Clarify, Abstain or Answer? Strategising in Conversation with Belief-Augmented Generation
Pith reviewed 2026-06-29 21:21 UTC · model grok-4.3
The pith
Belief-Augmented Generation lets LLMs decide to answer, clarify or abstain by reasoning over K samples of their own outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
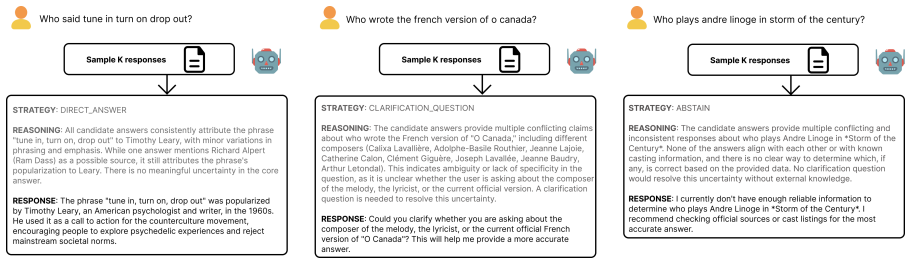
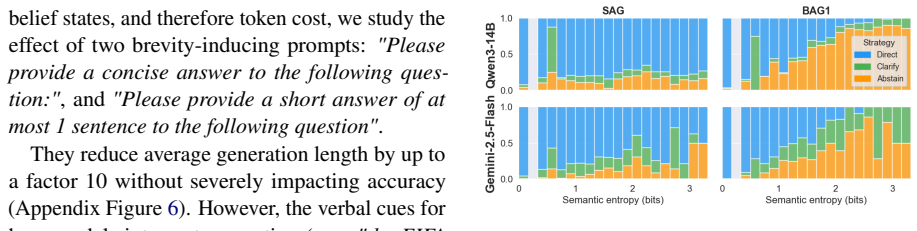
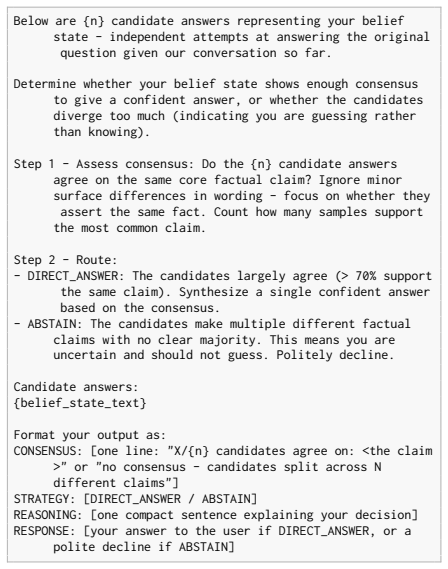
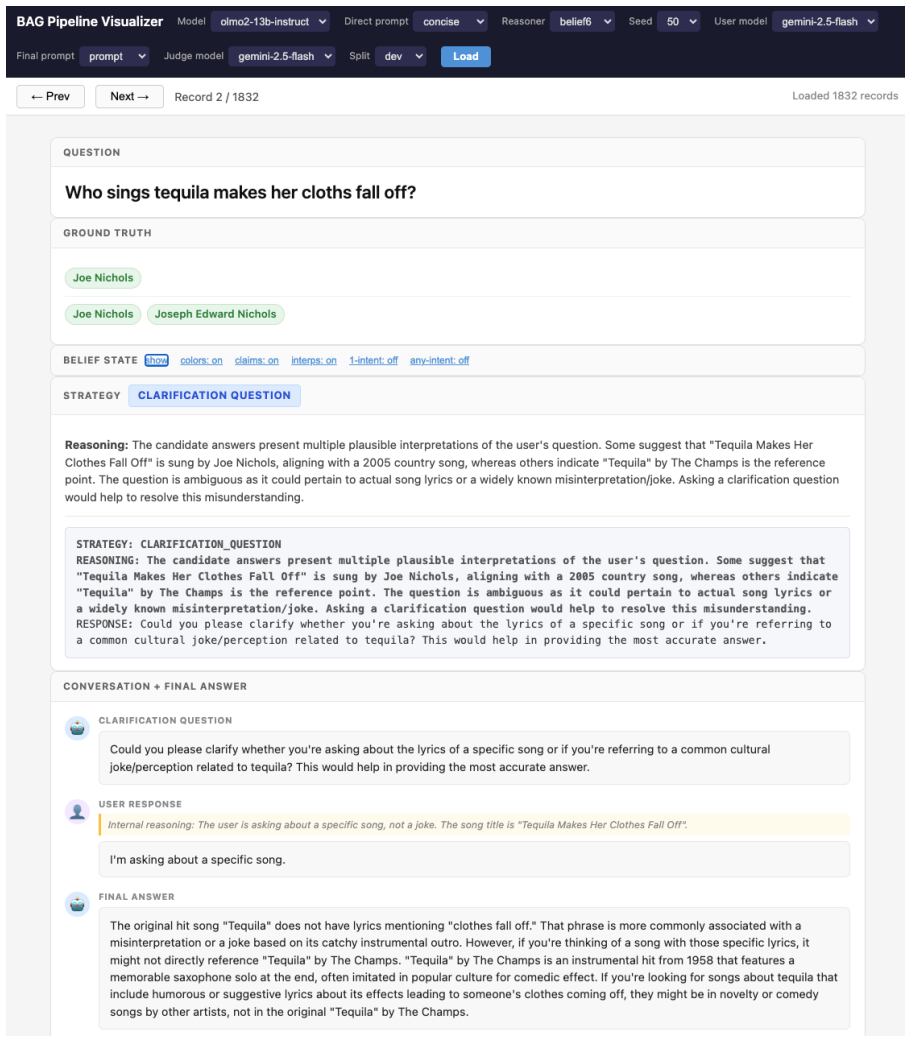
BAG incorporates K responses sampled from an LLM into its prompt and instructs the model to reason over those samples when selecting among answer, clarify, or abstain. In a multi-turn ambiguous QA setting this produces higher accuracy than baselines and strategy decisions that align more closely with the model's sampled belief state, although the distinction between clarification and abstention remains difficult to control.
What carries the argument
Belief-Augmented Generation (BAG), the mechanism that inserts K model-generated samples into the prompt so the LLM can reason over its own belief state before choosing a conversational strategy.
If this is right
- BAG raises QA accuracy across six different language models.
- Strategy decisions become more faithful to the model's sampled belief state than those from prompt-only methods.
- Default LLMs continue to ignore input and factual uncertainty by almost never choosing to clarify or abstain.
- Disentangling when to clarify versus when to abstain remains an open control problem even with BAG.
Where Pith is reading between the lines
- The method could be tested on other multi-turn tasks such as negotiation or tutoring where uncertainty signals matter.
- If the K-sample prompt technique scales, it offers a training-free route to uncertainty-aware generation in any sampling-based model.
- Persistent difficulty separating clarification from abstention suggests the belief state alone may not be sufficient and additional signals or fine-tuning could be needed.
Load-bearing premise
