T1-Bench: Benchmarking Multi-Scenario Agents in Real-World Domains
Pith reviewed 2026-06-27 13:04 UTC · model grok-4.3
The pith
T1-Bench introduces a benchmark for agentic systems that spans 25 domains with interleaved multi-turn scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
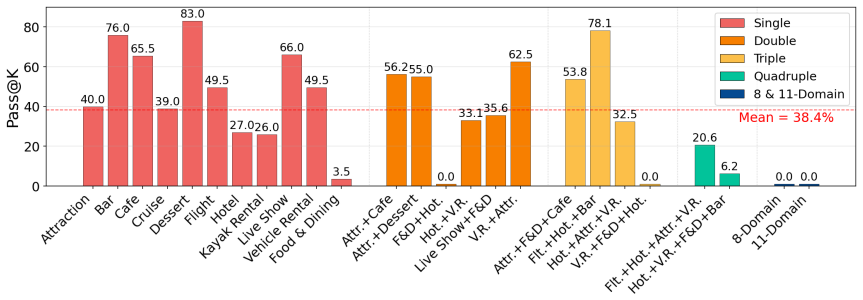
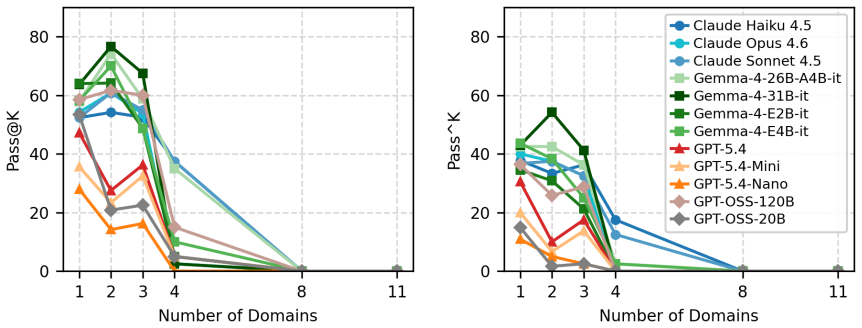
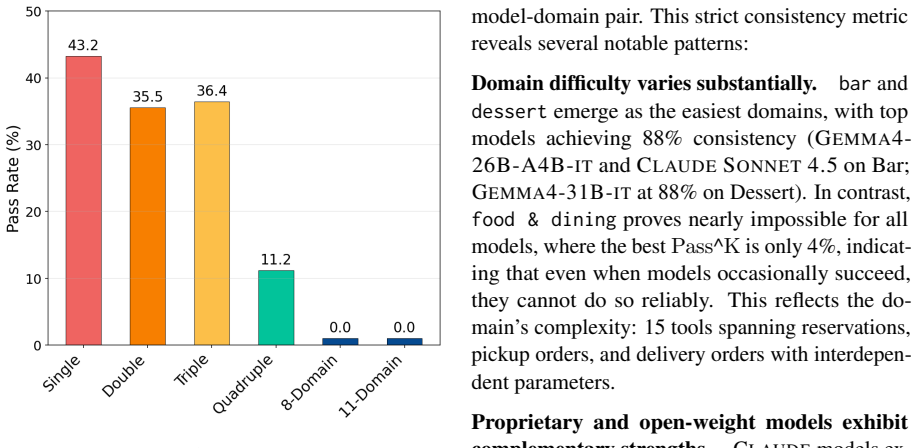
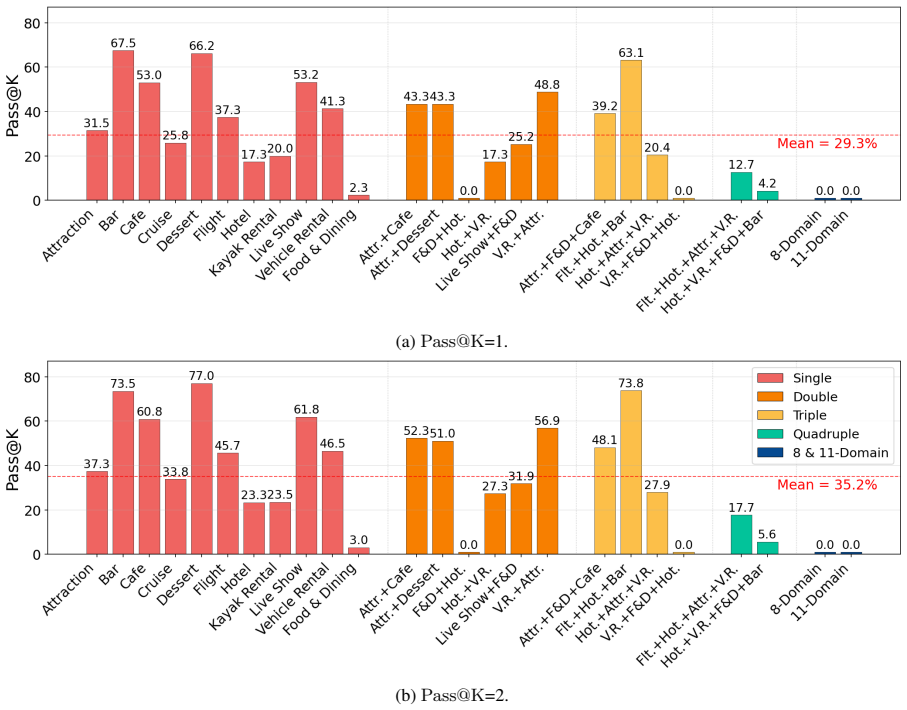
