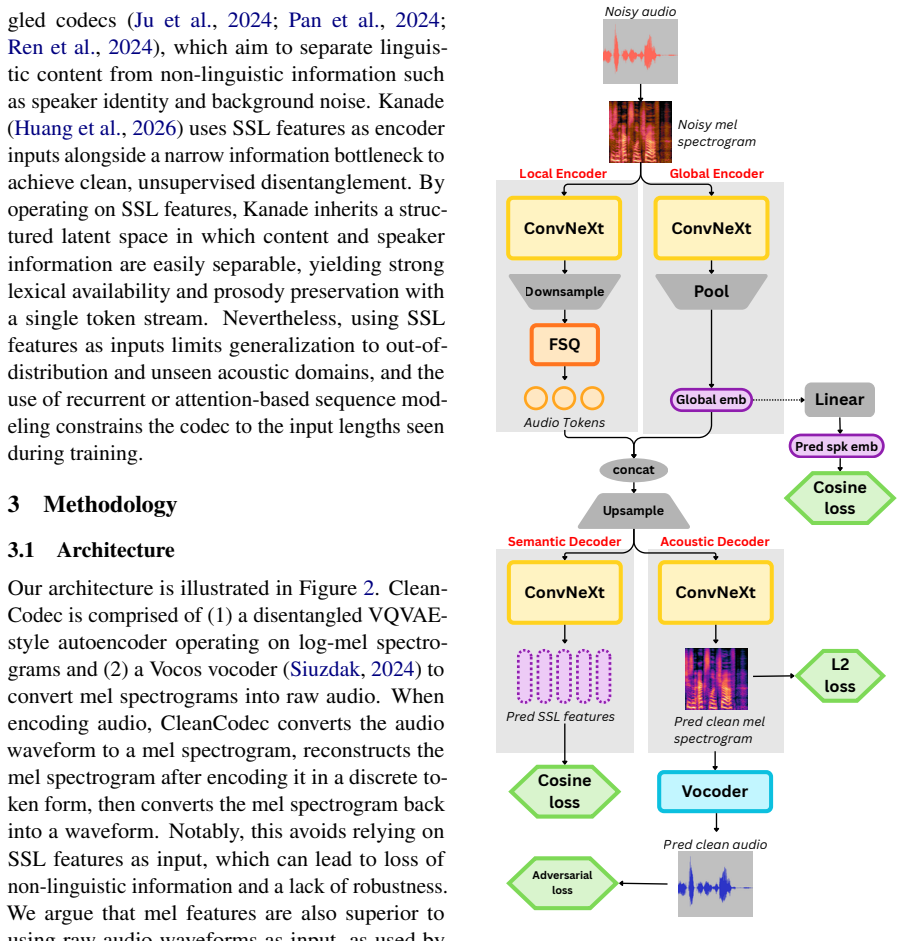
- The provided manuscript text consists only of the abstract and contains no architecture diagrams, loss formulations, training objectives, or equations describing how the selective information bottleneck is enforced (e.g., no details on the denoising objective or perceptual loss terms). This prevents verification of whether the method reliably separates perceptually important features from noise as claimed.
- [Abstract] The abstract asserts 'substantially outperforming existing codecs' and 'state-of-the-art tokenization efficiency' at 12.5 tokens per second, but supplies no quantitative metrics, baseline comparisons, or table references to support the magnitude of gains in speaker similarity or intelligibility. Without these, the central efficiency-quality tradeoff claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the review and the opportunity to clarify aspects of the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: The provided manuscript text consists only of the abstract and contains no architecture diagrams, loss formulations, training objectives, or equations describing how the selective information bottleneck is enforced (e.g., no details on the denoising objective or perceptual loss terms). This prevents verification of whether the method reliably separates perceptually important features from noise as claimed.
Authors: The version provided for review was limited to the abstract. The complete manuscript contains architecture diagrams, loss formulations, training objectives, and equations detailing the selective information bottleneck, denoising objective, and perceptual loss terms. We will submit the full manuscript with these technical details in the revision. revision: yes
-
Referee: [Abstract] The abstract asserts 'substantially outperforming existing codecs' and 'state-of-the-art tokenization efficiency' at 12.5 tokens per second, but supplies no quantitative metrics, baseline comparisons, or table references to support the magnitude of gains in speaker similarity or intelligibility. Without these, the central efficiency-quality tradeoff claim cannot be evaluated.