That including K samples in the prompt and prompting the model to reason over them is enough to produce strategy decisions faithful to the underlying belief state without any further training or manual tuning.
What would settle it
A controlled test in which BAG strategy outputs show no higher correlation with the distribution of the K samples than prompt-only baselines, or produce no accuracy improvement on the same ambiguous QA tasks.
Figures











read the original abstract
Large language models (LLMs) define a distribution over text, which can be viewed as a probabilistic representation of uncertainty: sampling K responses yields a belief state - responses a model deems plausible. Existing work exploits this representation for narrow tasks like either decoding or selective prediction, and often requires manual interventions, not controlling generation directly. We propose Belief-Augmented Generation (BAG): grounding LLMs in their own belief state via the prompt and letting them reason over these K samples to decide on a conversational strategy: answer, clarify, or abstain. In a multi-turn ambiguous QA setting, we find that LLMs by default rarely clarify or abstain, ignoring uncertainty about the input or facts. BAG improves QA accuracy across six models and yields strategy decisions more faithful to the belief state than prompt-only baselines. Disentangling when to clarify from when to abstain, however, remains challenging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Belief-Augmented Generation (BAG), a prompting method that samples K responses from an LLM to form a belief state over plausible outputs, then incorporates these samples into the prompt so the model can reason over them and select a conversational strategy (answer, clarify, or abstain) in multi-turn ambiguous QA. The central claim is that BAG raises QA accuracy across six models and produces strategy decisions more faithful to the underlying belief state than prompt-only baselines, while noting that separating clarification from abstention remains difficult.
