DexHoldem: Playing Texas Hold'em with Dexterous Embodied System
Pith reviewed 2026-05-20 09:34 UTC · model grok-4.3
The pith
DexHoldem provides a physical benchmark that tests whether embodied agents can perceive, decide, and dexterously manipulate cards through a full Texas Hold'em game loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
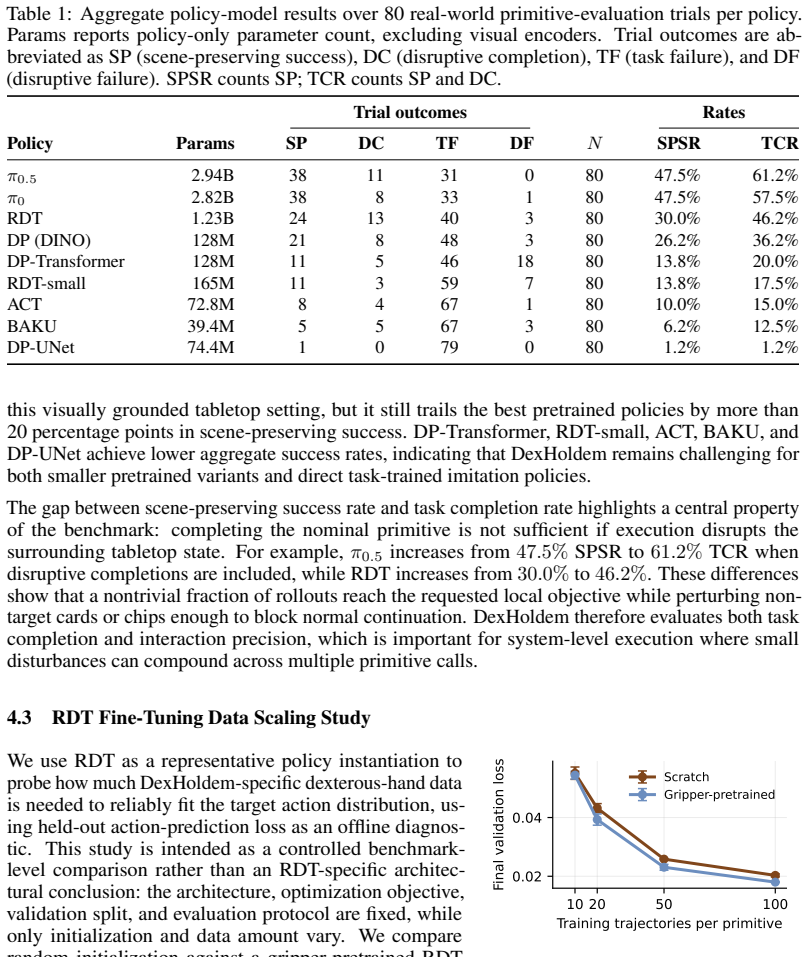
DexHoldem evaluates dexterous tabletop execution, agentic perception, and embodied decision routing in a shared physical setting. The best policy reaches 61.2 percent task completion and 47.5 percent scene-preserving success on the primitives. The strongest perception model attains 34.3 percent strict problem-level accuracy while reaching 66.8 percent average field-wise accuracy, revealing a gap between isolated visual capabilities and complete state recovery needed for routing. Three case studies instantiate the full embodied loop to demonstrate error accumulation across repeated primitive executions.
What carries the argument
The DexHoldem benchmark, which supplies demonstrations for 14 Texas Hold'em primitives, runs standardized policy and agentic-perception evaluations on physical hardware, and closes the loop with waiting, recovery, and help-request behaviors.
If this is right
- Policies achieve at most 61.2 percent task completion and 47.5 percent scene-preserving success on the 14 primitives.
- Perception models exhibit a large gap between 66.8 percent field-wise accuracy and 34.3 percent strict game-state accuracy required for decision routing.
- Closed-loop deployments reveal compounding errors across perception, policy, and repeated primitive executions.
- The benchmark explicitly supports testing of recovery dispatches, human-help requests, and scene-maintenance behaviors.
Where Pith is reading between the lines
- The same structured game-state recovery tasks could be applied to other multi-step tabletop activities to test generality beyond poker.
- Directly feeding perception outputs into policy inputs might shrink the observed error accumulation across full loops.
- Repeating the evaluations on different dexterous hardware would show whether the performance numbers are specific to the ShadowHand.
- Extending runs to complete multi-hand games would expose whether the current primitives scale to longer sequences.
Load-bearing premise
The 14 chosen Texas Hold'em manipulation primitives and the defined agentic perception tasks are representative of the core challenges faced by embodied agents in dynamic, multi-step physical scenes.
