Human-Centric Transferable Tactile Pre-Training for Dexterous Robotic Manipulation
Pith reviewed 2026-07-02 11:16 UTC · model grok-4.3
The pith
Pre-training on human tactile videos with unified spaces transfers to dexterous robot manipulation via future tactile prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that Transferable Tactile Pre-Training on the H-Tac human dataset, by maintaining a single unified tactile and action space across phases and training a tactile expert to predict future tactile readings, explicitly captures contact dynamics and physical interactions, enabling superior generalization and fine-grained dexterous manipulation when transferred to robots.
What carries the argument
Unified tactile and action spaces across pre-training and post-training, together with a tactile expert that predicts future tactile signals to model contact dynamics.
If this is right
- The approach yields superior performance compared with dynamics-agnostic post-training on downstream dexterous tasks.
- It produces robust generalization across simulation and real-robot settings.
- It supports fine-grained manipulation capabilities that require precise force feedback.
- It enables scalable tactile pre-training through human-to-robot transfer.
Where Pith is reading between the lines
- If the unified-space assumption holds, similar pre-training pipelines could be applied to other scarce modalities such as audio or proprioception.
- The method suggests that collecting more human egocentric tactile data could further raise the performance ceiling without changing the robot hardware.
- Downstream tasks that currently rely on vision-language-action models might see additive gains by inserting the tactile expert as an auxiliary prediction head.
Load-bearing premise
A single unified tactile and action space is enough to preserve human knowledge and bridge the human-robot gap without any extra alignment losses or domain randomization.
What would settle it
Real-robot experiments in which a version without the future-tactile-prediction expert or without the unified space matches or exceeds the reported performance on the same manipulation tasks would falsify the necessity of those components.
Figures
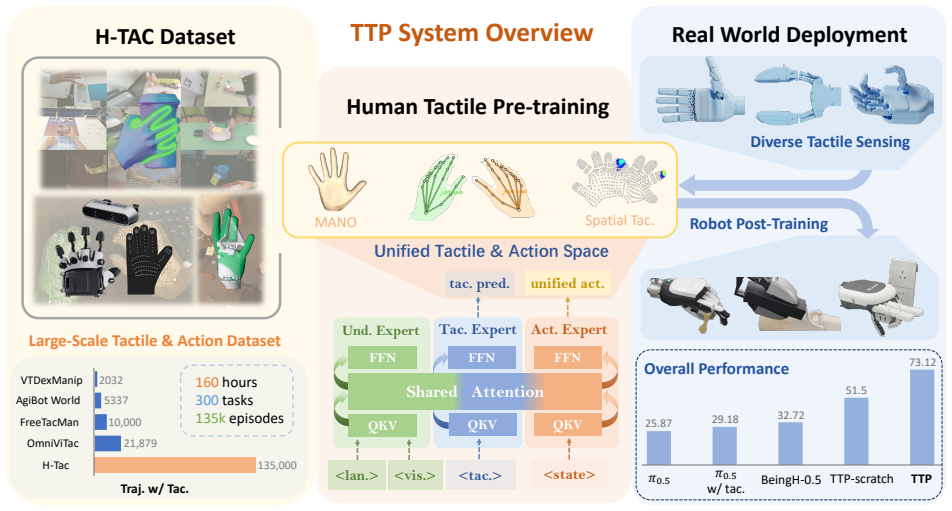

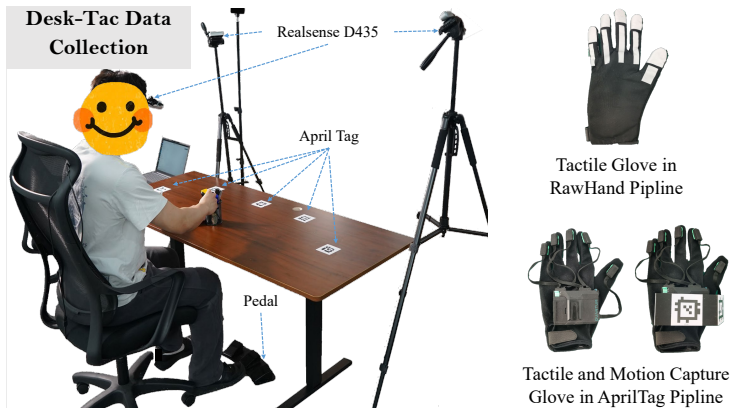
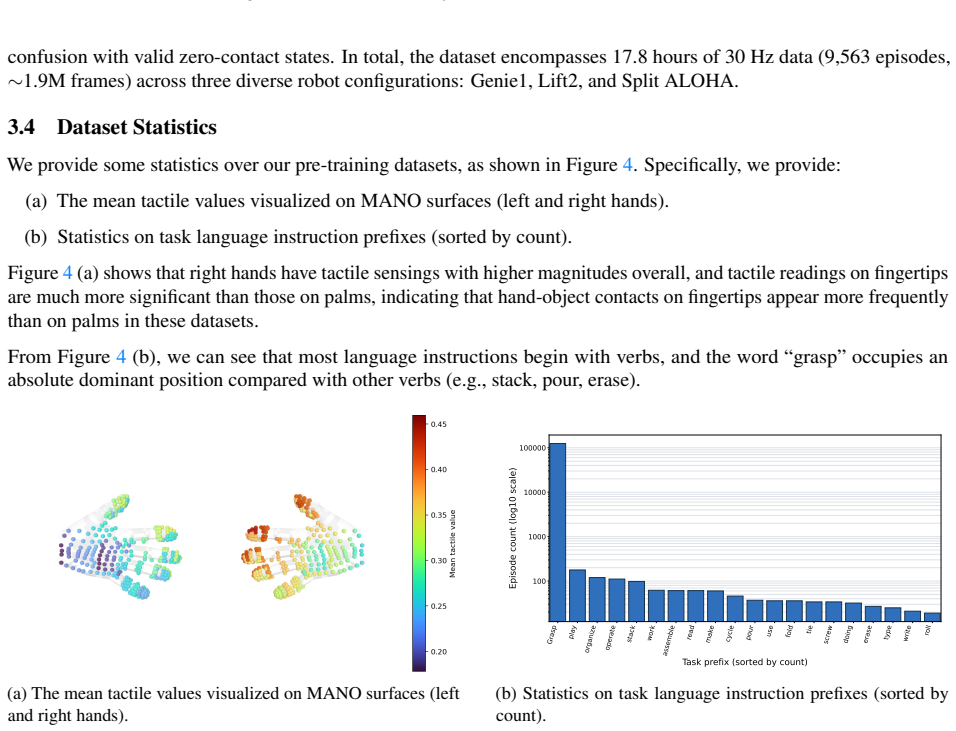
