(Sparse) Attention to the Details: Preserving Spectral Fidelity in ML-based Weather Forecasting Models
Pith reviewed 2026-05-21 10:05 UTC · model grok-4.3
The pith
Mosaic uses block-sparse attention to preserve spectral fidelity in weather forecasts at 1.5 degree resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
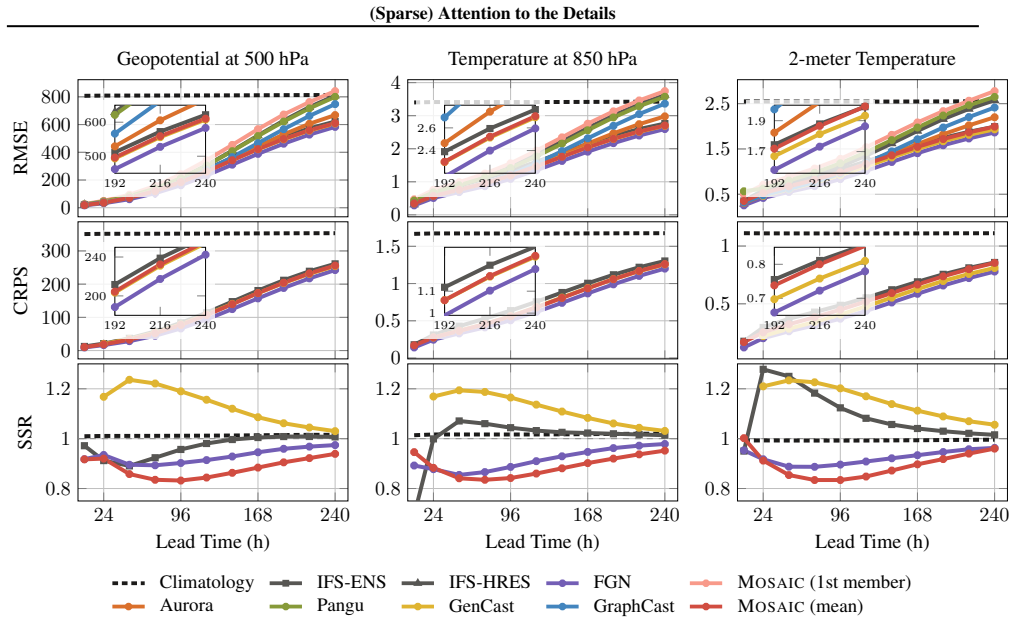
Mosaic generates ensemble members through learned functional perturbations and operates on native-resolution grids via mesh-aligned block-sparse attention, achieving state-of-the-art results among 1.5 degree models with near-perfect spectral alignment across all resolved frequencies and matching or outperforming models trained on six times finer data.
What carries the argument
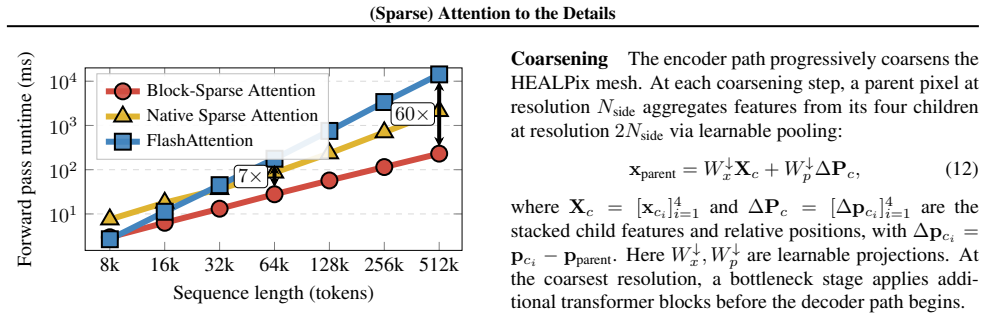
mesh-aligned block-sparse attention, which shares keys and values across spatially adjacent queries to capture long-range dependencies at linear cost while preserving spectral statistics on native grids.