Significance. If the reported accuracy gains and faithfulness improvements prove robust under proper controls, the work would offer a training-free route to uncertainty-aware strategy selection in dialogue, extending sampling-based uncertainty representations from narrow decoding or selective-prediction tasks to direct control of generation behavior. The explicit acknowledgment of the clarify/abstain disentanglement problem is a constructive limitation statement.
major comments (1)
- Abstract: the central claims of accuracy improvement across six models and greater faithfulness of strategy decisions are stated without any quantitative results, baseline specifications, dataset descriptions, evaluation metrics, or statistical tests, so the claims cannot be assessed from the manuscript as presented.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the concern regarding the abstract below and will make the requested revisions.
read point-by-point responses
-
Referee: Abstract: the central claims of accuracy improvement across six models and greater faithfulness of strategy decisions are stated without any quantitative results, baseline specifications, dataset descriptions, evaluation metrics, or statistical tests, so the claims cannot be assessed from the manuscript as presented.
Authors: We agree that the abstract would be more informative and allow immediate assessment of the claims if it included key quantitative highlights. In the revised version we will add concise statements of the main results (e.g., average accuracy gains across the six models and the faithfulness improvement relative to prompt-only baselines) while retaining the high-level description. Full experimental details, metrics, and statistical information remain in Sections 4 and 5; the abstract change is intended only to improve readability and transparency. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical comparison of Belief-Augmented Generation (BAG) against prompt-only baselines in ambiguous QA. It reports accuracy gains across six models and more faithful strategy decisions without any equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations. The central claims rest on experimental outcomes rather than any self-referential reduction to inputs by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chinmaya Andukuri, Jan-Philipp Fr \"a nken, Tobias Gerstenberg, and Noah Goodman. 2024. https://openreview.net/forum?id=CrzAj0kZjR ST ar- GATE : Teaching language models to ask clarifying questions . In First Conference on Language Modeling
2024
- [2]
-
[3]
Joris Baan, Raquel Fern \'a ndez, Barbara Plank, and Wilker Aziz. 2024. https://doi.org/10.18653/v1/2024.eacl-short.24 Interpreting predictive probabilities: Model confidence or human label variation? In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers), pages 268--277, St....
- [4]
-
[5]
Amanda Bertsch, Alex Xie, Graham Neubig, and Matthew Gormley. 2023. https://doi.org/10.18653/v1/2023.bigpicture-1.9 It ' s MBR all the way down: Modern generation techniques through the lens of minimum B ayes risk . In Proceedings of the Big Picture Workshop, pages 108--122, Singapore. Association for Computational Linguistics
-
[6]
Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. 2025. https://doi.org/10.3386/w34255 How people use chatgpt . Working Paper 34255, National Bureau of Economic Research
-
[7]
Maximillian Chen, Ruoxi Sun, Tomas Pfister, and Sercan O Arik. 2025. https://openreview.net/forum?id=SIE6VFps9x Learning to clarify: Multi-turn conversations with action-based contrastive self-training . In The Thirteenth International Conference on Learning Representations
2025
-
[8]
Jeremy Cole, Michael Zhang, Daniel Gillick, Julian Eisenschlos, Bhuwan Dhingra, and Jacob Eisenstein. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.35 Selectively answering ambiguous questions . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 530--543, Singapore. Association for Computational Linguistics
-
[9]
Yang Deng, Lizi Liao, Liang Chen, Hongru Wang, Wenqiang Lei, and Tat-Seng Chua. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.711 Prompting and evaluating large language models for proactive dialogues: Clarification, target-guided, and non-collaboration . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10602--10621,...
-
[10]
Bryan Eikema and Wilker Aziz. 2020. https://doi.org/10.18653/v1/2020.coling-main.398 Is MAP decoding all you need? the inadequacy of the mode in neural machine translation . In Proceedings of the 28th International Conference on Computational Linguistics, pages 4506--4520, Barcelona, Spain (Online). International Committee on Computational Linguistics
- [11]
-
[12]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017):625--630
2024
-
[13]
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.398 Enabling large language models to generate text with citations . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6465--6488, Singapore. Association for Computational Linguistics
-
[14]
Yifan Gao, Henghui Zhu, Patrick Ng, Cicero Nogueira dos Santos, Zhiguo Wang, Feng Nan, Dejiao Zhang, Ramesh Nallapati, Andrew O. Arnold, and Bing Xiang. 2021. https://doi.org/10.18653/v1/2021.acl-long.253 Answering ambiguous questions through generative evidence fusion and round-trip prediction . In Proceedings of the 59th Annual Meeting of the Associatio...