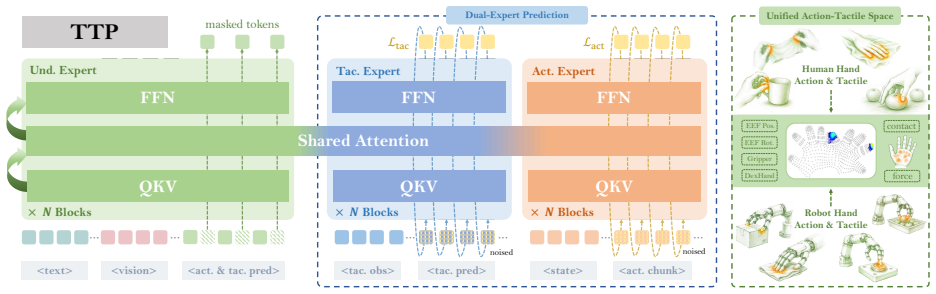


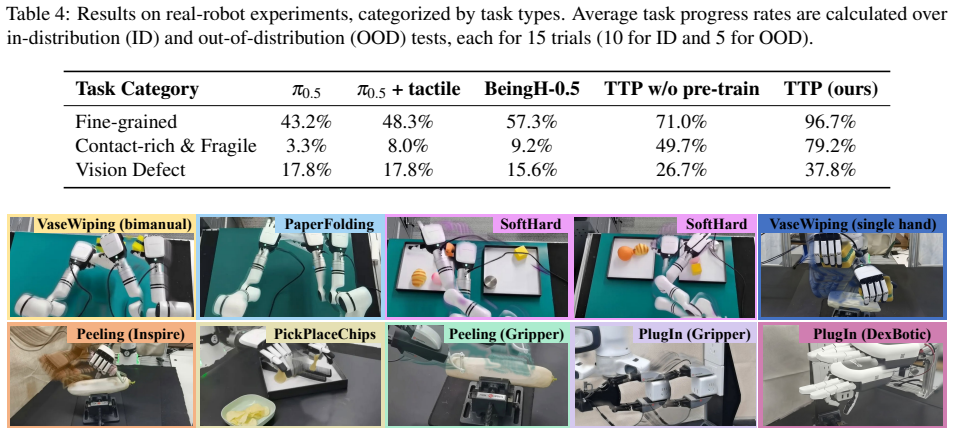


read the original abstract
As an essential modality for dexterous and contact-rich tasks, tactile sensing provides precise force feedback that cannot be reliably inferred from vision. However, limited by hardware and data collection systems, existing datasets with tactility remain small in scale and narrow in contact coverage. Meanwhile, Vision-Language-Action (VLA) models with tactile modality are constrained on dynamics-agnostic post-training, which limits the performance ceiling on downstream tasks. In this paper, we present H-Tac, a large-scale tactile-action dataset with 160-hour egocentric human videos containing more than 300 tasks and 135k episodes. Building upon this, we propose Transferable Tactile Pre-Training (TTP), a system of tactile-based pre-training on human data for fine-grained robotic tasks. To bridge the gap between humans and robots, we use unified tactile and action spaces throughout the pre-training and post-training phases, preserving prior knowledge during human-to-robot transfer. By leveraging a tactile expert for future tactile prediction, our framework explicitly models the contact dynamics and precise physical interactions. Extensive experiments in simulation and on real robots demonstrate that our model achieves superior performance, exhibiting robust generalization and fine-grained manipulation capabilities. TTP paves the way for scalable tactile pre-training via human-to-robot transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the H-Tac dataset comprising 160 hours of egocentric human videos with tactile and action annotations across more than 300 tasks and 135k episodes. It proposes Transferable Tactile Pre-Training (TTP), a pre-training framework that operates on human data using a single unified tactile and action space for both pre-training and downstream robot fine-tuning, augmented by a tactile expert module that predicts future tactile signals to explicitly model contact dynamics. The central claim is that this approach enables effective human-to-robot transfer, yielding superior performance, robust generalization, and fine-grained dexterous manipulation capabilities in both simulation and real-robot experiments.
