AI translation of literary texts is "fine", but readers still prefer human translations
Pith reviewed 2026-06-25 19:16 UTC · model grok-4.3
The pith
Readers prefer human literary translations over AI versions for ease, clarity and immersion, even when they cannot tell them apart.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
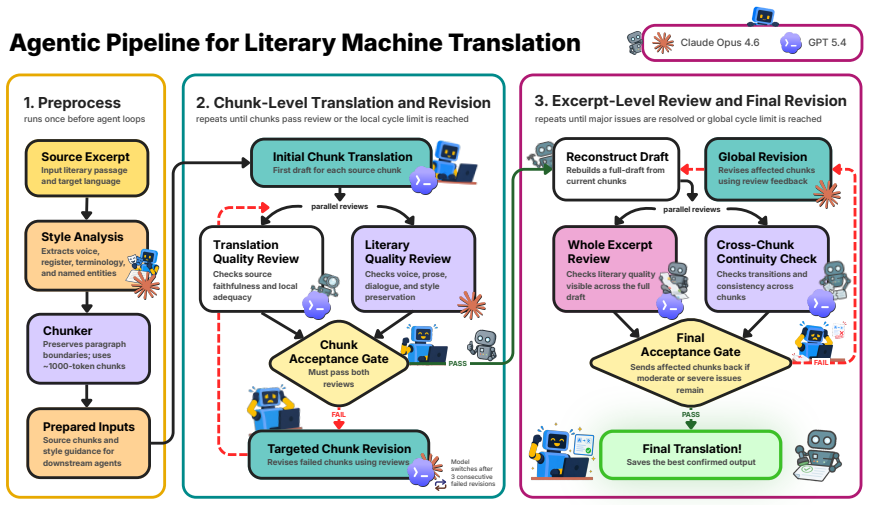
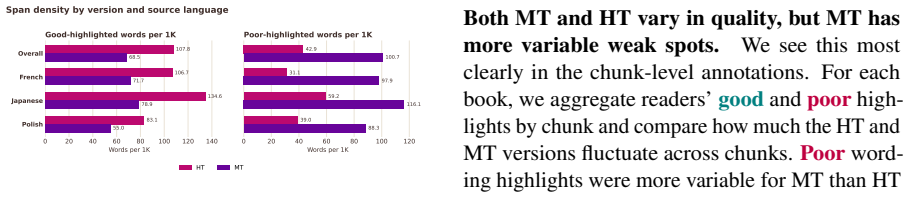
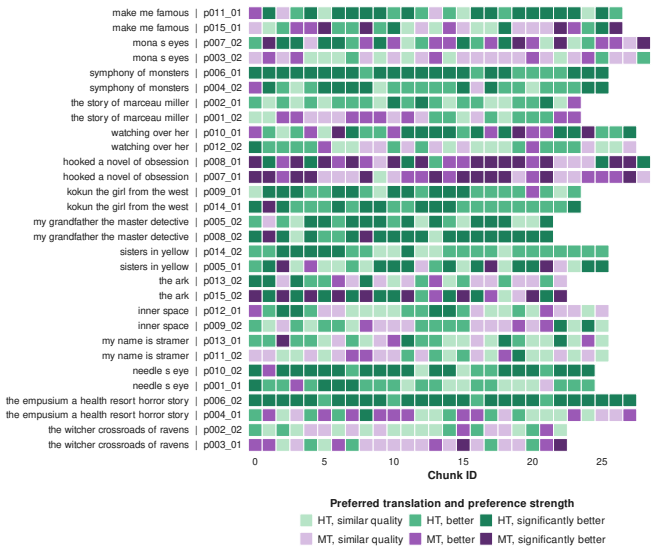
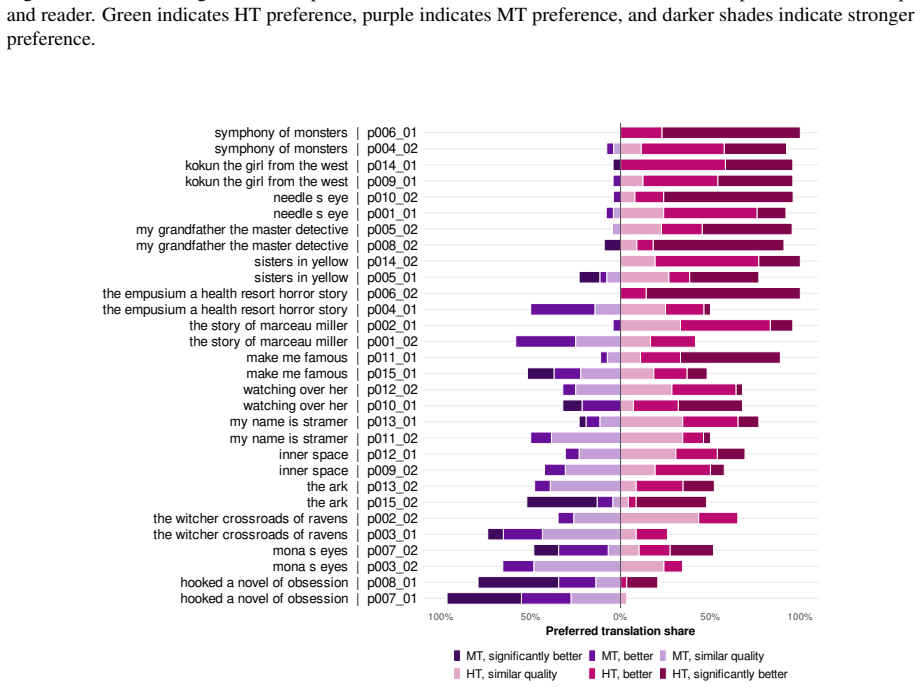
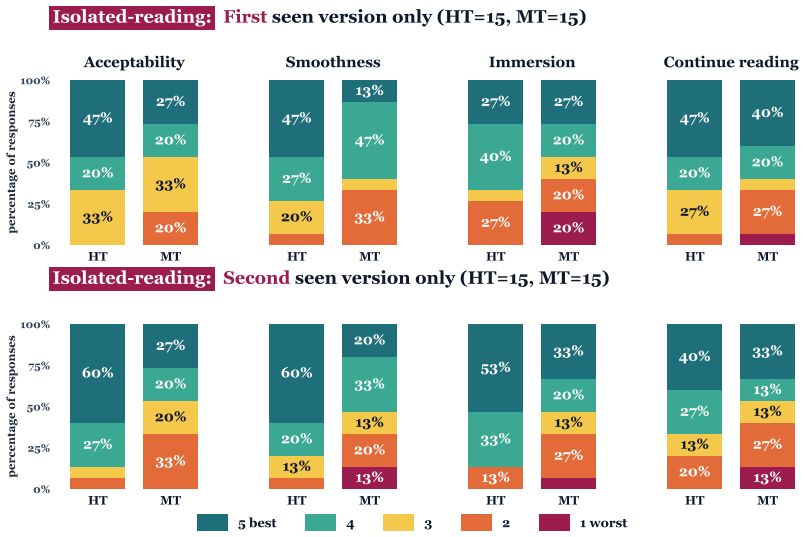
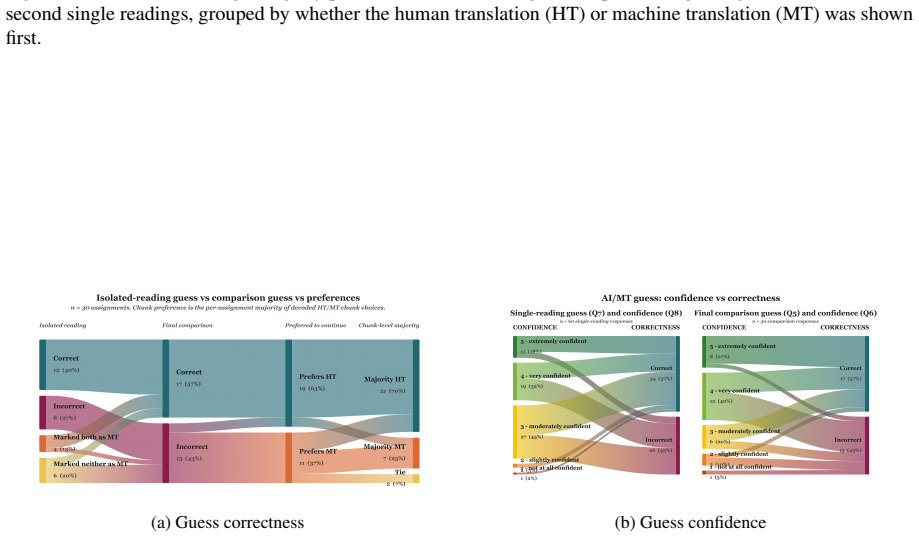
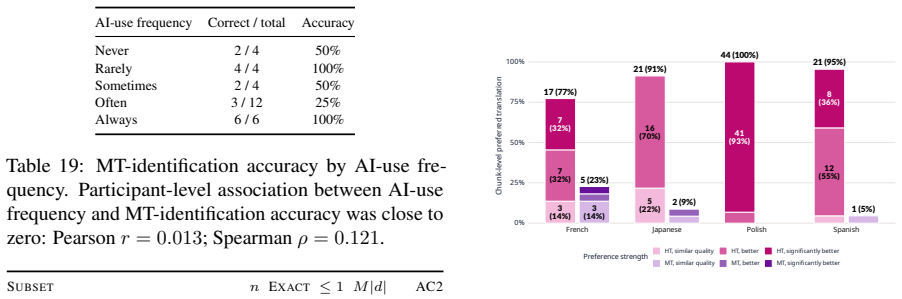
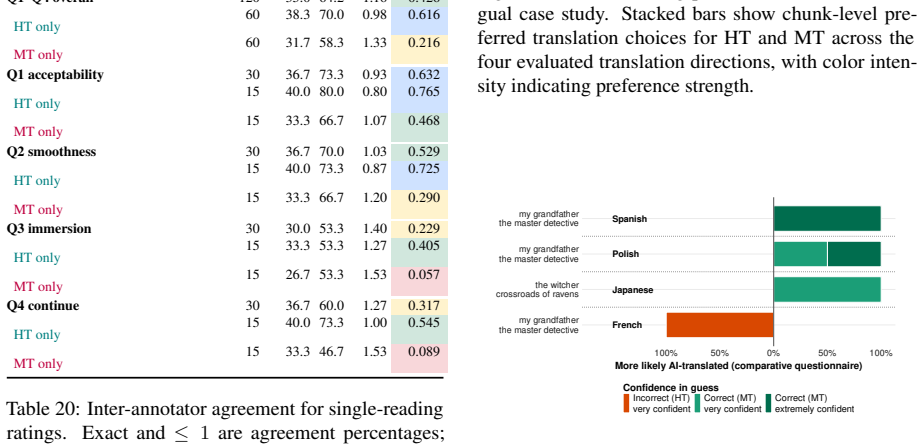
