MV-WAM: Manifold-Aware World Action Model with Value Augmentation
Pith reviewed 2026-06-26 14:34 UTC · model grok-4.3
The pith
MV-WAM aligns visual and action manifolds with a causal mask and manifold-aware optimization to raise robotic manipulation success under distribution shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
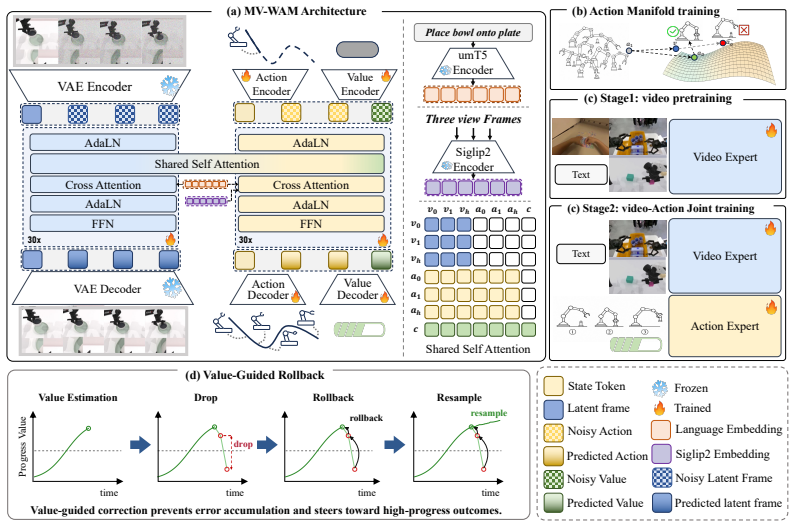
MV-WAM is an end-to-end framework that jointly models visual prediction, action generation, and value estimation with a cross-modality causal mask that hierarchically grounds actions in predicted video frames and value tokens in both modalities, a manifold-aware optimization scheme that accounts for structural heterogeneity across modalities, and a progress-value regulation mechanism that estimates task completion while detecting misalignment between predicted frames and generated actions.
What carries the argument
Cross-modality causal mask plus manifold-aware optimization scheme that grounds actions in predicted frames while respecting modality-specific manifold structures.
If this is right
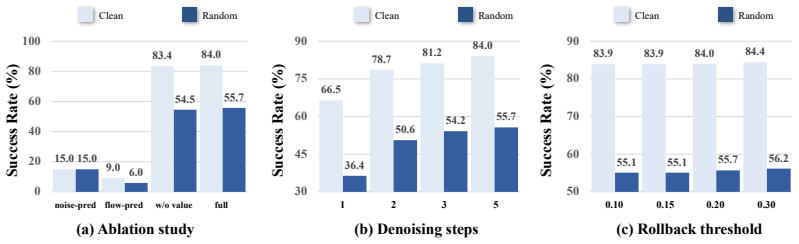
- Robotic policies can reach 55.7 percent mean success on random out-of-distribution scenarios without randomized action supervision during training.
- The same architecture yields 77.5 percent mean success across four real dual-arm tasks of varying difficulty.
- Value estimation can simultaneously track task progress and flag execution deviations for autonomous rollback.
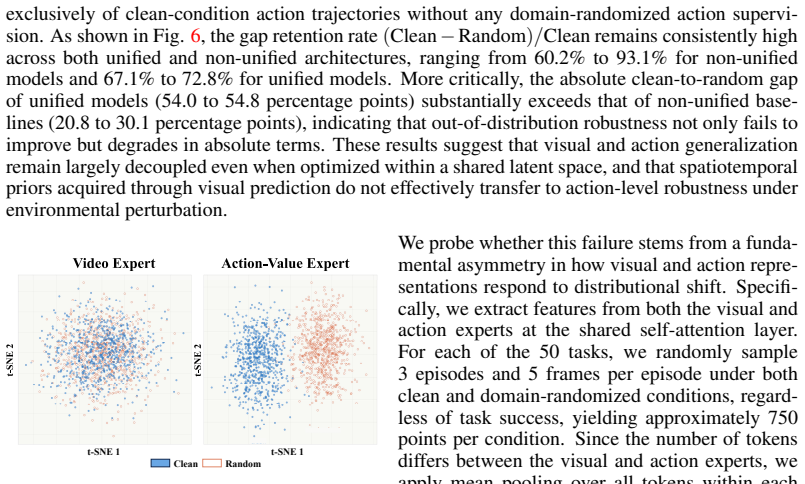
- Explicit handling of manifold heterogeneity stabilizes joint video-action training under distribution shift.
Where Pith is reading between the lines
- The same masking and manifold-aware loss could be applied to other sequence models that combine heterogeneous data streams, such as language and sensor readings.