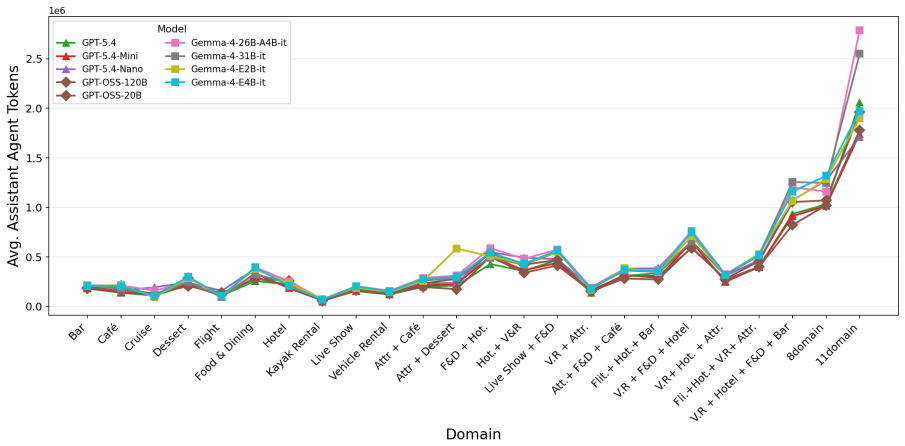
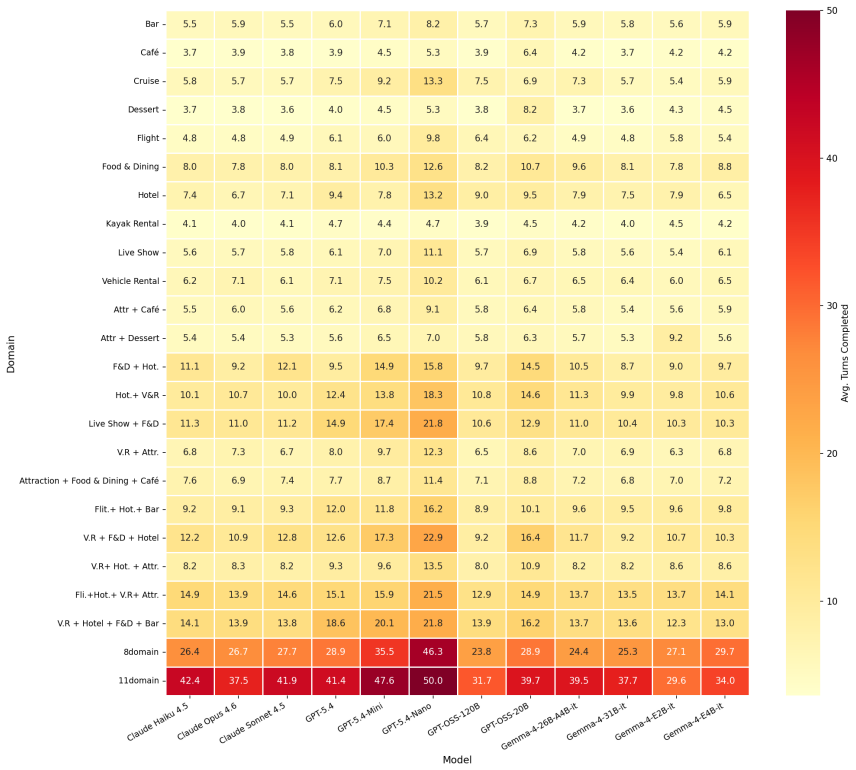
T1-Bench is a high-fidelity benchmark featuring interleaved scenarios across twenty-five domains of varying difficulty that require structured reasoning in multi-turn user-assistant interactions, advancing prior benchmarks by increasing compositional complexity, interaction depth, and domain coverage in simulated multi-domain environments.