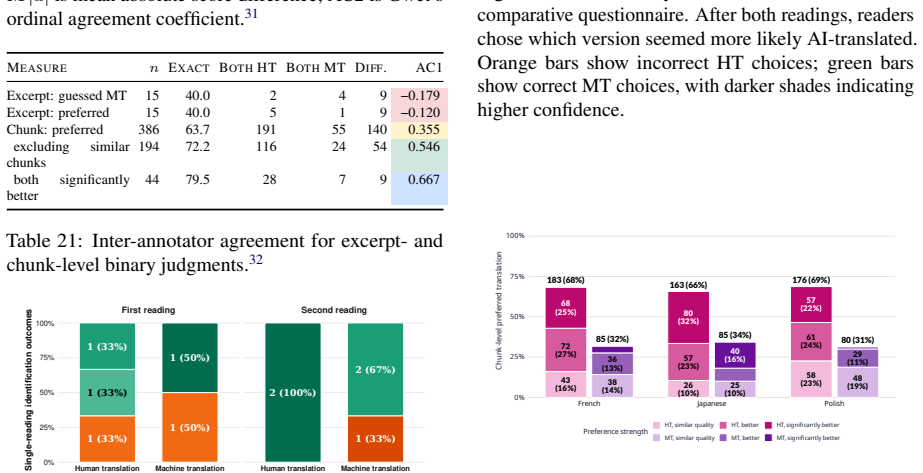
Across 30 excerpt-level comparisons and 772 chunk-level comparisons, readers favored the human translations 19/30 and 522/772 times respectively, describing them as easier, clearer, and more immersive. They identified the human version correctly only 17 times out of 30 and showed a tendency to prefer whichever text they believed to be human. Machine translations displayed greater internal quality variation than human ones. Standard automatic metrics, including LLM-as-a-judge methods, did not recover the reader preferences and instead favored the machine output.
What carries the argument
A controlled reader study protocol that collects preferences, source guesses, and span annotations from immersive full-excerpt reading and from close examination of aligned human-machine text chunks.
Load-bearing premise
The agentic LLM pipeline used to produce the machine translations stands in for current best AI literary translation, and the judgments of these 15 readers apply beyond the tested books and languages.
What would settle it
A replication using a different leading LLM pipeline or a larger and more diverse set of readers that finds equal or higher preference for the machine translations would falsify the reported preference pattern.