-
[15]
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. 2024. https://doi.org/10.18653/v1/2024.naacl-long.366 A survey of confidence estimation and calibration in large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technol...
-
[16]
Mario Giulianelli, Joris Baan, Wilker Aziz, Raquel Fern \'a ndez, and Barbara Plank. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.887 What comes next? evaluating uncertainty in neural text generators against human production variability . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14349--14371, Si...
-
[17]
Bairu Hou, Yujian Liu, Kaizhi Qian, Jacob Andreas, Shiyu Chang, and Yang Zhang. 2024. Decomposing uncertainty for large language models through input clarification ensembling. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org
2024
-
[18]
Hyuhng Joon Kim, Youna Kim, Cheonbok Park, Junyeob Kim, Choonghyun Park, Kang Min Yoo, Sang-goo Lee, and Taeuk Kim. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.119 Aligning language models to explicitly handle ambiguity . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1989--2007, Miami, Florida, USA....
-
[19]
Michael Kirchhof, Luca F \"u ger, Adam Golinski, Eeshan Gunesh Dhekane, Arno Blaas, and Sinead Williamson. 2025. Self-reflective uncertainties: Do llms know their internal answer distribution? In ICML 2025 Workshop on Reliable and Responsible Foundation Models
2025
-
[20]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023 a . https://openreview.net/pdf?id=VQWuqgSoVN Clam: Selective clarification for ambiguous questions with generative language models . Workshop on Challenges in Deployable Generative AI at International Conference on Machine Learning (ICML)
2023
-
[21]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023 b . https://openreview.net/forum?id=VD-AYtP0dve Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation . In The Eleventh International Conference on Learning Representations
2023
-
[22]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. https://doi.org/10.1162/tacl_a_00276 Natural questions: A benchma...
-
[23]
Dongryeol Lee, Segwang Kim, Minwoo Lee, Hwanhee Lee, Joonsuk Park, Sang-Woo Lee, and Kyomin Jung. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.772 Asking clarification questions to handle ambiguity in open-domain QA . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 11526--11544, Singapore. Association for Computati...
-
[24]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, and 1 others. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459--9474
2020
-
[25]
Zongxi Li, Yang Li, Haoran Xie, and S. Joe Qin. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.115 C ond A mbig QA : A benchmark and dataset for conditional ambiguous question answering . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2269--2288, Suzhou, China. Association for Computational Linguistics
-
[26]
Sewon Min, Kenton Lee, Ming-Wei Chang, Kristina Toutanova, and Hannaneh Hajishirzi. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.560 Joint passage ranking for diverse multi-answer retrieval . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6997--7008, Online and Punta Cana, Dominican Republic. Associat...
-
[27]
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.466 A mbig QA : Answering ambiguous open-domain questions . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5783--5797, Online. Association for Computational Linguistics
-
[28]
Yang Nan, Pengfei He, Ravi Tandon, and Han Xu. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.841 Can multiple responses from an LLM reveal the sources of its uncertainty? In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 15551--15569, Suzhou, China. Association for Computational Linguistics
-
[29]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, and 1 others. 2025. Olmo 3. arXiv preprint arXiv:2512.13961
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Sergey Pletenev, Maria Marina, Nikolay Ivanov, Daria Galimzianova, Nikita Krayko, Mikhail Salnikov, Vasily Konovalov, Alexander Panchenko, and Viktor Moskvoretskii. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.434 Will it still be true tomorrow? multilingual evergreen question classification to improve trustworthy QA . In Proceedings of the 2025 Conf...
-
[31]
Irina Saparina and Mirella Lapata. 2025. Reasoning about intent for ambiguous requests. arXiv preprint arXiv:2511.10453
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Anastasiia Sedova, Robert Litschko, Diego Frassinelli, Benjamin Roth, and Barbara Plank. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.1003 To know or not to know? analyzing self-consistency of large language models under ambiguity . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 17203--17217, Miami, Florida, USA. ...