Significance. If the performance and generalization claims are supported by rigorous ablations and quantitative transfer metrics, the work would be significant for tactile robotics: it directly tackles data scarcity by scaling pre-training via human demonstrations and provides a concrete mechanism (unified spaces plus future tactile prediction) for embodiment transfer that could raise the performance ceiling of tactile-augmented VLA models on contact-rich tasks.
major comments (2)
- [Abstract] Abstract: The claim that 'unified tactile and action spaces throughout the pre-training and post-training phases' suffice to 'bridge the gap between humans and robots' and 'preserve prior knowledge' is load-bearing for the transfer mechanism, yet the manuscript provides no ablations isolating this design choice from alternatives that include explicit alignment losses or domain randomization. Without such controls or quantitative metrics (e.g., sim-to-real gap before/after unification), attribution of the reported 'superior performance' and 'robust generalization' remains unverified.
- [Experiments] Experiments (implied §4–5): The abstract asserts 'extensive experiments in simulation and on real robots' demonstrating superiority, but no tables, error bars, baseline comparisons, or per-task metrics are referenced that would allow verification of the performance gains or the contribution of the tactile expert. This absence directly undermines evaluation of the central empirical claims.
minor comments (1)
- [Abstract] The abstract mentions '135k episodes' but does not clarify episode length, contact coverage statistics, or sensor calibration details that would be needed to assess dataset quality relative to prior tactile corpora.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'unified tactile and action spaces throughout the pre-training and post-training phases' suffice to 'bridge the gap between humans and robots' and 'preserve prior knowledge' is load-bearing for the transfer mechanism, yet the manuscript provides no ablations isolating this design choice from alternatives that include explicit alignment losses or domain randomization. Without such controls or quantitative metrics (e.g., sim-to-real gap before/after unification), attribution of the reported 'superior performance' and 'robust generalization' remains unverified.