What carries the argument
T1-Bench benchmark of interleaved multi-domain scenarios that tests agent behavior, tool utilization, and conversational quality.
If this is right
- Agents must demonstrate sustained reasoning and coordination across multiple domains in a single session.
- The benchmark supplies a standardized, reproducible way to compare tool use and conversational quality.
- Automatic metrics are supplemented by human judgments for qualitative assessment.
- Public release of data and evaluation code enables broader community use.
Where Pith is reading between the lines
- Widespread adoption could shift agent development toward systems that handle domain switches without losing context.
- The benchmark may expose gaps in current models' ability to maintain long-horizon plans across unrelated tasks.
- Designers of future benchmarks could adapt the interleaved-scenario structure to non-customer domains such as technical support or research assistance.
Load-bearing premise
The simulated multi-domain environments accurately reflect the demands of real-world customer-facing interactions.
What would settle it
Models that score highest on T1-Bench perform poorly when deployed in live customer service systems.
Figures



















read the original abstract
Recent advances in reasoning and tool-calling capabilities of large language models (LLMs) have enabled increasingly capable agentic systems. However, existing benchmarks remain limited in task complexity, realism, and domain diversity, and often fail to capture interactions that span multiple domains, limiting their ability to evaluate agents in realistic multi-step settings that require sustained reasoning and coordination. To address these limitations, we introduce T1-Bench, a high-fidelity, comprehensive benchmark for evaluating agentic systems in realistic customer-facing, multi-domain environments, featuring interleaved scenarios that require structured reasoning across multi-turn user-assistant interactions and substantially increasing both compositional complexity and evaluative rigor across 25 domains of varying difficulty. We evaluate T1-Bench using 12 proprietary and open-weight models, providing a reproducible and standardized framework for assessing agent behavior, tool utilization, and conversational quality in complex, multi-step environments. We further complement automatic evaluation with human judgments to strengthen the assessment of qualitative performance. Overall, T1-Bench substantially advances prior benchmarks by increasing task complexity, interaction depth, and domain coverage in simulated multi-domain environments. To facilitate future research on agentic systems, we will publicly release data and evaluation code as open source.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
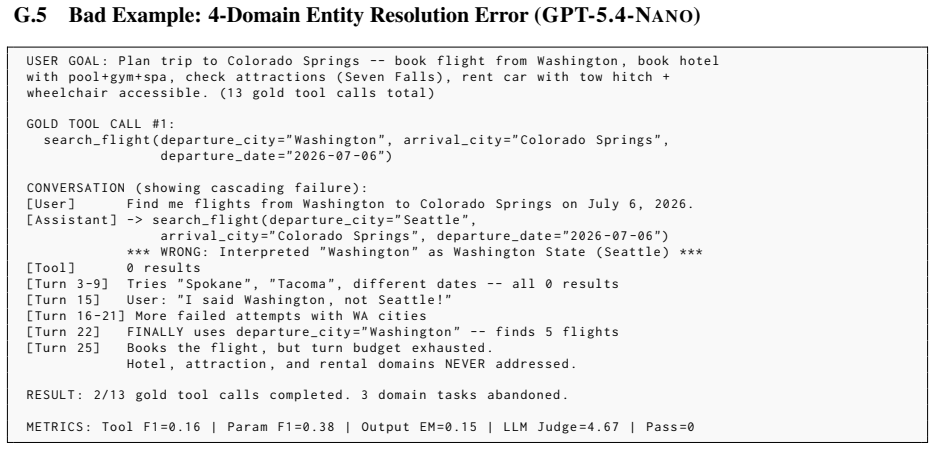
Summary. The paper introduces T1-Bench, a benchmark for agentic LLM systems consisting of interleaved multi-domain scenarios across 25 domains of varying difficulty. It claims to increase task complexity, interaction depth, and domain coverage relative to prior work by using expert-designed or LLM-generated tasks in simulated customer-facing environments. The authors evaluate 12 proprietary and open-weight models on tool utilization, conversational quality, and structured reasoning, supplementing automatic metrics with human judgments, and state they will release data and evaluation code.