What would settle it
A new policy or perception model run on the identical physical DexHoldem setup that exceeds 61.2 percent task completion or 34.3 percent strict accuracy would directly test whether the reported performance ceilings are fundamental or merely current limits.
Figures







read the original abstract
Evaluating embodied systems on real dexterous hardware requires more than isolated primitive skills: an agent must perceive a changing tabletop scene, choose a context-appropriate action, execute it with a dexterous hand, and leave the scene usable for later decisions. We introduce DexHoldem, a real-world system-level benchmark built around Texas Hold'em dexterous manipulation with a ShadowHand. DexHoldem provides 1,470 teleoperated demonstrations across 14 Texas Hold'em manipulation primitives, a standardized physical policy benchmark, and an agentic perception benchmark that tests whether agents can recover the structured game state needed for embodied decision making. On primitive execution, $\pi_{0.5}$ obtains the highest task completion rate ($61.2\%$), while $\pi_{0.5}$ and $\pi_0$ tie on scene-preserving success rate ($47.5\%$). On agentic perception, Opus 4.7 obtains the best strict problem-level accuracy ($34.3\%$), while GPT 5.5 obtains the best average field-wise accuracy ($66.8\%$), exposing a gap between isolated visual sub-capabilities and complete routing-relevant state recovery. Finally, we instantiate the full embodied-agent loop in three case studies, where waiting, recovery dispatches, human-help requests, and repeated primitive execution reveal how perception and policy errors accumulate during closed-loop deployment. DexHoldem therefore evaluates dexterous tabletop execution, agentic perception, and embodied decision routing in a shared physical setting. Project page: https://dexholdem.github.io/Dexholdem/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DexHoldem, a real-world system-level benchmark for dexterous embodied agents centered on Texas Hold'em card manipulation using a ShadowHand. It contributes 1,470 teleoperated demonstrations across 14 manipulation primitives, a standardized physical policy benchmark reporting task completion and scene-preservation metrics, an agentic perception benchmark measuring recovery of structured game state, and three closed-loop case studies illustrating error accumulation in perception-policy loops.
Significance. If the benchmark's scope is validated, DexHoldem offers a concrete, hardware-grounded testbed that integrates perception, decision routing, and dexterous execution in a shared physical setting, exposing gaps between isolated visual capabilities and complete state recovery needed for embodied decisions. The physical experiments, teleoperated demonstration collection, and explicit case studies on waiting/recovery/human-help behaviors provide reproducible empirical grounding that strengthens claims about real-world deployment challenges.
major comments (1)
- [§3] §3 (Benchmark Design): The 14 Texas Hold'em manipulation primitives are introduced as representative of core dexterous tabletop challenges without ablations against alternative tasks, explicit transfer experiments, or quantitative justification that success on these primitives predicts performance on broader multi-step dynamic scenes; this modeling choice is load-bearing for the central claim that DexHoldem evaluates dexterous execution and embodied decision routing in representative physical settings.
minor comments (2)
- [Figure 4] Figure 4 and §5.2: The perception accuracy tables would benefit from clearer error bars or per-run variance to allow readers to assess stability of the reported 34.3% strict accuracy and 66.8% field-wise accuracy.
- [§6] §6 (Case Studies): The three closed-loop examples are described qualitatively; adding quantitative metrics on error propagation rates across the full loop would strengthen the illustration of how perception and policy errors accumulate.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential of DexHoldem as a hardware-grounded benchmark integrating perception, policy, and dexterous execution. We address the single major comment on benchmark design below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Design): The 14 Texas Hold'em manipulation primitives are introduced as representative of core dexterous tabletop challenges without ablations against alternative tasks, explicit transfer experiments, or quantitative justification that success on these primitives predicts performance on broader multi-step dynamic scenes; this modeling choice is load-bearing for the central claim that DexHoldem evaluates dexterous execution and embodied decision routing in representative physical settings.