Authors: We agree that the manuscript would benefit from ablations that isolate the contribution of the unified tactile and action spaces. The current experiments focus on end-to-end performance of TTP but do not include direct comparisons against variants using explicit alignment losses or domain randomization, nor do they report sim-to-real gaps before versus after unification. We will add these ablations and metrics in the revised version to better substantiate the transfer mechanism. revision: yes
-
Referee: [Experiments] Experiments (implied §4–5): The abstract asserts 'extensive experiments in simulation and on real robots' demonstrating superiority, but no tables, error bars, baseline comparisons, or per-task metrics are referenced that would allow verification of the performance gains or the contribution of the tactile expert. This absence directly undermines evaluation of the central empirical claims.
Authors: We acknowledge that the manuscript does not sufficiently reference or display the detailed experimental results. We will revise the experiments section to include comprehensive tables with error bars, baseline comparisons, and per-task metrics for simulation and real-robot settings, along with ablations quantifying the tactile expert module's contribution. revision: yes
Circularity Check
No circularity: framework claims rest on design choices and empirical results, not self-referential reductions
full rationale
The paper presents TTP as a pre-training system using unified tactile/action spaces and a tactile expert for future prediction to model contact dynamics. No equations, derivations, or fitted parameters are described in the provided text that reduce any claimed prediction or result to an input defined inside the paper. The bridging mechanism is stated as an explicit design choice rather than derived from prior self-citations or ansatzes. Central performance claims are supported by experiments in simulation and on real robots, making the derivation self-contained against external benchmarks with no load-bearing self-citation chains or self-definitional steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hot3d: Hand and object tracking in 3d from egocentric multi-view videos
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Shangchen Han, Fan Zhang, Linguang Zhang, Jade Fountain, Edward Miller, Selen Basol, et al. Hot3d: Hand and object tracking in 3d from egocentric multi-view videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7061–7071, 2025
2025
-
[2]
Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doersch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation. In Conference on Robot Learning, pages 3936–3951. PMLR, 2025
2025
-
[3]
Vla-touch: Enhancing vision-language-action model with dual-level tactile feedback
Jianxin Bi, Kevin Yuchen Ma, Ce Hao, Mike Shou Zheng, and Harold Soh. Vla-touch: Enhancing vision-language-action model with dual-level tactile feedback. IEEE Robotics and Automation Letters, 2026
2026
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Haus- man, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Sliced and radon wasserstein barycenters of measures
Nicolas Bonneel, Julien Rabin, Gabriel Peyré, and Hanspeter Pfister. Sliced and radon wasserstein barycenters of measures. Journal of Mathematical Imaging and Vision, 51(1):22–45, 2015
2015
-
[6]
Decaf: Monocular deformation capture for face and hand interactions
Samarth Brahmbhatt, Cheng-You Li, Heeseung Kim, Zerong Zheng, Gurprit Singh, Giljoo Bernstein, Taehyun Kim, Hyeongwoo Kim, Ramesh Raskar, and Yaser Sheikh. Decaf: Monocular deformation capture for face and hand interactions. In SIGGRAPH Asia 2024 Conference Papers, pages 1–12, 2024
2024
-
[7]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions. arXiv preprint arXiv:2505.06111, 2025. 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model. arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
DexYCB: A benchmark for capturing hand grasping of objects
Yu-Wei Chao, Wei Yang, Yu Xiang, Pavlo Molchanov, Ankur Handa, Jonathan Tremblay, Yashraj S Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, et al. DexYCB: A benchmark for capturing hand grasping of objects. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9044–9053, 2021