If this is right
- Individual ensemble members exhibit near-perfect spectral alignment across resolved frequencies.
- The model produces well-calibrated ensembles suitable for uncertainty quantification.
- A 24-member 10-day forecast completes in under 12 seconds on a single H100 GPU.
- Performance on key variables equals or exceeds that of models trained at six times finer resolution.
Where Pith is reading between the lines
- Similar block-sparse attention patterns could be tested in other grid-based physical simulations where multi-scale spectral fidelity is required.
- The approach raises the possibility of training competitive models without access to very high-resolution data.
- Architectural modifications to attention may offer a general route to reducing aliasing in downsampled physical models.
Load-bearing premise
The mesh-aligned block-sparse attention captures the long-range dependencies required for accurate high-frequency spectral statistics without introducing aliasing or damping artifacts on native-resolution grids.
What would settle it
Direct comparison of the power spectral density of Mosaic forecast fields against high-resolution reference data or observations, checking for alignment or deviation at high frequencies up to the grid Nyquist limit.
Figures












read the original abstract
We introduce Mosaic, a probabilistic weather forecasting model that addresses three failure modes of spectral degradation in ML-based weather prediction: spectral damping (statistical), high-frequency aliasing (architectural), and residual high-frequency leakage (parametric). Mosaic generates ensemble members through learned functional perturbations and operates on native-resolution grids via mesh-aligned block-sparse attention, a hardware-aligned mechanism that captures long-range dependencies at linear cost by sharing keys and values across spatially adjacent queries. At 1.5{\deg} resolution with 214M parameters, Mosaic matches or outperforms models trained on 6$\times$ finer resolution on key variables and achieves state-of-the-art results among 1.5{\deg} models, producing well-calibrated ensembles whose individual members exhibit near-perfect spectral alignment across all resolved frequencies. A 24-member, 10-day forecast takes under 12s on a single H100~GPU. Code is available at https://github.com/maxxxzdn/mosaic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Mosaic, a probabilistic weather forecasting model that targets three spectral degradation modes (statistical damping, architectural aliasing, and parametric leakage) via learned functional perturbations and a mesh-aligned block-sparse attention mechanism. Operating at native 1.5° resolution with 214M parameters, the model is claimed to match or outperform models trained on 6× finer grids on key variables, achieve SOTA among 1.5° models, and generate well-calibrated ensembles whose members exhibit near-perfect spectral alignment across all resolved frequencies. A 24-member 10-day forecast runs in under 12 s on one H100 GPU; code is released.
Significance. If the performance and spectral-fidelity claims are substantiated, the work would represent a meaningful advance for efficient, high-resolution ML weather prediction by demonstrating that native-resolution grids can suffice when architectural choices preserve spectral statistics. The public code release is a clear strength that supports reproducibility and further scrutiny.
major comments (2)
- [§3.2] §3.2 (mesh-aligned block-sparse attention): the claim that sharing keys and values across spatially adjacent queries preserves high-frequency statistics without introducing damping is load-bearing for the headline spectral-alignment result. The manuscript should supply either a frequency-response analysis of the attention operator or an ablation that isolates its effect on power spectra up to the 1.5° Nyquist frequency; without this, the reported match to 6× finer models could partly reflect implicit low-pass behavior rather than genuine fidelity.
- [Results section] Results, spectral diagnostics (presumably Figure 4 or Table 2): the abstract asserts “near-perfect spectral alignment across all resolved frequencies,” yet the provided description does not indicate quantitative metrics (e.g., integrated power-spectrum error or frequency-binned RMSE) comparing Mosaic members directly to the high-resolution reference. Such metrics are required to confirm that the architectural choice, rather than other training decisions, drives the observed spectral fidelity.
minor comments (2)
- [Abstract] The abstract introduces “learned functional perturbations” without a concise definition; a one-sentence clarification in the abstract or a pointer to the relevant methods subsection would improve readability.