Significance. A benchmark that genuinely raises the bar on multi-turn, cross-domain agent evaluation could help standardize assessment of sustained reasoning and coordination. The commitment to public release of data and code supports reproducibility. However, the significance is limited by the absence of evidence that the simulated environments match real customer interaction demands.
major comments (1)
- [Abstract] Abstract: The central claim that T1-Bench 'substantially advances prior benchmarks by increasing task complexity, interaction depth, and domain coverage in simulated multi-domain environments' and features 'high-fidelity' and 'realistic' environments rests on an untested assumption. No metrics are reported that validate fidelity (e.g., correlation between observed agent failure modes and real customer logs, human ratings of scenario realism, or pilot comparisons with deployed systems). This leaves the 'realistic multi-step settings' premise unsupported and makes the advance claim dependent on construction details whose realism is not demonstrated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the concern regarding the validation of the simulated environments' realism below.
read point-by-point responses
-
Referee: The central claim that T1-Bench 'substantially advances prior benchmarks by increasing task complexity, interaction depth, and domain coverage in simulated multi-domain environments' and features 'high-fidelity' and 'realistic' environments rests on an untested assumption. No metrics are reported that validate fidelity (e.g., correlation between observed agent failure modes and real customer logs, human ratings of scenario realism, or pilot comparisons with deployed systems). This leaves the 'realistic multi-step settings' premise unsupported and makes the advance claim dependent on construction details whose realism is not demonstrated.
Authors: We acknowledge that the manuscript does not report quantitative validation metrics, such as correlations with real customer logs or dedicated human ratings of scenario realism. The description of the environments as realistic is grounded in their design as simulated customer-facing scenarios with tasks created by experts or LLMs across 25 domains. However, to strengthen the manuscript and align claims with presented evidence, we will revise the abstract to qualify the language, removing 'high-fidelity' and tempering 'realistic' to 'simulated multi-domain' environments designed to reflect customer interactions. We will also add a limitations section discussing the lack of direct real-world validation. revision: yes
Circularity Check
No circularity; benchmark paper contains no derivations or fitted predictions
full rationale
The paper is a benchmark introduction with no equations, predictions, or first-principles derivations. Its central claim—that T1-Bench advances prior work by increasing task complexity, interaction depth, and domain coverage—is presented as a direct consequence of the authors' explicit design decisions (25 domains, interleaved multi-domain scenarios, human+automatic evaluation), not as a result derived from or fitted to prior data or self-cited theorems. No self-definitional, fitted-input, or self-citation-load-bearing steps appear; the realism assumption is an untested modeling choice but does not create circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Towards Scalable Customization and Deployment of Multi-Agent Systems for Enterprise Applications
A two-stage framework for domain-adapting multi-agent LLMs and optimizing their inference claims a 4.48x throughput gain with maintained performance on enterprise tasks.
Reference graph
Works this paper leans on
-
[1]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan
Sparkme: Adaptive semi-structured interview- ing for qualitative insight discovery.arXiv preprint arXiv:2602.21136. Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. 2025. $\tau^2$-bench: : Evaluating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982. Amartya Chakraborty, Paresh Dashore, Nadia Bath...
arXiv 2025
-
[2]
Swe-smith: Scaling data for software engineer- ing agents.Advances in Neural Information Process- ing Systems, 38. Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R Narasimhan. 2025. {$\tau$}-bench: A benchmark for \underline{T}ool-\underline{A}gent- \underline{U}ser interaction in real-world domains. InThe Thirteenth International Conference on Learn-...