2021
-
[10]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Jiaya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiangmiao Pang, Yu Qiao, et al. Internvla-m1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Omnivtla: Vision- tactile-language-action model with semantic-aligned tactile sensing
Zhengxue Cheng, Yiqian Zhang, Wenkang Zhang, Haoyu Li, Keyu Wang, Li Song, and Hengdi Zhang. Omnivtla: Vision- tactile-language-action model with semantic-aligned tactile sensing. arXiv preprint arXiv:2508.08706, 2025
-
[12]
Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. Robotics: Science and Systems, 2024
2024
-
[13]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[14]
Arctic: A dataset for dexterous bimanual hand-object manipulation
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J Black, and Otmar Hilliges. Arctic: A dataset for dexterous bimanual hand-object manipulation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12943–12954, 2023
2023
-
[15]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, Jinlan Fu, Jingjing Gong, and Xipeng Qiu. Libero-plus: In-depth robustness analysis of vision-language-action models. arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995–19012, 2022
2022
-
[17]
Konstantin Gubernatorov, Mikhail Sannikov, Ilya Mikhalchuk, Egor Kuznetsov, Makar Artemov, Ogunwoye Faith Ouwatobi, Marcelino Fernando, Artem Asanov, Ziang Guo, and Dzmitry Tsetserukou. Hapticvla: Contact-rich manipulation via vision- language-action model without inference-time tactile sensing. arXiv preprint arXiv:2603.15257, 2026
-
[18]
HOnnotate: A method for 3D annotation of hand and object poses
Shreyas Hampali, Mahdi Rad, Markus Oberweger, and Vincent Lepetit. HOnnotate: A method for 3D annotation of hand and object poses. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3196–3206, 2020
2020
-
[19]
Keypoint transformer: Solving joint identification in challenging hands and object interactions for accurate 3D pose estimation
Shreyas Hampali, Sayan Deb Sarkar, Mahdi Rad, and Vincent Lepetit. Keypoint transformer: Solving joint identification in challenging hands and object interactions for accurate 3D pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11090–11100, 2022
2022
-
[20]
Tla: tactile-language-action model for contact-rich manipulation
Peng Hao, Chaofan Zhang, Dingzhe Li, Xiaoge Cao, Xiaoshuai Hao, Shaowei Cui, and Shuo Wang. Tla: tactile-language-action model for contact-rich manipulation. Robot Learning, 3(1):17–18, 2026
2026
-
[21]
Resolving 3D human pose ambiguities with 3D scene constraints
Mohamed Hassan, Vasileios Choutas, Dimitrios Tzionas, and Michael J Black. Resolving 3D human pose ambiguities with 3D scene constraints. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2282–2292, 2019
2019
-
[22]
Scaling single human demonstrations for imitation learning using generative foundational models
Nick Heppert, Minh Quang Nguyen, and Abhinav Valada. Scaling single human demonstrations for imitation learning using generative foundational models. arXiv preprint arXiv:2602.12734, 2026
-
[23]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
Ryan Hoque, Peide Huang, David J Yoon, Mouli Sivapurapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video. arXiv preprint arXiv:2505.11709, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Tactile-based reinforcement learning for adaptive grasping under observation uncertainties
Xiao Hu and Yang Ye. Tactile-based reinforcement learning for adaptive grasping under observation uncertainties. arXiv preprint arXiv:2505.16167, 2025
-
[25]
Capturing and inferring dense full-body human-scene contact
Chun-Hao P Huang, Hongwei Yi, Markus Höschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J Black. Capturing and inferring dense full-body human-scene contact. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13274–13285, 2022
2022
-
[26]
Jialei Huang, Shuo Wang, Fanqi Lin, Yihang Hu, Chuan Wen, and Yang Gao. Tactile-vla: unlocking vision-language-action model’s physical knowledge for tactile generalization.arXiv preprint arXiv:2507.09160, 2025. 18