Authors: Abstracts are concise summaries and conventionally omit specific quantitative metrics and table references. The full manuscript includes tables with baseline comparisons and metrics on speaker similarity and intelligibility at 12.5 tokens per second. We can add a brief reference to the relevant evaluation table within the abstract if the referee recommends it. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe CleanCodec as a reframing of tokenization into a selective information bottleneck via a denoising objective, with performance claims resting on the proposed architecture and external downstream evaluations. No equations, fitted parameters presented as predictions, self-citations, or uniqueness theorems appear in the text. The derivation chain is therefore self-contained against external benchmarks with no load-bearing steps that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perceptually important features can be distinguished from imperceptible information such as noise and artifacts via learned encoding
Reference graph
Works this paper leans on
-
[1]
Kanade: A Simple Disentangled Tokenizer for Spoken Language Modeling
Zhijie Huang and Stephen McIntosh and Daisuke Saito and Nobuaki Minematsu , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.00594 , eprinttype =. 2602.00594 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.00594 2026
-
[2]
Hyunjun Heo and Ui. NeXt-TDNN: Modernizing Multi-Scale Temporal Convolution Backbone for Speaker Verification , booktitle =. 2024 , url =. doi:10.1109/ICASSP48485.2024.10447037 , timestamp =
-
[3]
Attentive Statistics Pooling for Deep Speaker Embedding , booktitle =
Koji Okabe and Takafumi Koshinaka and Koichi Shinoda , editor =. Attentive Statistics Pooling for Deep Speaker Embedding , booktitle =. 2018 , url =. doi:10.21437/INTERSPEECH.2018-993 , timestamp =
-
[4]
William Peebles and Saining Xie , title =. 2023 , url =. doi:10.1109/ICCV51070.2023.00387 , timestamp =
-
[5]
Nithin Rao Koluguri and Taejin Park and Boris Ginsburg , title =. 2022 , url =. doi:10.1109/ICASSP43922.2022.9746806 , timestamp =
-
[6]
Rongkun Xue and Yazhe Niu and Shuai Hu and Zixin Yin and Yongqiang Yao and Jing Yang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.18897 , eprinttype =. 2507.18897 , timestamp =
-
[7]
Lindell, Dave Van Veen, Jeong Joon Park, and Gordon Wetzstein
Zhuang Liu and Hanzi Mao and Chao. A ConvNet for the 2020s , booktitle =. 2022 , url =. doi:10.1109/CVPR52688.2022.01167 , timestamp =
-
[8]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Xinsheng Wang and Mingqi Jiang and Ziyang Ma and Ziyu Zhang and Songxiang Liu and Linqin Li and Zheng Liang and Qixi Zheng and Rui Wang and Xiaoqin Feng and Weizhen Bian and Zhen Ye and Sitong Cheng and Ruibin Yuan and Zhixian Zhao and Xinfa Zhu and Jiahao Pan and Liumeng Xue and Pengcheng Zhu and Yunlin Chen and Zhifei Li and Xie Chen and Lei Xie and Yik...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.01710 2025
-
[9]
Zein Shaheen, Tasnima Sadekova, Yulia Matveeva, Alexandra Shirshova, and Mikhail Kudinov
Brecht Desplanques and Jenthe Thienpondt and Kris Demuynck , editor =. 21st Annual Conference of the International Speech Communication Association, Interspeech 2020, Virtual Event, Shanghai, China, October 25-29, 2020 , pages =. 2020 , url =. doi:10.21437/INTERSPEECH.2020-2650 , timestamp =
-
[10]
David Snyder and Daniel Garcia. X-Vectors: Robust. 2018. 2018 , url =. doi:10.1109/ICASSP.2018.8461375 , timestamp =
-
[11]
doi:10.1109/JSTSP.2022.3188113 , abstract =