Figures



















read the original abstract
AI translation of literary works is increasingly common. While the content may be rendered adequately, we do not know enough about how readers experience it in terms of immersiveness and literary effect, aspects poorly captured by automatic machine translation metrics or human evaluation targeting fluency and adequacy. We ask 15 avid readers to compare recently published human translations (HT) to machine translations (MT) generated with an agentic large language model (LLM)-based pipeline, for 15 recent novels in French, Polish, and Japanese and translated into English. Readers evaluated approximately 8K-word excerpts in two conditions: immersive reading of the whole excerpt (30 comparisons) and close reading of 386 aligned HT-MT chunk pairs (772 comparisons), with two readers per book and in alternating order of presentation. Overall, readers find MT "fine", but prefer HT (slightly at excerpt-level 19/30, more clearly at chunk-level 522/772) for its ease, clarity, and immersive nature. Readers' highlights show that MT's quality varies more within one book than HT's does. Crucially, readers cannot reliably tell the two apart (17/30 guess correctly) and tend to prefer the version they believe to be human. Automatic metrics, including LLM-as-a-judge approaches, fail to recover reader preferences and favor MT. We release LAIT (Literary AI Translation), a reader-centered evaluation dataset with 1K reader comments, 2K judgments and preference ratings, and 7.2K span-level annotations, along with our evaluation protocol and supporting interface.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a human-subjects study in which 15 avid readers compared recently published human translations (HT) against machine translations (MT) generated by a single agentic LLM-based pipeline. The evaluation covers ~8K-word excerpts from 15 novels in French, Polish, and Japanese translated to English, using both immersive whole-excerpt reading (30 comparisons) and close reading of 386 aligned chunk pairs (772 comparisons). Readers rate MT as 'fine' but prefer HT (19/30 excerpt-level, 522/772 chunk-level) for ease, clarity, and immersiveness; they cannot reliably distinguish the two (17/30 correct guesses) and favor the version they believe is human. Automatic metrics, including LLM-as-judge, fail to recover these preferences. The authors release the LAIT dataset containing 1K reader comments, 2K judgments, and 7.2K span annotations together with the evaluation protocol.
Significance. If the reported preference patterns and indistinguishability result generalize, the work supplies concrete reader-centered evidence on literary aspects of translation quality that automatic metrics miss, together with a publicly released dataset that supports reproducibility and follow-on studies. The explicit contrast between excerpt-level and chunk-level judgments and the observation that MT quality varies more within books than HT does are useful empirical contributions.
major comments (1)
- [Abstract and Evaluation section] Abstract and Evaluation section: the central claims that readers prefer HT (19/30 and 522/772) yet cannot reliably distinguish MT from HT (17/30) rest on data from only 15 readers and a single agentic LLM pipeline. Because the paper itself notes that MT quality varies more within books than HT does, the absence of any comparison to alternative MT pipelines or a larger reader cohort makes the broader statements about AI versus human literary translation vulnerable to the specific implementation choices; this is load-bearing for the generalizability of the preference and indistinguishability results.
minor comments (3)
- [Abstract] Abstract: the description of chunk alignment, reader recruitment criteria, exact MT generation parameters, and any statistical testing of the reported counts is absent, hindering replication.
- [Abstract] Abstract: the alternating order of presentation is mentioned but no detail is given on how order effects or fatigue were controlled across the two readers per book.
- [Dataset release statement] Dataset release statement: while the LAIT dataset is a strength, the paper should specify the exact license, file formats, and whether the 7.2K span-level annotations include the original text spans or only offsets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to qualify claims about generalizability. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the central claims that readers prefer HT (19/30 and 522/772) yet cannot reliably distinguish MT from HT (17/30) rest on data from only 15 readers and a single agentic LLM pipeline. Because the paper itself notes that MT quality varies more within books than HT does, the absence of any comparison to alternative MT pipelines or a larger reader cohort makes the broader statements about AI versus human literary translation vulnerable to the specific implementation choices; this is load-bearing for the generalizability of the preference and indistinguishability results.