- If the manifold mismatch dominates generalization failure, extending the value regulator to longer horizons would require tighter coupling between the video predictor and the value head to prevent accumulated drift.
- The approach may reduce the need for domain randomization in real-robot training by making the policy more tolerant of visual-action misalignment.
Load-bearing premise
The performance gap in out-of-distribution scenarios is caused primarily by a structural mismatch between visual and action manifolds whose joint optimization harms action robustness, and the proposed mask and scheme close this gap without introducing new failure modes.
What would settle it
An ablation that keeps every other component fixed but removes only the manifold-aware optimization and cross-modality causal mask, then measures whether success rate on random RoboTwin scenarios falls back to the strongest baseline level.
Figures






read the original abstract
Achieving robust and generalizable manipulation across diverse environments remains a fundamental challenge in embodied robotics. Recent world action models achieve strong in-domain performance, yet their gains do not extend proportionally to out-of-distribution scenarios. We attribute this to a structural mismatch between visual and action modalities, whose intrinsically heterogeneous manifolds cause joint optimization to disproportionately degrade action robustness under distribution shift. To address this, we propose MV-WAM, a novel end-to-end framework that jointly models visual prediction, action generation, and value estimation designed to effectively leverage video priors during both training and inference for enhanced action generalization. Key to this unification is a cross-modality causal mask that hierarchically grounds actions in predicted video frames and value function tokens in both modalities. To further narrow the generalization gap, MV-WAM adopts a manifold-aware optimization scheme that explicitly accounts for the structural heterogeneity across modalities. Finally, MV-WAM introduces a progress-value regulation mechanism that estimates task completion and detects misalignment between predicted frames and generated actions, enabling the policy to autonomously identify execution deviations and recover through value-guided rollback. On the RoboTwin simulation, MV-WAM achieves a 55.7% mean success rate on random scenarios without any randomized action supervision, outperforming the strongest baseline by 29.3%. MV-WAM achieves a 77.5% mean success rate across four real-world tasks of varying difficulty on a dual-arm robot. Our results demonstrate that manifold-aware cross-modal alignment is essential for robust policy generalization, offering a path toward deployable robotic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MV-WAM, an end-to-end world action model for robotic manipulation that jointly performs visual prediction, action generation, and value estimation. It introduces a cross-modality causal mask to hierarchically ground actions in predicted frames and value tokens, a manifold-aware optimization scheme to handle heterogeneous visual-action manifolds, and a progress-value regulation mechanism for detecting misalignment and enabling value-guided recovery. The central empirical claims are a 55.7% mean success rate on random RoboTwin scenarios (29.3% above the strongest baseline) without randomized action supervision and 77.5% mean success across four real-world dual-arm tasks, with gains attributed to manifold-aware cross-modal alignment.
Significance. If the reported performance gains are shown to follow from the proposed components via controlled ablations, the work could meaningfully advance cross-modal policy learning for out-of-distribution robustness in embodied robotics. The integration of value estimation for autonomous rollback is a potentially useful direction, but the absence of supporting experimental structure in the presented material limits assessment of its contribution.
major comments (2)
- [Abstract] Abstract: the claim that the 55.7% success rate and 29.3% improvement over baseline are due to the cross-modality causal mask, manifold-aware optimization, and progress-value regulation is presented without any ablation tables, baseline implementation details, or statistical controls; this attribution is load-bearing for the central generalization claim but cannot be evaluated from the given text.
- [Abstract] Abstract: the weakest assumption that OOD gaps arise primarily from visual-action manifold mismatch (and are closed by the proposed scheme without new failure modes) receives no supporting analysis, failure-mode breakdown, or comparison to alternative explanations such as data leakage or baseline under-training.
minor comments (1)
- [Abstract] Abstract: the term 'random scenarios' is used without definition of sampling procedure, number of trials, or variance reporting, which affects reproducibility of the reported means.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger experimental support for our central claims. We address each major comment below and commit to revisions that provide the requested ablations, details, and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the 55.7% success rate and 29.3% improvement over baseline are due to the cross-modality causal mask, manifold-aware optimization, and progress-value regulation is presented without any ablation tables, baseline implementation details, or statistical controls; this attribution is load-bearing for the central generalization claim but cannot be evaluated from the given text.
Authors: We agree that the abstract makes a strong attribution without sufficient visible support in the provided text. The full manuscript contains ablation studies (Section 4.3) and baseline details (Appendix B), but these are not referenced in the abstract. We will revise the abstract to explicitly cite the ablation results, add statistical significance reporting (e.g., standard errors across seeds), and expand the experiments section with clearer baseline implementation details and controls. revision: yes
-
Referee: [Abstract] Abstract: the weakest assumption that OOD gaps arise primarily from visual-action manifold mismatch (and are closed by the proposed scheme without new failure modes) receives no supporting analysis, failure-mode breakdown, or comparison to alternative explanations such as data leakage or baseline under-training.