Sanyuan Chen and Chengyi Wang and Zhengyang Chen and Yu Wu and Shujie Liu and Zhuo Chen and Jinyu Li and Naoyuki Kanda and Takuya Yoshioka and Xiong Xiao and Jian Wu and Long Zhou and Shuo Ren and Yanmin Qian and Yao Qian and Jian Wu and Michael Zeng and Xiangzhan Yu and Furu Wei , title =. 2022 , url =. doi:10.1109/JSTSP.2022.3188113 , timestamp =
-
[12]
Wei. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units , journal =. 2021 , url =. doi:10.1109/TASLP.2021.3122291 , timestamp =
-
[13]
wav2vec 2.0:
Alexei Baevski and Yuhao Zhou and Abdelrahman Mohamed and Michael Auli , editor =. wav2vec 2.0:. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
2020
-
[14]
Neural Discrete Representation Learning , booktitle =
A. Neural Discrete Representation Learning , booktitle =. 2017 , url =
2017
-
[15]
The Twelfth International Conference on Learning Representations,
Hubert Siuzdak , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[16]
The Thirteenth International Conference on Learning Representations,
Shengpeng Ji and Ziyue Jiang and Wen Wang and Yifu Chen and Minghui Fang and Jialong Zuo and Qian Yang and Xize Cheng and Zehan Wang and Ruiqi Li and Ziang Zhang and Xiaoda Yang and Rongjie Huang and Yidi Jiang and Qian Chen and Siqi Zheng and Zhou Zhao , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[17]
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis , booktitle =
Jungil Kong and Jaehyeon Kim and Jaekyoung Bae , editor =. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis , booktitle =. 2020 , url =
2020
-
[18]
High Fidelity Neural Audio Compression , journal =
Alexandre D. High Fidelity Neural Audio Compression , journal =. 2023 , url =
2023
-
[19]
High-Fidelity Audio Compression with Improved
Rithesh Kumar and Prem Seetharaman and Alejandro Luebs and Ishaan Kumar and Kundan Kumar , editor =. High-Fidelity Audio Compression with Improved. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , year =
2023
-
[20]
Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation , booktitle =
Hanzhao Li and Liumeng Xue and Haohan Guo and Xinfa Zhu and Yuanjun Lv and Lei Xie and Yunlin Chen and Hao Yin and Zhifei Li , editor =. Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation , booktitle =. 2024 , url =. doi:10.21437/INTERSPEECH.2024-1559 , timestamp =
-
[21]
Luca Della Libera and Francesco Paissan and Cem Subakan and Mirco Ravanelli , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.04465 , eprinttype =. 2502.04465 , timestamp =
-
[22]
URLhttps://arxiv.org/abs/2508.19205
Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.19205 , eprinttype =. 2508.19205 , timestamp =
-
[23]
The Twelfth International Conference on Learning Representations,
Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[24]
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis , journal =
Zhen Ye and Xinfa Zhu and Chi. Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis , journal =. 2025 , url =. doi:10.48550/ARXIV.2502.04128 , eprinttype =. 2502.04128 , timestamp =
-
[25]
Won Jang and Dan Lim and Jaesam Yoon and Bongwan Kim and Juntae Kim , editor =. UnivNet:. 22nd Annual Conference of the International Speech Communication Association, Interspeech 2021, Brno, Czechia, August 30 - September 3, 2021 , pages =. 2021 , url =. doi:10.21437/INTERSPEECH.2021-1016 , timestamp =
-
[26]
BigVGAN:
Sang. BigVGAN:. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[27]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre D. Moshi: a speech-text foundation model for real-time dialogue , journal =. 2024 , url =. doi:10.48550/ARXIV.2410.00037 , eprinttype =. 2410.00037 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.00037 2024
-
[28]