arXiv 2025
-
[17]
Figure 6: System prompt configuration for the user agent for theBardomain
Always pass all arguments that are relevant to the tools . Figure 6: System prompt configuration for the user agent for theBardomain. 25 F.2 Example Assistant Prompt:Bars CRITICAL DIRECTIVES FOR TOOL EXECUTION = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = =
-
[18]
You are strictly forbidden from recommending places from your training data
YOU HAVE NO INTERNAL KNOWLEDGE OF REAL ESTABLISHMENTS . You are strictly forbidden from recommending places from your training data
-
[19]
This is a fatal error
DO NOT HALLUCINATE fake names or real names like Double Chicken Please , Angels Share . This is a fatal error
-
[20]
Let me check
NEVER SAY " Let me check " , " I am fetching ..." , or " Here are some options ...". If you need to search , your IMMEDIATE AND ONLY output must be a TOOL CALL . Do not output conversational text when a tool call is required
-
[21]
You MUST call`search_bars`EVERY SINGLE TIME the user asks for recommendations unless there are already relevant cached results that can be filtered
-
[22]
If the tool has not returned data yet , DO NOT make up a table
ONLY output a markdown table of results IF AND ONLY IF you have just received a successful JSON response from a tool call . If the tool has not returned data yet , DO NOT make up a table . - When a search or filter tool returns multiple results , you MUST display ALL of them in the table . Never truncate , summarize , or show only a subset -- the user nee...
-
[23]
Always rely on tool calls to respond to the user , and do not simply repeat results shown previously to the user without calling the appropriate tool first
-
[24]
Wait for the tool to return data before speaking to the user
SILENT TOOL CALLS : When you are initiating a tool call , your text output MUST be completely empty . Wait for the tool to return data before speaking to the user
-
[25]
- Do NOT call`filter_bars`if the new filtering criteria do not directly apply to the existing result set and require a separate search
USE FILTER_BARS FOR FOLLOW - UPS : - If you have already run`search_bars`in a previous turn , and the user asks to narrow down those specific results , you MUST use the`filter_bars`tool . - Do NOT call`filter_bars`if the new filtering criteria do not directly apply to the existing result set and require a separate search . - Do NOT run a brand - new`searc...
-
[26]
5 flights from NYC to LAX on 2025 -06 -01
CACHE USAGE -- Check the CURRENT CACHE SUMMARY provided in each prompt . Each key maps to a human - readable summary of what was saved ( e . g . , "5 flights from NYC to LAX on 2025 -06 -01") . Only call`get_results_from_cache`if the cache summary shows a relevant key . If the cache is empty or has no relevant key , do NOT call`get_results_from_cache`; go...
2025
-
[27]
Ask for bars in New Orleans that have happy hour
-
[28]
After seeing the results , narrow them down to places that offer a budget of up to $75 per person , using the results from the previous search
-
[29]
CRITICAL RULES :
After seeing the filtered results , say you need some time to think about it and end the conversation without making a booking . CRITICAL RULES :
-
[30]
Never offer to help
Act exactly like a human customer in a live chat interface . Never offer to help
-
[31]
Dear ") , or sign - offs ( e . g . ,
Avoid subject lines , greetings ( e . g . , " Dear ") , or sign - offs ( e . g . , " Sincerely ") . Keep responses to 1 -3 sentences , like a casual text message
-
[32]
Stay strictly within scope : only ask about features explicitly defined in the Bar Properties schema ( e . g . , has_pool_tables , has_live_music , has_valet_parking , price_level ) . Do not ask about features outside this schema
-
[33]
If the assistant provides a list of options , do not end the conversation - - select one and continue
-
[34]
Pace the conversation carefully : you have a maximum of 25 turns to achieve your goal
-
[35]
If options are limited , choose one rather than prolonging negotiation
Be decisive . If options are limited , choose one rather than prolonging negotiation . Do not go beyond your goal
-
[36]
Always speak the way a real person would text in a casual chat -- never like someone reading instructions out loud
Use natural , human - like phrasing . Always speak the way a real person would text in a casual chat -- never like someone reading instructions out loud . Follow the intent of your user template , but rephrase everything in your own natural voice : use contractions , everyday vocabulary , and the tone of a regular customer . Do not echo schema or field na...
-
[37]
Give the date in the form MM DD , YYYY
Anytime you are listing any dates , ensure you use natural language format . Give the date in the form MM DD , YYYY . MM is in word and DD is a number ( e . g . , March 1 , 2021)
2021
-
[38]
Finish the conversation as fast as possible ; do not go beyond the GOAL
-
[39]
If you are asking a question , ask it once
-
[40]
Always pay with the first registered credit card
-
[41]
should_end
Always pass all arguments that are relevant to the tools . CONVERSATION SO FAR : { history_text } Has the user fully completed their stated goal AND naturally concluded the conversation ( e . g . , said thanks / bye , or confirmed the booking / order / reservation is done ) ? If they still asked questions , do not end the conversation . Reply with a JSON ...