Authors: We acknowledge that the manuscript does not currently include dedicated analysis of this assumption or comparisons to alternatives. We will add a new subsection on failure modes (including cases of misalignment and rollback) and quantitative comparisons ruling out data leakage or baseline under-training (e.g., by reporting baseline training curves and data overlap metrics). This will directly address whether the gains stem from the proposed manifold-aware components. revision: yes
Circularity Check
No derivation chain or equations present; empirical performance claims cannot exhibit circularity by construction.
full rationale
The provided abstract and context contain no mathematical derivations, equations, or first-principles steps that could reduce to fitted inputs, self-citations, or ansatzes. All central claims are empirical success rates on RoboTwin and real-robot tasks, with attribution to architectural components (cross-modality causal mask, manifold-aware optimization, progress-value regulation). These are testable via ablation or replication and do not match any of the enumerated circularity patterns. The reader's note that no derivations are shown confirms the absence of a chain to inspect. Score 0 is the appropriate default when the paper is self-contained against external benchmarks and makes no reductionist claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structural mismatch between visual and action modalities causes joint optimization to disproportionately degrade action robustness under distribution shift
invented entities (3)
-
cross-modality causal mask
no independent evidence
-
manifold-aware optimization scheme
no independent evidence
-
progress-value regulation mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 2
Pith/arXiv arXiv 2023
-
[2]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022. 2, 14
2022
-
[3]
Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025. 2, 14
Pith/arXiv arXiv 2025
-
[4]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, et al. pi0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 7, 9, 10, 14, 18
Pith/arXiv arXiv 2024
-
[5]
Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022. 2, 14
Pith/arXiv arXiv 2022
-
[6]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025. 14 10
Pith/arXiv arXiv 2025
-
[7]
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024. 2
Pith/arXiv arXiv 2024
-
[8]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025. 3, 7
Pith/arXiv arXiv 2025
-
[9]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025. 7, 14, 18
2025
-
[10]
Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, Weishi Mi, Kevin Zhang, Zhiyuan Qin, Wanxin Tian, Kuangzhi Ge, Hao Li, et al. Wow: Towards a world omniscient world model through embodied interaction.arXiv preprint arXiv:2509.22642, 2025. 2, 4, 6
arXiv 2025
-
[11]
Unimax: Fairer and more effective language sampling for large-scale multilingual pretraining
Hyung Won Chung, Noah Constant, Xavier Garcia, Adam Roberts, Yi Tay, Sharan Narang, and Orhan Firat. Unimax: Fairer and more effective language sampling for large-scale multilingual pretraining. InInternational Conference on Learning Representations, 2023. 4
2023
-
[12]
Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023. 2, 14
Pith/arXiv arXiv 2023
-
[13]
Tenenbaum, Dale Schu- urmans, and Pieter Abbeel
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schu- urmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. In Advances in Neural Information Processing Systems (NeurIPS), 2023. 2
2023
-
[14]
A taxonomy for evaluating generalist robot manipulation policies.IEEE Robotics and Automation Letters, 2025
Jensen Gao, Suneel Belkhale, Sudeep Dasari, Ashwin Balakrishna, Dhruv Shah, and Dorsa Sadigh. A taxonomy for evaluating generalist robot manipulation policies.IEEE Robotics and Automation Letters, 2025. 2
2025
-
[15]
World models.arXiv preprint arXiv:1803.10122, 2(3):440,
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440,
-
[16]
Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019. 2
Pith/arXiv arXiv 1912
-
[17]
Ryan Hoque, Peide Huang, David J Yoon, Mouli Sivapurapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025. 14
Pith/arXiv arXiv 2025
-
[18]
Junjun Hu, Jintao Chen, Haochen Bai, Minghua Luo, Shichao Xie, Ziyi Chen, Fei Liu, Zedong Chu, Xinda Xue, Botao Ren, et al. Astranav-world: World model for foresight control and consistency.arXiv preprint arXiv:2512.21714, 2025. 2
Pith/arXiv arXiv 2025
-
[20]
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024. 14
Pith/arXiv arXiv 2024
-
[21]
Yucheng Hu, Jianke Zhang, Yuanfei Luo, Yanjiang Guo, Xiaoyu Chen, Xinshu Sun, Kun Feng, Qingzhou Lu, Sheng Chen, Yangang Zhang, et al. Bagelvla: Enhancing long-horizon manip- ulation via interleaved vision-language-action generation.arXiv preprint arXiv:2602.09849,