Qwen Team , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2601.15621 , eprinttype =. 2601.15621 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.15621 2026
-
[29]
Bartley and Nikolay Karpov and Jagadeesh Balam and Boris Ginsburg , title =
Monica Sekoyan and Nithin Rao Koluguri and Nune Tadevosyan and Piotr Zelasko and Travis M. Bartley and Nikolay Karpov and Jagadeesh Balam and Boris Ginsburg , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.14128 , eprinttype =. 2509.14128 , timestamp =
-
[30]
Takaaki Saeki and Detai Xin and Wataru Nakata and Tomoki Koriyama and Shinnosuke Takamichi and Hiroshi Saruwatari , editor =. 23rd Annual Conference of the International Speech Communication Association, Interspeech 2022, Incheon, Korea, September 18-22, 2022 , pages =. 2022 , url =. doi:10.21437/INTERSPEECH.2022-439 , timestamp =
-
[31]
Anurag Kumar and Ke Tan and Zhaoheng Ni and Pranay Manocha and Xiaohui Zhang and Ethan Henderson and Buye Xu , title =. 2023 , url =. doi:10.1109/ICASSP49357.2023.10096680 , timestamp =
-
[32]
Reshape Dimensions Network for Speaker Recognition , booktitle =
Ivan Yakovlev and Rostislav Makarov and Andrei Balykin and Pavel Malov and Anton Okhotnikov and Nikita Torgashov , editor =. Reshape Dimensions Network for Speaker Recognition , booktitle =. 2024 , url =. doi:10.21437/INTERSPEECH.2024-2116 , timestamp =
-
[33]
C Users J
Gage, Philip , title =. C Users J. , month = feb, pages =. 1994 , issue_date =
1994
-
[34]
Gray , title=
Robert M. Gray , title=. IEEE Assp Magazine , volume=. 1984 , publisher=
1984
-
[35]
Yongjian Chen and Tao Guan and Cheng Wang , title =. Sensors , volume =. 2010 , url =. doi:10.3390/S101211259 , timestamp =
-
[36]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[37]
Yuma Koizumi and Heiga Zen and Shigeki Karita and Yifan Ding and Kohei Yatabe and Nobuyuki Morioka and Michiel Bacchiani and Yu Zhang and Wei Han and Ankur Bapna , editor =. LibriTTS-R:. 24th Annual Conference of the International Speech Communication Association, Interspeech 2023, Dublin, Ireland, August 20-24, 2023 , pages =. 2023 , url =. doi:10.21437/...
-
[38]
Haorui He and Zengqiang Shang and Chaoren Wang and Xuyuan Li and Yicheng Gu and Hua Hua and Liwei Liu and Chen Yang and Jiaqi Li and Peiyang Shi and Yuancheng Wang and Kai Chen and Pengyuan Zhang and Zhizheng Wu , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.15907 , eprinttype =. 2501.15907 , timestamp =
-
[39]
GigaSpeech: An Evolving, Multi-Domain
Guoguo Chen and Shuzhou Chai and Guan. GigaSpeech: An Evolving, Multi-Domain. 22nd Annual Conference of the International Speech Communication Association, Interspeech 2021, Brno, Czechia, August 30 - September 3, 2021 , pages =. 2021 , url =. doi:10.21437/INTERSPEECH.2021-1965 , timestamp =
-
[40]
Tu Anh Nguyen and Wei. Expresso:. 24th Annual Conference of the International Speech Communication Association, Interspeech 2023, Dublin, Ireland, August 20-24, 2023 , pages =. 2023 , url =. doi:10.21437/INTERSPEECH.2023-1905 , timestamp =
-
[41]
Alexis Conneau and Min Ma and Simran Khanuja and Yu Zhang and Vera Axelrod and Siddharth Dalmia and Jason Riesa and Clara Rivera and Ankur Bapna , title =. 2022 , url =. doi:10.1109/SLT54892.2023.10023141 , timestamp =
-
[42]
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models , booktitle =
Zeqian Ju and Yuancheng Wang and Kai Shen and Xu Tan and Detai Xin and Dongchao Yang and Eric Liu and Yichong Leng and Kaitao Song and Siliang Tang and Zhizheng Wu and Tao Qin and Xiangyang Li and Wei Ye and Shikun Zhang and Jiang Bian and Lei He and Jinyu Li and Sheng Zhao , editor =. NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and ...