-
[27]
NORA: A Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks
Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U Tan, Navonil Majumder, Soujanya Poria, et al. Nora: A small open-sourced generalist vision language action model for embodied tasks. arXiv preprint arXiv:2504.19854, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: A vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Egomimic: Scaling imitation learning via egocentric video
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Danfei Xu. Egomimic: Scaling imitation learning via egocentric video. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13226–13233. IEEE, 2025
2025
-
[30]
3d diffuser actor: Policy diffusion with 3d scene representations
Tsung-Wei Ke, Nikolaos Gkanatsios, and Katerina Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations. Arxiv, 2024
2024
-
[31]
Uniskill: Imitating human videos via cross-embodiment skill representations
Hanjung Kim, Jaehyun Kang, Hyolim Kang, Meedeum Cho, Seon Joo Kim, and Youngwoon Lee. Uniskill: Imitating human videos via cross-embodiment skill representations. In Conference on Robot Learning, pages 4269–4294. PMLR, 2025
2025
-
[32]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success. arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Generalized sliced wasserstein distances
Soheil Kolouri, Kimia Nadjahi, Umut Simsekli, Roland Badeau, and Gustavo Rohde. Generalized sliced wasserstein distances. Advances in neural information processing systems, 32, 2019
2019
-
[35]
H2O: Two hands manipulating objects for first person interaction recognition
Taein Kwon, Bugra Tekin, Jan Stühmer, Federica Bogo, and Marc Pollefeys. H2O: Two hands manipulating objects for first person interaction recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10138–10148, 2021
2021
-
[36]
AT-VLA: Adaptive Tactile Injection for Enhanced Feedback Reaction in Vision-Language-Action Models
Xiaoqi Li, Muhe Cai, Jiadong Xu, Juan Zhu, Hongwei Fan, Yan Shen, Guangrui Ren, and Hao Dong. At-vla: Adaptive tactile injection for enhanced feedback reaction in vision-language-action models. arXiv preprint arXiv:2605.07308, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Favla: A force-adaptive fast-slow vla model for contact-rich robotic manipulation
Yao Li, Peiyuan Tang, Wuyang Zhang, Chengyang Zhu, Yifan Duan, Weikai Shi, Xiaodong Zhang, Zijiang Yang, Jianmin Ji, and Yanyong Zhang. Favla: A force-adaptive fast-slow vla model for contact-rich robotic manipulation. arXiv preprint arXiv:2602.23648, 2026
-
[38]
Zhixuan Liang, Yizhuo Li, Tianshuo Yang, Chengyue Wu, Sitong Mao, Tian Nian, Liuao Pei, Shunbo Zhou, Xiaokang Yang, Jiangmiao Pang, et al. Discrete diffusion vla: Bringing discrete diffusion to action decoding in vision-language-action policies. arXiv preprint arXiv:2508.20072, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Libero: Benchmarking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[40]
Vtdexmanip: A dataset and benchmark for visual-tactile pretraining and dexterous manipulation with reinforcement learning
Qingtao Liu, Yu Cui, Zhengnan Sun, Gaofeng Li, Jiming Chen, and Qi Ye. Vtdexmanip: A dataset and benchmark for visual-tactile pretraining and dexterous manipulation with reinforcement learning. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[41]
HOI4D: A 4D egocentric dataset for category-level human-object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. HOI4D: A 4D egocentric dataset for category-level human-object interaction. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21013–21022, 2022
2022
-
[42]
Gwm: Towards scalable gaussian world models for robotic manipulation
Guanxing Lu, Baoxiong Jia, Puhao Li, Yixin Chen, Ziwei Wang, Yansong Tang, and Siyuan Huang. Gwm: Towards scalable gaussian world models for robotic manipulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9263–9274, 2025
2025
-
[43]
Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. Being-h0: vision-language-action pretraining from large-scale human videos. arXiv preprint arXiv:2507.15597, 2025