Authors: We appreciate the referee's point that the selection of the 14 primitives is central to our claims. These primitives were systematically derived from the rules and typical flow of Texas Hold'em, covering the full range of required physical interactions: deck dealing, card flipping and revealing, chip pushing and stacking, and community-card organization. The set was refined through consultation with professional dealers and prior dexterous-manipulation literature to ensure coverage of contact-rich, precision, and in-hand skills that appear in real gameplay. We agree that ablations against alternative task sets or explicit transfer studies would further strengthen generalizability arguments; however, the primary goal of this work is to release a reproducible, domain-specific benchmark rather than to optimize or validate a universal task taxonomy. In the revised manuscript we have added a dedicated paragraph in §3 that (i) lists the explicit mapping from each primitive to core dexterous challenges, (ii) provides frequency estimates drawn from recorded poker sessions, and (iii) references established manipulation taxonomies to supply the requested quantitative grounding. This addition directly supports the claim that success on these primitives is indicative of performance in the broader multi-step physical scenes that constitute the benchmark. revision: yes
Circularity Check
Empirical benchmark with no derivation chain
full rationale
The paper introduces DexHoldem as a physical benchmark consisting of teleoperated demonstrations, policy evaluations on hardware, and perception model tests. All reported numbers (61.2% task completion, 34.3% strict accuracy, etc.) are direct empirical measurements from runs on the defined primitives and tasks. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs; the 14 primitives and game-state recovery tasks are explicitly chosen modeling decisions rather than derived results. No self-citation load-bearing steps or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- Selection of 14 primitives
axioms (1)
- domain assumption Teleoperated human demonstrations provide a suitable reference distribution for evaluating robot policy performance on the same primitives.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DexHoldem provides 1,470 teleoperated demonstrations across 14 Texas Hold'em manipulation primitives, a standardized physical policy benchmark, and an agentic perception benchmark that tests whether agents can recover the structured game state needed for embodied decision making.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On primitive execution, π0.5 obtains the highest task completion rate (61.2%), while π0.5 and π0 tie on scene-preserving success rate (47.5%).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Robel: Robotics benchmarks for learning with low-cost robots
Michael Ahn, Henry Zhu, Kristian Hartikainen, Hugo Ponte, Abhishek Gupta, Sergey Levine, and Vikash Kumar. Robel: Robotics benchmarks for learning with low-cost robots. InConfer- ence on robot learning, pp. 1300–1313. PMLR, 2020
work page 2020
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
OpenAI: Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafal Jozefowicz, Bob Mc- Grew, Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, et al. Learning dexterous in-hand manipulation.The International Journal of Robotics Research, 39(1):3–20, 2020
work page 2020
-
[4]
Dexart: Benchmarking generalizable dexterous manipulation with articulated objects, 2023
Chen Bao, Helin Xu, Yuzhe Qin, and Xiaolong Wang. Dexart: Benchmarking generalizable dexterous manipulation with articulated objects, 2023. URL https://arxiv.org/abs/2305. 05706
work page 2023
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. URL https: //arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Rt-1: Robotics transformer for real-world control at scale, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, ...
work page 2023
-
[7]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Henry Charlesworth and Giovanni Montana. Solving challenging dexterous manipulation tasks with trajectory optimisation and reinforcement learning, 2021. URL https://arxiv.org/ abs/2009.05104
-
[9]
Jiayi Chen, Yubin Ke, and He Wang. Bodex: Scalable and efficient robotic dexterous grasp synthesis using bilevel optimization.arXiv preprint arXiv:2412.16490, 2024
-
[10]
Tao Chen, Megha Tippur, Siyang Wu, Vikash Kumar, Edward Adelson, and Pulkit Agrawal. Visual dexterity: In-hand reorientation of novel and complex object shapes.Science Robotics, 8 (84):eadc9244, 2023
work page 2023
-
[11]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, Weiliang Deng, Yubin Guo, Tian Nian, Xuanbing Xie, Qiangyu Chen, Kailun Su, Tianling Xu, Guodong Liu, Mengkang Hu, Huan ang Gao, Kaixuan Wang, Zhixuan Liang, Yusen Qin, Xiaokang Yang, Ping Luo, and Yao Mu. Robotwin 2.0: A scalable d...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations, 2020. URL https://arxiv.org/abs/ 2002.05709. 10
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
Towards human-level bimanual dexterous manipulation with reinforcement learning
Yuanpei Chen, Yaodong Yang, Tianhao Wu, Shengjie Wang, Xidong Feng, Jiechuan Jiang, Zongqing Lu, Stephen Marcus McAleer, Hao Dong, and Song-Chun Zhu. Towards human-level bimanual dexterous manipulation with reinforcement learning. InThirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022. URL https://openreview...
work page 2022
-
[14]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[15]
Benchmarking in-hand manipulation.IEEE Robotics and Automation Letters, 5(2):588–595, April 2020
Silvia Cruciani, Balakumar Sundaralingam, Kaiyu Hang, Vikash Kumar, Tucker Hermans, and Danica Kragic. Benchmarking in-hand manipulation.IEEE Robotics and Automation Letters, 5(2):588–595, April 2020. ISSN 2377-3774. doi: 10.1109/lra.2020.2964160. URL http://dx.doi.org/10.1109/LRA.2020.2964160
-
[16]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. Palm-e: An embodied ...