Authors: We agree that the modest reader sample and single pipeline constrain broad generalizations, and that the noted intra-book MT variation makes pipeline choice relevant. The study is framed as an initial reader-centered exploration using a current state-of-the-art agentic approach rather than a comprehensive survey of all MT systems. We will revise the abstract and Evaluation section to explicitly qualify the central claims as applying to the tested pipeline and cohort, while retaining the reported counts. We will also expand the Limitations section to discuss the implications of these design choices and the value of follow-up work with additional pipelines and larger reader groups. These textual changes will better align the stated scope with the data without requiring new experiments. revision: partial
Circularity Check
No circularity: empirical human-subjects study with direct observations
full rationale
This paper is a reader study reporting preference counts (19/30 excerpt-level, 522/772 chunk-level), indistinguishability rates (17/30), and qualitative comments from 15 participants evaluating fixed HT/MT pairs. These quantities are direct tallies of participant responses rather than quantities derived from equations, fitted parameters, or self-citations. No derivation chain exists; the central claims rest on the collected data itself, with no reduction of results to inputs by construction. The paper is self-contained against external benchmarks as a straightforward empirical evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Mike Allen. 2017. https://us.sagepub.com/en-us/nam/the-sage-encyclopedia-of-communication-research-methods/book244974 The SAGE encyclopedia of communication research methods . SAGE Publications, Inc, 2455 Teller Road, Thousand Oaks California 91320
2017
-
[3]
Amazon Staff . 2025. Amazon introduces Kindle Translate , an AI -powered translation service for authors to reach global readers. https://www.aboutamazon.com/news/books-and-authors/amazon-kindle-translate-books-authors. Accessed: 2026-05-22
2025
-
[6]
Antonio Castaldo, Sheila Castilho, Joss Moorkens, and Johanna Monti. 2025. https://aclanthology.org/2025.mtsummit-1.40/ Extending CREAMT : Leveraging large language models for literary translation post-editing . In Proceedings of Machine Translation Summit XX: Volume 1, pages 506--515, Geneva, Switzerland. European Association for Machine Translation
2025
-
[7]
Ella Creamer. 2024. https://www.theguardian.com/books/2024/nov/04/dutch-publisher-to-use-ai-to-translate-books-into-english-veen-bosch-keuning-artificial-intelligence Dutch publisher to use AI to translate limited number of books into English . The Guardian
2024
-
[8]
Bradley Emi and Max Spero. 2024. https://arxiv.org/abs/2402.14873 Technical report on the pangram ai-generated text classifier . Preprint, arXiv:2402.14873
arXiv 2024
-
[10]
Kyo Gerrits and Ana Guerberof-Arenas. 2025. To mt or not to mt: An eye-tracking study on the reception by dutch readers of different translation and creativity levels. In Proceedings of Machine Translation Summit XX: Volume 1, pages 516--537
2025
-
[12]
GlobeScribe.AI
GlobeScribe.AI Ltd . GlobeScribe.AI . https://globescribe.ai/. Accessed: 2026-05-22
2026
-
[13]
Google DeepMind . 2026. Gemini 3.1 Pro Model Card . https://deepmind.google/models/model-cards/gemini-3-1-pro/. Accessed 2026-05-26
2026
-
[14]
Yvette Graham, Timothy Baldwin, Alistair Moffat, and Justin Zobel. 2013. https://aclanthology.org/W13-2305/ Continuous measurement scales in human evaluation of machine translation . In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, pages 33--41, Sofia, Bulgaria. Association for Computational Linguistics
2013
-
[15]
Melanie C Green and Timothy C Brock. 2000. The role of transportation in the persuasiveness of public narratives. Journal of personality and social psychology, 79(5):701
2000
-
[16]
Ana Guerberof-Arenas and Antonio Toral. 2020. The impact of post-editing and machine translation on creativity and reading experience. Translation Spaces, 9(2):255--282
2020
-
[17]
Ana Guerberof-Arenas and Antonio Toral. 2022. Creativity in translation: Machine translation as a constraint for literary texts. Translation spaces, 11(2):184--212
2022
-
[18]
Ana Guerberof-Arenas and Antonio Toral. 2024. To be or not to be: A translation reception study of a literary text translated into dutch and catalan using machine translation. Target, 36(2):215--244
2024
-
[20]
Kilem Li Gwet. 2021. Handbook of inter-rater reliability. Advanced Analytics
2021
-
[21]
Fantine Huot, Reinald Kim Amplayo, Jennimaria Palomaki, Alice Shoshana Jakobovits, Elizabeth Clark, and Mirella Lapata. 2025. https://openreview.net/forum?id=HfWcFs7XLR Agents' room: Narrative generation through multi-step collaboration . In The Thirteenth International Conference on Learning Representations
2025
-
[26]
M. G. Kendall. 1938. https://doi.org/10.1093/biomet/30.1-2.81 A new measure of rank correlation . Biometrika, 30(1--2):81--93
-
[27]
Dorothy Kenny and Marion Winters. 2020. Machine translation, ethics and the literary translator’s voice. Translation Spaces, 9(1):123--149
2020
-
[30]