- [44]
-
[45]
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Qi Lv, Weijie Kong, Hao Li, Jia Zeng, Zherui Qiu, Delin Qu, Haoming Song, Qizhi Chen, Xiang Deng, and Jiangmiao Pang. F1: A vision-language-action model bridging understanding and generation to actions. arXiv preprint arXiv:2509.06951, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Enhancing tactile-based reinforcement learning for robotic control
Elle Miller, Trevor McInroe, David Abel, Oisin Mac Aodha, and Sethu Vijayakumar. Enhancing tactile-based reinforcement learning for robotic control. Advances in Neural Information Processing Systems, 38:129460–129494, 2025
2025
-
[47]
Interhand2
Gyeongsik Moon, Shoou-I Yu, He Wen, Takaaki Shiratori, and Kyoung Mu Lee. Interhand2. 6m: A dataset and baseline for 3d interacting hand pose estimation from a single rgb image. In European Conference on Computer Vision, pages 548–564. Springer, 2020
2020
-
[48]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J Bjorck Nvidia, Fernando Castaneda, N Cherniadev, X Da, R Ding, L Fan, Y Fang, D Fox, F Hu, S Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model. arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Em- bodied hands: Modeling and capturing hands and bodies to- gether,
Javier Romero, Dimitrios Tzionas, and Michael J Black. Embodied hands: Modeling and capturing hands and bodies together. arXiv preprint arXiv:2201.02610, 2022
-
[53]
Opentouch: Bringing full-hand touch to real-world interaction
Yuxin Ray Song, Jinzhou Li, Rao Fu, Devin Murphy, Kaichen Zhou, Rishi Shiv, Yaqi Li, Haoyu Xiong, Crystal Elaine Owens, Yilun Du, et al. Opentouch: Bringing full-hand touch to real-world interaction. arXiv preprint arXiv:2512.16842, 2025
-
[54]
Interactive Post-Training for Vision-Language-Action Models
Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Krähenbühl. Interactive post-training for vision-language-action models.arXiv preprint arXiv:2505.17016, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Yang Tian, Yuyin Yang, Yiman Xie, Zetao Cai, Xu Shi, Ning Gao, Hangxu Liu, Xuekun Jiang, Zherui Qiu, Feng Yuan, et al. Interndata-a1: Pioneering high-fidelity synthetic data for pre-training generalist policy. arXiv preprint arXiv:2511.16651, 2025
-
[56]
HO-Cap: A capture system and dataset for 3D reconstruction and pose tracking of hand-object interaction
Jikai Wang, Qifan Zhang, Yu-Wei Chao, Bowen Wen, Xiaohu Guo, and Yu Xiang. HO-Cap: A capture system and dataset for 3D reconstruction and pose tracking of hand-object interaction. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[57]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Tactalign: Human-to-robot policy transfer via tactile alignment
Youngsun Wi, Jessica Yin, Elvis Xiang, Akash Sharma, Jitendra Malik, Mustafa Mukadam, Nima Fazeli, and Tess Hellebrekers. Tactalign: Human-to-robot policy transfer via tactile alignment. arXiv preprint arXiv:2602.13579, 2026
-
[59]
Human2robot: Learning robot actions from paired human-robot videos
Sicheng Xie, Haidong Cao, Zejia Weng, Zhen Xing, Haoran Chen, Shiwei Shen, Jiaqi Leng, Zuxuan Wu, and Yu-Gang Jiang. Human2robot: Learning robot actions from paired human-robot videos. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 11078–11086, 2026
2026
-
[60]
Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation
Han Xue, Jieji Ren, Wendi Chen, Gu Zhang, Yuan Fang, Guoying Gu, Huazhe Xu, and Cewu Lu. Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation. In Proceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[61]
OakInk: A large-scale knowledge repository for understanding hand-object interaction
Lixin Yang, Kailin Li, Xinyu Zhan, Fei Wu, Anran Xu, Liu Liu, Sheng Xie, Kai Xu, and Dacheng Tao. OakInk: A large-scale knowledge repository for understanding hand-object interaction. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20953–20962, 2022
2022
-
[62]