work page 2023
-
[17]
D4rl: Datasets for deep data-driven reinforcement learning, 2021
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning, 2021. URL https://arxiv.org/abs/2004. 07219
work page 2021
-
[18]
Maniskill2: A unified benchmark for generalizable manipulation skills
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, and Hao Su. Maniskill2: A unified benchmark for generalizable manipulation skills, 2023. URL https://arxiv.org/abs/2302.04659
-
[19]
Baku: An efficient transformer for multi-task policy learning, 2024
Siddhant Haldar, Zhuoran Peng, and Lerrel Pinto. Baku: An efficient transformer for multi-task policy learning, 2024. URLhttps://arxiv.org/abs/2406.07539
-
[20]
Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer, 2021. URLhttps://arxiv.org/abs/2102.01293
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Inner monologue: Embodied reasoning through planning with language models, 2022
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, and Brian Ichter. Inner monologue: Embodied reasoning through planning with language models, 2022
work page 2022
-
[22]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. Rlbench: The robot learning benchmark & learning environment, 2019. URL https://arxiv.org/abs/1909. 12271
work page 2019
-
[25]
Vima: General robot manipulation with multimodal prompts
Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. Vima: General robot manipulation with multimodal prompts. InFortieth International Conference on Machine Learning, 2023. 11
work page 2023
-
[26]
Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning
Zhenyu Jiang, Yuqi Xie, Kevin Lin, Zhenjia Xu, Weikang Wan, Ajay Mandlekar, Linxi Jim Fan, and Yuke Zhu. Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 16923–16930. IEEE, 2025
work page 2025
-
[27]
Yuanchen Ju, Yongyuan Liang, Yen-Jen Wang, Nandiraju Gireesh, Yuanliang Ju, Seungjae Lee, Qiao Gu, Elvis Hsieh, Furong Huang, and Koushil Sreenath. Momagraph: State-aware unified scene graphs with vision-language model for embodied task planning.International Conference on Learning Representations (ICLR) Oral, 2026
work page 2026
-
[28]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Big Transfer (BiT): General Visual Repre- sentation Learning, 2020
Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (bit): General visual representation learning, 2020. URL https://arxiv.org/abs/1912.11370
-
[30]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Robohive – a unified framework for robot learning
Vikash Kumar, Rutav Shah, Gaoyue Zhou, Vincent Moens, Vittorio Caggiano, Jay Vakil, Abhishek Gupta, and Aravind Rajeswaran. Robohive – a unified framework for robot learning. InNeurIPS: Conference on Neural Information Processing Systems, 2023. URL https: //sites.google.com/view/robohive
work page 2023
-
[32]
Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control, 2023. URL https://arxiv.org/abs/2209.07753
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URL https: //arxiv.org/abs/2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation, 2025. URLhttps://arxiv.org/abs/2410.07864
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Realdex: Towards human-like grasping for robotic dexterous hand,
Yumeng Liu, Yaxun Yang, Youzhuo Wang, Xiaofei Wu, Jiamin Wang, Yichen Yao, Sören Schwertfeger, Sibei Yang, Wenping Wang, Jingyi Yu, and Yuexin Ma. Realdex: Towards human-like grasping for robotic dexterous hand.arXiv preprint arXiv:2402.13853, 2024. URL https://arxiv.org/abs/2402.13853
-
[36]
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations.arXiv preprint arXiv:2310.17596, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks, 2022. URL https://arxiv.org/abs/2112.03227
-
[38]
Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations, 2021
Tongzhou Mu, Zhan Ling, Fanbo Xiang, Derek Yang, Xuanlin Li, Stone Tao, Zhiao Huang, Zhiwei Jia, and Hao Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations, 2021
work page 2021
-
[39]
Robotwin: Dual-arm robot benchmark with generative digital twins (early version), 2025
Yao Mu, Tianxing Chen, Shijia Peng, Zanxin Chen, Zeyu Gao, Yude Zou, Lunkai Lin, Zhiqiang Xie, and Ping Luo. Robotwin: Dual-arm robot benchmark with generative digital twins (early version), 2025. URLhttps://arxiv.org/abs/2409.02920
-
[40]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots, 2024. URLhttps://arxiv.org/abs/2406.02523. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Charles Xu, Jianlan Luo, Tobias Kreiman, You Liang Tan, Lawrence Yun- liang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science a...