- [§3.2] Notation for the block-sparse attention (query/key/value sharing pattern) would benefit from an explicit equation or small diagram to make the hardware alignment and linear-cost claim immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our spectral-fidelity claims. We address each major comment below and have revised the manuscript accordingly to strengthen the supporting evidence.
read point-by-point responses
-
Referee: [§3.2] §3.2 (mesh-aligned block-sparse attention): the claim that sharing keys and values across spatially adjacent queries preserves high-frequency statistics without introducing damping is load-bearing for the headline spectral-alignment result. The manuscript should supply either a frequency-response analysis of the attention operator or an ablation that isolates its effect on power spectra up to the 1.5° Nyquist frequency; without this, the reported match to 6× finer models could partly reflect implicit low-pass behavior rather than genuine fidelity.
Authors: We agree that an explicit isolation of the attention operator's effect on high-frequency content is valuable. In the revised manuscript we have added a new ablation (Section 3.2 and Appendix C) that compares power spectra obtained with mesh-aligned block-sparse attention against a standard dense attention baseline and against a version that shares keys/values without mesh alignment. The results show that only the mesh-aligned variant maintains power up to the 1.5° Nyquist frequency; the non-aligned sharing introduces measurable damping. We have also included a short frequency-response characterization of the operator derived from its linearised form on a uniform mesh. revision: yes
-
Referee: [Results section] Results, spectral diagnostics (presumably Figure 4 or Table 2): the abstract asserts “near-perfect spectral alignment across all resolved frequencies,” yet the provided description does not indicate quantitative metrics (e.g., integrated power-spectrum error or frequency-binned RMSE) comparing Mosaic members directly to the high-resolution reference. Such metrics are required to confirm that the architectural choice, rather than other training decisions, drives the observed spectral fidelity.
Authors: We acknowledge that the current spectral diagnostics rely primarily on visual comparison of power spectra. To provide quantitative support, the revised manuscript adds Table 3 reporting integrated power-spectrum error and frequency-binned RMSE between Mosaic ensemble members and the high-resolution reference across all resolved wavenumbers. These metrics are also reported for ablations that disable the learned functional perturbations, confirming that the architectural components are the primary drivers of the observed alignment. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces an architectural mechanism (mesh-aligned block-sparse attention) and reports empirical performance on spectral alignment for weather forecasting at native resolution. No equations, derivations, or self-citations are presented in the available text that reduce a claimed prediction or result to a fitted parameter or prior self-referential definition by construction. The central results rest on experimental comparisons to finer-resolution models and state-of-the-art benchmarks rather than any self-definitional loop or renamed input. This is the expected outcome for an empirical architecture paper with released code; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
block-sparse attention... sharing keys and values across spatially adjacent queries... HEALPix mesh... near-perfect spectral alignment across all resolved frequencies
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
spectral power ratios... individual ensemble members... near-perfect spectral alignment
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Uncertainty-aware Machine Learning Interatomic Potentials via Learned Functional Perturbations
Learned functional perturbations convert deterministic ML interatomic potentials to probabilistic models trained with CRPS, improving uncertainty calibration over Bayesian baselines on N-body and silica benchmarks.
Reference graph
Works this paper leans on
-
[1]
Brandstetter, J., Worrall, D. E., and Welling, M. Mes- sage passing neural PDE solvers. InThe Tenth Inter- national Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29,
work page 2022
-
[2]
ECMWF. Medium-range forecasts. URL https://www.ecmwf.int/en/forecasts/ documentation-and-support/ medium-range-forecasts. Accessed: 2026-01-
work page 2026
-
[3]
Ablation Study We conduct ablation experiments to validate MOSAIC’s key design choices
13 (Sparse) Attention to the Details A. Ablation Study We conduct ablation experiments to validate MOSAIC’s key design choices. To make ablations tractable, all variants, including the ablation baseline, are trained under a reduced-scale protocol that differs from the full model (Section C.4) in several ways: training uses ERA5 data from 2007–2018 only (v...