2024
-
[43]
Yong Ren and Tao Wang and Jiangyan Yi and Le Xu and Jianhua Tao and Chu Yuan Zhang and Junzuo Zhou , title =. 2024 , url =. doi:10.1109/ICASSP48485.2024.10448454 , timestamp =
-
[44]
CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92)
Yamagishi, Junichi and Veaux, Christophe and MacDonald, Kirsten. CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92)
-
[45]
Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu
Heiga Zen and Viet Dang and Rob Clark and Yu Zhang and Ron J. Weiss and Ye Jia and Zhifeng Chen and Yonghui Wu , editor =. LibriTTS:. 20th Annual Conference of the International Speech Communication Association, Interspeech 2019, Graz, Austria, September 15-19, 2019 , pages =. 2019 , url =. doi:10.21437/INTERSPEECH.2019-2441 , timestamp =
-
[46]
Simple and Controllable Music Generation , booktitle =
Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre D. Simple and Controllable Music Generation , booktitle =. 2023 , url =
2023
-
[47]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Philip Anastassiou and Jiawei Chen and Jitong Chen and Yuanzhe Chen and Zhuo Chen and Ziyi Chen and Jian Cong and Lelai Deng and Chuang Ding and Lu Gao and Mingqing Gong and Peisong Huang and Qingqing Huang and Zhiying Huang and Yuanyuan Huo and Dongya Jia and Chumin Li and Feiya Li and Hui Li and Jiaxin Li and Xiaoyang Li and Xingxing Li and Lin Liu and ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.02430 2024
-
[48]
Wataru Nakata and Yuki Saito and Yota Ueda and Hiroshi Saruwatari , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.17052 , eprinttype =. 2509.17052 , timestamp =
-
[49]
Robin Scheibler and Eric Bezzam and Ivan Dokmanic , title =. 2018. 2018 , url =. doi:10.1109/ICASSP.2018.8461310 , timestamp =
-
[50]
Audio Set: An ontology and human-labeled dataset for audio events
Jort F. Gemmeke and Daniel P. W. Ellis and Dylan Freedman and Aren Jansen and Wade Lawrence and R. Channing Moore and Manoj Plakal and Marvin Ritter , title =. 2017. 2017 , url =. doi:10.1109/ICASSP.2017.7952261 , timestamp =
-
[51]
FSD50K: an open dataset of human-labeled sound events,
Eduardo Fonseca and Xavier Favory and Jordi Pons and Frederic Font and Xavier Serra , title =. 2022 , url =. doi:10.1109/TASLP.2021.3133208 , timestamp =
-
[52]
WHAM!: Extending Speech Separation to Noisy Environments , booktitle =
Gordon Wichern and Joe Antognini and Michael Flynn and Licheng Richard Zhu and Emmett McQuinn and Dwight Crow and Ethan Manilow and Jonathan Le Roux , editor =. WHAM!: Extending Speech Separation to Noisy Environments , booktitle =. 2019 , url =. doi:10.21437/INTERSPEECH.2019-2821 , timestamp =
-
[53]
Yao Shi and Hui Bu and Xin Xu and Shaoji Zhang and Ming Li , title =. CoRR , volume =. 2020 , url =. 2010.11567 , timestamp =
arXiv 2020
-
[54]
doi:10.21437/interspeech.2017-950 , booktitle=
Arsha Nagrani and Joon Son Chung and Andrew Zisserman , editor =. VoxCeleb:. 18th Annual Conference of the International Speech Communication Association, Interspeech 2017, Stockholm, Sweden, August 20-24, 2017 , pages =. 2017 , url =. doi:10.21437/INTERSPEECH.2017-950 , timestamp =
-
[55]
The Twelfth International Conference on Learning Representations,
Xin Zhang and Dong Zhang and Shimin Li and Yaqian Zhou and Xipeng Qiu , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[56]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang and Sanyuan Chen and Yu Wu and Ziqiang Zhang and Long Zhou and Shujie Liu and Zhuo Chen and Yanqing Liu and Huaming Wang and Jinyu Li and Lei He and Sheng Zhao and Furu Wei , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2301.02111 , eprinttype =. 2301.02111 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2301.02111 2023
-
[57]
Parker and Anton Smirnov and Jordi Pons and CJ Carr and Zack Zukowski and Zach Evans and Xubo Liu , title =
Julian D. Parker and Anton Smirnov and Jordi Pons and CJ Carr and Zack Zukowski and Zach Evans and Xubo Liu , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[58]
Jiaqi Li and Xiaolong Lin and Zhekai Li and Shixi Huang and Yuancheng Wang and Chaoren Wang and Zhenpeng Zhan and Zhizheng Wu , editor =. DualCodec:. 26th Annual Conference of the International Speech Communication Association, Interspeech 2025, Rotterdam, The Netherlands, 17-21 August 2025 , publisher =. 2025 , url =. doi:10.21437/INTERSPEECH.2025-468 , ...
-
[59]
Yu Pan and Lei Ma and Jianjun Zhao , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2404.02702 , eprinttype =. 2404.02702 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.