-
[22]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, et al.π 0.5: a vision-language-action model with open-world generalization, 2025. 14 11
2025
-
[23]
Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998. 3
1998
-
[24]
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026. 6
Pith/arXiv arXiv 2026
-
[25]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 2, 14
Pith/arXiv arXiv 2024
-
[26]
Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026. 2
Pith/arXiv arXiv 2026
-
[27]
Weixin Liang, Lili Yu, Liang Luo, Srinivasan Iyer, Ning Dong, Chunting Zhou, Gargi Ghosh, Mike Lewis, Wen-tau Yih, Luke Zettlemoyer, et al. Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models.arXiv preprint arXiv:2411.04996,
-
[28]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 3
Pith/arXiv arXiv 2022
-
[29]
Hybridvla: Collaborative diffusion and autore- gression in a unified vision-language-action model.ICLR, 2025
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autore- gression in a unified vision-language-action model.ICLR, 2025. 14
2025
-
[30]
Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024. 3, 7, 9, 10, 18
Pith/arXiv arXiv 2024
-
[31]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration
-
[32]
In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 14
2021
-
[34]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, pages 8748–8763, 2021. 2
2021
-
[35]
Krisanu Sarkar. Learning beyond euclid: Curvature-adaptive generalization for neural net- works on manifolds.arXiv preprint arXiv:2507.02999, 2025. 4, 17
arXiv 2025
-
[36]
Learning generalizable manipulation policies with object-centric 3d representations
Xiaofeng Shi, Zhenjia Xu, Zhiyuan Wang, and Katerina Fragkiadaki. Learning generalizable manipulation policies with object-centric 3d representations. InConference on Robot Learn- ing, 2023. 2
2023
-
[37]
Quanxin Shou, Fangqi Zhu, Shawn Chen, Puxin Yan, Zhengyang Yan, Yikun Miao, Xi- aoyi Pang, Zicong Hong, Ruikai Shi, Hao Huang, et al. Halo: A unified vision- language-action model for embodied multimodal chain-of-thought reasoning.arXiv preprint arXiv:2602.21157, 2026. 7, 14, 18
arXiv 2026
-
[38]
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Pre- dictive inverse dynamics models are scalable learners for robotic manipulation.arXiv preprint arXiv:2412.15109, 2024. 2 12
Pith/arXiv arXiv 2024
-
[39]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Al- abdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multilingual vision- language encoders with improved semantic understanding, localization, and dense features....
Pith/arXiv arXiv 2025
-
[40]
Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chaomin Shen, et al. Diffusion-vla: Scaling robot foundation models via unified diffusion and autoregression.arXiv preprint arXiv:2412.03293, 2024. 14
arXiv 2024
-
[41]
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation.arXiv preprint arXiv:2412.13877, 2024. 14
Pith/arXiv arXiv 2024
-
[42]
Shihan Wu, Xuecheng Liu, Shaoxuan Xie, Pengwei Wang, Xinghang Li, Bowen Yang, Zhe Li, Kai Zhu, Hongyu Wu, Yiheng Liu, et al. Robocoin: An open-sourced bimanual robotic data collection for integrated manipulation.arXiv preprint arXiv:2511.17441, 2025. 14
Pith/arXiv arXiv 2025
-
[43]
Learning interactive real-world simulators
Sherry Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. InInternational Conference on Learning Representations (ICLR), 2024. 2
2024
-
[44]
Yandan Yang, Shuang Zeng, Tong Lin, Xinyuan Chang, Dekang Qi, Junjin Xiao, Haoyun Liu, Ronghan Chen, Yuzhi Chen, Dongjie Huo, et al. Abot-m0: Vla foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026. 2
Pith/arXiv arXiv 2026
-
[45]
World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. 2
Pith/arXiv arXiv 2026
-
[46]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. InAdvances in Neural Information Processing Systems, volume 33, pages 5824–5836, 2020. 2
2020
-
[47]
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026. 2, 7, 14, 18
Pith/arXiv arXiv 2026
-
[48]
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent.arXiv preprint arXiv:2501.18867, 2025. 7, 14, 18
arXiv 2025
-
[49]
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained biman- ual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023. 14
Pith/arXiv arXiv 2023
-
[50]
Irasim: Learning interactive real-robot action simulators.arXiv preprint arXiv:2406.14540, 2024
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. Irasim: Learning interactive real-robot action simulators.arXiv preprint arXiv:2406.14540, 2024. 2 13 A Related Work Vision-Language-Action Models.Early imitation learning approaches such as ACT [48] and Dif- fusion Policy [9] demonstrated the effectiveness of expressive policy arc...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.