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Ruihan Yang, Qinxi Yu, Yecheng Wu, Rui Yan, Borui Li, An-Chieh Cheng, Xueyan Zou, Yunhao Fang, Xuxin Cheng, Ri-Zhao Qiu, et al. Egovla: Learning vision-language-action models from egocentric human videos. arXiv preprint arXiv:2507.12440, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Osmo: Open-source tactile glove for human-to-robot skill transfer
Jessica Yin, Haozhi Qi, Youngsun Wi, Sayantan Kundu, Mike Lambeta, William Yang, Changhao Wang, Tingfan Wu, Jitendra Malik, and Tess Hellebrekers. Osmo: Open-source tactile glove for human-to-robot skill transfer. arXiv preprint arXiv:2512.08920, 2025
-
[64]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. In Proceedings of Robotics: Science and Systems (RSS), 2024. 20
2024
-
[65]
OakInk2: A dataset of bimanual hands-object manipulation in complex task completion
Xinyu Zhan, Lixin Yang, Yifei Zhao, Kangrui Mao, Hanwen Xu, Zenan Lin, Kailin Li, and Kai Xu. OakInk2: A dataset of bimanual hands-object manipulation in complex task completion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 504–514, 2024
2024
-
[66]
Vtla: Vision-tactile-language-action model with preference learning for insertion manipulation
Chaofan Zhang, Peng Hao, Xiaoge Cao, Xiaoshuai Hao, Shaowei Cui, and Shuo Wang. Vtla: Vision-tactile-language-action model with preference learning for insertion manipulation. Biomimetic Intelligence and Robotics, page 100333, 2026
2026
-
[67]
Chi Zhang, Penglin Cai, Haoqi Yuan, Chaoyi Xu, and Zongqing Lu. Unitachand: Unified spatio-tactile representation for human to robotic hand skill transfer. arXiv preprint arXiv:2512.21233, 2025
-
[68]
Gu Zhang, Qicheng Xu, Haozhe Zhang, Jianhan Ma, Long He, Yiming Bao, Zeyu Ping, Zhecheng Yuan, Chenhao Lu, Chengbo Yuan, et al. Unidex: A robot foundation suite for universal dexterous hand control from egocentric human videos.arXiv preprint arXiv:2603.22264, 2026
-
[69]
Dig-flow: Discrepancy-guided flow matching for robust vla models
Wanpeng Zhang, Ye Wang, Hao Luo, Haoqi Yuan, Yicheng Feng, Sipeng Zheng, Qin Jin, and Zongqing Lu. Dig-flow: Discrepancy-guided flow matching for robust vla models. arXiv preprint arXiv:2512.01715, 2025
-
[70]
Craft: Adapting vla models to contact-rich manipulation via force-aware curriculum fine-tuning
Yike Zhang, Yaonan Wang, Xinxin Sun, Kaizhen Huang, Zhiyuan Xu, Junjie Ji, Zhengping Che, Jian Tang, and Jingtao Sun. Craft: Adapting vla models to contact-rich manipulation via force-aware curriculum fine-tuning. arXiv preprint arXiv:2602.12532, 2026
-
[71]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[72]
Fd-vla: Force-distilled vision-language-action model for contact-rich manipulation
Ruiteng Zhao, Wenshuo Wang, Yicheng Ma, Xiaocong Li, Francis EH Tay, Marcelo H Ang Jr, and Haiyue Zhu. Fd-vla: Force-distilled vision-language-action model for contact-rich manipulation. arXiv preprint arXiv:2602.02142, 2026
-
[73]
Egopressure: A dataset for hand pressure and pose estimation in egocentric vision
Yiming Zhao, Taein Kwon, Paul Streli, Marc Pollefeys, and Christian Holz. Egopressure: A dataset for hand pressure and pose estimation in egocentric vision. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 27727–27738, 2025
2025
-
[74]
Ruijie Zheng, Dantong Niu, Yuqi Xie, Jing Wang, Mengda Xu, Yunfan Jiang, Fernando Castañeda, Fengyuan Hu, You Liang Tan, Letian Fu, et al. Egoscale: Scaling dexterous manipulation with diverse egocentric human data.arXiv preprint arXiv:2602.16710, 2026
-
[75]
Omnivta: Visuo-tactile world modeling for contact-rich robotic manipulation
Yuhang Zheng, Songen Gu, Weize Li, Yupeng Zheng, Yujie Zang, Shuai Tian, Xiang Li, Ce Hao, Chen Gao, Si Liu, et al. Omnivta: Visuo-tactile world modeling for contact-rich robotic manipulation. arXiv preprint arXiv:2603.19201, 2026
-
[76]
Traj2Action: A Co-Denoising Framework for Trajectory-Guided Human-to-Robot Skill Transfer
Han Zhou, Jinjin Cao, Liyuan Ma, Xueji Fang, and Guo jun Qi. Traj2action: A co-denoising framework for trajectory-guided human-to-robot skill transfer. arXiv preprint arXiv:2510.00491, 2025. 21 Appendix A Hyperparameters In our method, we have some hyperparameters that can be tuned during training, as listed in Table 9. For simulation benchmarks and real ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.