work page 2024
-
[42]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Virtualhome: Simulating household activities via programs
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. Virtualhome: Simulating household activities via programs. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 8494–8502, 2018
work page 2018
-
[44]
Dexpoint: General- izable point cloud reinforcement learning for sim-to-real dexterous manipulation
Yuzhe Qin, Binghao Huang, Zhao-Heng Yin, Hao Su, and Xiaolong Wang. Dexpoint: General- izable point cloud reinforcement learning for sim-to-real dexterous manipulation. InConference on Robot Learning, pp. 594–605. PMLR, 2023
work page 2023
-
[45]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.arXiv preprint arXiv:1709.10087, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision, pp. 9339–9347, 2019
work page 2019
-
[48]
Shadow Robot Company.Shadow Dexterous Hand - Technical Specification. Shadow Robot Company, 2025. URL https://shadowrobot.com/wp-content/uploads/2025/ 09/shadow_dexterous_hand_e_technical_specification.pdf
work page 2025
-
[49]
Shadow teleoperation system: Technical specification, Septem- ber 2025
Shadow Robot Company. Shadow teleoperation system: Technical specification, Septem- ber 2025. URL https://shadowrobot.com/wp-content/uploads/2025/09/shadow_ teleop_technical_specification.pdf. Technical specification
work page 2025
-
[50]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mot- taghi, Luke Zettlemoyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10740–10749, 2020
work page 2020
-
[51]
Karen Liu, Silvio Savarese, Hyowon Gweon, Jiajun Wu, and Li Fei-Fei
Sanjana Srivastava, Chengshu Li, Michael Lingelbach, Roberto Martín-Martín, Fei Xia, Kent Vainio, Zheng Lian, Cem Gokmen, Shyamal Buch, C. Karen Liu, Silvio Savarese, Hyowon Gweon, Jiajun Wu, and Li Fei-Fei. Behavior: Benchmark for everyday household activities in virtual, interactive, and ecological environments, 2021
work page 2021
-
[52]
Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai, 2025
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse kai Chan, Yuan Gao, Xuanlin Li, Tongzhou Mu, Nan Xiao, Arnav Gurha, Viswesh Nagaswamy Rajesh, Yong Woo Choi, Yen-Ru Chen, Zhiao Huang, Roberto Calandra, Rui Chen, Shan Luo, and Hao Su. Maniskill3: Gpu parallelized robotics simulation and r...
work page 2025
-
[53]
Fast-grasp’d: Dexterous multi-finger grasp generation through differentiable simulation, 2023
Dylan Turpin, Tao Zhong, Shutong Zhang, Guanglei Zhu, Jingzhou Liu, Ritvik Singh, Eric Heiden, Miles Macklin, Stavros Tsogkas, Sven Dickinson, and Animesh Garg. Fast-grasp’d: Dexterous multi-finger grasp generation through differentiable simulation, 2023. URL https: //arxiv.org/abs/2306.08132. 13
-
[54]
Qineng Wang, Wenlong Huang, Yu Zhou, Hang Yin, Tianwei Bao, Jianwen Lyu, Weiyu Liu, Ruohan Zhang, Jiajun Wu, Fei-Fei Li, and Manling Li. Enact: Evaluating embodied cognition with world modeling of egocentric interaction.arXiv preprint arXiv:2511.20937, 2025
-
[55]
Dexh2r: A benchmark for dynamic dexterous grasping in human-to- robot handover, 2025
Youzhuo Wang, Jiayi Ye, Chuyang Xiao, Yiming Zhong, Heng Tao, Hang Yu, Yumeng Liu, Jingyi Yu, and Yuexin Ma. Dexh2r: A benchmark for dynamic dexterous grasping in human-to- robot handover, 2025. URLhttps://arxiv.org/abs/2506.23152
-
[56]
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, et al. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents.arXiv preprint arXiv:2502.09560, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Dex1b: Learning with 1b demonstrations for dexterous manipulation,
Jianglong Ye, Keyi Wang, Chengjing Yuan, Ruihan Yang, Yiquan Li, Jiyue Zhu, Yuzhe Qin, Xueyan Zou, and Xiaolong Wang. Dex1b: Learning with 1b demonstrations for dexterous manipulation, 2025. URLhttps://arxiv.org/abs/2506.17198
-
[58]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pp. 1094–1100. PMLR, 2020
work page 2020
-
[59]
Jialiang Zhang, Haoran Liu, Danshi Li, Xinqiang Yu, Haoran Geng, Yufei Ding, Jiayi Chen, and He Wang. Dexgraspnet 2.0: Learning generative dexterous grasping in large-scale synthetic cluttered scenes, 2024. URLhttps://arxiv.org/abs/2410.23004
-
[60]
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks, 2024. URL https://arxiv.org/abs/2412.18194
-
[61]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pp. 2165–2183. PMLR, 2023. 14 A Author Contributions Feng Co-proposed and led the project; designed the data-collec...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.