-
[33]
Omar Shaikh, Kristina Gligoric, Ashna Khetan, Matthias Gerstgrasser, Diyi Yang, and Dan Jurafsky. 2024. https://doi.org/10.18653/v1/2024.naacl-long.348 Grounding gaps in language model generations . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: L...
-
[34]
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2025. https://openreview.net/forum?id=4FWAwZtd2n Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning . In The Thirteenth International Conference on Learning Representations
2025
-
[35]
Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming-Wei Chang. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.566 ASQA : Factoid questions meet long-form answers . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8273--8288, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[36]
Mirac Suzgun, Luke Melas-Kyriazi, and Dan Jurafsky. 2023. https://doi.org/10.18653/v1/2023.findings-acl.262 Follow the wisdom of the crowd: Effective text generation via minimum B ayes risk decoding . In Findings of the Association for Computational Linguistics: ACL 2023, pages 4265--4293, Toronto, Canada. Association for Computational Linguistics
-
[37]
Rossi, Sungchul Kim, Guang-Jie Ren, Vaishnavi Muppala, Shun Jiang, Yongsung Kim, and Chanyoung Park
Mehrab Tanjim, Yeonjun In, Xiang Chen, Victor Bursztyn, Ryan A. Rossi, Sungchul Kim, Guang-Jie Ren, Vaishnavi Muppala, Shun Jiang, Yongsung Kim, and Chanyoung Park. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.482 Disambiguation in conversational question answering in the era of LLM s and agents: A survey . In Proceedings of the 2025 Conference on Em...
-
[38]
Alberto Testoni and Raquel Fern \'a ndez. 2024. https://doi.org/10.18653/v1/2024.eacl-long.16 Asking the right question at the right time: Human and model uncertainty guidance to ask clarification questions . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 258--2...
-
[39]
Alberto Testoni, Barbara Plank, and Raquel Fern \'a ndez. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1206 RA c QUE t: Unveiling the dangers of overlooked referential ambiguity in visual LLM s . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 23638--23658, Suzhou, China. Association for Computational ...
-
[40]
Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Lyudmila Rvanova, Daniil Vasilev, Akim Tsvigun, Sergey Petrakov, Rui Xing, Abdelrahman Sadallah, Kirill Grishchenkov, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov, and Artem Shelmanov. 2025. https://doi.org/10.1162/tacl_a_00737 Benchmarking uncertainty quantification methods for larg...
-
[41]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://openreview.net/forum?id=1PL1NIMMrw Self-consistency improves chain of thought reasoning in language models . In The Eleventh International Conference on Learning Representations
2023
-
[42]
Ian Wu, Patrick Fernandes, Amanda Bertsch, Seungone Kim, Sina Khoshfetrat Pakazad, and Graham Neubig. 2025. https://openreview.net/forum?id=7xCSK9BLPy Better instruction-following through minimum bayes risk . In The Thirteenth International Conference on Learning Representations
2025
-
[43]
Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, and Jing Gao. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.343 S ay S elf: Teaching LLM s to express confidence with self-reflective rationales . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5985--5998, Miami, Florida, USA. ...
-
[44]
Gal Yona, Roee Aharoni, and Mor Geva. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.443 Can large language models faithfully express their intrinsic uncertainty in words? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7752--7764, Miami, Florida, USA. Association for Computational Linguistics
-
[45]
Michael JQ Zhang and Eunsol Choi. 2025. https://doi.org/10.18653/v1/2025.findings-naacl.306 Clarify when necessary: Resolving ambiguity through interaction with LM s . In Findings of the Association for Computational Linguistics: NAACL 2025, pages 5526--5543, Albuquerque, New Mexico. Association for Computational Linguistics
-
[46]
Bradley Knox, and Eunsol Choi
Michael JQ Zhang, W. Bradley Knox, and Eunsol Choi. 2025. https://openreview.net/forum?id=cwuSAR7EKd Modeling future conversation turns to teach LLM s to ask clarifying questions . In The Thirteenth International Conference on Learning Representations
2025
-
[47]
Tong Zhang, Peixin Qin, Yang Deng, Chen Huang, Wenqiang Lei, Junhong Liu, Dingnan Jin, Hongru Liang, and Tat-Seng Chua. 2024. https://doi.org/10.18653/v1/2024.acl-long.578 CLAMBER : A benchmark of identifying and clarifying ambiguous information needs in large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational...
-
[48]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[49]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.