2026
-
[42]
Harrisburg
search_flight ( departure_city =" Harrisburg " , arrival_city =" Portland " , airline =[" CloudNine Air "] , departure_date ="2026 -05 -30") CONVERSATION : [ Assistant ] Hello ! Welcome to Flight Assistant . How can I help you ? [ User ] I'm looking for a flight from Harrisburg to Portland on May 30 , 2026. I'd like to fly with CloudNine Air if possible ....
2026
-
[43]
New York
search_flight ( departure_city =" New York " , arrival_city =" Denver " , departure_date ="2026 -06 -11" , ticket_class =" Business ")
2026
-
[44]
s e a r c h _ f l i g h t _ r e s u l t s _ 0
filter_flight ( cache_key =" s e a r c h _ f l i g h t _ r e s u l t s _ 0 " , d e p a r t u r e _ t i m e _ a f t e r ="07:00")
-
[45]
Denver
search_hotel ( city =" Denver " , has_gym = true )
-
[46]
s e a r c h _ h o t e l _ r e s u l t s _ 0
filter_hotel ( cache_key =" s e a r c h _ h o t e l _ r e s u l t s _ 0 " , has_digital_key = true )
-
[47]
f i l t e r _ h o t e l _ r e s u l t s _ 0
filter_hotel ( cache_key =" f i l t e r _ h o t e l _ r e s u l t s _ 0 " , h a s _ e l e c t r i c _ v e h i c l e _ c h a r g i n g = true )
-
[48]
Denver
g e t _ t o p _ a t t r a c t i o n s ( city =" Denver ")
-
[49]
Denver
s e a r c h _ v e h i c l e _ r e n t a l s ( city =" Denver " , category =" car ")
-
[50]
s e a r c h _ v e h i c l e _ r e n t a l s _ r e s u l t s _ 0
f i l t e r _ v e h i c l e _ r e n t a l s ( cache_key =" s e a r c h _ v e h i c l e _ r e n t a l s _ r e s u l t s _ 0 " , is_automatic = true )
-
[51]
f i l t e r _ v e h i c l e _ r e n t a l s _ r e s u l t s _ 0
f i l t e r _ v e h i c l e _ r e n t a l s ( cache_key =" f i l t e r _ v e h i c l e _ r e n t a l s _ r e s u l t s _ 0 " , h a s _ i n s u r a n c e _ i n c l u d e d = true ) CONVERSATION ( abbreviated ) : [ User ] Business flights from New York to Denver on June 11 , 2026. [ Asst ] -> search_flight (...) | 1 result : FL129 , Jetline , $375 .99 [ Use...
2026
-
[52]
Panama City
search_flight ( departure_city =" Panama City " , arrival_city =" St . Louis " , departure_date ="2026 -05 -19" , airline =[" Blue River Air "])
2026
-
[53]
USR -8 CF0E436
book_flight ( user_id =" USR -8 CF0E436 " , flight_id =" FL535 " , passenger_names =[" Jennifer Smith "] , n umb er _p as sen ge rs =1 , c r e d i t _ c a r d _ l a s t _ f o u r ="3993" , ...) CONVERSATION : [ User ] I'm looking for a flight from Panama City to St . Louis on May 19. [ Assistant ] What departure date and ticket class ? [ User ] May 19 , 2...
2026
-
[54]
Alaska
search_cruises ( destination =" Alaska " , departure_port =" Seattle " , cabin_type =" balcony " , p r i c e _ p e r _ p e r s o n _ m a x =6000)
-
[55]
CR000151
b o o k _ c r u i s e _ r e s e r v a t i o n ( cruise_id =" CR000151 " , number_guests =2 , ...) CONVERSATION (21 failed attempts ) : [ User ] I'm looking for a cruise to Alaska from Seattle . [ Assistant ] -> search_cruises ( destination =" Alaska " , departure_port =" Seattle " , duration_nights =[] , tier =2 , cabin_type =" balcony ") *** HALLUCINATED...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.