work page 2007
-
[4]
to the remaining surface and pressure-level variables: 10-meter V-wind, mean sea level pressure, U- and V-wind at 850 hPa, and specific humidity at 700 hPa. Rows 1–2 show RMSE, rows 3–4 show CRPS, and rows 5–6 show the spread-to-skill ratio (values close to 1.0 indicate well-calibrated ensembles). All forecasts are regridded to 1.5° resolution. 15 (Sparse...
work page 2022
-
[5]
All metrics are evaluated at 1.5° resolution
4.773 4.828 1.992 563.2 3.339 3.534 Table 5.RMSE scores for key weather variables at 240 h (10-day) lead time. All metrics are evaluated at 1.5° resolution. B.3. Hurricane Ian Case Study Fig. 9 shows the 10-meter wind speed evolution from a single MOSAICrun initialized on September 23, 2022, 12Z (5 days before Hurricane Ian’s Category 4 landfall). Ground ...
work page 2022
-
[6]
Table 6 reports the GMSP drift relative to the initial condition
and evaluate over the 2020 test year: 712 initialization dates (00:00 and 12:00 UTC, 2020 year) with 48 ensemble members each. Table 6 reports the GMSP drift relative to the initial condition. The maximum mean drift after 10 days is−0.086hPa (0.009%relative to∼1013hPa), confirming that MOSAICneither systematically creates nor destroys atmospheric mass ove...
work page 2020
-
[7]
For the 0.25◦ benchmark, we finetune on HRES-fc0 analysis from 2016–2021 and test on
work page 2016
-
[8]
as Zarr archives on Google Cloud Storage. ERA5 reanalysis is provided as 1959-2023 01 10-6h-240x121 equiangular with poles conservative.zarrand HRES-fc0 analysis as2016-2022-6h-240x121 equiangular with poles conservative.zarr. Both datasets are conserva- tively remapped from their native grids to a240×121equiangular latitude-longitude grid (1.5° resolutio...
work page 1959
-
[9]
Learning rate warmup.Pretraining uses no warmup
The base learning rate is0.02; per-stage values are listed in Table 10 and follow the cosine schedule described therein. Learning rate warmup.Pretraining uses no warmup. All finetuning stages employ a 500-step linear warmup from 10−6 ×ηto the stage-specific learning rateη, followed by cosine annealing. Early stopping.We apply early stopping based on valid...
work page 2022
-
[10]
Loss Function The training objective is the latitude-weighted, variable-weighted fair CRPS (Eq
C.5. Loss Function The training objective is the latitude-weighted, variable-weighted fair CRPS (Eq. 16): L= 1 |D| X d∈D 1 HW X h,w CX i=1 αi ωh CRPS(ˆx1:N i,h,w,d,ˆyi,h,w,d),(18) wheredindexes the batch,(h, w)indexes spatial grid points on theH×Wlatitude-longitude grid,iindexes theC=82 output channels,α i is the per-channel variable weight, andω h is the...
work page 2023
-
[11]
implementation as foundation and following the memory-efficient approach of FlashAttention (Dao et al., 2022). The forward pass loads query blocks into SRAM and streams selected key-value blocks through, computing attention without materializing the full attention matrix. The backward pass computes gradients for keys and values by iterating over all query...
work page 2022
-
[12]
on Google Cloud Storage. HRES-f0 (Ground Truth) MOSAIC(1st member) MOSAIC(mean) Figure 12.Forecast rollout trajectories showing 10-day evolution of wind speed fields at 850 hPa. 26 (Sparse) Attention to the Details HRES-f0 (Ground Truth) MOSAIC(1st member) MOSAIC(mean) Figure 13.Forecast rollout trajectories showing 10-day evolution of surface temperature...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.