Muhammed Yusuf Kocyigit, Eleftheria Briakou, Daniel Deutsch, Jiaming Luo, Colin Cherry, and Markus Freitag. 2025. https://openreview.net/forum?id=MpjtvkvXDo Overestimation in LLM evaluation: A controlled large-scale study on data contamination s impact on machine translation . In Forty-second International Conference on Machine Learning
2025
-
[31]
Samuel L \"a ubli, Sheila Castilho, Graham Neubig, Rico Sennrich, Qinlan Shen, and Antonio Toral. 2020. A set of recommendations for assessing human--machine parity in language translation. Journal of artificial intelligence research, 67:653--672
2020
-
[32]
Samuel L \"a ubli, Rico Sennrich, and Martin Volk. 2018. Has machine translation achieved human parity? a case for document-level evaluation. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 4791--4796
2018
-
[33]
Arle Richard Lommel, Aljoscha Burchardt, and Hans Uszkoreit. 2013. https://aclanthology.org/2013.tc-1.6/ Multidimensional quality metrics: a flexible system for assessing translation quality . In Proceedings of Translating and the Computer 35, London, UK. Aslib
2013
-
[35]
Evgeny Matusov. 2019. The challenges of using neural machine translation for literature. In Proceedings of the qualities of literary machine translation, pages 10--19
2019
-
[36]
Joss Moorkens, Antonio Toral, Sheila Castilho, and Andy Way. 2018. Translators’ perceptions of literary post-editing using statistical and neural machine translation. Translation Spaces, 7(2):240--262
2018
-
[37]
Annu Nishioka. 2024. https://asia.nikkei.com/Business/Media-Entertainment/Japanese-publisher-to-launch-light-novel-app-with-AI-assisted-translations Japanese publisher to launch `light novel' app with AI -assisted translations . Nikkei Asia. Accessed: 2026-05-24
2024
-
[39]
Chau Minh Pham, Yapei Chang, and Mohit Iyyer. 2026. https://github.com/AutoFiction-AI/autofiction Autofiction pipeline . Research pipeline for long-form AI novel generation
2026
-
[40]
Barbara Plank. 2022. The “problem” of human label variation: On ground truth in data, modeling and evaluation. In Proceedings of the 2022 conference on empirical methods in natural language processing, pages 10671--10682
2022
-
[42]
Brian Porter and Edouard Machery. 2024. Ai-generated poetry is indistinguishable from human-written poetry and is rated more favorably. Scientific Reports, 14(1):26133
2024
-
[43]
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. Comet: A neural framework for mt evaluation. In Proceedings of the 2020 conference on empirical methods in natural language processing (emnlp), pages 2685--2702
2020
-
[47]
Kristiina Taivalkoski-Shilov. 2019 a . Ethical issues regarding machine (-assisted) translation of literary texts. Perspectives, 27(5):689--703
2019
-
[48]
Kristiina Taivalkoski-Shilov. 2019 b . Free indirect discourse: an insurmountable challenge for literary mt systems? In Proceedings of the qualities of literary machine translation, pages 35--39
2019
-
[55]
Rebecca Webster, Margot Fonteyne, Arda Tezcan, Lieve Macken, and Joke Daems. 2020. Gutenberg goes neural: Comparing features of D utch human translations with raw neural machine translation outputs in a corpus of E nglish literary classics. In Informatics, volume 7, page 32. MDPI
2020
-
[59]
Tiffany Zhu, Iain Weissburg, Kexun Zhang, and William Yang Wang. 2025. Human bias in the face of ai: Examining human judgment against text labeled as ai generated. In Findings of the Association for Computational Linguistics: ACL 2025, pages 25907--25914
2025
-
[61]
Marco, Guillermo and Gonzalo, Julio and Fresno, V \'i ctor. The Reader is the Metric: How Textual Features and Reader Profiles Explain Conflicting Evaluations of AI Creative Writing. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1304
-
[62]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[63]
Publications Manual , year = "1983", publisher =
1983
-
[64]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[65]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[66]
Dan Gusfield , title =. 1997
1997
-
[67]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[68]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[69]
Wongpakaran, Nahathai and Wongpakaran, Tinakon and Wedding, Danny and Gwet, Kilem L , year =. A comparison of Cohen’s Kappa and Gwet’s AC1 when calculating inter-rater reliability coefficients: a study conducted with personality disorder samples , volume =. BMC Medical Research Methodology , publisher =. doi:10.1186/1471-2288-13-61 , number =
-
[70]
Landis, J. Richard and Koch, Gary G. , year =. The Measurement of Observer Agreement for Categorical Data , volume =. Biometrics , publisher =. doi:10.2307/2529310 , number =
-
[71]
Handbook of inter-rater reliability
Gwet, Kilem Li. Handbook of inter-rater reliability
-
[72]
The Guardian , year =
Creamer, Ella , title =. The Guardian , year =
-
[73]
2025 , month = nov, note =
Amazon Introduces. 2025 , month = nov, note =
2025
-
[74]
Marzena Karpinska and Katherine Thai and Kalpesh Krishna and John Wieting and Moira Inghilleri and Mohit Iyyer , month =
-
[75]
Carpuat, Marine and Asscher, Omri and Bali, Kalika and Bentivogli, Luisa and Blain, Fr \'e d \'e ric and Bowker, Lynne and Choudhury, Monojit and Daum \'e III, Hal and Duh, Kevin and Gao, Ge and Grissom II, Alvin and Karpinska, Marzena and Khoong, Elaine C. and Lewis, William D. and Martins, Andr \'e F. T. and Nurminen, Mary and Oard, Douglas W. and Popov...
-
[76]
Nikkei Asia , year =
Nishioka, Annu , title =. Nikkei Asia , year =
-
[77]
Bleu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[78]
BLEURT : Learning Robust Metrics for Text Generation
Sellam, Thibault and Das, Dipanjan and Parikh, Ankur. BLEURT : Learning Robust Metrics for Text Generation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.704
-
[79]
BlonDe : An Automatic Evaluation Metric for Document-level Machine Translation
Jiang, Yuchen and Liu, Tianyu and Ma, Shuming and Zhang, Dongdong and Yang, Jian and Huang, Haoyang and Sennrich, Rico and Cotterell, Ryan and Sachan, Mrinmaya and Zhou, Ming. BlonDe : An Automatic Evaluation Metric for Document-level Machine Translation. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational...
-
[80]
and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr \'e F
Guerreiro, Nuno M. and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr \'e F. T. x COMET : Transparent Machine Translation Evaluation through Fine-grained Error Detection. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00683
-
[81]
and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C
Rei, Ricardo and Treviso, Marcos and Guerreiro, Nuno M. and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C. de Souza, Jos \'e G. and Glushkova, Taisiya and Alves, Duarte and Coheur, Luisa and Lavie, Alon and Martins, Andr \'e F. T. C omet K iwi: IST -Unbabel 2022 Submission for the Quality Estimation Shared Task. Proceedings of the Sevent...
-
[82]
GEMBA - MQM : Detecting Translation Quality Error Spans with GPT -4
Kocmi, Tom and Federmann, Christian. GEMBA - MQM : Detecting Translation Quality Error Spans with GPT -4. Proceedings of the Eighth Conference on Machine Translation. 2023. doi:10.18653/v1/2023.wmt-1.64
-
[83]
M etric X -23: The G oogle Submission to the WMT 2023 Metrics Shared Task
Juraska, Juraj and Finkelstein, Mara and Deutsch, Daniel and Siddhant, Aditya and Mirzazadeh, Mehdi and Freitag, Markus. M etric X -23: The G oogle Submission to the WMT 2023 Metrics Shared Task. Proceedings of the Eighth Conference on Machine Translation. 2023. doi:10.18653/v1/2023.wmt-1.63
-
[84]
Zhang, Ran and Zhao, Wei and Macken, Lieve and Eger, Steffen. L i T rans P ro QA : An LLM -based Literary Translation Evaluation Metric with Professional Question Answering. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1482
-
[85]
arXiv preprint arXiv:2412.01340 , year=
A 2-step framework for automated literary translation evaluation: Its promises and pitfalls , author=. arXiv preprint arXiv:2412.01340 , year=
-
[86]
Thai, Katherine and Karpinska, Marzena and Krishna, Kalpesh and Ray, Bill and Inghilleri, Moira and Wieting, John and Iyyer, Mohit. Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.672
-
[87]
Zhang, Ran and Zhao, Wei and Eger, Steffen. How Good Are LLM s for Literary Translation, Really? Literary Translation Evaluation with Humans and LLM s. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.n...
-
[88]
Multidimensional quality metrics: a flexible system for assessing translation quality
Lommel, Arle Richard and Burchardt, Aljoscha and Uszkoreit, Hans. Multidimensional quality metrics: a flexible system for assessing translation quality. Proceedings of Translating and the Computer 35. 2013
2013
-
[89]
Freitag, Markus and Foster, George and Grangier, David and Ratnakar, Viresh and Tan, Qijun and Macherey, Wolfgang. Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation. Transactions of the Association for Computational Linguistics. 2021. doi:10.1162/tacl_a_00437
-
[90]
Wu, Minghao and Xu, Jiahao and Yuan, Yulin and Haffari, Gholamreza and Wan, Longyue and Luo, Weihua and Zhang, Kaifu. (Perhaps) Beyond Human Translation: Harnessing Multi-Agent Collaboration for Translating Ultra-Long Literary Texts. Transactions of the Association for Computational Linguistics. 2025. doi:10.1162/tacl.a.25
-
[91]
Extending CREAMT : Leveraging Large Language Models for Literary Translation Post-Editing
Castaldo, Antonio and Castilho, Sheila and Moorkens, Joss and Monti, Johanna. Extending CREAMT : Leveraging Large Language Models for Literary Translation Post-Editing. Proceedings of Machine Translation Summit XX: Volume 1. 2025
2025
-
[92]
Karpinska, Marzena and Iyyer, Mohit. Large Language Models Effectively Leverage Document-level Context for Literary Translation, but Critical Errors Persist. Proceedings of the Eighth Conference on Machine Translation. 2023. doi:10.18653/v1/2023.wmt-1.41
-
[93]
Wang, Longyue and Tu, Zhaopeng and Gu, Yan and Liu, Siyou and Yu, Dian and Ma, Qingsong and Lyu, Chenyang and Zhou, Liting and Liu, Chao-Hong and Ma, Yufeng and Chen, Weiyu and Graham, Yvette and Webber, Bonnie and Koehn, Philipp and Way, Andy and Yuan, Yulin and Shi, Shuming. Findings of the WMT 2023 Shared Task on Discourse-Level Literary Translation: A...
-
[94]
Literary Machine Translation under the Magnifying Glass: Assessing the Quality of an NMT -Translated Detective Novel on Document Level
Fonteyne, Margot and Tezcan, Arda and Macken, Lieve. Literary Machine Translation under the Magnifying Glass: Assessing the Quality of an NMT -Translated Detective Novel on Document Level. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[95]
Project P i P e N ovel: Pilot on Post-editing Novels
Toral, Antonio and Wieling, Martijn and Castilho, Sheila and Moorkens, Joss and Way, Andy. Project P i P e N ovel: Pilot on Post-editing Novels. Proceedings of the 21st Annual Conference of the European Association for Machine Translation. 2018
2018
-
[96]
arXiv preprint arXiv:2605.13596 , year=
Creativity Bias: How Machine Evaluation Struggles with Creativity in Literary Translations , author=. arXiv preprint arXiv:2605.13596 , year=
-
[97]
2026 , version =
Pham, Chau Minh and Chang, Yapei and Iyyer, Mohit , title =. 2026 , version =
2026
-
[98]
2024 , eprint=
Technical Report on the Pangram AI-Generated Text Classifier , author=. 2024 , eprint=
2024
-
[99]
2023 , note =
ordinal---Regression Models for Ordinal Data , author =. 2023 , note =
2023
-
[100]
Fitting Linear Mixed-Effects Models Using
Douglas Bates and Martin M. Fitting Linear Mixed-Effects Models Using. Journal of Statistical Software , year =
-
[101]
David R. Thomas , title =. American Journal of Evaluation , volume =. 2006 , doi =. https://doi.org/10.1177/1098214005283748 , abstract =
-
[102]
Russell, Jenna and Karpinska, Marzena and Iyyer, Mohit. People who frequently use C hat GPT for writing tasks are accurate and robust detectors of AI -generated text. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.267
-
[103]
Jacovi, Alon and Caciularu, Avi and Goldman, Omer and Goldberg, Yoav. Stop Uploading Test Data in Plain Text: Practical Strategies for Mitigating Data Contamination by Evaluation Benchmarks. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.308
-
[104]
Turning E nglish-centric LLM s Into Polyglots: How Much Multilinguality Is Needed?
Kew, Tannon and Schottmann, Florian and Sennrich, Rico. Turning E nglish-centric LLM s Into Polyglots: How Much Multilinguality Is Needed?. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.766
-
[105]
Kocmi, Tom and Artemova, Ekaterina and Avramidis, Eleftherios and Bawden, Rachel and Bojar, Ond r ej and Dranch, Konstantin and Dvorkovich, Anton and Dukanov, Sergey and Fishel, Mark and Freitag, Markus and Gowda, Thamme and Grundkiewicz, Roman and Haddow, Barry and Karpinska, Marzena and Koehn, Philipp and Lakougna, Howard and Lundin, Jessica and Monz, C...
-
[106]
M etric X -24: The G oogle Submission to the WMT 2024 Metrics Shared Task
Juraska, Juraj and Deutsch, Daniel and Finkelstein, Mara and Freitag, Markus. M etric X -24: The G oogle Submission to the WMT 2024 Metrics Shared Task. Proceedings of the Ninth Conference on Machine Translation. 2024. doi:10.18653/v1/2024.wmt-1.35
-
[107]
2026 , month = feb, howpublished =
2026
-
[108]
Walker, Callum , year =. An Eye-Tracking Study of Equivalent Effect in Translation: The Reader Experience of Literary Style , ISBN =. doi:10.1007/978-3-030-55769-0 , publisher =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.